

系统仿真学报 ›› 2024, Vol. 36 ›› Issue (11): 2616-2630.doi: 10.16182/j.issn1004731x.joss.23-0926
鲁斌1,2, 王明晗1,2, 孙洋1,2, 杨振宇1,2
收稿日期:2023-07-21
修回日期:2023-09-12
出版日期:2024-11-13
发布日期:2024-11-19
通讯作者:
王明晗
第一作者简介:鲁斌(1975-),男,教授,博导,博士,研究方向为智能计算与计算机视觉、综合能源系统与大数据分析。
基金资助:Lu Bin1,2, Wang Minghan1,2, Sun Yang1,2, Yang Zhenyu1,2
Received:2023-07-21
Revised:2023-09-12
Online:2024-11-13
Published:2024-11-19
Contact:
Wang Minghan
摘要:
针对基于点云的三维目标检测中存在的特征提取能力不足和检测头分类与回归不一致问题,提出基于SECOND网络的ResCST架构。该模型在三维稀疏卷积层中引入残差连接,结合 SwinTransformer 捕捉长距离依赖关系的能力和卷积神经网络获取局部特征的优势,提出CNN-SwinTransformer 混合模型,有效提升特征表达能力;提出 RCIoU 方法,并将其应用于回归和分类分支,实现了分类与回归任务的联合优化。实验结果表明,在自动驾驶数据集 KITTI汽车类别检测中,该模型在简单、中等和困难难度级别下的三维检测精度分别达到了91.21%、82.97%和80.28%。所提方法对困难目标检测效果提升明显,可达到每秒25帧的推理速度。所提出的 ResCST 架构在精度与速率之间取得了较好的平衡。
中图分类号:
鲁斌,王明晗,孙洋等 . 全局信息感知与局部特征融合的高效三维目标检测[J]. 系统仿真学报, 2024, 36(11): 2616-2630.
Lu Bin,Wang Minghan,Sun Yang,et al . Global-local Fusion for Efficient 3D Object Detection[J]. Journal of System Simulation, 2024, 36(11): 2616-2630.
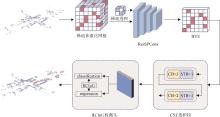
图1
ResCST整体框架
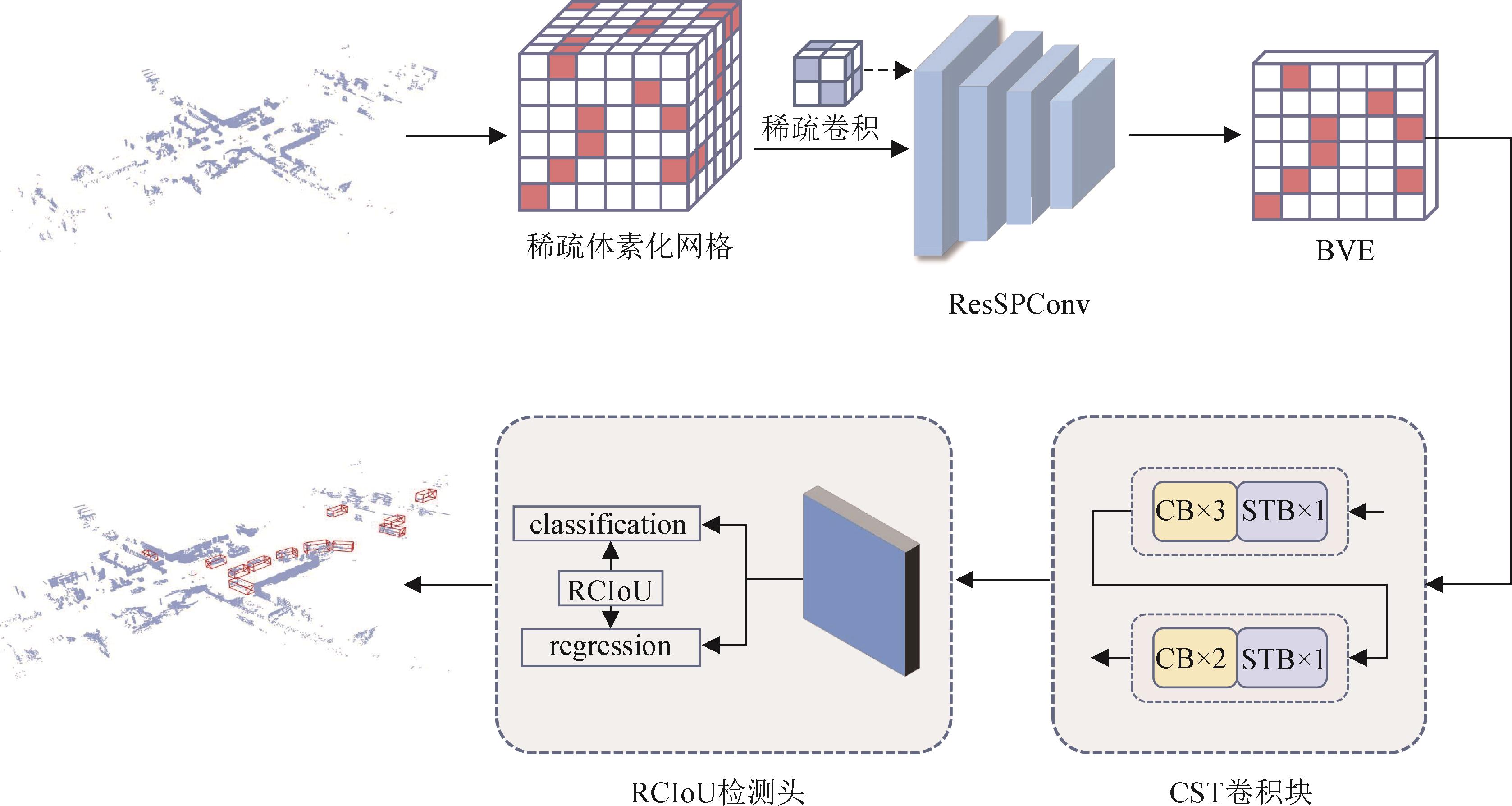

图 2
体素化结果可视化


图 3
堆叠前与堆叠后特征图可视化
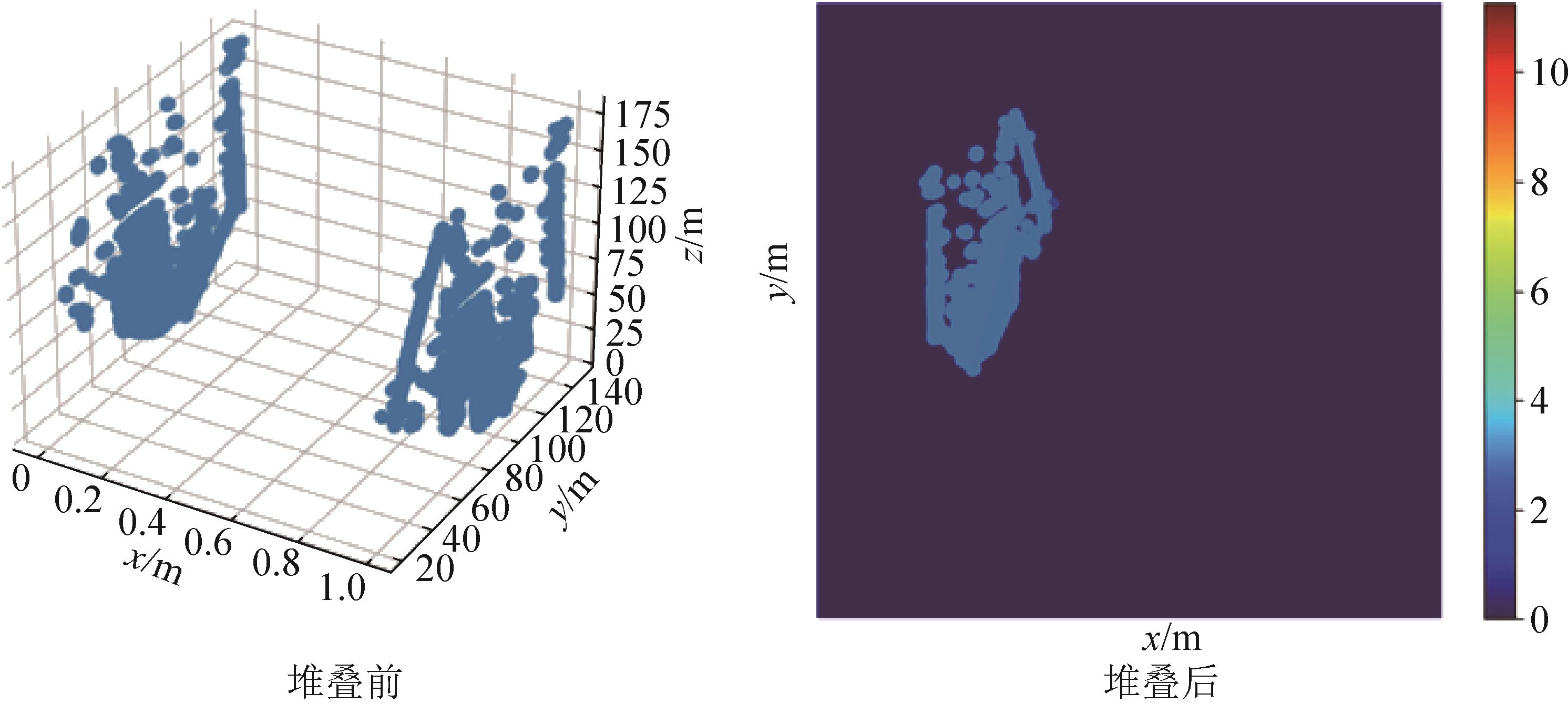
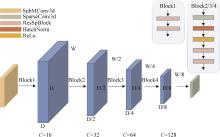
图4
ResSPConvNet架构
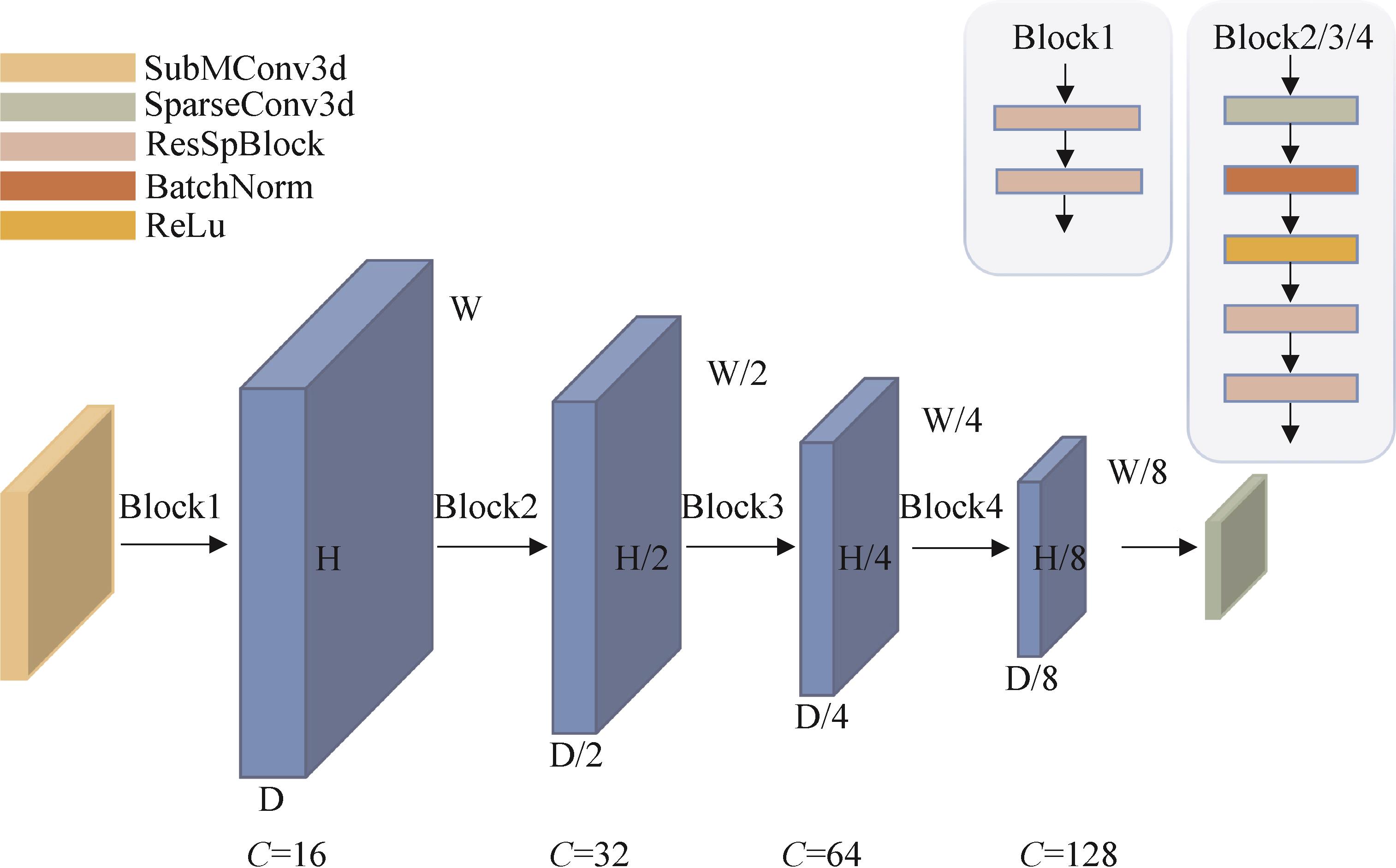
图 5
CST网络结构及自注意力特征图
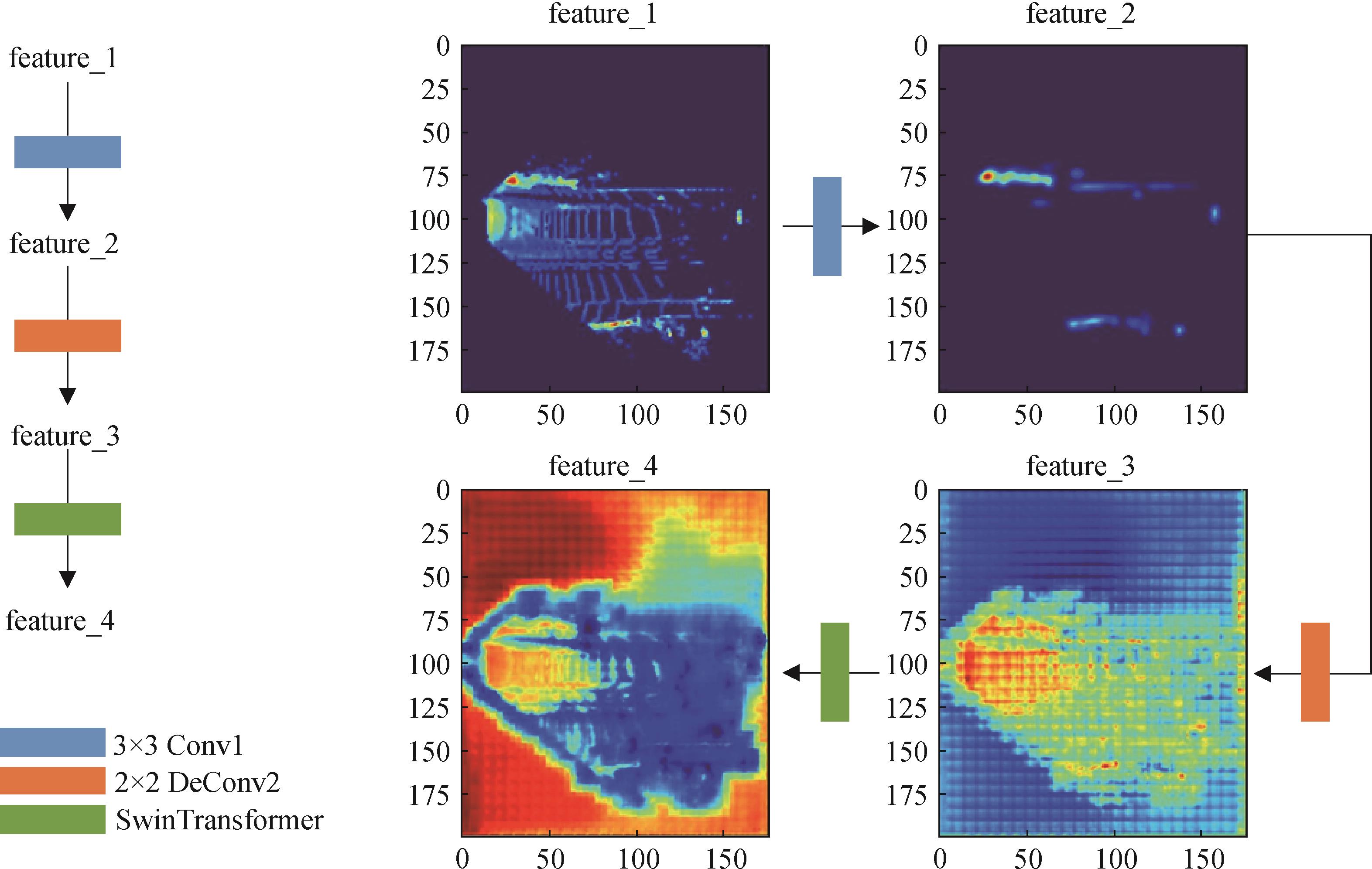
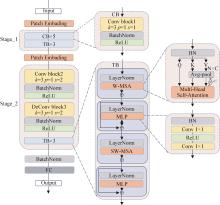
图6
CST架构图
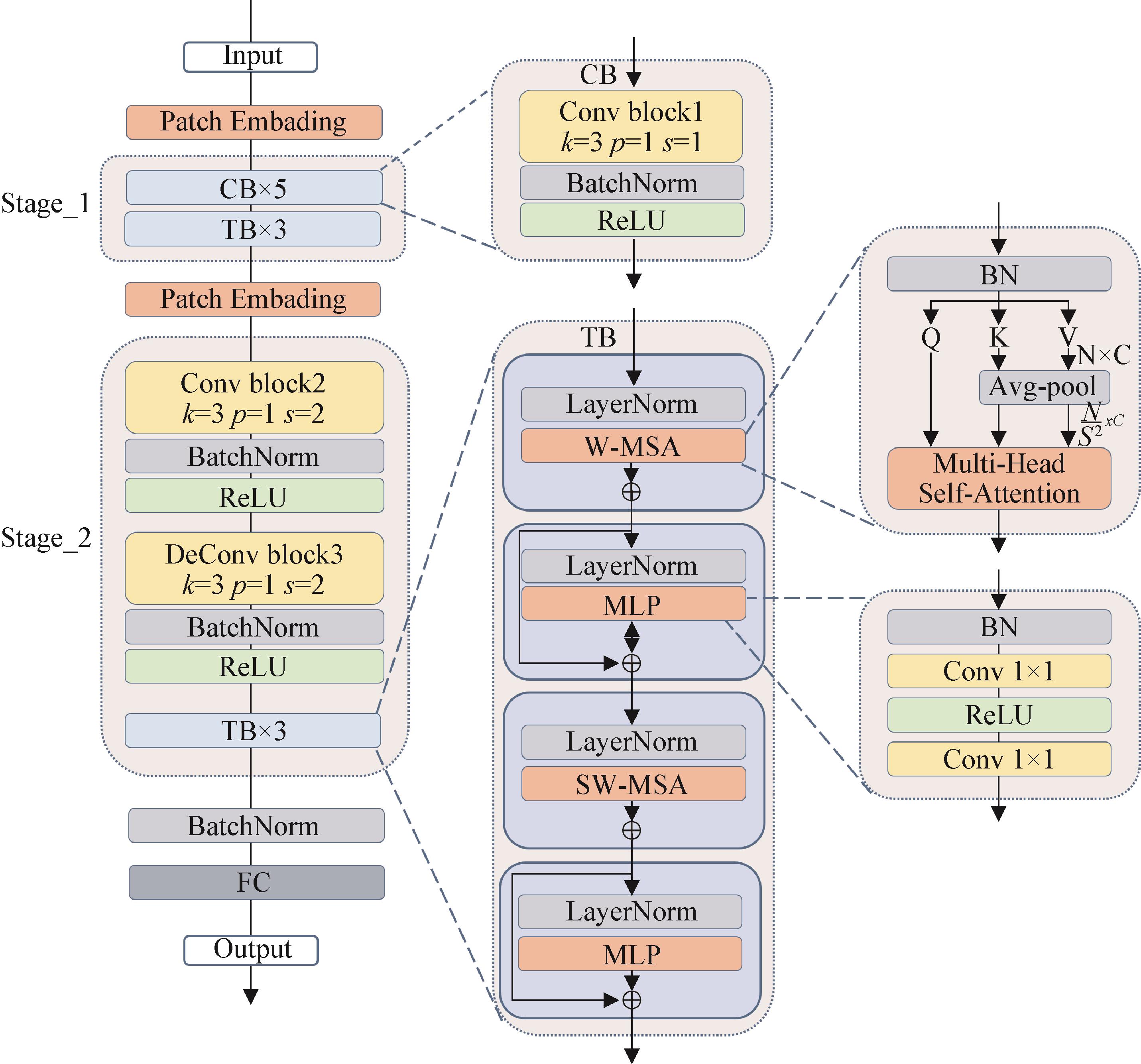
表1
实验环境及参数
| 环境 | 参数 |
|---|---|
| GPU | NVIDIA RTX 3090 |
| 显存 | 24 GB |
| Python 版本 | 3.8 |
| 深度学习框架 | PyTorch 1.8.1 |
