

系统仿真学报 ›› 2024, Vol. 36 ›› Issue (1): 67-82.doi: 10.16182/j.issn1004731x.joss.22-0937
李晨1( ), 何明1(), 董晨2, 李伟1
), 何明1(), 董晨2, 李伟1
收稿日期:2022-08-09
修回日期:2022-10-18
出版日期:2024-01-20
发布日期:2024-01-19
通讯作者:
何明
E-mail:651220007@qq.com;paper_review@126.com
第一作者简介:李晨(1994-),男,硕士生,研究方向为计算机视觉。E-mail:651220007@qq.com
基金资助:
Li Chen1(), He Ming1(), Dong Chen2, Li Wei1
Received:2022-08-09
Revised:2022-10-18
Online:2024-01-20
Published:2024-01-19
Contact:
He Ming
E-mail:651220007@qq.com;paper_review@126.com
摘要:
针对传统点积注意力缺乏方向性的问题,建立了一种基于余弦相似性的定向注意力模型(directed attention model, DAM)。为有效表示视频帧时空特征间的方向关系,运用余弦相似性理论,定义了注意力机制中关系函数,能够去除特征间关系绝对值;为降低注意力机制计算量,从时间和空间两个维度上对运算进行分解;结合线性注意力运算,进一步优化计算复杂度。实验分为两个阶段:对定向注意力各模块开展了4个消融实验,以表现DAM在精确度和效率方面的最佳性能;该模型在Sth-Sth V1(something something V1)数据集上的精确度较I3D-NL(inflated 3D ConvNet non-local)高7.3%,在UCF101(101 human action classes from videos in the wild)数据集上的识别精确率为95.7%。研究成果在安全监控、自动驾驶等方面应用前景广泛。
中图分类号:
李晨,何明,董晨等 . 基于余弦相似性的定向注意力行为识别模型[J]. 系统仿真学报, 2024, 36(1): 67-82.
Li Chen,He Ming,Dong Chen,et al . Action Recognition Model of Directed Attention Based on Cosine Similarity[J]. Journal of System Simulation, 2024, 36(1): 67-82.
表 1
AR方法总览概况
| 角度 | 方法 | 代表模型 | 优、缺点 |
|---|---|---|---|
| 时间特征提取 | 双流网络 | Two-stream Network[ | 可提取时间特征,但计算量高、不稳定、特征局部 |
| 3D CNN | C3D[ | 可提取时空特征,但计算量高,无法提取全局特征 | |
| 时态模块 | TSM[ | 可灵活提取时空特征,但无法高效联系全局信息 | |
| 高效率优化 | 输入数据优化 | TSN[ | 可降低效率,但影响识别准确性 |
| 时空分解卷积 | P3D[ | 可降低效率,但不利于模型最优迭代 | |
| 深度分离卷积 | CSN[ | 可降低效率,但缺少跨通道信息 | |
| 混合卷积 | ECO[ | 可降低效率,但前期训练工作较困难 | |
| 全局特征捕获 | 全局均匀采样 | TSN[ | 可捕获时间全局特征,但缺乏对空间全局特征 |
| LSTM | I3D-LSTM[ | 增强全局表征,但训练效率较低 | |
| 自注意力机制 | NLNN[ | 可提取全局特征,但缺乏特征方向性和运行效率 |
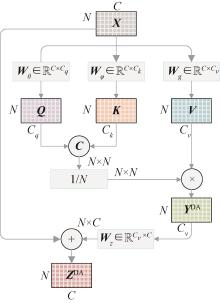
图1
DA-NL-1定向注意力非局部块
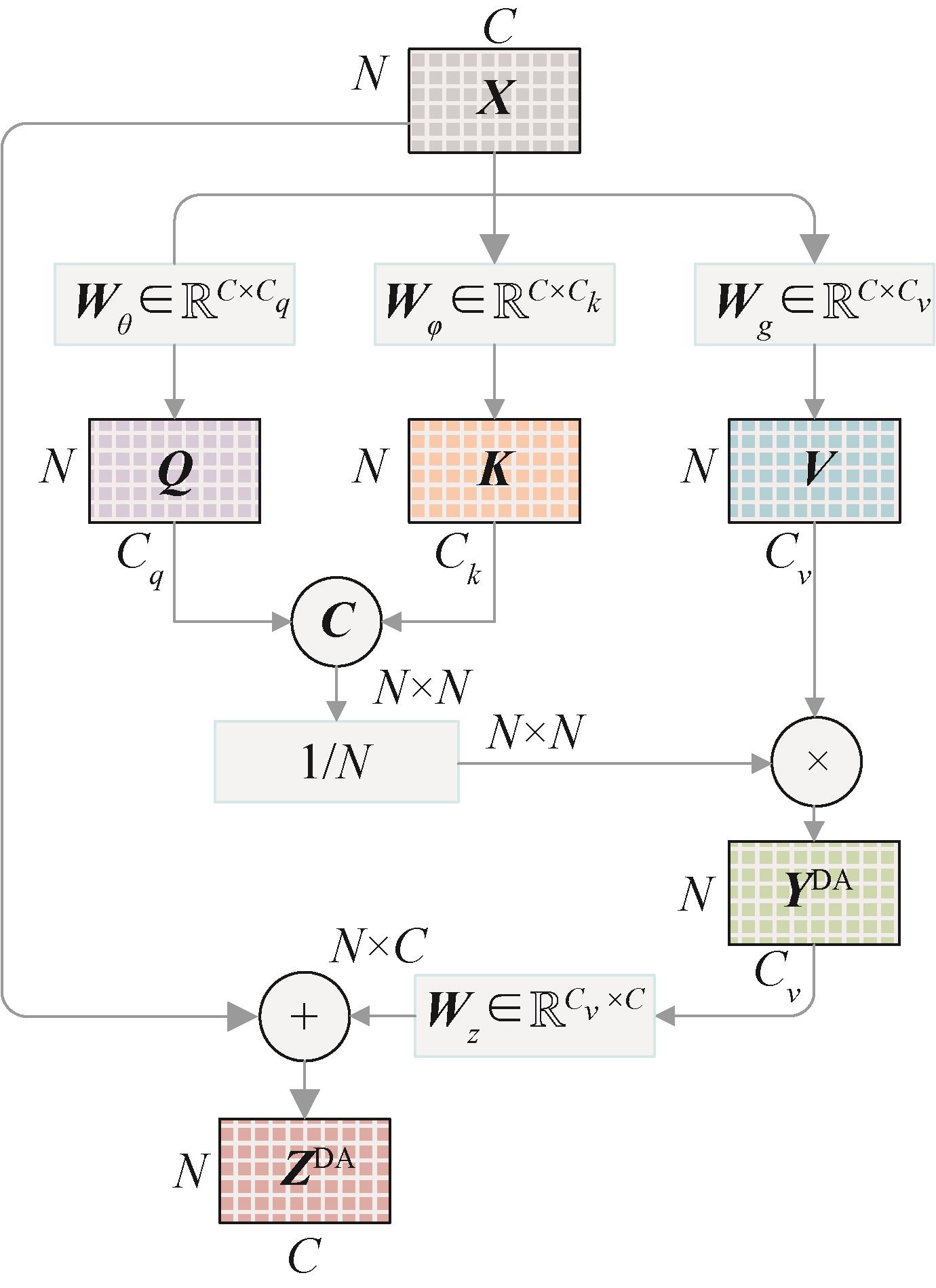
图 2
DA-DA时空分解定向注意力非局部块
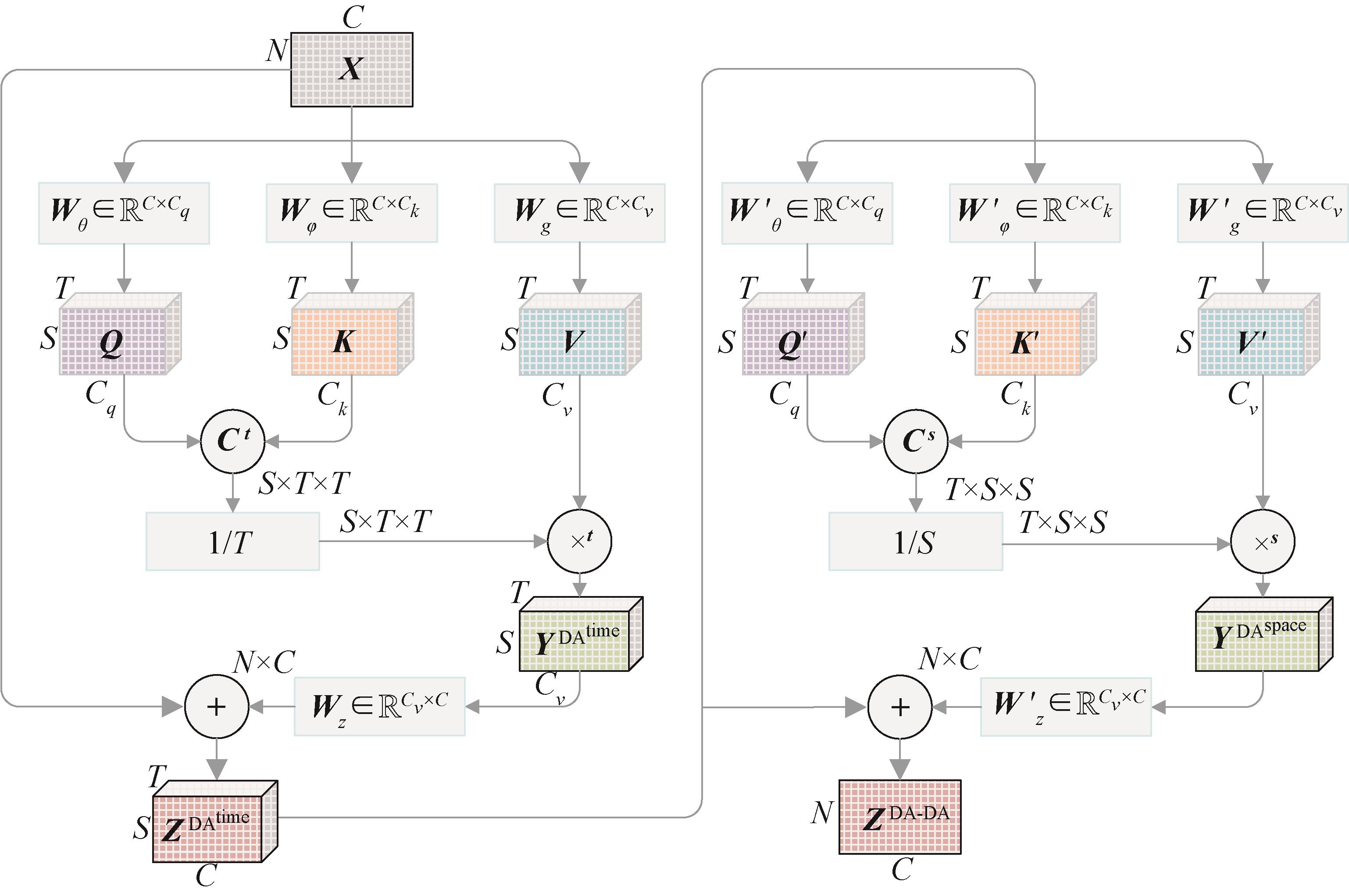
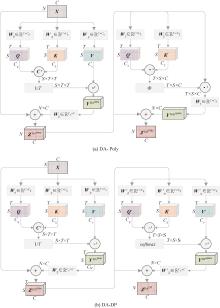
图 3
高效组合定向注意力模块DA-Poly和DA-DP
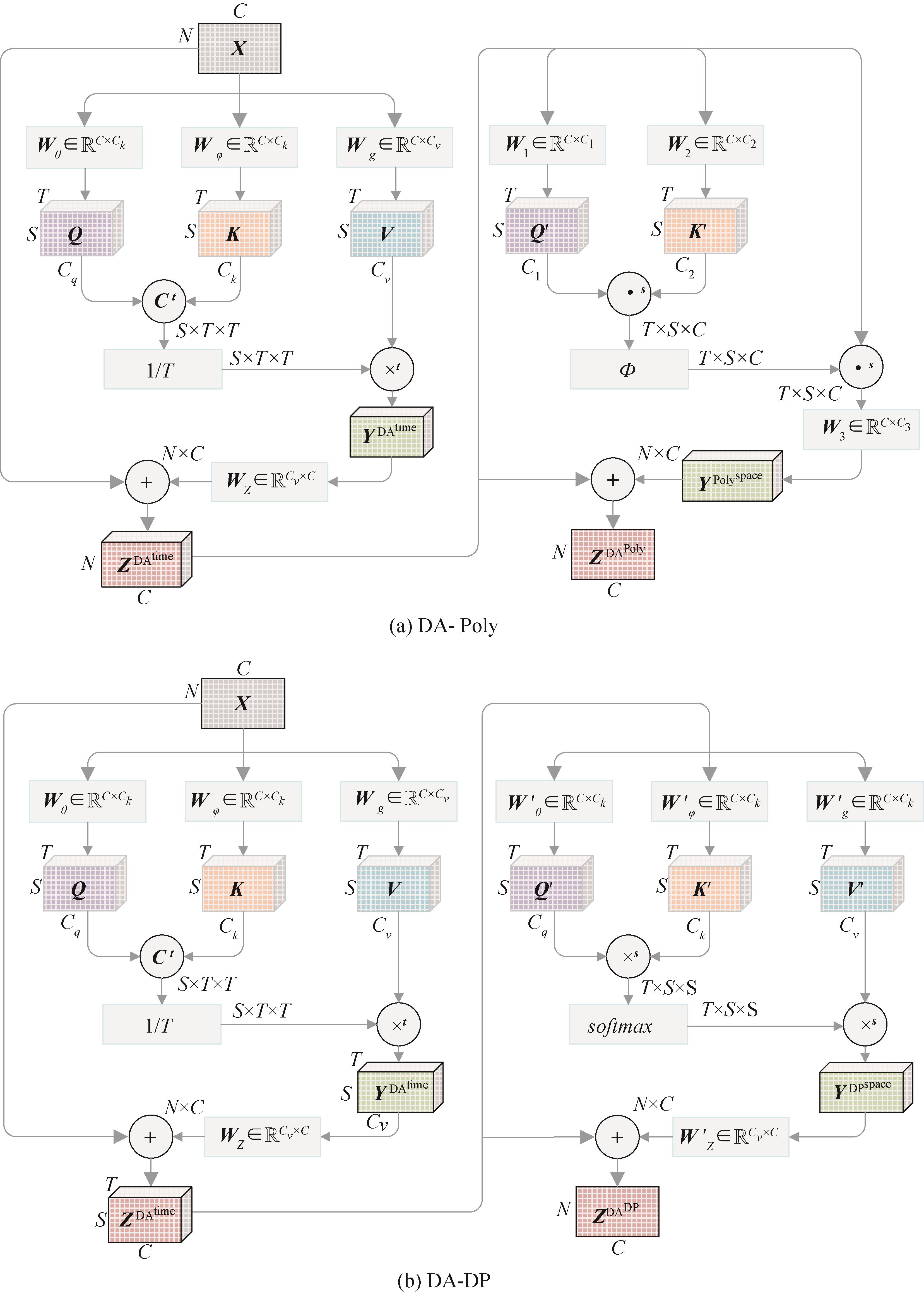
表 2
ResNet50-C2D架构
| 名称 | 输出尺寸 | 卷积核 | 步长 |
|---|---|---|---|
| 输入 | 32×224×224 | ||
