

Journal of System Simulation ›› 2025, Vol. 37 ›› Issue (9): 2420-2430.doi: 10.16182/j.issn1004731x.joss.24-0369
• Papers • Previous Articles Next Articles
Ni Peilong, Mao Pengjun, Wang Ning, Yang Mengjie
Received:2024-04-09
Revised:2024-04-22
Online:2025-09-18
Published:2025-10-24
Contact:
Mao Pengjun
CLC Number:
Ni Peilong, Mao Pengjun, Wang Ning, Yang Mengjie. Robot Path Planning Based on Improved A-DDQN Algorithm[J]. Journal of System Simulation, 2025, 37(9): 2420-2430.
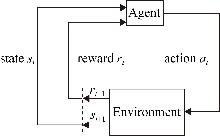
Fig. 1
Basic framework of reinforcement learning
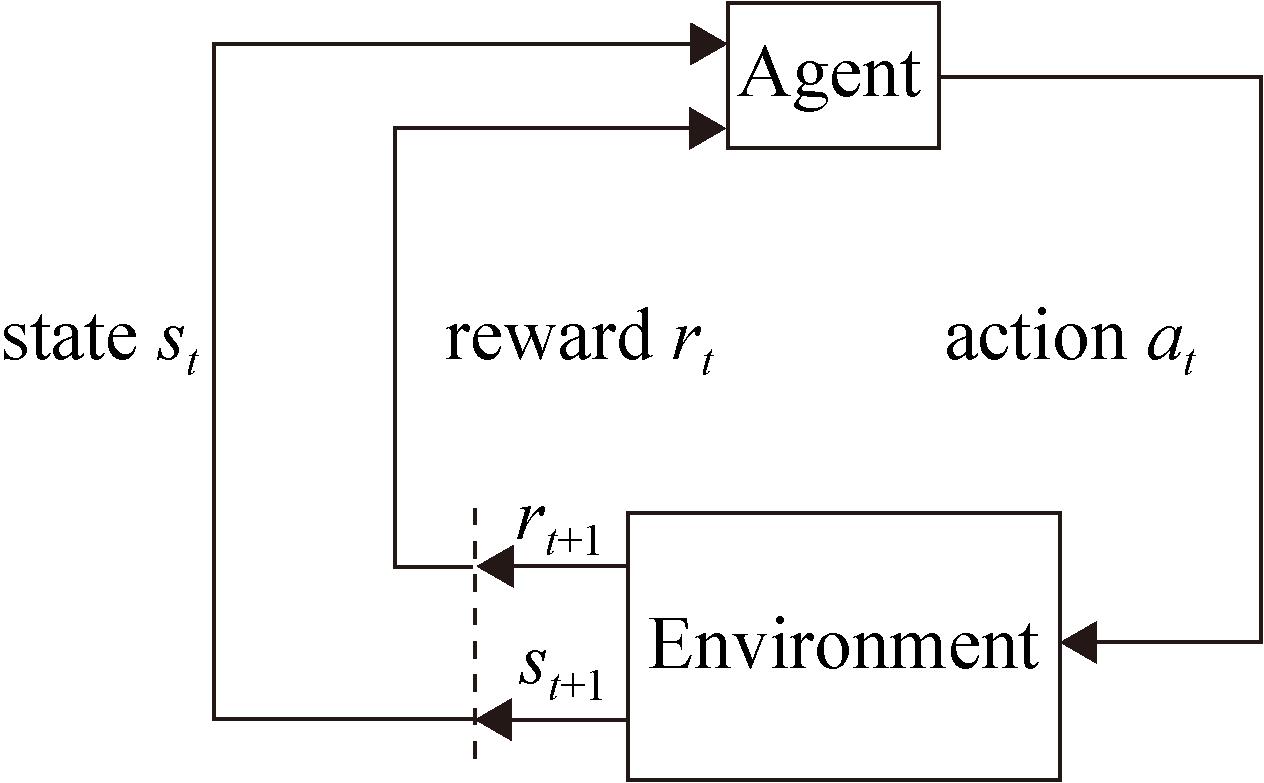
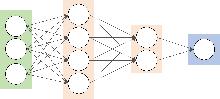
Fig. 2
Neural network structure
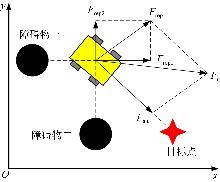
Fig. 3
Artificial potential field
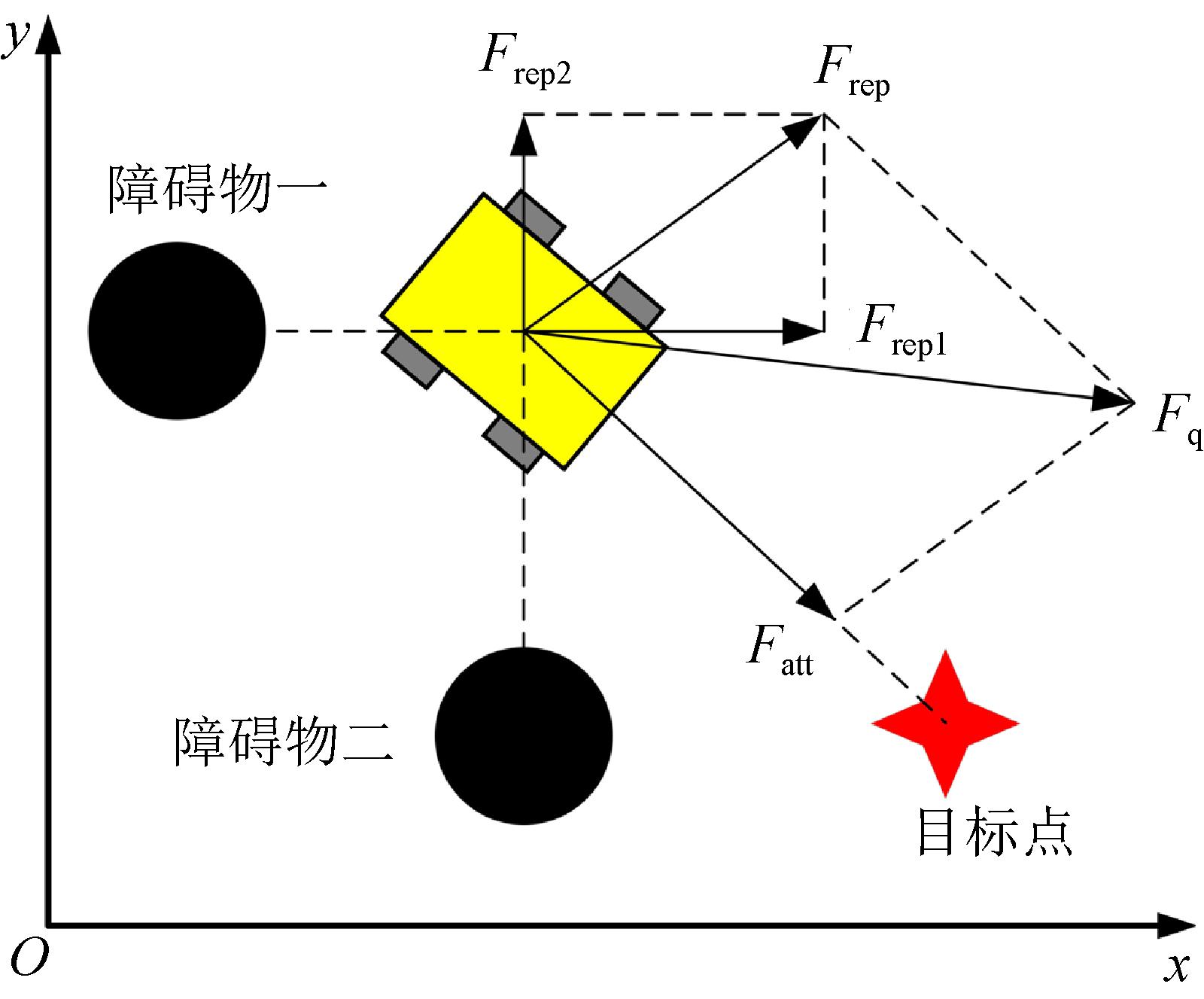
Fig. 4
A-DDQN overall framework diagram
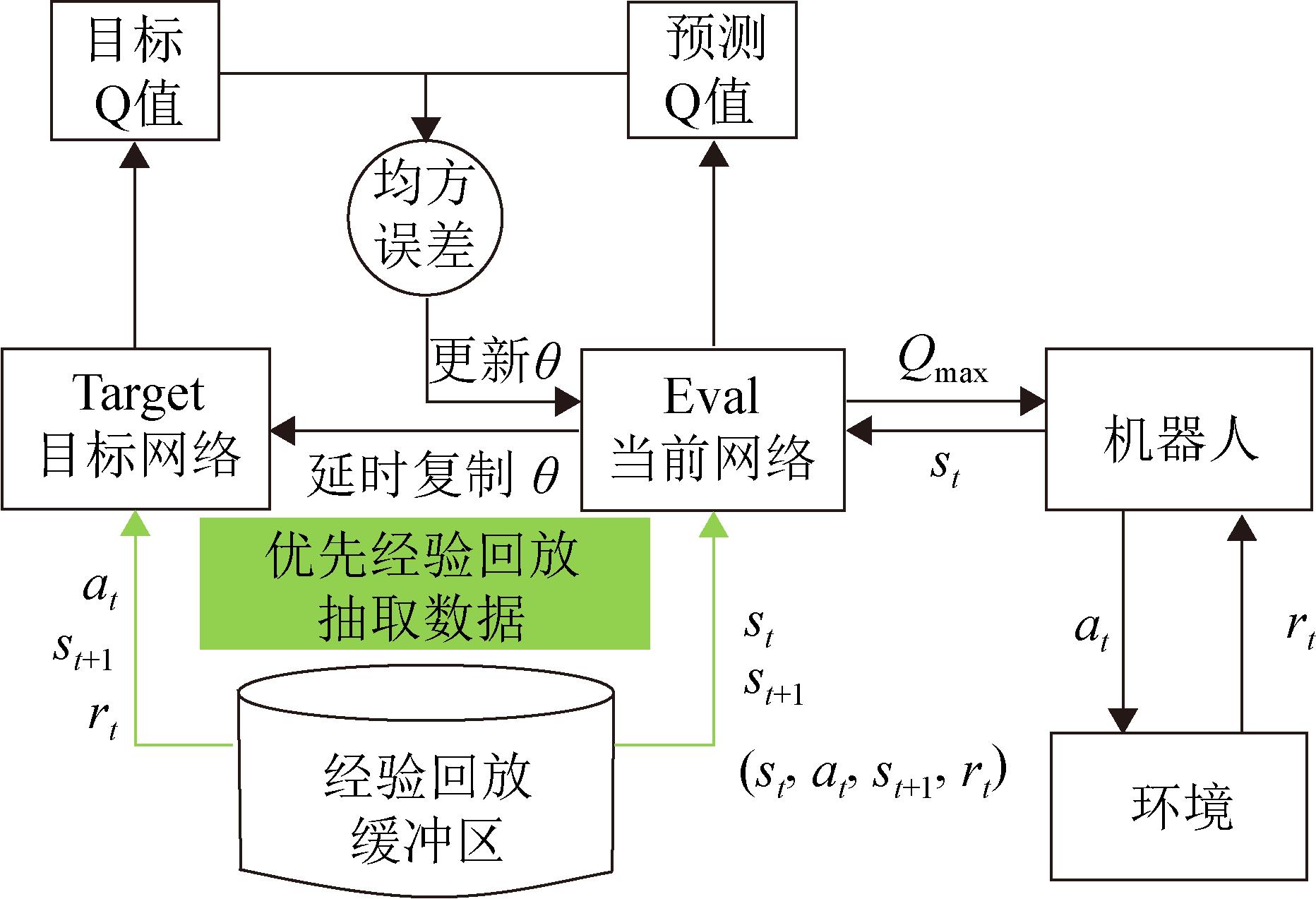
