

Journal of System Simulation ›› 2023, Vol. 35 ›› Issue (10): 2249-2261.doi: 10.16182/j.issn1004731x.joss.23-FZ0824
• Papers • Previous Articles Next Articles
Wang Yukun( ), Wang Ze, Dong Liwei, Li Ni()
), Wang Ze, Dong Liwei, Li Ni()
Received:2023-07-03
Revised:2023-09-15
Online:2023-10-30
Published:2023-10-26
Contact:
Li Ni
E-mail:wyk_13@foxmail.com;lini@buaa.edu.cn
CLC Number:
Wang Yukun, Wang Ze, Dong Liwei, Li Ni. Research on Multi-aircraft Air Combat Behavior Modeling Based on Hierarchical Intelligent Modeling Methods[J]. Journal of System Simulation, 2023, 35(10): 2249-2261.
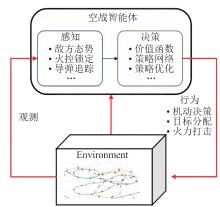
Fig. 1
Deep reinforcement learning process applied to air combat
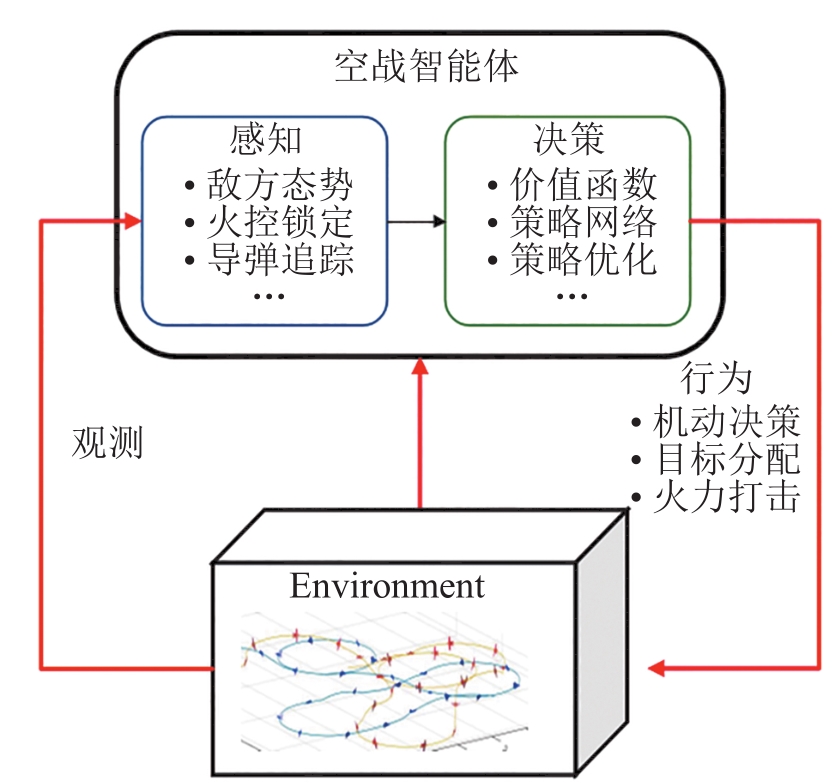
Fig. 2
Situation map obtained through simulation
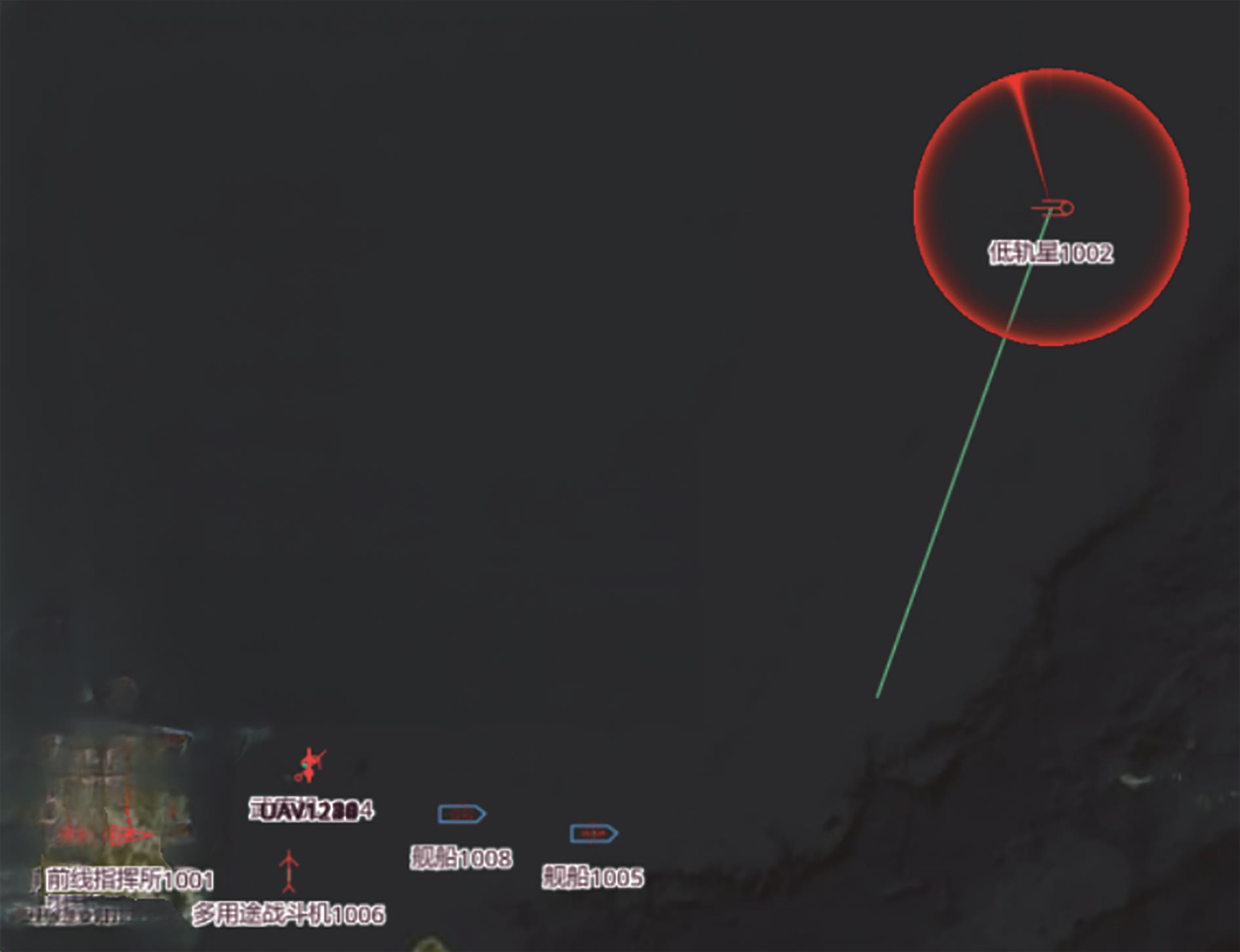

Fig. 3
Two-dimensional situation map example
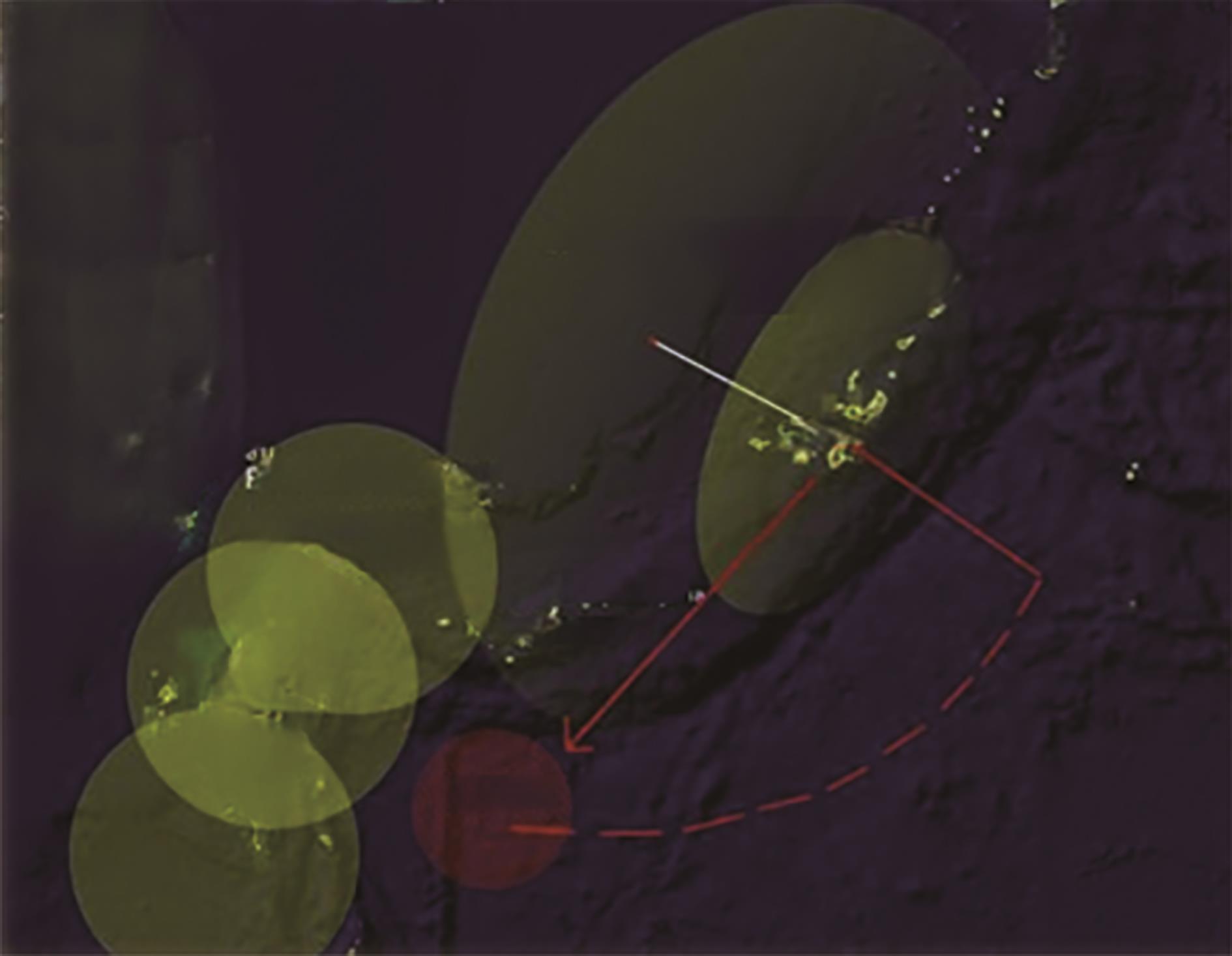

Fig. 4
Information situation map color segmentation subgraph