| CUDA 版本 | 11.1 |
| cuDNN版本 | 8.0 |
| SpConv | 2.3.3 |
表2
本文方法与其他类方法的AP3D对比(R40)
| Method | Stage | Car_AP3D(IoU=0.7)% | ||
|---|---|---|---|---|
| Easy | Moderate | Hard | ||
| PointRCNN[ | Two | 85.94 | 75.76 | 68.32 |
| Point-GNN[ | 88.33 | 79.47 | 72.29 | |
| VoTr-TSD[ | 89.90 | 82.09 | 79.14 | |
| CT3D[ | 87.83 | 81.77 | 77.16 | |
| BtcDet[ | 90.64 | 82.86 | 78.09 | |
| VoxelNet[ | One | 77.82 | 65.11 | 62.85 |
| SECOND[ | 83.34 | 73.66 | 66.20 | |
| PointPillar[ | 86.46 | 77.28 | 74.65 | |
| SE-SSD[ | 91.49 | 82.54 | 77.15 | |
| Ours | 91.21 | 82.97 | 80.28 | |
| Method | Stage | Cyclist_AP3D(IoU=0.7)% | ||
| Easy | Moderate | Hard | ||
| PointRCNN[ | Two | 92.51 | 71.89 | 67.48 |
| Point-GNN[ | ‒ | ‒ | ‒ | |
| VoTr-TSD[ | ‒ | ‒ | ‒ | |
| CT3D[ | 89.01 | 71.88 | 67.91 | |
| BtcDet[ | ‒ | ‒ | ‒ | |
| VoxelNet[ | One | ‒ | ‒ | ‒ |
| SECOND[ | 82.96 | 66.74 | 62.78 | |
| PointPillar[ | 81.58 | 62.94 | 58.98 | |
| SE-SSD[ | ‒ | ‒ | ‒ | |
| Ours | 87.81 | 69.94 | 65.33 | |
表3
本文方法与其他单阶段类方法汽车类的AP3D对比(R11)
| Method | FPS | Car_AP3D(IoU=0.7)% | ||
|---|---|---|---|---|
| Easy | Moderate | Hard | ||
| VoxelNet[ | 4.4 | 81.97 | 65.46 | 62.85 |
| SECOND[ | 20 | 87.43 | 76.48 | 69.10 |
| PointPillar[ | 42 | 86.62 | 76.06 | 68.91 |
| SE-SSD[ | 25 | ‒ | 81.71 | ‒ |
| Ours | 25 | 89.17 | 78.95 | 78.04 |

图7
可视化结果

表4
消融实验的3D检测平均均值精度
| ResSPConvNet | CSTNet | RCIoU | Car_AP3D% | ||
|---|---|---|---|---|---|
| Easy | Moderate | Hard | |||
| × | × | × | 87.43 | 76.48 | 69.10 |
| √ | × | × | 87.90 | 77.61 | 76.48 |