| Conv1 | 16×112×112 | 1×7×7,64 | 1,2,2 |
| Pool1 | 8×56×56 | 3×3×3,max | 1,2,2 |
| Res1 | 8×56×56 | 1,1,1 | |
| Pool2 | 4×56×56 | 3×1×1, max | 2,1,1 |
| Res2 | 4×28×28 | 1,2,2 | |
| Res3 | 4×14×14 | 1,2,2 | |
| Res4 | 4×7×7 | 1,2,2 | |
| Pool3 | 1×1×1 | 4×7×7, average | 1,1,1 |
| Fc | 1×1×1 | 2048×class | 1,1,1 |
图4
基于不同数量定向模块的DAM
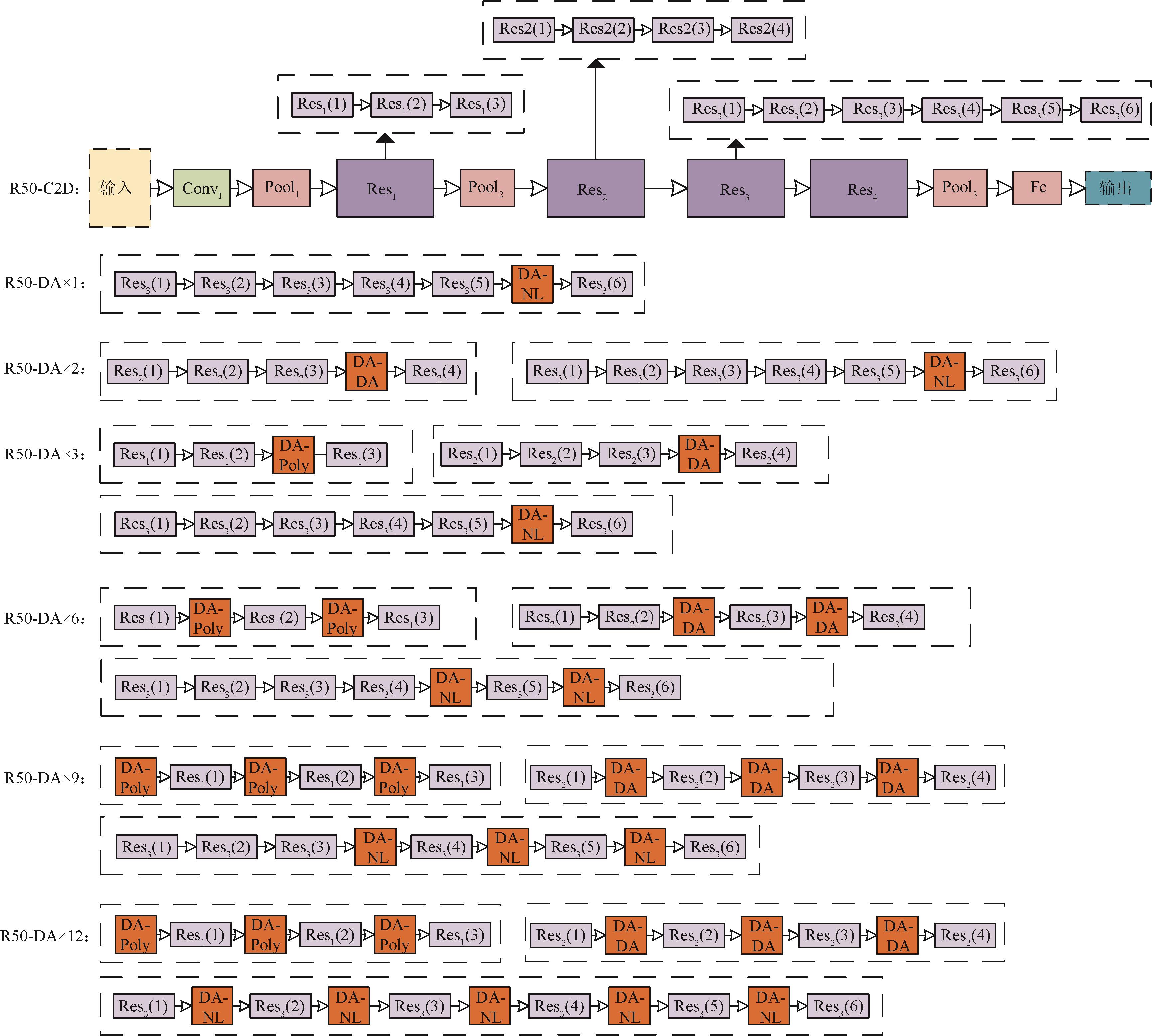
表3
基于不同关系函数的单模块性能对比
| 模块 | 参数量/MB | GFLOPS×View | Top1/ % | Top5/ % |
|---|---|---|---|---|
| 基准模型 | 24.18 | 26.19×10×3 | 71.76 | 89.85 |
| DP-NL[ | 25.56 | 26.47×10×3 | 72.68 | 90.47 |
| Poly-NL[ | 25.33 | 26.20×10×3 | 72.65 | 90.46 |
| DA-NL-1 | 25.53 | 27.02×10×3 | 73.21 | 90.73 |
| DA-NL-2 | 25.57 | 27.04×10×3 | 73.18 | 90.71 |
表 4
各组合定向注意力模块在Res层的性能比较
| 位置 | 模块 | 参数量/MB | GFLOPS×View | Top1/ % | Top5/ % |
|---|---|---|---|---|---|
| 基准模型 | 24.18 | 26.19×10×3 | 71.76 | 89.85 | |
| Res1 | DA-NL | 24.27 | 237.92×10×3 | 72.94 | 90.43 |
| DA-DA | 25.19 | 52.72×10×3 | 72.72 | 90.35 | |
| DA-Poly | 24.83 | 26.26×10×3 | 72.43 | 90.27 | |
| DA-DP | 25.22 | 35.08×10×3 | 72.46 | 90.26 | |
| Poly-DA | 24.83 | 52.66×10×3 | 72.68 | 90.32 | |
| DP-DA | 25.22 | 52.68×10×3 | 72.65 | 90.31 | |
| Res2 | DA-NL | 24.51 | 32.81×10×3 | 73.07 | 90.58 |
| DA-DA | 26.23 | 27.85×10×3 | 72.94 | 90.41 | |
| DA-Poly | 26.08 | 26.20×10×3 | 72.68 | 90.32 | |
| DA-DP | 26.25 | 26.75×10×3 | 72.65 | 90.31 | |
| Poly-DA | 26.08 | 27.84×10×3 | 72.90 | 90.38 | |
| DP-DA | 26.25 | 27.84×10×3 | 72.91 | 90.37 | |
| Res3 | DA-NL | 25.53 | 27.02×10×3 | 73.21 | 90.73 |
| DA-DA | 27.98 | 26.40×10×3 | 72.84 | 90.53 | |
| DA-Poly | 27.35 | 26.19×10×3 | 72.53 | 90.39 | |
| DA-DP | 30.02 | 26.26×10×3 | 72.49 | 90.37 | |
| Poly-DA | 27.35 | 26.39×10×3 | 72.76 | 90.40 | |
| DP-DA | 30.02 | 26.39×10×3 | 72.74 | 90.39 | |
| Res4 | DA-NL | 29.68 | 26.29×10×3 | 72.51 | 90.25 |
| DA-DA | 36.18 | 26.22×10×3 | 72.34 | 90.15 | |
| DA-Poly | 35.82 | 26.19×10×3 | 72.01 | 89.98 | |
| DA-DP | 36.24 | 26.20×10×3 | 72.04 | 90.02 | |