Fig. 5
Situation feature area extraction
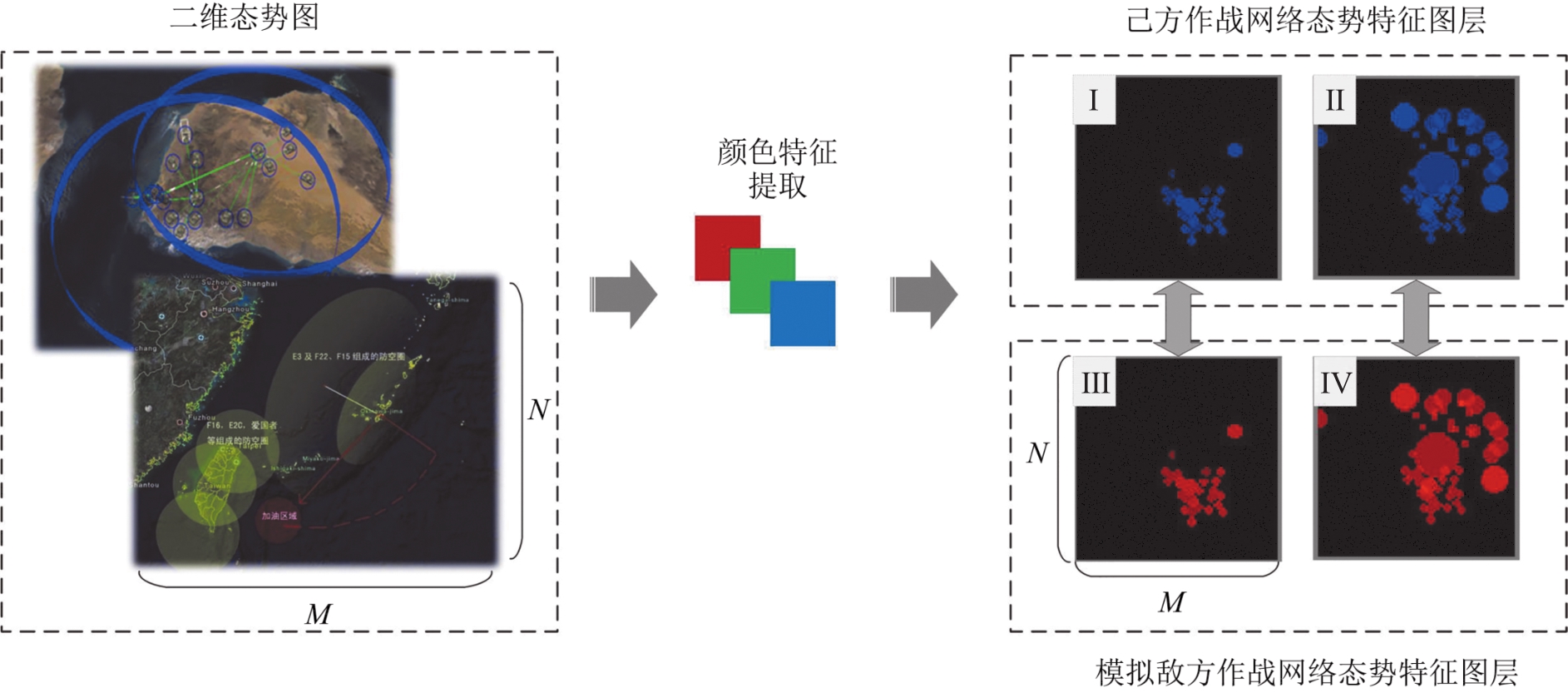
Fig. 6
Reward function design
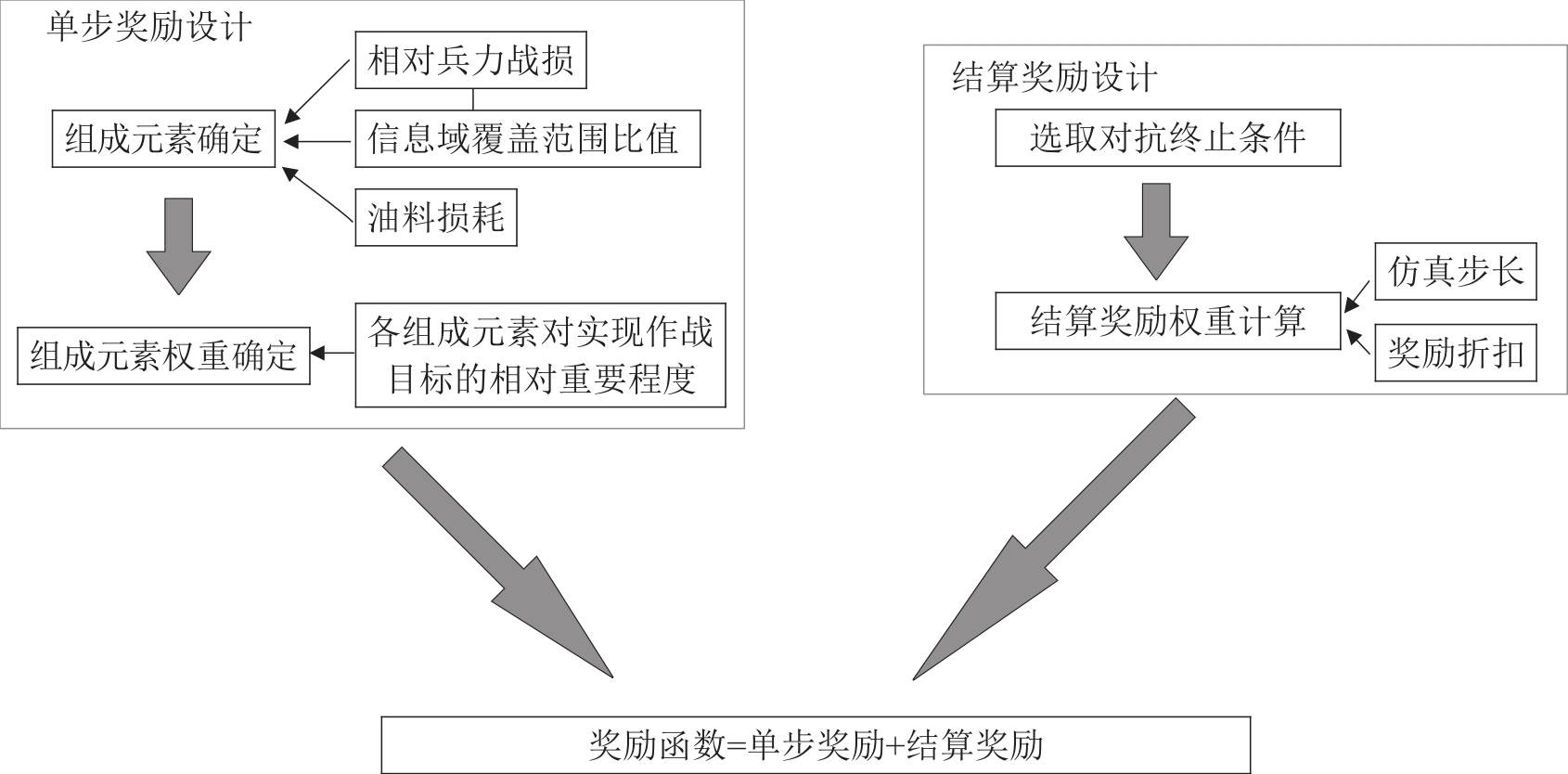

Fig. 7
Multi-aircraft adversarial intelligent behavior decision-making modeling hierarchical framework
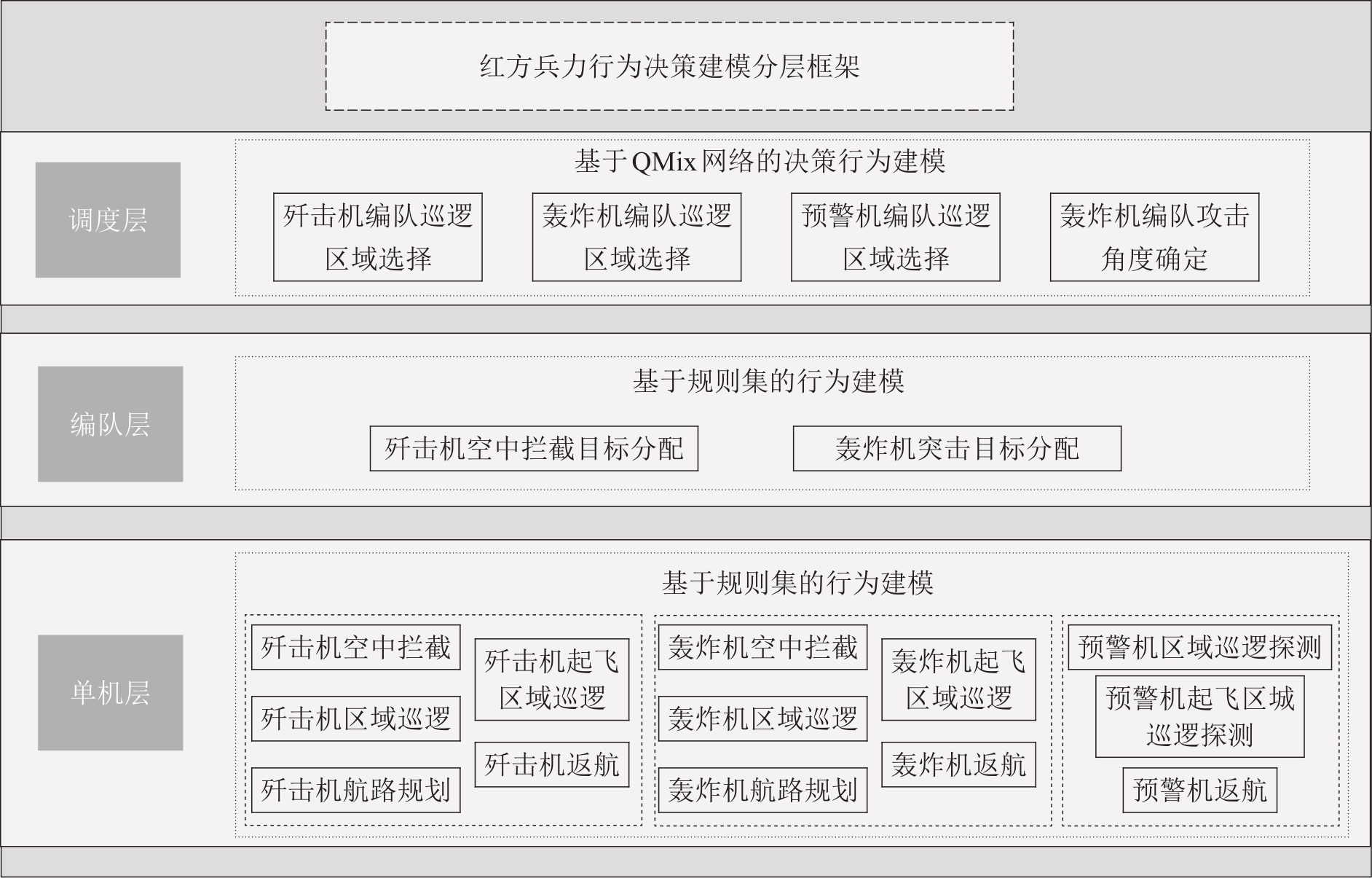
Table 1
Formation target allocation rule set
| 规则前件 | 规则后件 |
|---|---|
| 剩余弹药&&未分配目标&&存在未分配敌机 | 就近原则分配未被锁定敌机作为目标 |
| 无剩余弹药 | 不进行目标分配 |
| 剩余弹药&&已分配目标&&存在更近敌机 | 将更近敌机设置为新目标 |
| 剩余弹药&&已分配目标&&目标已损毁 | 重新分配拦截目标 |
| 剩余弹药&&无分配目标&&无未分配敌机 | 到调度层指定的区域巡逻 |
Table 2
Single fighter combat rule set
| 规则前件 | 规则后件 |
|---|---|
| 当前状态为区域巡逻&&收到空中拦截指令 | 进行空中拦截 |
| 当前状态为空中拦截&&拦截目标已损毁 | 前往网络输出的指定区域巡逻 |
| 油料不足 | 返航 |
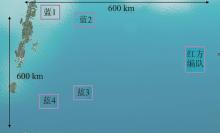
Fig. 8
Joint naval and air force combat scenarios
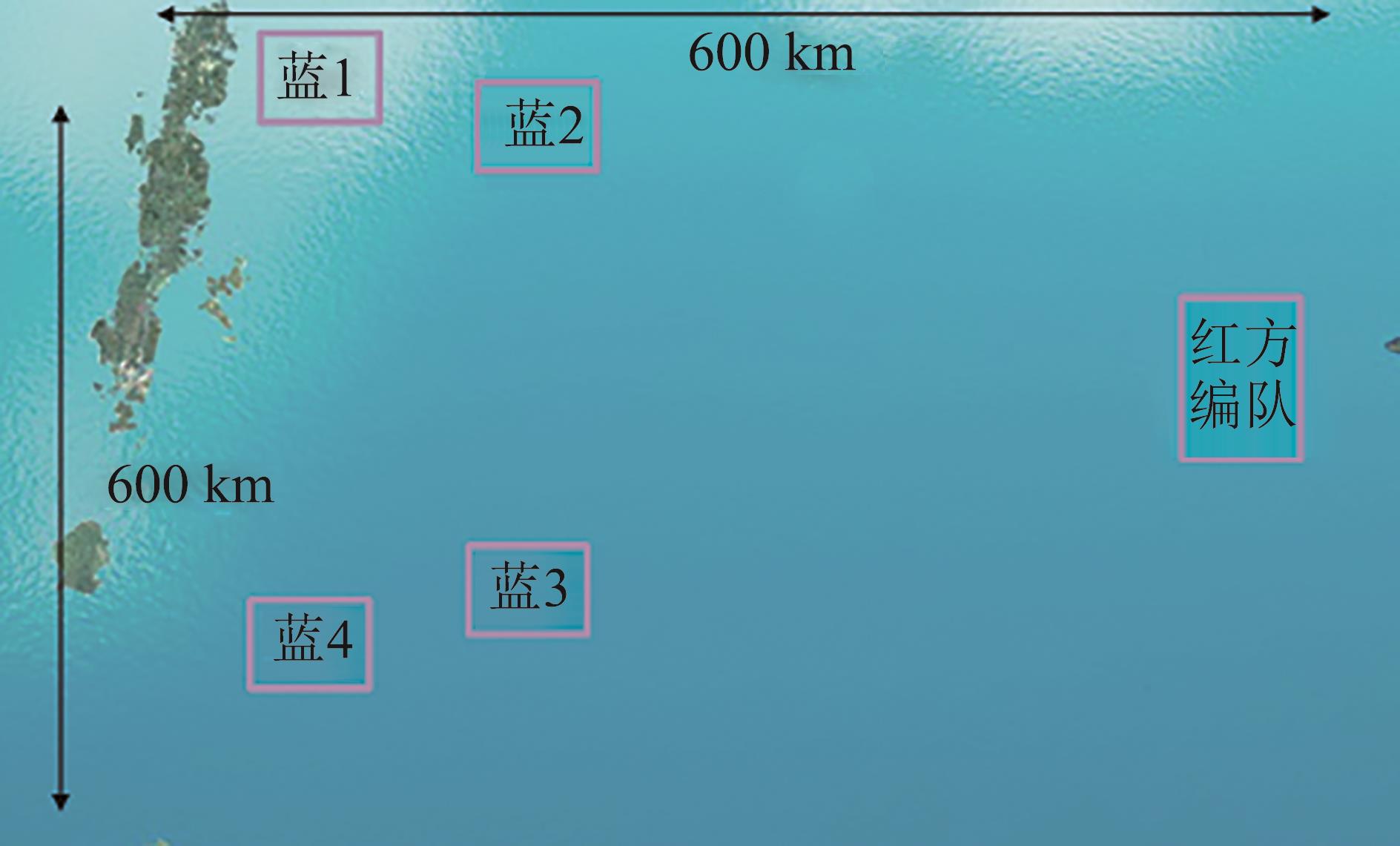

Fig. 9
Initial distribution of troops
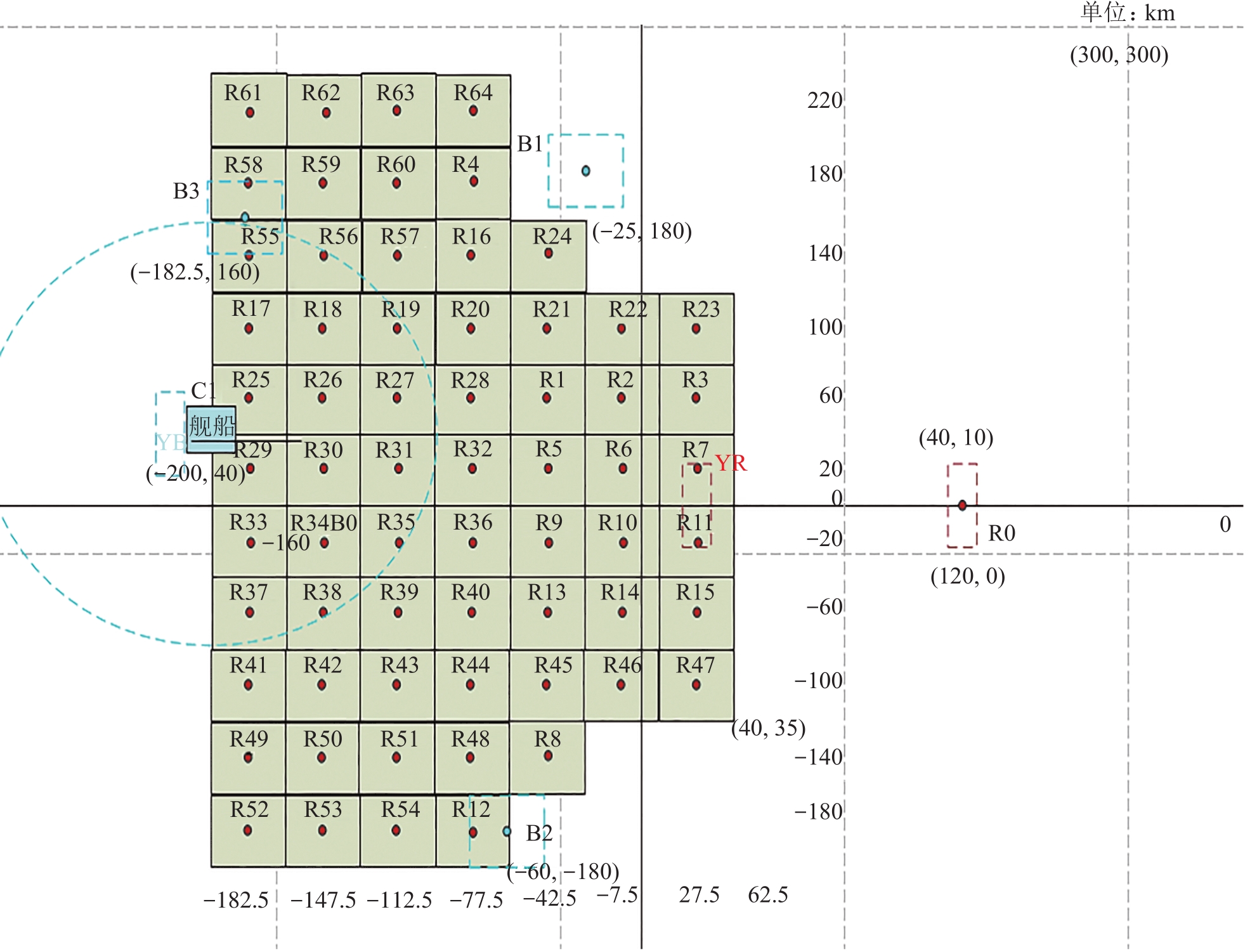
Table 3
State space input to QMix
| 参数 | 参数含义 |
|---|---|
| Xr | 红方兵力平台x坐标位置 |