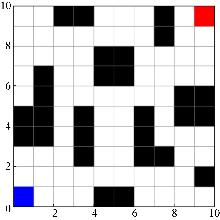
Fig. 5
Simulation map
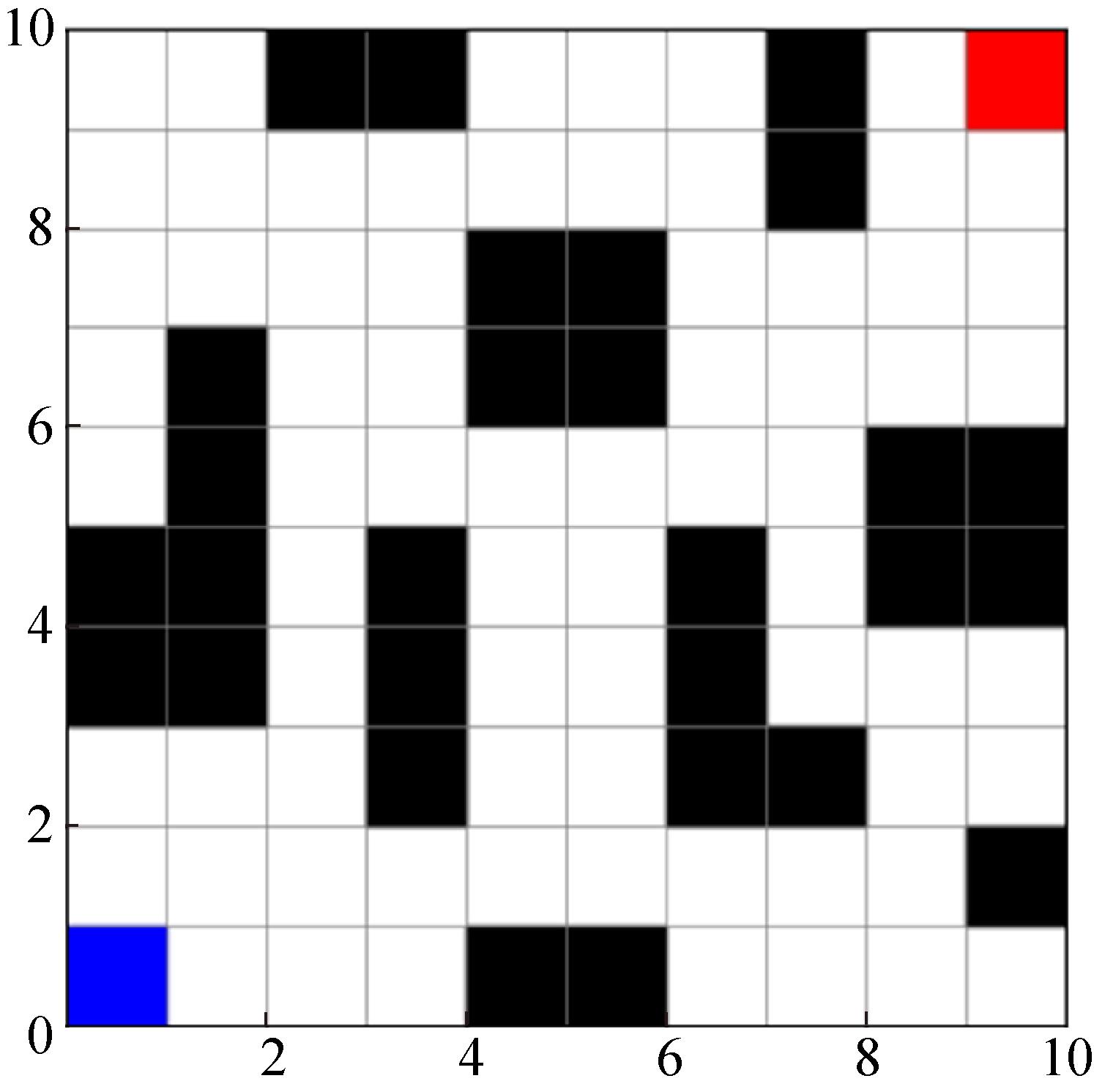
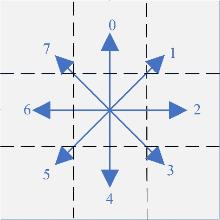
Fig. 6
Robot movement direction
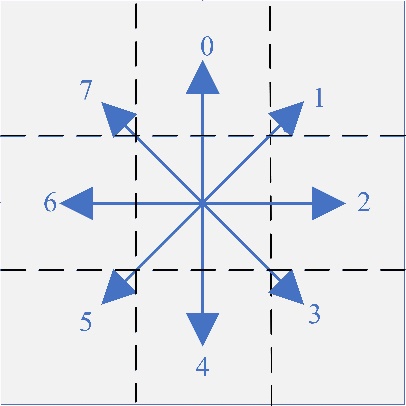
Table 1
Hyperparameter settings
| 超参数 | 数值 | 超参数 | 数值 |
|---|---|---|---|
| 折扣率 | 0.9 | 动作空间大小 | 8 |
| 学习率 | 0.1 | 迭代次数 | 200 |
| 初始探索率 | 1 | 引力奖励常数 | 0.000 01 |
| 最小探索率 | 0.1 | 排斥奖励常数 | 0.05 |
| 探索衰减值 | 0.998 | 方向奖励常数 | 0.05 |
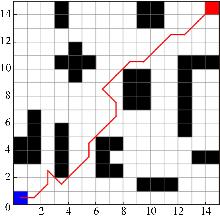
Fig. 7
Traditional algorithm path planning effect
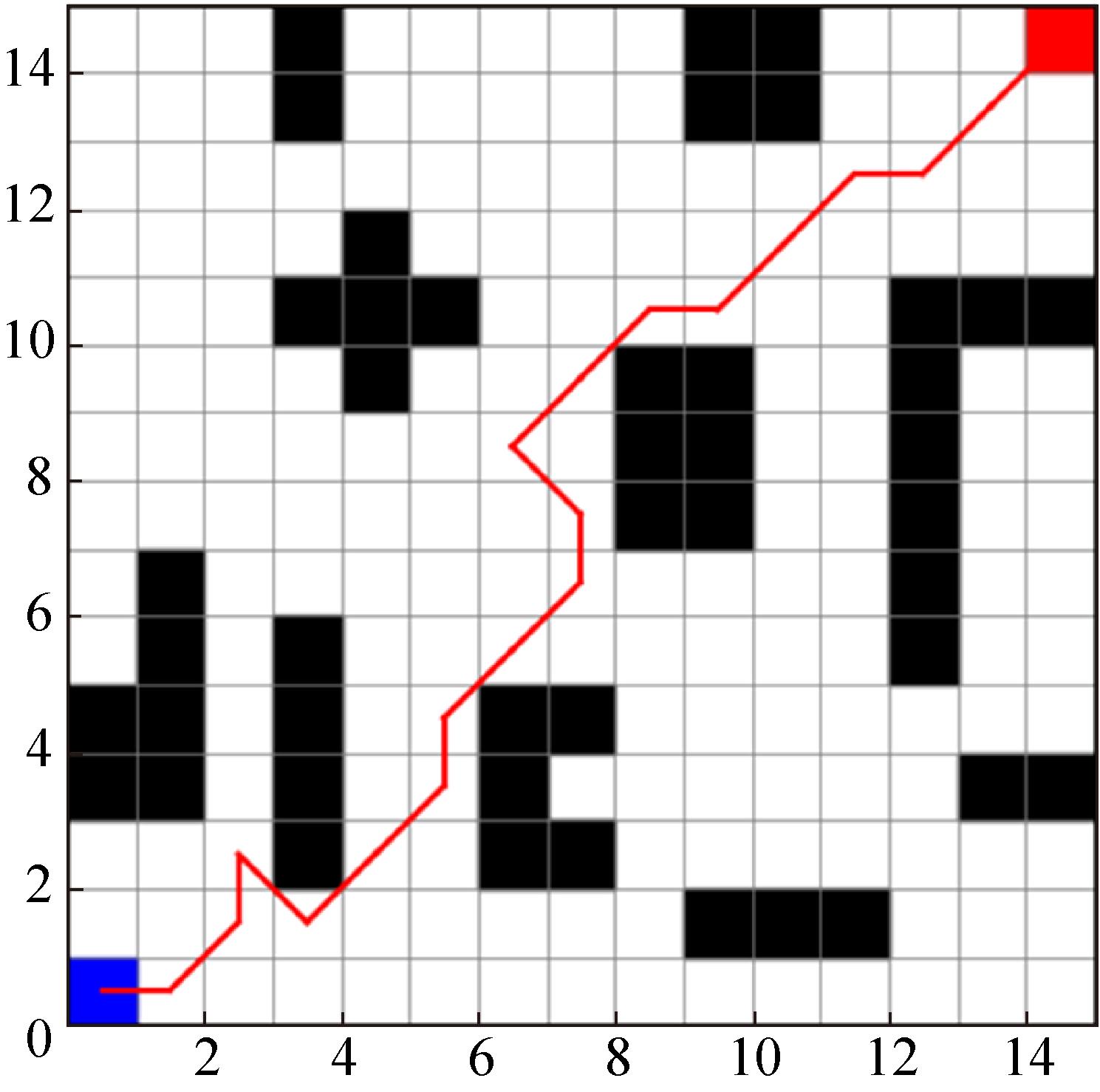
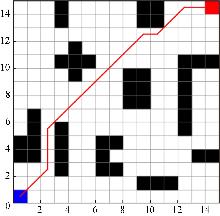
Fig. 8
Improvement algorithm path planning effect
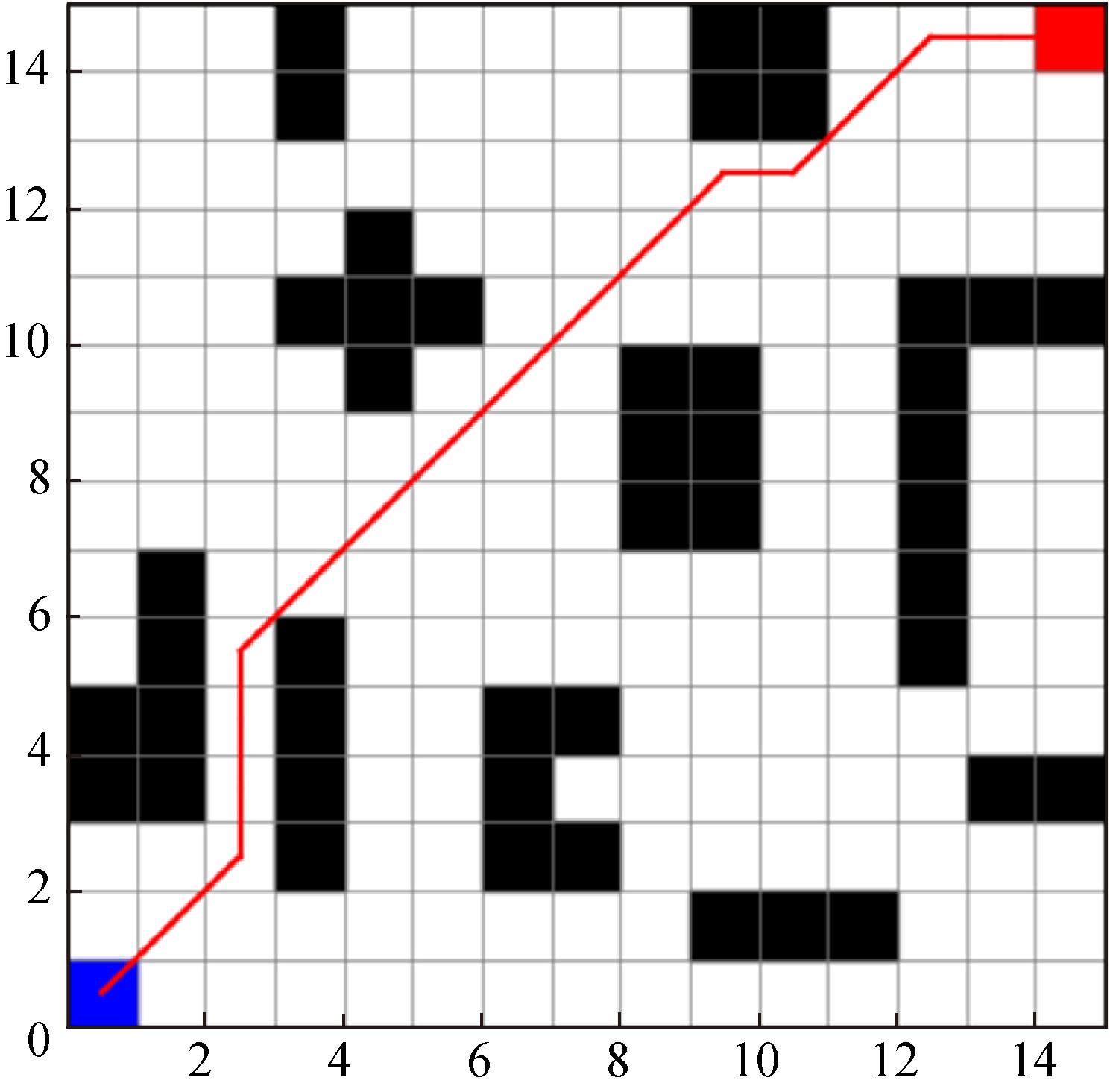
Fig. 9
Reward comparison curve
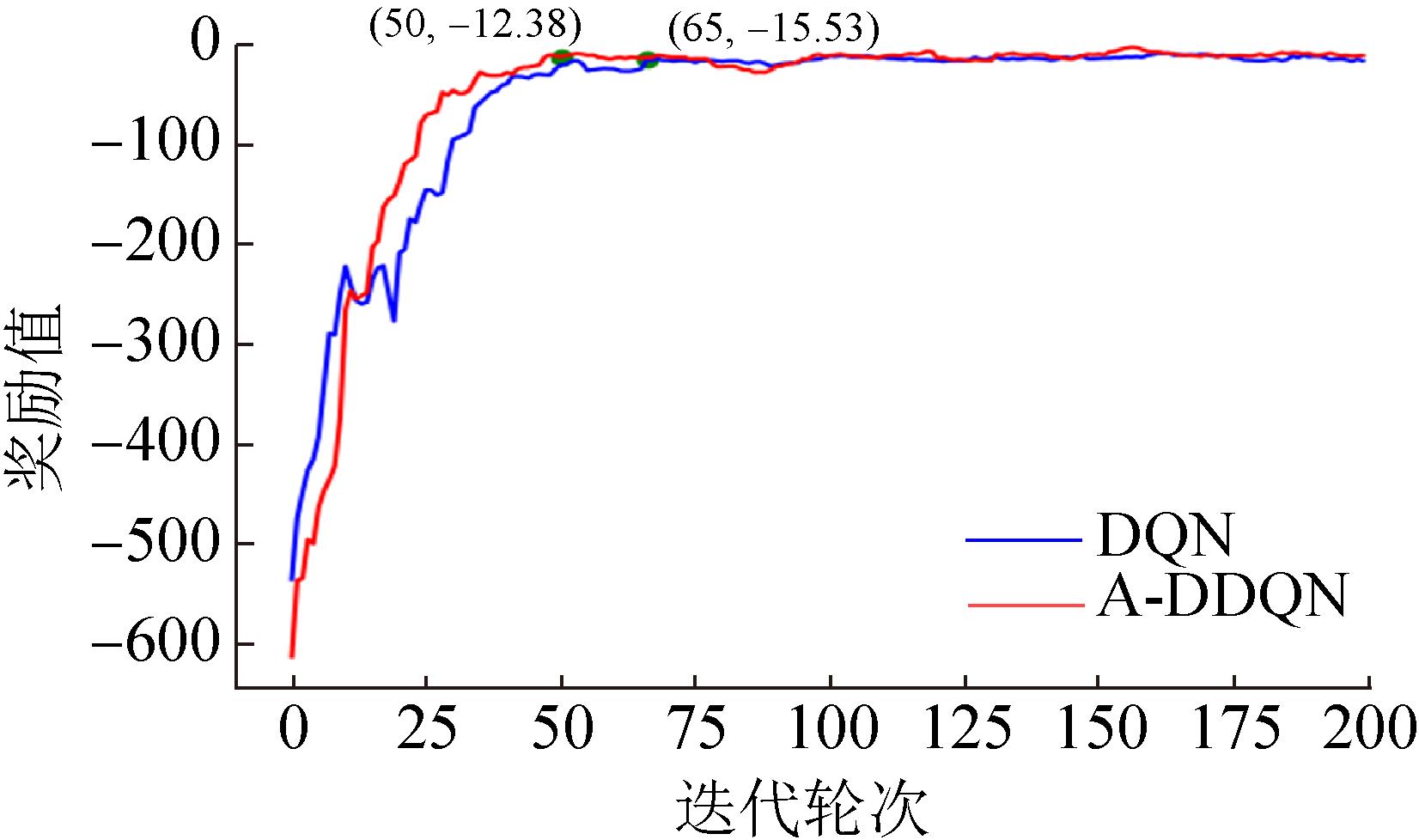
Fig. 10
Comparison curve of steps
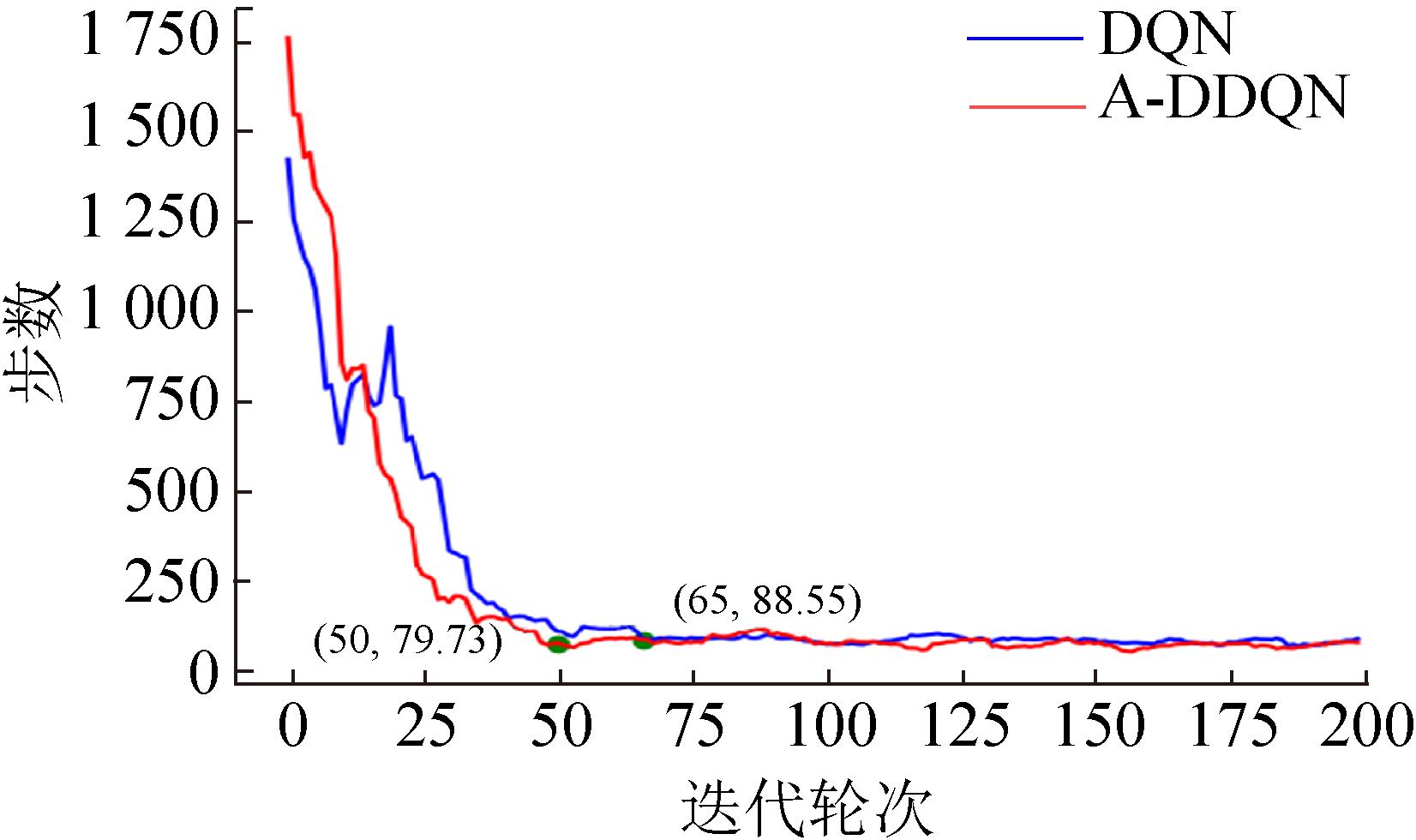
Table 2