| × | √ | × | 87.77 | 77.42 | 76.03 |
| × | × | √ | 88.66 | 78.59 | 77.72 |
| √ | √ | √ | 89.87 | 79.10 | 78.99 |
表 5
卷积算子性能对比试验
| 卷积算子 | Car_AP3D% | 参数设置 | ||
|---|---|---|---|---|
| Easy | Moderate | Hard | ||
| 标准卷积 | 89.87 | 79.10 | 78.99 | ‒ |
| 空洞卷积 | 89.26 | 78.97 | 78.26 | dilation rate=2 |
| 分组卷积 | 88.77 | 77.42 | 77.03 | group size = 2 |
| 1 | Qi R, Su Hao, Mo Kaichun, et al. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2017: 77-85. |
| 2 | Qi R, Yi Li, Su Hao, et al. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates, Inc., 2017: 5105-5114. |
| 3 | Lang A H, Vora S, Caesar H, et al. PointPillars: Fast Encoders for Object Detection From Point Clouds[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2019: 12689-12697. |
| 4 | Zhou Sifan, Tian Zhi, Chu Xiangxiang, et al. FastPillars: A Deployment-friendly Pillar-based 3D Detector[EB/OL]. (2023-02-07) [2023-03-08]. . |
| 5 | Shi Guangsheng, Li Ruifeng, Ma Chao. PillarNet: Real-time and High-performance Pillar-based 3D Object Detection[EB/OL]. (2022-08-26) [2023-03-26]. . |
| 6 | Yin Tianwei, Zhou Xingyi, Krähenbühl Philipp. Center-based 3D Object Detection and Tracking[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2021: 11779-11788. |
| 7 | Zhou Yin, Tuzel O. VoxelNet: End-to-end Learning for Point Cloud Based 3D Object Detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4490-4499. |
| 8 | Yan Yan, Mao Yuxing, Li Bo. SECOND: Sparsely Embedded Convolutional Detection[J]. Sensors, 2018, 18(10): 3337. |