| Yr | 红方兵力平台y坐标位置 |
| LXr | 红方兵力平台类型 |
| Hr | 红方兵力平台航向 |
| D_numr | 红方兵力平台的携弹量 |
| Ar | 红方火力域覆盖比 |
| Ir | 红方探测信息域覆盖范围 |
| Xb | 蓝方兵力平台x坐标位置 |
| Yb | 蓝方兵力平台y坐标位置 |
| LXb | 蓝方兵力平台类型 |
| Hb | 蓝方兵力平台的航向 |
| Ab | 蓝方火力域覆盖比 |
| Ib | 蓝方探测信息域覆盖范围 |
Table 4
QMix network parameters
| 参数 | 参数含义 | 参数取值 |
|---|---|---|
| n_agents | 智能体数量 | 2 |
| obs_dim | 输入状态空间维度 | 264 |
| action_dim | 行为空间 | 64 |
| batch_size | 批次 | 512 |
| gamma | 折扣因子 | 0.9 |
| replace_target_iter | 目标网络参数更新周期 | 200 |
| lr | 学习率 | 0.000 5 |
| epsilon | 探索概率 | 1.0 |
| epsilon_min | 最小探索概率 | 0.02 |
| epsilon_decay | 探索衰减概率 | 0.999 9 |
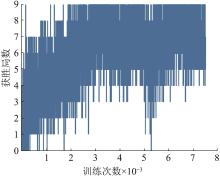
Fig. 10
Number of victories of red side in QMix network training process
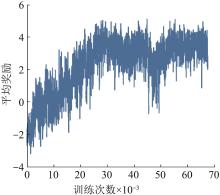
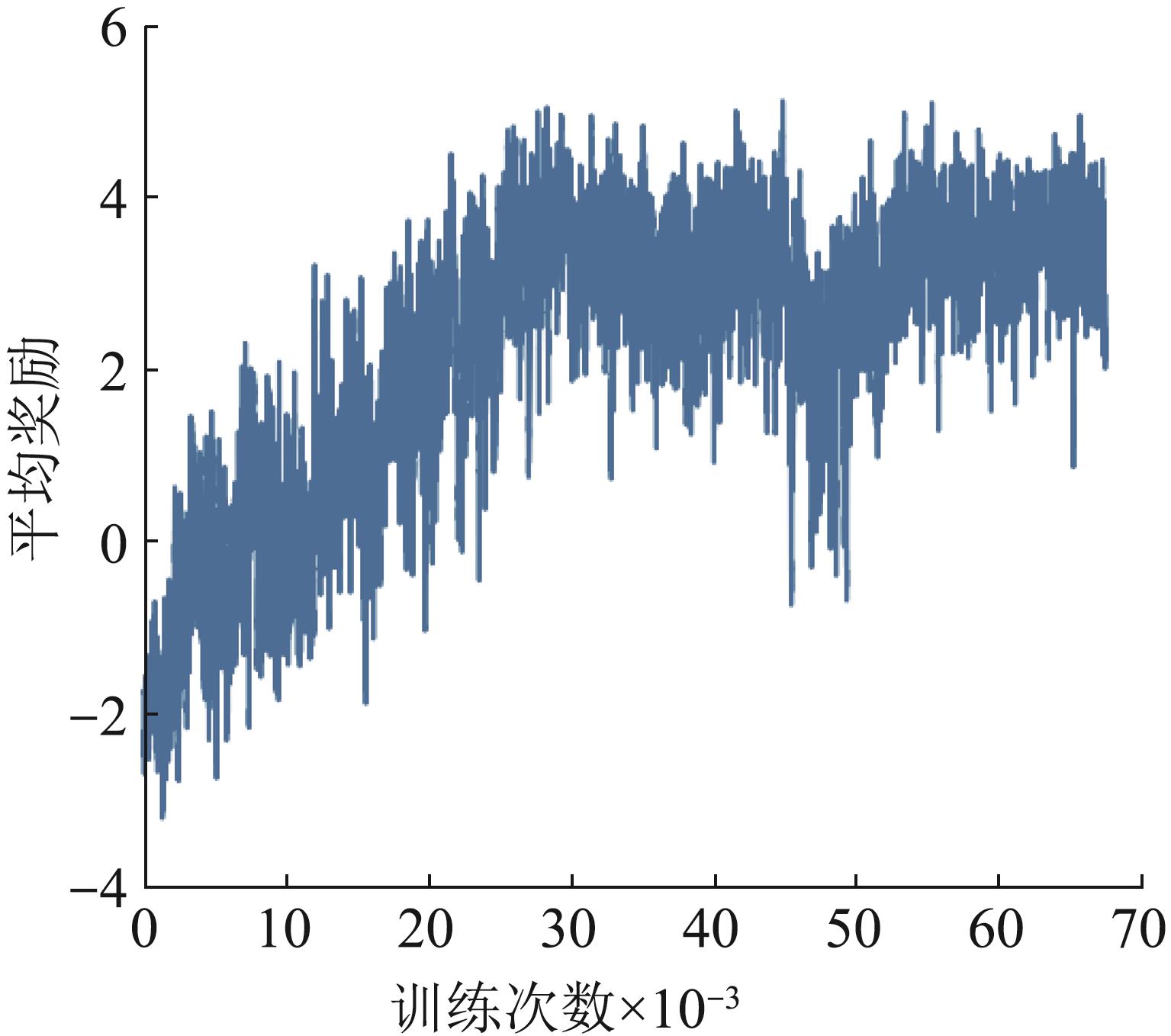
Fig. 11
Reward curve
| 1 | Holcomb S D, Porter W K, Ault S V, et al. Overview on DeepMind and Its AlphaGo Zero AI[C]//Proceedings of the 2018 International Conference on Big Data and Education. New York, NY, USA: Association for Computing Machinery, 2018: 67-71. |
