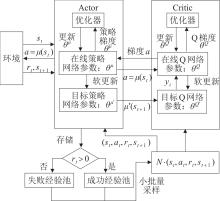
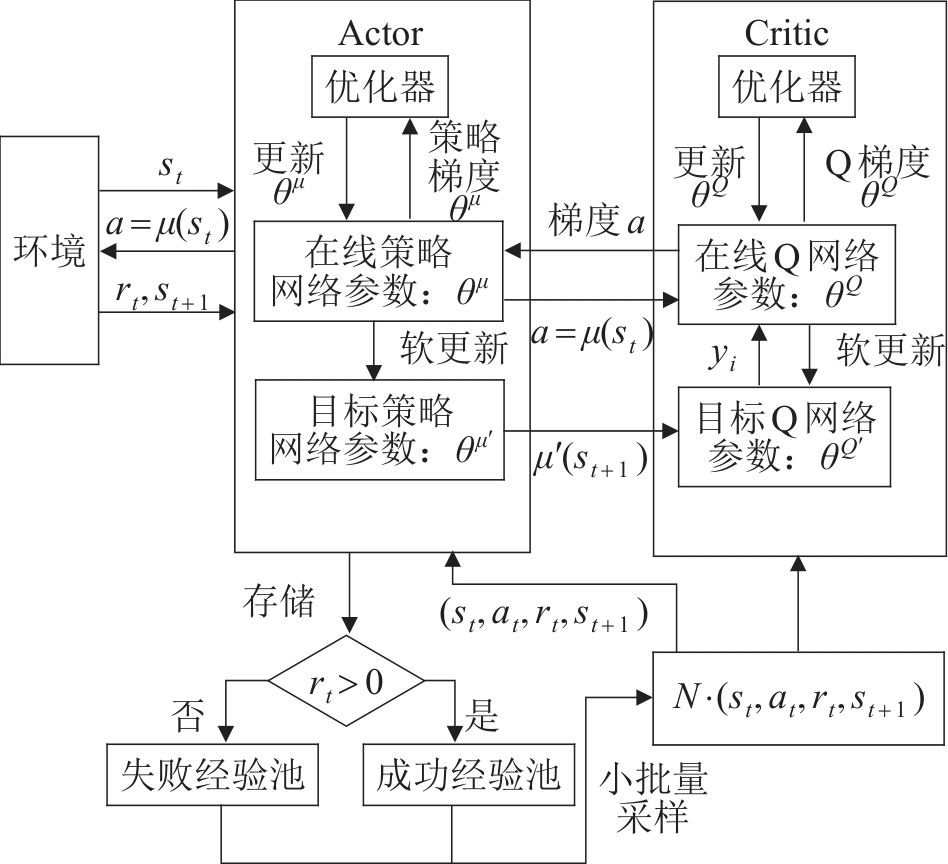
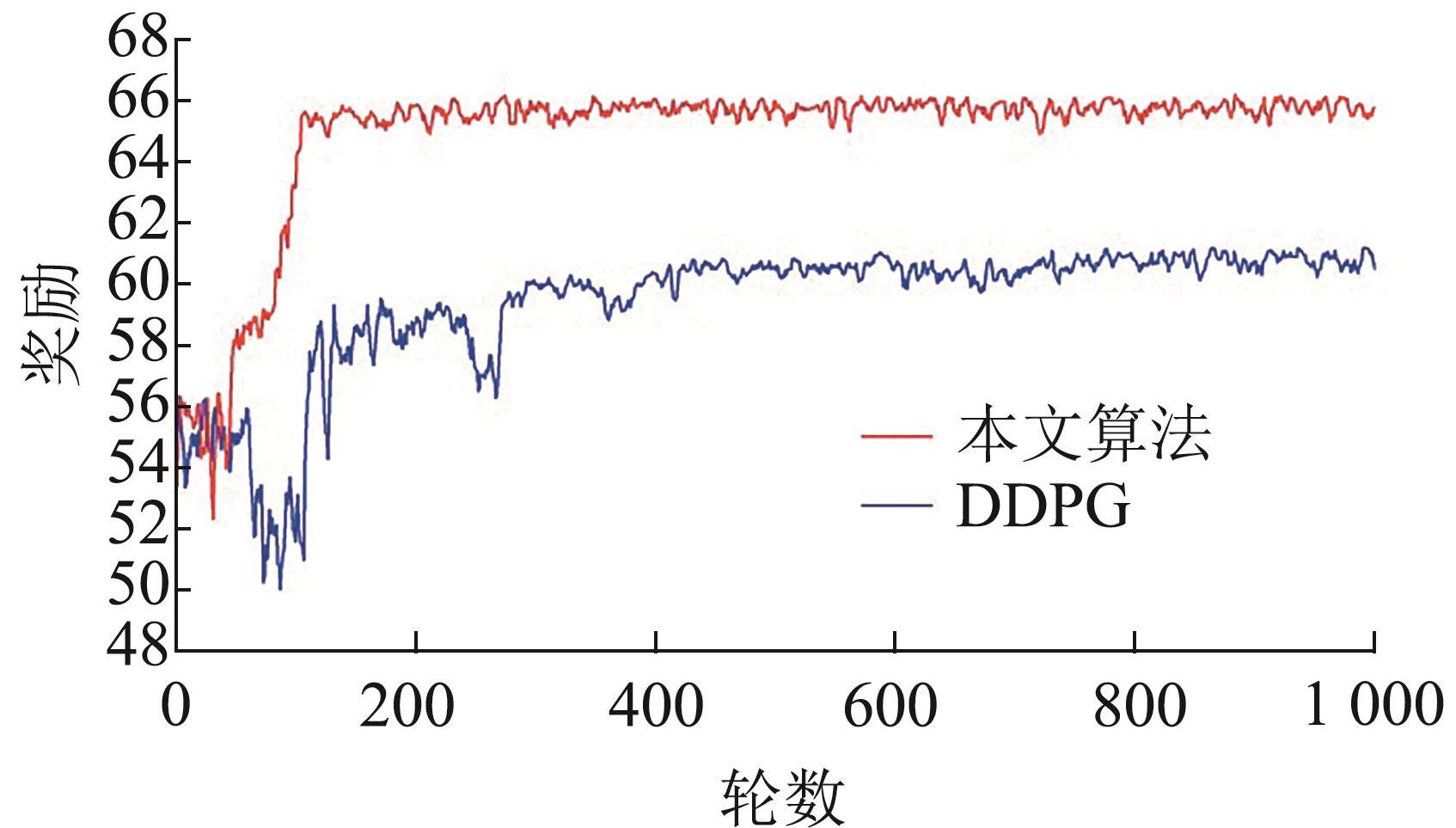
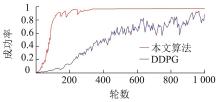
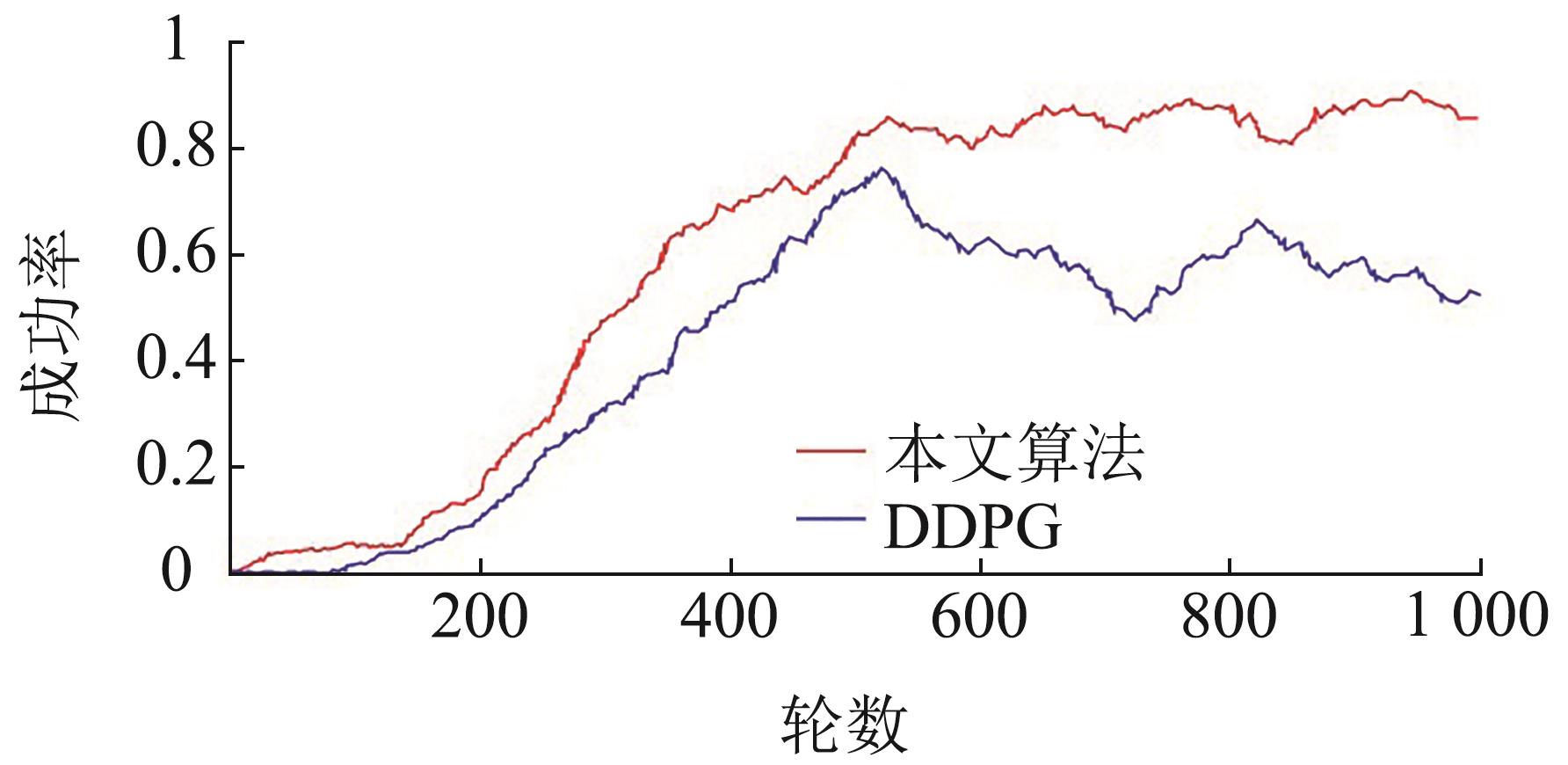
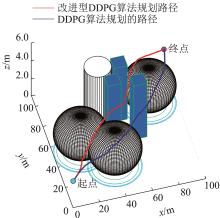
| 1 |
Zhang Ming, Li Wei, Wang Mengmeng, et al. Helicopter-UAVs Search and Rescue Task Allocation Considering UAVs Operating Environment and Performance[J]. Computers & Industrial Engineering, 2022, 167: 107994.
|
| 2 |
Xing Linjie, Fan Xiaoyan, Dong Yaxin, et al. Multi-UAV Cooperative System for Search and Rescue Based on YOLOv5[J]. International Journal of Disaster Risk Reduction, 2022, 76: 102972.
|
| 3 |
Raptis Emmanuel K, Krestenitis Marios, Egglezos Konstantinos, et al. End-to-end Precision Agriculture UAV-based Functionalities Tailored to Field Characteristics[J]. Journal of Intelligent & Robotic Systems, 2023, 107(2): 23.
|
| 4 |
Zhou Maowu, Chen Hongbin, Shu Lei, et al. UAV-assisted Sleep Scheduling Algorithm for Energy-efficient Data Collection in Agricultural Internet of Things[J]. IEEE Internet of Things Journal, 2022, 9(13): 11043-11056.