| 9 | Vaswani A, Shazeer N, Parmar N, et al. Attention Is All You Need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates, Inc., 2017: 6000-6010. |
| 10 | Li Jiashi, Xia Xin, Li Wei, et al. Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios[EB/OL]. (2022-08-16) [2023-04-11]. . |
| 11 | Li Jiale, Luo Shujie, Zhu Ziqi, et al. 3D IoU-net: IoU Guided 3D Object Detector for Point Clouds[EB/OL]. (2020-04-10) [2023-04-05]. . |
| 12 | Ren Shaoqing, He Kaiming, Girshick R, et al. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2015: 91-99. |
| 13 | Li Xiang, Wang Wenhai, Wu Lijun, et al. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection[C]//Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates, Inc., 2020: 21002-21012. |
| 14 | Zheng Zhaohui, Wang Ping, Liu Wei, et al. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 12993-13000. |
| 15 | Zhou Dingfu, Fang Jin, Song Xibin, et al. IoU Loss for 2D/3D Object Detection[C]//2019 International Conference on 3D Vision (3DV). Piscataway: IEEE, 2019: 85-94. |
| 16 | Zheng Wu, Tang Weiliang, Jiang Li, et al. SE-SSD: Self-ensembling Single-stage Object Detector from Point Cloud[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2021: 14489-14498. |
| 17 | Sheng Hualian, Cai Sijia, Zhao Na, et al. Rethinking IoU-based Optimization for Single-stage 3D Object Detection[C]//Computer Vision – ECCV 2022. Cham: Springer Nature Switzerland, 2022: 544-561. |
| 18 | Shi Shaoshuai, Wang Xiaogang, Li Hongsheng. PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2019: 770-779. |