| 2 | Arulkumaran K, Cully A, Togelius J. AlphaStar: an Evolutionary Computation Perspective[C]//Proceedings of the Genetic and Evolutionary Computation Conference Companion. New York, NY, USA: Association for Computing Machinery, 2019: 314-315. |
| 3 | Berner C, Brockman G, Chan B, et al. Dota 2 With Large Scale Deep Reinforcement Learning[EB/OL]. (2019-12-13) [2023-05-10]. . |
| 4 | 杨惟轶, 白辰甲, 蔡超, 等. 深度强化学习中稀疏奖励问题研究综述[J]. 计算机科学, 2020, 47(3): 182-191. |
| Yang Weiyi, Bai Chenjia, Cai Chao, et al. Survey on Sparse Reward in Deep Reinforcement Learning[J]. Computer Science, 2020, 47(3): 182-191. | |
| 5 | Chen G. A New Framework for Multi-agent Reinforcement Learning-centralized Training and Exploration With Decentralized Execution via Policy Distillation[EB/OL]. (2019-10-21) [2022-11-02]. . |
| 6 | Lowe R, Wu Yi, Tamar A, et al. Multi-agent Actor-critic for Mixed Cooperative-competitive Environments[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2017: 6382-6393. |
| 7 | Marthi B. Automatic Shaping and Decomposition of Reward Functions[C]//Proceedings of the 24th International Conference on Machine learning. New York, NY, USA: Association for Computing Machinery, 2007: 601-608. |
| 8 | Chen Jiayu, Zhang Yuanxin, Xu Yuanfan, et al. Variational Automatic Curriculum Learning for Sparse-reward Cooperative Multi-agent Problems[C]//35th Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2021, 34: 9681-9693. |
| 9 | Hu Yujing, Wang Weixun, Jia Hangtian, et al. Learning to Utilize Shaping Rewards: A New Approach of Reward Shaping[C]//34th Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2020: 15931-15941. |
| 10 | Zhelo O, Zhang Jingwei, Tai Lei, et al. Curiosity-driven Exploration for Mapless Navigation With Deep Reinforcement Learning[EB/OL]. (2018-05-14) [2023-06-21]. . |
| 11 | Wang Xin, Chen Yudong, Zhu Wenwu. A Survey on Curriculum Learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(9): 4555-4576. |