|
| 5 |
Asadzadeh Saeid, Wilson José de Oliveira, Carlos Roberto de Souza Filho. UAV-based Remote Sensing for the Petroleum Industry and Environmental Monitoring: State-of-the-art and Perspectives[J]. Journal of Petroleum Science and Engineering, 2022, 208, Part D: 109633.
|
| 6 |
Lee H W. Research on Multi-functional Logistics Intelligent Unmanned Aerial Vehicle[J]. Engineering Applications of Artificial Intelligence, 2022, 116: 105341.
|
| 7 |
Lu Ziyi, Yu Na, Wang Xuehe. Incentive Mechanism and Path Planning for Unmanned Aerial Vehicle (UAV) Hitching over Traffic Networks[J]. Future Generation Computer Systems, 2023, 145: 521-535.
|
| 8 |
Lippiello Vincenzo, Cacace Jonathan. Robust Visual Localization of a UAV over a Pipe-rack Based on the Lie Group SE(3)[J]. IEEE Robotics and Automation Letters, 2022, 7(1): 295-302.
|
| 9 |
Liu Kangcheng, Chen B M. Industrial UAV-based Unsupervised Domain Adaptive Crack Recognitions: From Database Towards Real-site Infrastructural Inspections[J]. IEEE Transactions on Industrial Electronics, 2023, 70(9): 9410-9420.
|
| 10 |
Chai Xuzhao, Zheng Zhishuai, Xiao Junming, et al. Multi-strategy Fusion Differential Evolution Algorithm for UAV Path Planning in Complex Environment[J]. Aerospace Science and Technology, 2022, 121: 107287.
|
| 11 |
Yan Yuehao, Zhiying Lü, Yuan Jinbiao, et al. Obstacle Avoidance for Multi-UAV System with Optimized Artificial Potential Field Algorithm[J]. International Journal of Robotics and Automation, 2021, 36: 1-7.
|
| 12 |
Zu Linan, Wang Zhipeng, Liu Cong, et al. Research on UAV Path Planning Method Based on Improved HPO Algorithm in Multitask Environment[J]. IEEE Sensors Journal, 2023, 23(17): 19881-19893.
|
| 13 |
Xue Yuntao, Chen Weisheng. A UAV Navigation Approach Based on Deep Reinforcement Learning in Large Cluttered 3D Environments[J]. IEEE Transactions on Vehicular Technology, 2023, 72(3): 3001-3014.
|
| 14 |
Zhao Jinduo, Gan Zhigao, Liang Jiakai, et al. Path Planning Research of a UAV Base Station Searching for Disaster Victims' Location Information Based on Deep Reinforcement Learning[J]. Entropy, 2022, 24(12): 1767.
|
| 15 |
Zhang Sitong, Li Yibing, Ye Fang, et al. A Hybrid Human-in-the-loop Deep Reinforcement Learning Method for UAV Motion Planning for Long Trajectories with Unpredictable Obstacles[J]. Drones, 2023, 7(5): 311.
|
| 16 |
张云燕, 魏瑶, 刘昊, 等. 基于深度强化学习的端到端无人机避障决策[J]. 西北工业大学学报, 2022, 40(5): 1055-1064.
|
|
Zhang Yunyan, Wei Yao, Liu Hao, et al. End-to-end UAV Obstacle Avoidance Decision Based on Deep Reinforcement Learning[J]. Journal of Northwestern Polytechnical University, 2022, 40(5): 1055-1064.
|
| 17 |
文超, 董文瀚, 解武杰, 等. 基于解耦型MADDPG的无人机集群自主跟踪与避障[J]. 飞行力学, 2022, 40(6): 24-31.
|
|
Wen Chao, Dong Wenhan, Xie Wujie, et al. Autonomous Tracking and Obstacle Avoidance of UAV Swarms Based on Decomposed MADDPG[J]. Flight Dynamics, 2022, 40(6): 24-31.
|