| Poly-DA | 35.82 | 26.22×10×3 | 72.28 | 90.12 | |
| DP-DA | 36.24 | 26.22×10×3 | 72.31 | 90.10 |

图 5
在Res3插入双模块的不同方案
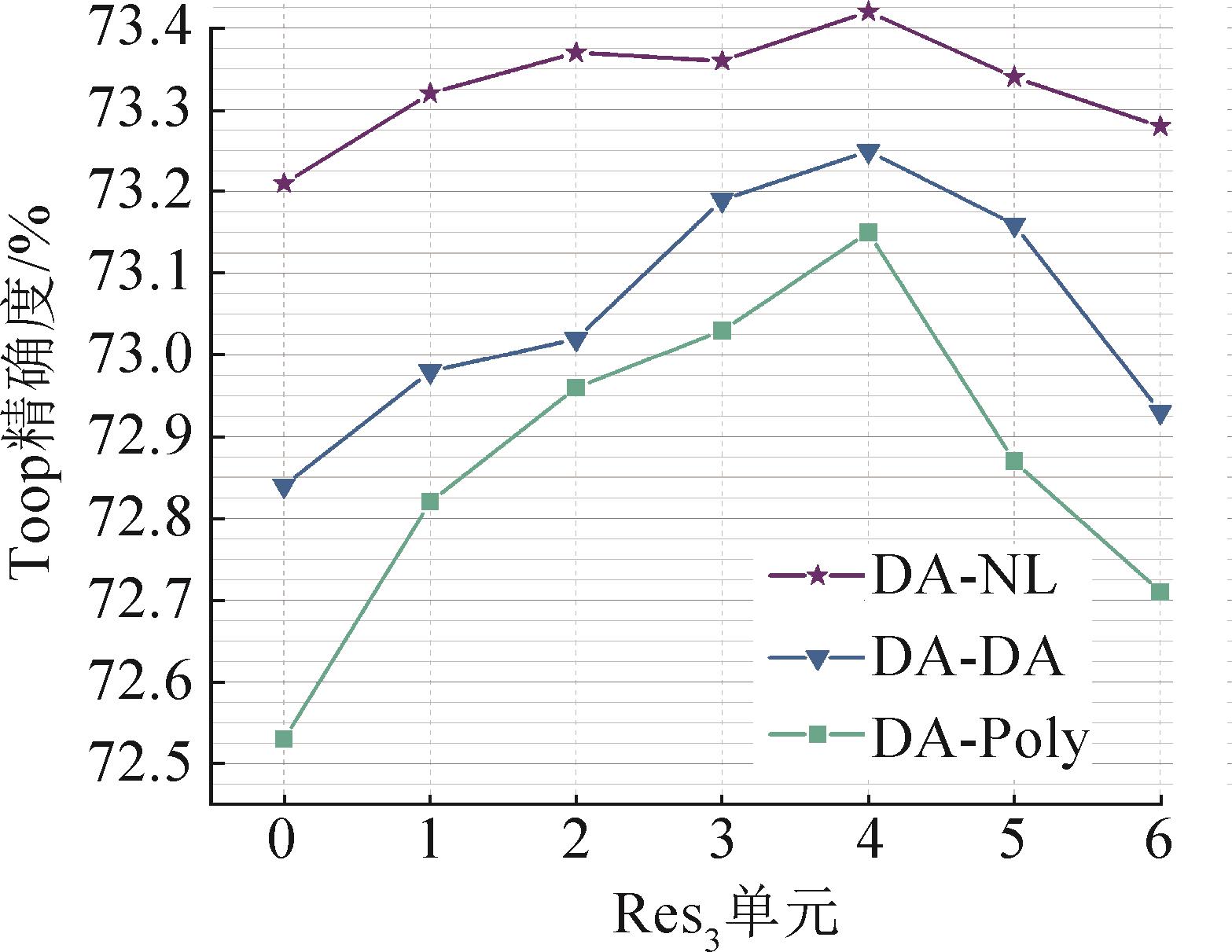
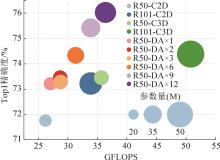
图 6
DAM与基准架构的比较
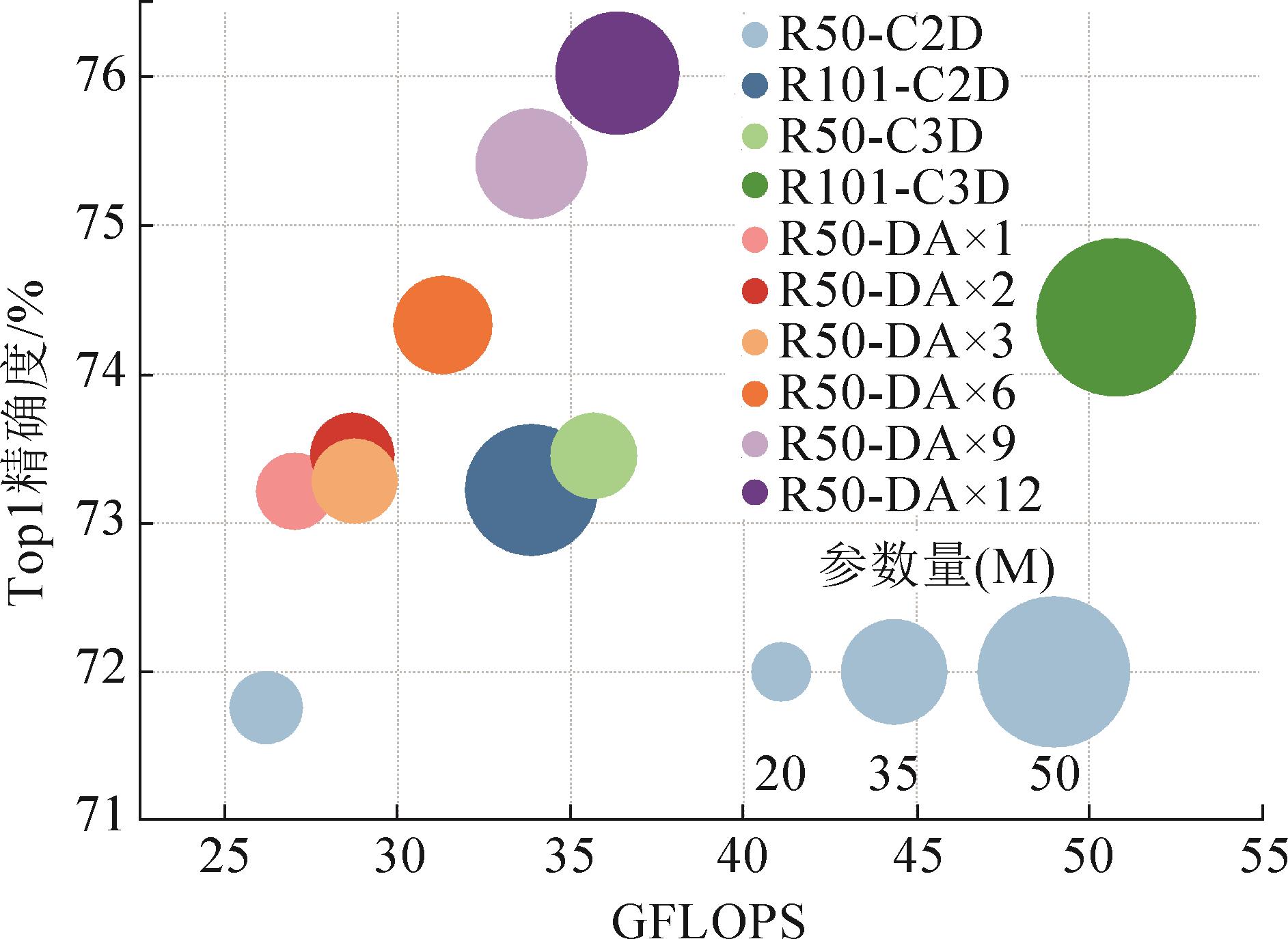
表 5
各对比模型在Sth-Sth V1数据集上的实验训练参数
| 模型 | 主干架构 | 预训练 | 初始学习率 | Dropout | 动量 | 权重衰减 | 帧数 | 分辨率 | 周期 | Batch |
|---|---|---|---|---|---|---|---|---|---|---|
| C2D[ | ResNet50 | I+K400 | 0.001 | 0.5 | 0.9 | 5×10-4 | 32 | 224×224 | 100 | 16 |
| TSN[ | BNInception | I | 0.020 | 0.8 | 0.9 | 1×10-4 | 8 | 224×224 | 50 | 8 |
| TSN[ | ResNet50 | I | 0.020 | 0.8 | 0.9 | 1×10-4 | 8 | 224×224 | 50 | 8 |
| C3D[ | ResNet50 | I+K400 | 0.001 | 0.5 | 0.9 | 5×10-4 | 32 | 224×224 | 100 | 16 |
| ECO[ | BNIncep+R18 | I+K400 | 0.001 | 0.5 | 0.9 | 5×10-4 | 8 | 224×224 | 100 | 32 |
| I3D[ | ResNet50 | I+K400 | 0.001 25 | 0.3 | 0.9 | 1×10-4 | 32 | 224×224 | 100 | 8 |
| I3D+NL[ | ResNet50 | I+K400 | 0.001 25 | 0.3 | 0.9 | 1×10-4 | 32 | 224×224 | 100 | 8 |
| S3D-G[ | BN-Inception | I | 0.100 | 0.5 | 0.9 | 1×10-4 | 64 | 224×224 | 100 | 6 |
| TRN[ | BNInception | I | 0.001 | 0.5 | 0.9 | 1×10-4 | 8 | 224×224 | 100 | 10 |
| TRN[ | ResNet50 | I | 0.001 | 0.5 | 0.9 | 1×10-4 | 8 | 224×224 | 100 | 10 |
| TSM[ | ResNet50 | I+K400 | 0.010 | 0.5 | 0.9 | 1×10-4 | 8 | 224×224 | 50 | 64 |
| TEA*[ | ResNet50 | I | 16 | 224×224 | ||||||
| TDN[ | ResNet50 | I+S1M | 0.020 | 0.5 | 0.9 | 1×10-4 | 8 | 224×224 | 60 | 128 |
| DAM | ResNet50 | I+K400 | 0.001 | 0.5 | 0.9 | 5×10-4 | 32 | 224×224 | 100 | 16 |
表 6
DAM在Sth-Sth V1数据集上与其他方法的测试比较
| 模型 | 主干架构 | 帧数×View | 分辨率 | 参数量/MB | GFLOPS×View | Top1 | Top5 |
|---|---|---|---|---|---|---|---|
| C2D[ | ResNet50 | 32×1×1 | 224×224 | 24.18 | 26.19×1×1 | 18.7 | 45.3 |
| TSN[ | BNInception | 8×1×1 | 224×224 | 10.70 | 16×1×1 | 19.5 | |
| TSN[ | ResNet50 | 8×1×1 | 224×224 | 24.30 | 33×1×1 | 19.7 | 46.6 |
| C3D[ | ResNet50 | 32×1×1 | 224×224 | 28.51 | 35.67×1×1 | 32.8 | 60.3 |
| ECO[ | BNIncep+R18 | 8×1×1 | 224×224 | 47.50 | 32×1×1 | 39.6 | |