| 12 | Hutsebaut-Buysse M, Mets K, Latré S. Hierarchical Reinforcement Learning: A Survey and Open Research Challenges[J]. Machine Learning & Knowledge Extraction, 2022, 4(1): 172-221. |
| 13 | 周攀, 黄江涛, 章胜, 等. 基于深度强化学习的智能空战决策与仿真[J]. 航空学报, 2023, 44(4): 94-107. |
| Zhou Pan, Huang Jiangtao, Zhang Sheng, et al. Intelligent Air Combat Decision Making and Simulation Based on Deep Reinforcement Learning[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(4): 94-107. | |
| 14 | 李永丰, 史静平, 章卫国, 等. 深度强化学习的无人作战飞机空战机动决策[J]. 哈尔滨工业大学学报, 2021, 53(12): 33-41. |
| Li Yongfeng, Shi Jingping, Zhang Weiguo, et al. Maneuver Decision of UCAV in Air Combat Based on Deep Reinforcement Learning[J]. Journal of Harbin Institute of Technology, 2021, 53(12): 33-41. | |
| 15 | Wang Zhuang, Li Hui, Wu Haolin, et al. Improving Maneuver Strategy in Air Combat by Alternate Freeze Games With a Deep Reinforcement Learning Algorithm[J]. Mathematical Problems in Engineering, 2020, 2020: 7180639. |