Comparison of algorithm results indicators
| 算法 | 路径长度/m | 迭代轮次 | 拐点个数 |
|---|---|---|---|
| 性能提升/% | 11.5 | 23.1 | 61.5 |
| DQN | 24.4 | 65 | 13 |
| A-DDQN | 21.6 | 50 | 5 |
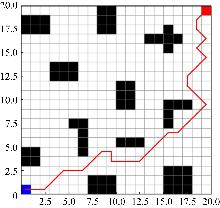
Fig. 11
Traditional algorithm path planning effect
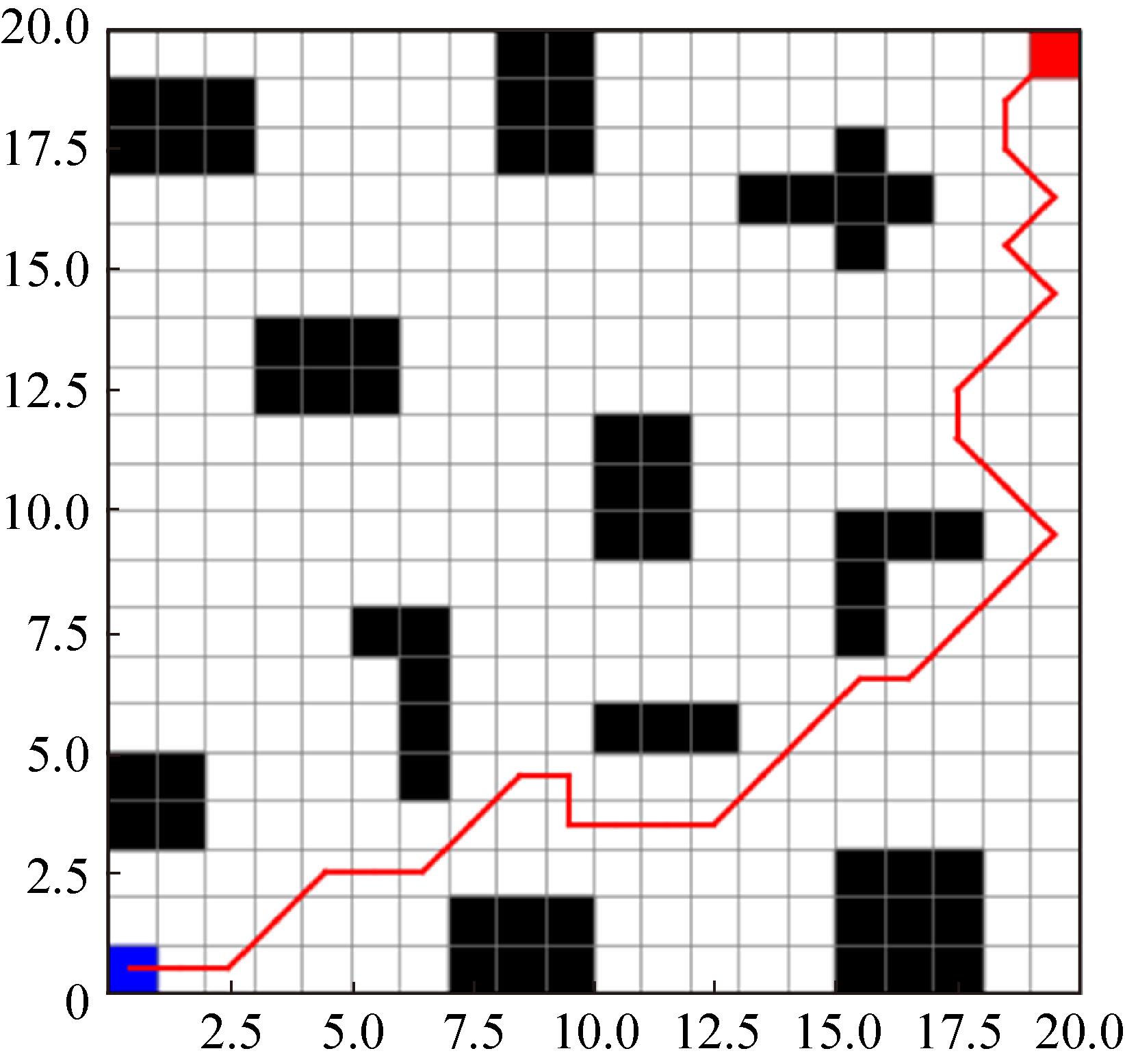
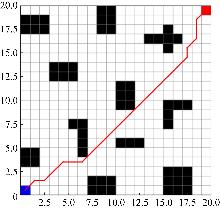
Fig. 12
Improvement algorithm path planning effect
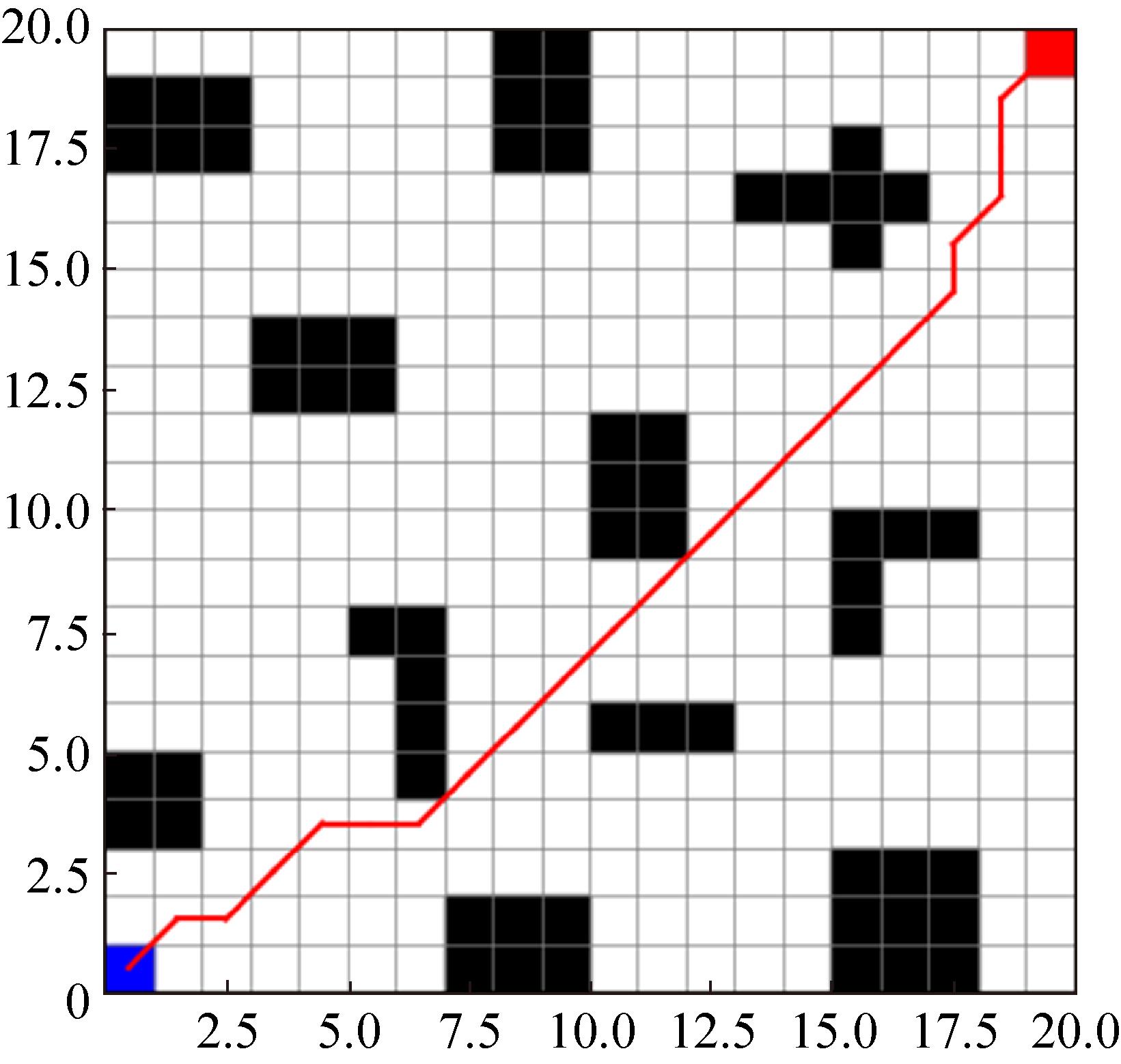
Fig. 13
Reward comparison curve
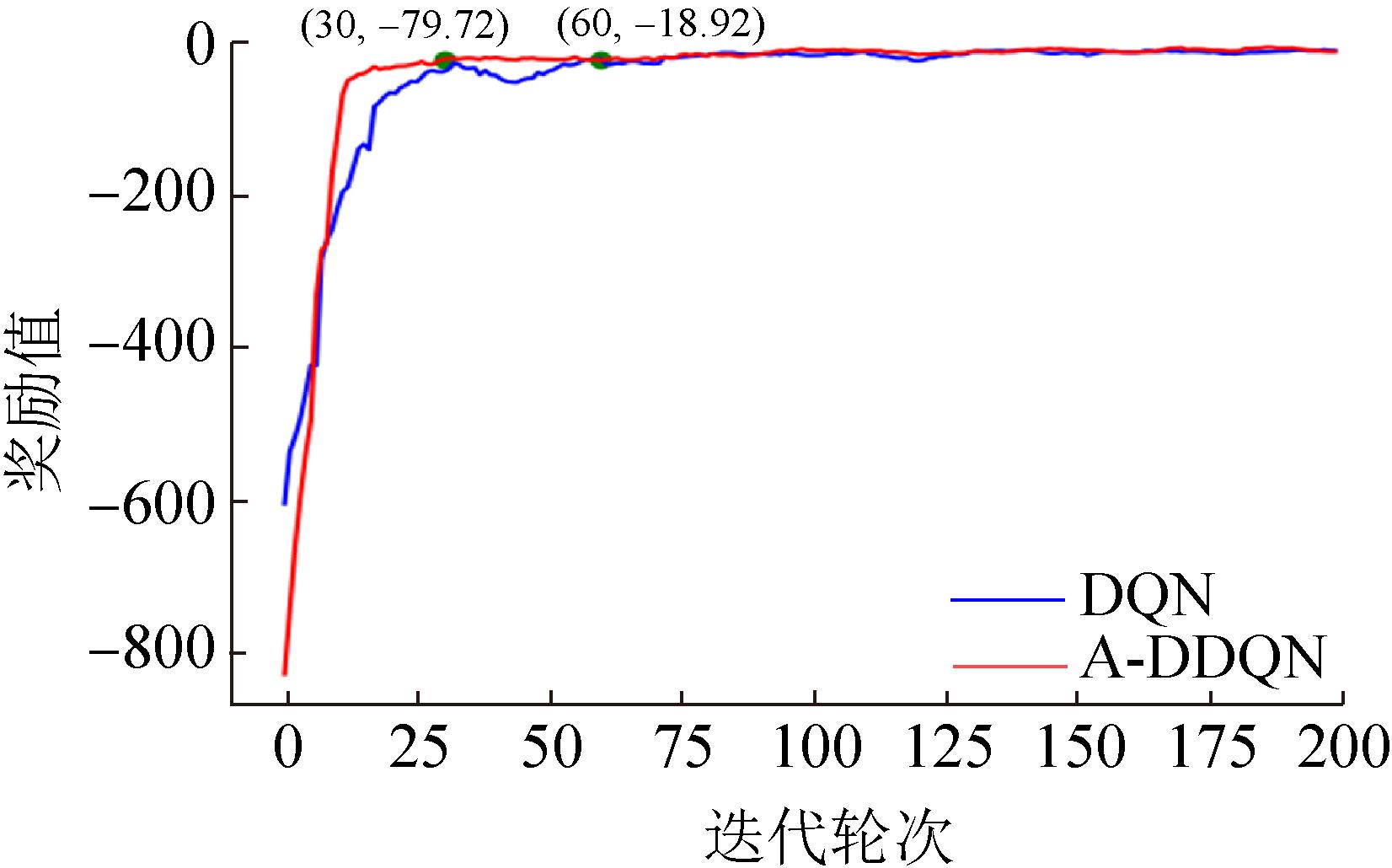
Fig. 14
Comparison curve of steps
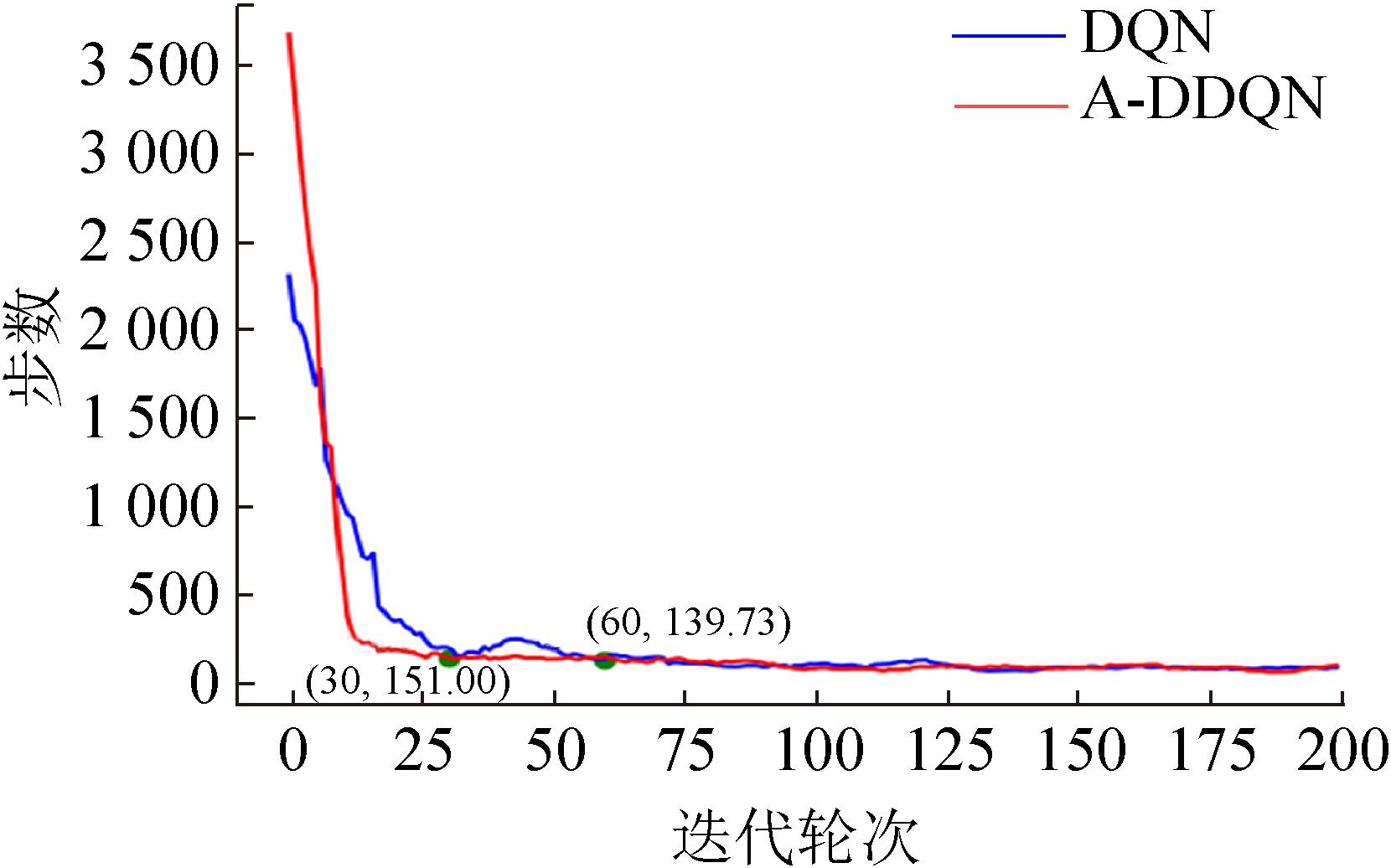
Table 3
Comparison of algorithm results indicators
| 算法 | 路径长度/m | 迭代轮次 | 拐点个数 |
|---|---|---|---|
| 性能提升/% | 19.4 | 50.0 | 52.9 |
| DQN | 35.5 | 60 | 17 |
| A-DDQN | 28.6 | 30 | 8 |
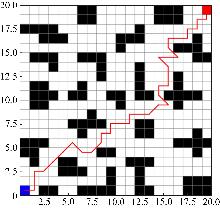
Fig. 15
Traditional algorithm path planning effect