| I3D[ | ResNet50 | 32×2×1 | 224×224 | 28.00 | 153×2×1 | 41.6 | 72.2 |
| I3D+NL[ | ResNet50 | 32×2×1 | 224×224 | 35.30 | 168×2×1 | 44.4 | 76.0 |
| S3D-G[ | BN-Inception | 64×1×1 | 224×224 | 11.56 | 71.38×1×1 | 48.2 | 78.7 |
| TRN[ | BNInception | 8×1×1 | 224×224 | 18.30 | 16×1×1 | 34.4 | |
| TRN[ | ResNet50 | 8×1×1 | 224×224 | 31.80 | 33×1×1 | 38.9 | 68.1 |
| TSM[ | ResNet50 | 8×1×1 | 224×224 | 24.30 | 33×1×1 | 45.6 | 74.2 |
| TEA[ | ResNet50 | 16×1×1 | 224×224 | 70×1×1 | 51.9 | 80.3 | |
| TDN[ | ResNet50 | 8×1×1 | 224×224 | 36×1×1 | 52.3 | 80.6 | |
| DAM | ResNet50 | 8×1×1 | 224×224 | 40.38 | 9.09×1×1 | 48.2 | 76.5 |
| DAM | ResNet50 | 16×1×1 | 224×224 | 40.38 | 18.18×1×1 | 49.5 | 78.3 |
| DAM | ResNet50 | 32×1×1 | 224×224 | 40.38 | 36.36×1×1 | 51.7 | 80.1 |
表 7
DAM在UCF101和HMDB51上的平均类精度
| 模型 | 预训练 | UCF101 | HMDB51 |
|---|---|---|---|
| C3D[ | Kinetics400 | 84.6 | 54.3 |
| I3D[ | Kinetics400 | 91.8 | 66.4 |
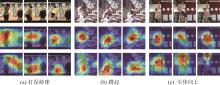
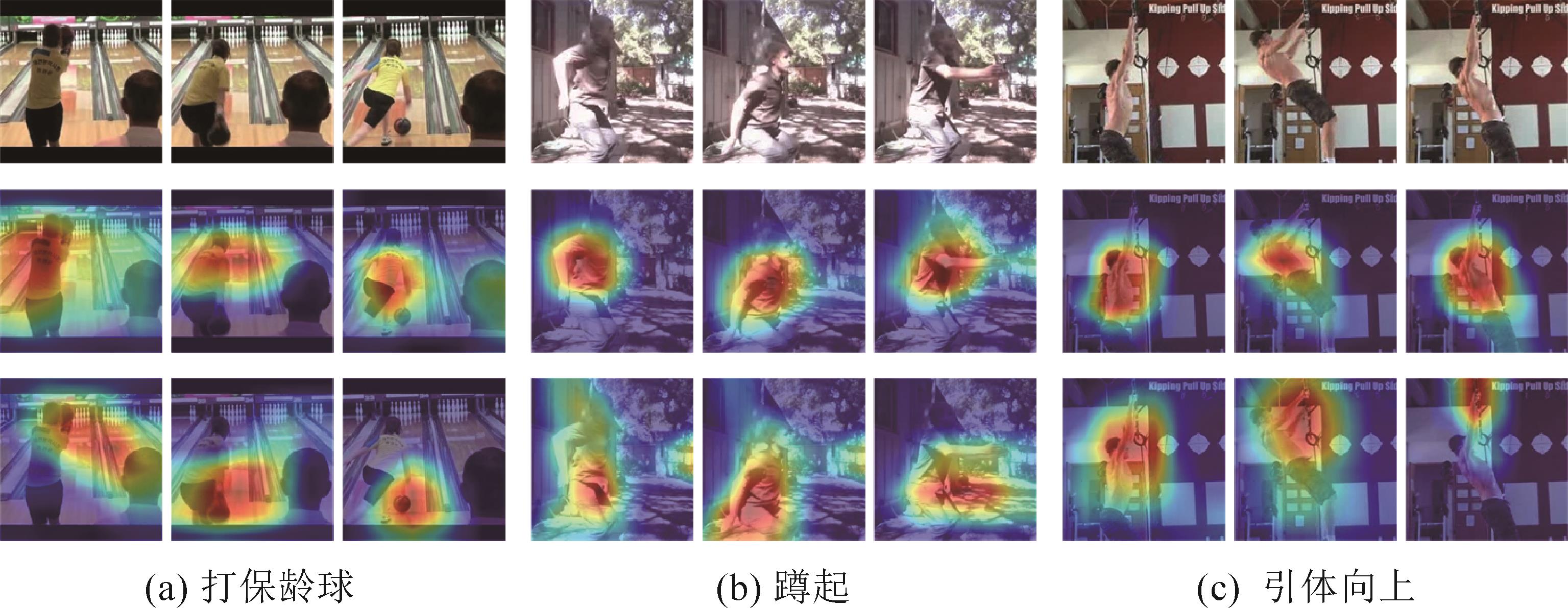
图 7
使用CAM可视化特定于行为的激活图
| 1 | Wang Xiaolong, Girshick R, Gupta A, et al. Non-local Neural Networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2018: 7794-7803. |
| 2 | Truong T D, Bui Quoc-Huy, Chi Nhan Duong, et al. DirecFormer: A Directed Attention in Transformer Approach to Robust Action Recognition[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2022: 19998-20008. |
| 3 | Babiloni F, Marras I, Kokkinos F, et al. Poly-NL: Linear Complexity Non-local Layers with 3rd Order Polynomials[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE, 2021: 10498-10508. |
| 4 | Wang Heng, Schmid Cordelia. Action Recognition with Improved Trajectories[C]//2013 IEEE International Conference on Computer Vision. Piscataway, NJ, USA: IEEE, 2013: 3551-3558. |
| 5 | Simonyan K, Zisserman A. Two-stream Convolutional Networks for Action Recognition in Videos[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA, USA: MIT Press, 2014: 568-576. |