| 19 | Yang Zetong, Sun Yanan, Liu Shu, et al. 3DSSD: Point-based 3D Single Stage Object Detector[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2020: 11037-11045. |
| 20 | Pan Xuran, Xia Zhuofan, Song Shiji, et al. 3D Object Detection with Pointformer[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2021: 7459-7468. |
| 21 | Shi Weijing, Rajkumar R. Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2020: 1708-1716. |
| 22 | Ge Runzhou, Ding Zhuangzhuang, Hu Yihan, et al. AFDet: Anchor Free One Stage 3D Object Detection[EB/OL]. (2020-06-30) [2023-04-26]. . |
| 23 | Hu Yihan, Ding Zhuangzhuang, Ge Runzhou, et al. AFDetV2: Rethinking the Necessity of the Second Stage for Object Detection from Point Clouds[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2022, 36(1): 969-979. |
| 24 | Zheng Wu, Tang Weiliang, Chen Sijin, et al. CIA-SSD: Confident IoU-aware Single-stage Object Detector from Point Cloud[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35(4): 3555-3562. |
| 25 | Fan Lue, Pang Ziqi, Zhang Tianyuan, et al. Embracing Single Stride 3D Object Detector with Sparse Transformer[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2022: 8448-8458. |
| 26 | Zou Jiayu, Tian Kun, Zhu Zheng, et al. DiffBEV: Conditional Diffusion Model for Bird's Eye View Perception[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2024, 38(7), 7846-7854. |
| 27 | Li Bo, Zhang Tianlei, Xia Tian. Vehicle Detection from 3D Lidar Using Fully Convolutional Network[EB/OL]. (2016-08-29) [2023-05-31]. . |