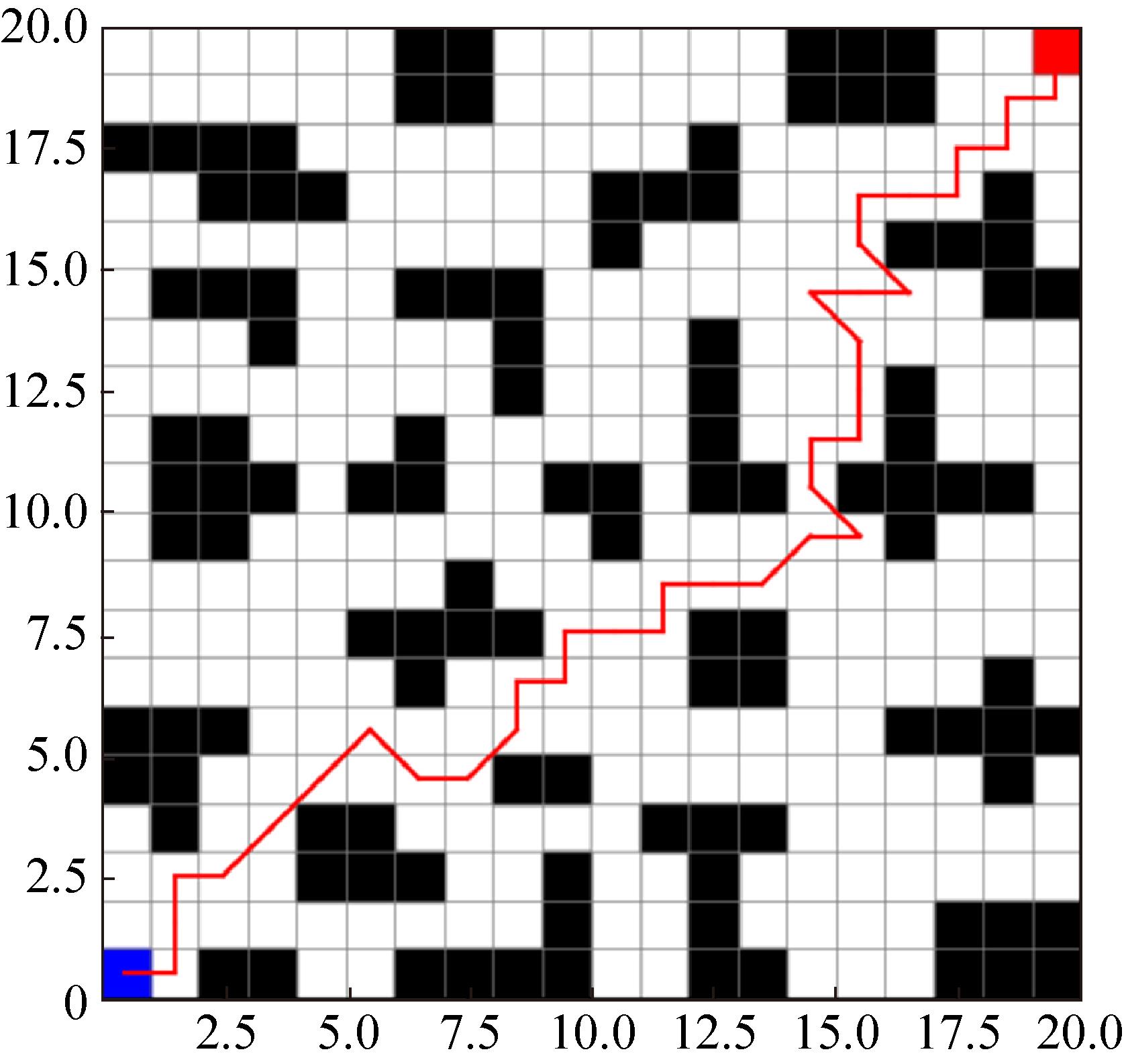
Fig. 16
Improvement algorithm path planning effect
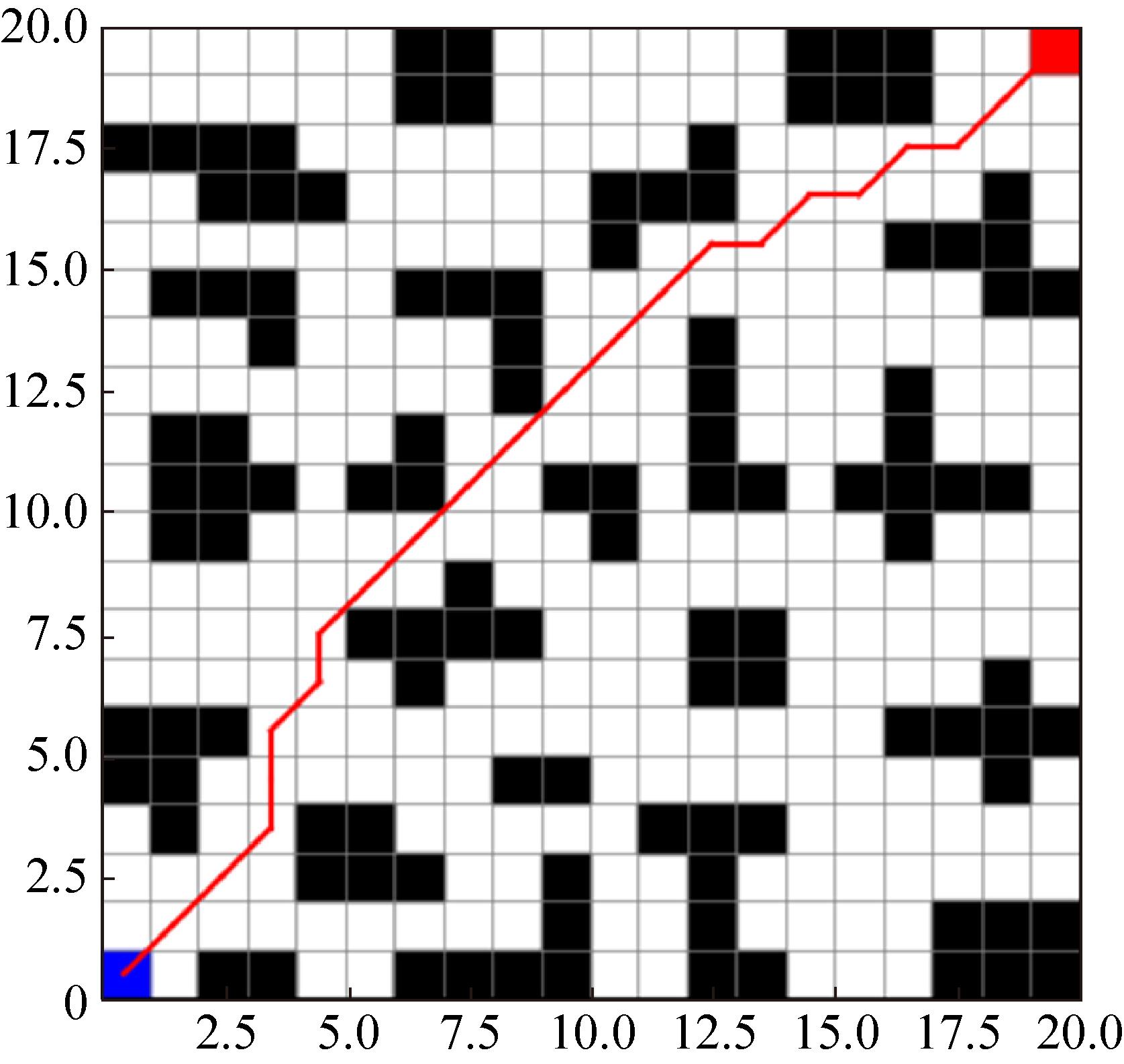
Fig. 17
Reward comparison curve
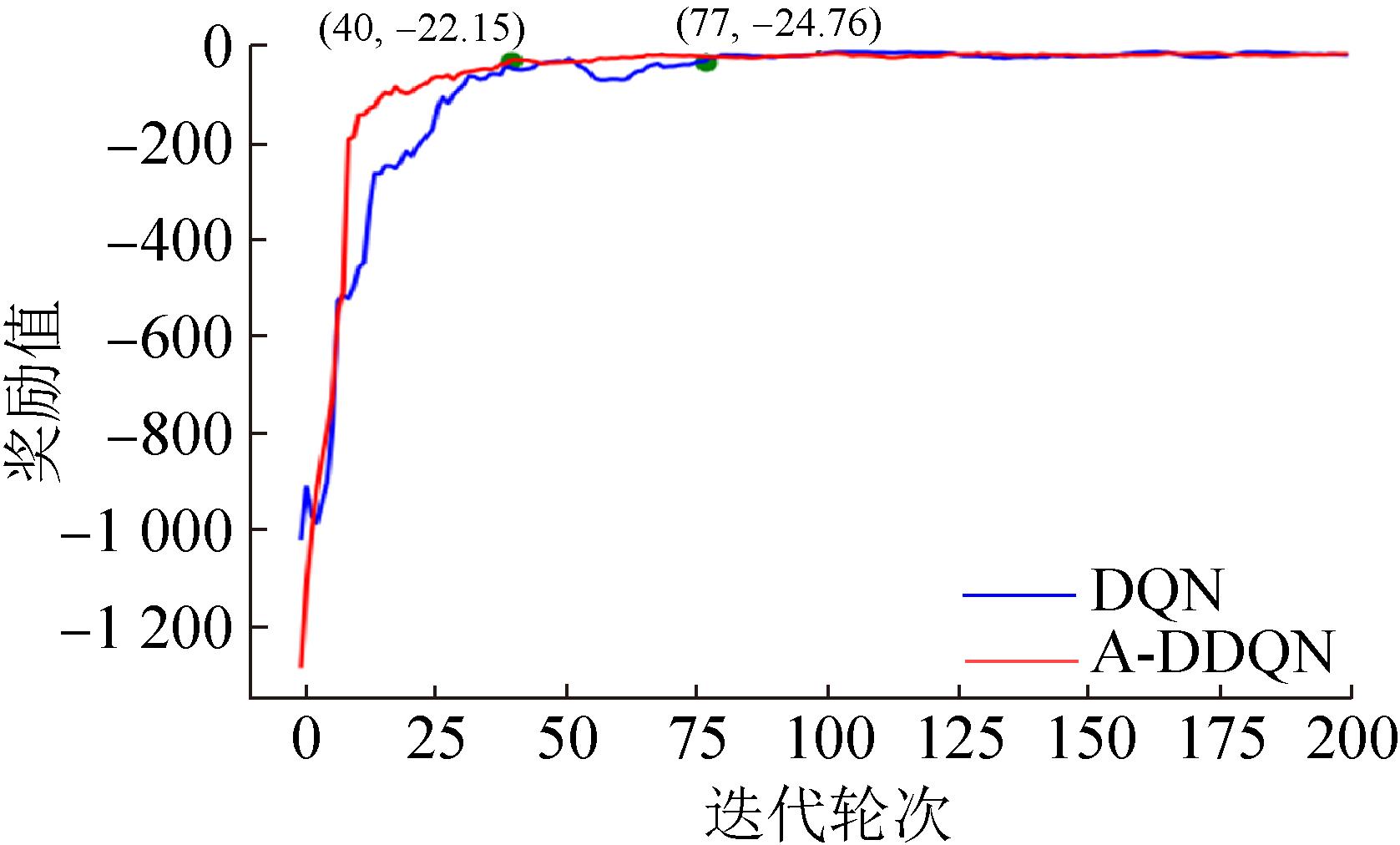
Fig. 18
Comparison curve of steps
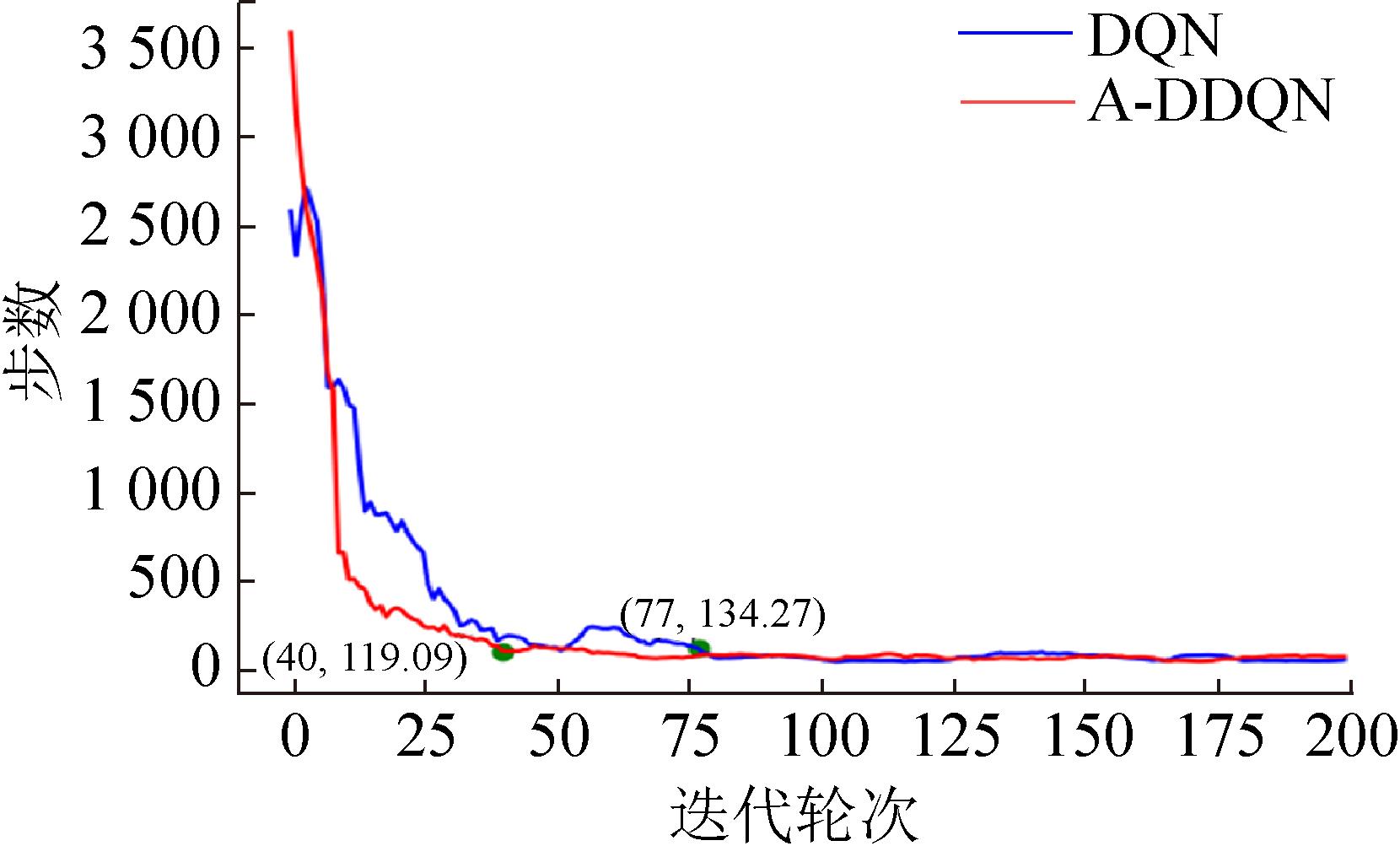
Table 4
Comparison of algorithm results indicators
| 算法 | 路径长度/m | 迭代轮次 | 拐点个数 |
|---|---|---|---|
| 性能提升/% | 29.7 | 48.1 | 64.3 |
| DQN | 40.7 | 77 | 28 |
| A-DDQN | 28.6 | 40 | 10 |
| [1] |
林桂娟, 李子涵, 王宇. 基于全局关键点提取的改进A*算法全局路径规划研究[J]. 系统仿真学报, 2025, 37(3): 667-678.
|
|
|
|
| [2] |
张瑞, 周丽, 刘正洋. 融合RRT*与DWA算法的移动机器人动态路径规划[J]. 系统仿真学报, 2024, 36(4): 957-968.
|
|
|
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
邓向阳, 张立民, 方伟, 等. 基于双向汇聚引导蚁群算法的机器人路径规划[J]. 系统仿真学报, 2022, 34(5): 1101-1108.
|
|
|
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
李子怡, 胡祥涛, 张勇乐, 等. 基于虚拟目标制导的自适应Q学习路径规划算法[J]. 计算机集成制造系统, 2024, 30(2): 553-568.