| 6 | Feichtenhofer Christoph, Pinz Axel, Zisserman A. Convolutional Two-stream Network Fusion for Video Action Recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2016: 1933-1941. |
| 7 | Feichtenhofer Christoph, Pinz Axel, Wildes Richard P. Spatiotemporal Residual Networks for Video Action Recognition[C]//Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2016: 3476-3484. |
| 8 | Feichtenhofer Christoph, Pinz Axel, Wildes Richard P. Spatiotemporal Multiplier Networks for Video Action Recognition[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2017: 7445-7454. |
| 9 | Tran D, Bourdev L, Fergus R, et al. Learning Spatiotemporal Features with 3D Convolutional Networks[C]//2015 IEEE International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE, 2015: 4489-4497. |
| 10 | Carreira João, Zisserman A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2017: 4724-4733. |
| 11 | Lin Ji, Gan Chuang, Han Song. TSM: Temporal Shift Module for Efficient Video Understanding[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE, 2019: 7082-7092. |
| 12 | Zhou Bolei, Andonian A, Oliva A, et al. Temporal Relational Reasoning in Videos[C]//Computer Vision-ECCV 2018. Cham: Springer International Publishing, 2018: 831-846. |
| 13 | Wang Limin, Xiong Yuanjun, Wang Zhe, et al. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition[C]//Computer Vision-ECCV 2016. Cham: Springer International Publishing, 2016: 20-36. |
| 14 | Qiu Zhaofan, Yao Ting, Mei Tao. Learning Spatio-temporal Representation with Pseudo-3D Residual Networks[C]//2017 IEEE International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE, 2017: 5534-5542. |
| 15 | Xie Saining, Sun Chen, Huang J, et al. Rethinking Spatiotemporal Feature Learning: Speed-accuracy Trade-offs in Video Classification[C]//Computer Vision-ECCV 2018. Cham: Springer International Publishing, 2018: 318-335. |
| 16 | Tran D, Wang Heng, Feiszli M, et al. Video Classification with Channel-separated Convolutional Networks[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE, 2019: 5551-5560. |