| 28 | Beltrán Jorge, Guindel Carlos, Francisco Miguel Moreno, et al. BirdNet: A 3D Object Detection Framework from LiDAR Information[C]//2018 21st International Conference on Intelligent Transportation Systems (ITSC). Piscataway: IEEE, 2018: 3517-3523. |
| 29 | Wang Tai, Zhu Xinge, Lin Dahua. Reconfigurable Voxels: A New Representation for LiDAR-based Point Clouds[C]//Proceedings of the 2020 Conference on Robot Learning. Chia Laguna Resort: PMLR, 2021: 286-295. |
| 30 | Wu Hai, Wen Chenglu, Li Wei, et al. Transformation-equivariant 3D Object Detection for Autonomous Driving[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2023, 37(3): 2795-2802. |
| 31 | Wu Xiaopei, Peng Liang, Yang Honghui, et al. Sparse Fuse Dense: Towards High Quality 3D Detection with Depth Completion[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2023: 5408-5417. |
| 32 | Dosovitskiy A, Beyer L, Kolesnikov A, et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale[EB/OL]. (2021-06-03) [2023-05-28]. . |
| 33 | Zhou Yin, Sun Pei, Zhang Yu, et al. End-to-end Multi-view Fusion for 3D Object Detection in LiDAR Point Clouds[C]//Proceedings of the Conference on Robot Learning. Chia Laguna Resort: PMLR, 2020: 923-932. |
| 34 | Liu Ze, Lin Yutong, Cao Yue, et al. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2021: 9992-10002. |
| 35 | Zhao Hengshuang, Jiang Li, Jia Jiaya, et al. Point Transformer[EB/OL]. (2021-09-26) [2023-05-13]. . |
| 36 | Mao Jiageng, Xue Yujing, Niu Minzhe, et al. Voxel Transformer for 3D Object Detection[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2021: 3144-3153. |