|
|
|
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
张晨, 蒋文英, 陈思源, 等. 基于双层DQN的多智能体路径规划[J]. 中国图象图形学报, 2023, 28(7): 2167-2181.
|
|
|
|
| [16] |
韩玲, 张晖, 方若愚, 等. 基于改进深度强化学习的全局路径规划策略[J]. 汽车安全与节能学报, 2023, 14(2): 202-211.
|
|
|
|
| [17] |
李明, 叶汪忠, 燕洁华. 基于深度强化学习的沙漠机器人路径规划[J]. 系统仿真学报, 2024, 36(12): 2917-2925.
|
|
|
|
| [18] |
|
| [19] |
|
| [20] |
段建民, 陈强龙. 利用先验知识的Q-Learning路径规划算法研究[J]. 电光与控制, 2019, 26(9): 29-33.
|
|
|
| [1] | Liang Longxiao, Mao Jianlin, Wang Niya, Fang Chengyuan, Zhou Wenna. Multi-agent CBS Path Planning Algorithm Based on Minimum Planning Margin First [J]. Journal of System Simulation, 2026, 38(5): 1159-1173. |
| [2] | Zhang Dingkun, Liang Haizhao. Hierarchical Motion Planning of Mobile Robot Based on Dynamic Corridor Inflation and Convex Optimization [J]. Journal of System Simulation, 2026, 38(5): 1383-1407. |