| 17 | Zolfaghari Mohammadreza, Singh Kamaljeet, Brox Thomas. ECO: Efficient Convolutional Network for Online Video Understanding[C]//Computer Vision-ECCV 2018. Cham: Springer International Publishing, 2018: 713-730. |
| 18 | Feichtenhofer C. X3D: Expanding Architectures for Efficient Video Recognition[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2020: 200-210. |
| 19 | Wang Xianyuan, Miao Zhenjiang, Zhang Ruyi, et al. I3D-LSTM: A New Model for Human Action Recognition[C]//IOP Conference Series: Materials Science and Engineering. Bristol, United Kingdom: IOP Publishing, 2019: 032035. |
| 20 | Tran D, Ray J, Shou Z, et al. Convnet Architecture Search for Spatiotemporal Feature Learning[J]. Computing Research Repository, 2017, 16(8): 1-12. |
| 21 | Li Yan, Ji Bin, Shi Xintian, et al. TEA: Temporal Excitation and Aggregation for Action Recognition[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2020: 906-915. |
| 22 | 罗会兰, 陈翰. 时空卷积注意力网络用于动作识别[J]. 计算机工程与应用, 2023, 59(9): 150-158. |
| Luo Huilan, Chen Han. Spatial-temporal Convolutional Attention Network for Action Recognition[J]. Computer Engineering and Applications, 2023, 59(9): 150-158. | |
| 23 | 吴丽君, 李斌斌, 陈志聪, 等. 3D多重注意力机制下的行为识别[J]. 福州大学学报(自然科学版), 2022, 50(1): 47-53. |
| Wu Lijun, Li Binbin, Chen Zhicong, et al. Action Recognition Under 3D Multiple Attention Mechanism[J]. Journal of Fuzhou University(Natural Science Edition), 2022, 50(1): 47-53. | |
| 24 | Zhu Yi, Lan Zhenzhong, Newsam S, et al. Hidden Two-stream Convolutional Networks for Action Recognition[C]//Computer Vision-ACCV 2018. Cham: Springer International Publishing, 2019: 363-378. |
| 25 | Feichtenhofer C, Fan Haoqi, Malik J, et al. SlowFast Networks for Video Recognition[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE, 2019: 6201-6210. |
| 26 | Wang Limin, Tong Zhan, Ji Bin, et al. TDN: Temporal Difference Networks for Efficient Action Recognition[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2021: 1895-1904. |