| 37 | He Chenhang, Li Ruihuang, Li Shuai, et al. Voxel Set Transformer: A Set-to-set Approach to 3D Object Detection from Point Clouds[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2022: 8407-8417. |
| 38 | Chen Xuanyao, Liu Zhijian, Tang Haotian, et al. SparseViT: Revisiting Activation Sparsity for Efficient High-resolution Vision Transformer[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2023: 2061-2070. |
| 39 | He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep Residual Learning for Image Recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2016: 770-778. |
| 40 | Xia Xin, Li Jiashi, Wu Jie, et al. TRT-ViT: TensorRT-oriented Vision Transformer[EB/OL]. (2022-07-12) [2023-06-01]. . |
| 41 | Li Yanyu, Yuan Geng, Wen Yang, et al. EfficientFormer: Vision Transformers at MobileNet Speed[C]//Advances in Neural Information Processing Systems. Red Hook: Curran Associates, Inc., 2022: 12934-12949. |
| 42 | Li Xiang, Wang Wenhai, Hu Xiaolin, et al. Generalized Focal Loss V2: Learning Reliable Localization Quality Estimation for Dense Object Detection[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2021: 11627-11636. |
| 43 | Geiger Andreas, Lenz Philip, Urtasun R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite[C]//Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2012: 3354-3361. |
| 44 | Sheng Hualian, Cai Sijia, Liu Yuan, et al. Improving 3D Object Detection with Channel-wise Transformer[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2021: 2723-2732. |