| [3] | Meng Wenlong, Pu Yanbo, Gong Ya. AUV Path Planning Integrating Local-global Strategies in Unknown Environments [J]. Journal of System Simulation, 2026, 38(4): 889-902. |
| [4] | Li Dequan, Xiong Wan. Robot Path Planning by Reinforcement Learning Based on SAC3Q-HDM [J]. Journal of System Simulation, 2026, 38(3): 714-724. |
| [5] | Xie Jun, Zhang Qi, Peng Yanyun, Shi Haonan, Li Dongyang, Liu Xi. Research on UAV Path Planning Method Based on Collision Free Trajectory [J]. Journal of System Simulation, 2026, 38(3): 808-817. |
| [6] | Zhu Ling, Li Jing, Zhang Zhaohui. An Adaptive Robot Path Planning Based on Improved REA* Algorithm [J]. Journal of System Simulation, 2026, 38(2): 332-345. |
| [7] | Wang Bingkun, Wang Yue, Yang Mei, Zhang Pengnian, Fan Bohao, Tang Jie. Strike Strategy Planning Method of Unmanned Ground Vehicles Based on Improved PPO Algorithm [J]. Journal of System Simulation, 2026, 38(2): 372-386. |
| [8] | Ding Zhengkun, Liu Jiaqi, Xu Junzheng, Xu Yuezhu, Wang Xingmei. Intelligent Air Combat Decision-making Method Based on BiGRU and Priority Dynamic Sampling [J]. Journal of System Simulation, 2026, 38(2): 447-459. |
| [9] | Tao Caixia, Chen Naikun, Gao Fengyang, Zhang Jiangang. Distributed Optimization for Integrated Energy Based on Multi-agent Reinforcement Learning [J]. Journal of System Simulation, 2026, 38(2): 476-487. |
| [10] | Jiang Ming, He Tao. Solving the Vehicle Routing Problem Based on Deep Reinforcement Learning [J]. Journal of System Simulation, 2025, 37(9): 2177-2187. |
| [11] | Yu Yiran, Lai Huicheng, Gao Guxue, Zhang Guo, Peng Wangyinan, Yang Longfei, Huang Junhao. Optimization Method for Multi Agricultural Machinery Collaborative Operation Based on Genetic Algorithm and A * Algorithm [J]. Journal of System Simulation, 2025, 37(9): 2397-2408. |
| [12] | Zhang Kaixiang, Mao Jianlin, Wang Niya, Xu Zhihao. Multi-robot Hierarchical Collaborative k-robust Path Planning for Path Interference [J]. Journal of System Simulation, 2025, 37(8): 2074-2088. |
| [13] | Chen Zhen, Wu Zhuoyi, Zhang Lin. Research on Policy Representation in Deep Reinforcement Learning [J]. Journal of System Simulation, 2025, 37(7): 1753-1769. |
| [14] | Wan Yuhang, Zhu Zilu, Zhong Chunfu, Liu Yongkui, Lin Tingyu, Zhang Lin. Dynamic Path Planning for Robotic Arms Based on an Improved PPO Algorithm [J]. Journal of System Simulation, 2025, 37(6): 1462-1473. |
| [15] | Ye Chen, Shao Peng, Zhang Shaoping, Li Wenting, Zhou Tengming. Enhanced Artificial Gorilla Algorithm for Mobile Robot Path Planning [J]. Journal of System Simulation, 2025, 37(6): 1474-1485. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