| 27 | Ma C Y, Chen M H, Kira Z, et al. TS-LSTM and Temporal-inception: Exploiting Spatiotemporal Dynamics for Activity Recognition[J]. Signal Processing: Image Communication, 2019, 71: 76-87. |
| 28 | Neimark D, Bar O, Zohar M, et al. Video Transformer Network[C]//2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW). Piscataway, NJ, USA: IEEE, 2021: 3156-3165. |
| 29 | Li Kunchang, Wang Yali, Gao Peng, et al. UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning[EB/OL]. (2022-02-08) [2022-04-04]. . |
| 30 | Arnab A, Dehghani M, Heigold G, et al. ViViT: A Video Vision Transformer[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE, 2021: 6816-6826. |
| 31 | Fan Haoqi, Xiong Bo, Mangalam K, et al. Multiscale Vision Transformers[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE, 2021: 6804-6815. |
| 32 | Li Yanghao, Wu Chaoyuan, Fan Haoqi, et al. MViTv2: Improved Multiscale Vision Transformers for Classification and Detection[EB/OL]. (2022-03-30) [2022-04-04]. . |
| 33 | Alfasly S, Lu Jian, Xu Chen, et al. Learnable Irrelevant Modality Dropout for Multimodal Action Recognition on Modality-specific Annotated Videos[EB/OL]. (2022-03-27) [2022-04-04]. . |
| 34 | He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep Residual Learning for Image Recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2016: 770-778. |
| 35 | Kay W, Carreira João, Simonyan K, et al. The Kinetics Human Action Video Dataset[EB/OL]. (2017-05-19) [2022-04-04]. . |
| 36 | Goyal Raghav, Samira Ebrahimi Kahou, Michalski Vincent, et al. The "Something Something" Video Database for Learning and Evaluating Visual Common Sense[C]//2017 IEEE International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE, 2017: 5843-5851. |
| 37 | Soomro K, Zamir A R, Shah M. UCF101: A Dataset of 101 Human Actions Classes from Videos in the Wild[EB/OL]. (2013-12-03) [2022-04-04]. . |