| 45 | Xu Qiangeng, Zhong Yiqi, Neumann U. Behind the Curtain: Learning Occluded Shapes for 3D Object Detection[C]//Proceedings of the AAAI Conference on Artificial Intelligence, 2022, 36(3), 2893-2901. |
| [1] | 石敏, 郭诗盛, 王素琴, 李兆歆, 朱登明. 融合物理与几何先验的无抓取标注6-DoF抓取检测方法[J]. 系统仿真学报, 2026, 38(5): 1290-1302. |
| [2] | 姜彦吉, 肖星佚, 董浩, 于淼, 黄金山, 刘大千, 费博雯. 融合点线特征的图关系优化3D车道线检测方法[J]. 系统仿真学报, 2026, 38(5): 1303-1319. |
| [3] | 万飞, 尹勇. 融合GPS先验信息的3D高斯溅射大规模场景配准技术[J]. 系统仿真学报, 2026, 38(3): 563-571. |
| [4] | 陈燕军, 周敏, 查蒙, 张美洲. 基于CCL-YOLOv8的汽车轮毂表面缺陷检测算法研究与分析[J]. 系统仿真学报, 2026, 38(3): 670-686. |
| [5] | 杨灿, 陈凯, 朱峰. 多约束条件下基于强化学习的无人机团队定向优化方法[J]. 系统仿真学报, 2026, 38(2): 360-371. |
| [6] | 王继恒, 胡阳, 宋子秋, 房方, 刘吉臻. 基于多模态混合深度学习的大型风电机组入流风场预测[J]. 系统仿真学报, 2026, 38(2): 501-517. |
| [7] | 朱贺, 周锋, 张琪, 朱孟笑, 代菊. PL-Mamba:基于双模态融合的三维点云语义分割网络[J]. 系统仿真学报, 2026, 38(1): 73-83. |
| [8] | 江明, 何韬. 基于深度强化学习的带容量约束车辆路径问题求解[J]. 系统仿真学报, 2025, 37(9): 2177-2187. |
| [9] | 姜彦吉, 张颖阳, 董浩, 张晓光, 王美惠. 基于实例关联的暗光下车道线检测[J]. 系统仿真学报, 2025, 37(9): 2188-2199. |
| [10] | 马仑, 杨跃, 王迨贺, 廖桂生, 李幸. 联合自注意力机制与权值共享的人体行为识别模型[J]. 系统仿真学报, 2025, 37(9): 2409-2419. |
| [11] | 鲁斌, 杨烜, 杨振宇, 高啸天. 自适应采样与重影多尺度特征融合的轻量化焊缝缺陷检测[J]. 系统仿真学报, 2025, 37(8): 1978-1990. |
| [12] | 李明煜, 林家泉. 基于YOLOv8-DF的轻量化驾驶员面部目标检测算法[J]. 系统仿真学报, 2025, 37(8): 2103-2114. |
| [13] | 刘子龙, 张磊. 自然环境下改进YOLOv5对小目标苹果的检测[J]. 系统仿真学报, 2025, 37(8): 2124-2138. |
| [14] | 吴建平, 李冠洲, 赵帅, 黄玲. 自动驾驶仿真测试技术驱动汽车产业智能跃迁[J]. 系统仿真学报, 2025, 37(7): 1649-1664. |
| [15] | 杨路, 裴俊莹. 融合多尺度特征的航拍目标检测算法[J]. 系统仿真学报, 2025, 37(6): 1486-1498. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