| 38 | Kuehne H, Jhuang H, Garrote E, et al. HMDB: A Large Video Database for Human Motion Recognition[C]//2011 International Conference on Computer Vision. Piscataway, NJ, USA: IEEE, 2011: 2556-2563. |
| 39 | Deng Jia, Dong Wei, Socher R, et al. ImageNet: A Large-scale Hierarchical Image Database[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2009: 248-255. |
| 40 | Wang Xiaolong, Gupta A. Videos as Space-time Region Graphs[C]//Computer Vision-ECCV 2018: 15th European Conference. Heidelberg: Springer-Verlag, 2018: 413-431. |
| 41 | Zhou Bolei, Khosla A, Lapedriza A, et al. Learning Deep Features for Discriminative Localization[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2016: 2921-2929. |
| [1] | 王军, 刘敏, 张啸川, 丁一珊, 冯居辉, 庄晔. 基于神经网络的无人车动力学建模方法[J]. 系统仿真学报, 2026, 38(4): 932-947. |
| [2] | 陈燕军, 周敏, 查蒙, 张美洲. 基于CCL-YOLOv8的汽车轮毂表面缺陷检测算法研究与分析[J]. 系统仿真学报, 2026, 38(3): 670-686. |
| [3] | 冯雪健, 丁晗, 童逸琦, 霍超颖, 张燕津. 一种目标典型航迹形状仿真及多视角识别算法[J]. 系统仿真学报, 2026, 38(3): 725-735. |
| [4] | 刘沛津, 张闽心, 何林, 孙艺阁, 苏庭琪. 面向城市复杂环境视觉地点识别算法研究[J]. 系统仿真学报, 2026, 38(3): 818-828. |
| [5] | 杨灿, 陈凯, 朱峰. 多约束条件下基于强化学习的无人机团队定向优化方法[J]. 系统仿真学报, 2026, 38(2): 360-371. |
| [6] | 王继恒, 胡阳, 宋子秋, 房方, 刘吉臻. 基于多模态混合深度学习的大型风电机组入流风场预测[J]. 系统仿真学报, 2026, 38(2): 501-517. |
| [7] | 邹长军, 葛志宇, 钟晨曦. 基于时空Swin Transformer的流固耦合交互序列图像预测网络[J]. 系统仿真学报, 2026, 38(1): 112-124. |
| [8] | 江明, 何韬. 基于深度强化学习的带容量约束车辆路径问题求解[J]. 系统仿真学报, 2025, 37(9): 2177-2187. |
| [9] | 姜彦吉, 张颖阳, 董浩, 张晓光, 王美惠. 基于实例关联的暗光下车道线检测[J]. 系统仿真学报, 2025, 37(9): 2188-2199. |
| [10] | 马仑, 杨跃, 王迨贺, 廖桂生, 李幸. 联合自注意力机制与权值共享的人体行为识别模型[J]. 系统仿真学报, 2025, 37(9): 2409-2419. |
| [11] | 鲁斌, 杨烜, 杨振宇, 高啸天. 自适应采样与重影多尺度特征融合的轻量化焊缝缺陷检测[J]. 系统仿真学报, 2025, 37(8): 1978-1990. |
| [12] | 刘子龙, 张磊. 自然环境下改进YOLOv5对小目标苹果的检测[J]. 系统仿真学报, 2025, 37(8): 2124-2138. |
| [13] | 王秉珩, 刘庭瑞, 杨帆, 张欢, 李伟, 马萍, 杨明. 仿真可信度智能评估需求及方法研究[J]. 系统仿真学报, 2025, 37(7): 1710-1722. |
| [14] | 陈坤, 陈亮, 谢济铭, 刘丰博, 陈泰熊, 位路宽. 基于LSTM-GNN的畸形交叉口自适应信号控制仿真研究[J]. 系统仿真学报, 2025, 37(6): 1343-1351. |
| [15] | 王子怡, 张凯, 钱殿伟, 刘玉贞. 一种基于DRL的分布式装备体系优选方法[J]. 系统仿真学报, 2025, 37(6): 1565-1573. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