| 16 | 章胜, 杜昕, 肖娟, 等. 基于深度强化学习的固定翼飞行器六自由度飞行智能控制[J]. 指挥与控制学报, 2022, 8(2): 179-188. |
| Zhang Sheng, Du Xin, Xiao Juan, et al. Fixed-wing Aircraft 6-DOF Flight Control Based on Deep Reinforcement Learning[J]. Journal of Command and Control, 2022, 8(2): 179-188. | |
| 17 | 孙智孝, 杨晟琦, 朴海音, 等. 未来智能空战发展综述[J]. 航空学报, 2021, 42(8): 28-42. |
| Sun Zhixiao, Yang Shengqi, Haiyin Piao, et al. A Survey of Air Combat Artificial Intelligence[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(8): 28-42. | |
| 18 | Tashev B, Purcell M, McLaughlin B. Russia's Information Warfare: Exploring the Cognitive Dimension[J]. MCU Journal, 2019, 10(2): 129-147. |
| 19 | Hamfelt A, Karlsson M, Thierfelder T, et al. Beyond K-means: Clusters Identification for GIS[M]//Popovich V V, Claramunt C, Devogele T, et al. Information Fusion and Geographic Information Systems: Towards the Digital Ocean. Berlin, Heidelberg: Springer Berlin Heidelberg, 2011: 93-105. |
| 20 | Rashid T, Farquhar G, Peng Bei, et al. Weighted QMIX: Expanding Monotonic Value Function Factorisation for Deep Multi-agent Reinforcement Learning[C]//34th Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2020: 10199-10210. |
| [1] | Dong Zhiming, Hu Zhongqi, Dai Haoran, Gao Jiancheng. An Automated Generation Method for Combat Simulation Scenarios Based on Large Language Models [J]. Journal of System Simulation, 2026, 38(5): 1129-1145. |
| [2] | Wang Fangbo, Guo Jian, Du Chenglie, Liu Yifan, Zhang Pengpeng. Design and Verification of Manned-unmanned Collaborative Combat Capability System Based on MBSE [J]. Journal of System Simulation, 2026, 38(3): 800-807. |
| [3] | Wu Shuxia, Zhang Junjie, Chen Delong, Chen Zheyi. Resource-efficient Continuous Learning Framework for Edge Real-time Video Analytics [J]. Journal of System Simulation, 2026, 38(2): 294-306. |
| [4] | Wang Bingkun, Wang Yue, Yang Mei, Zhang Pengnian, Fan Bohao, Tang Jie. Strike Strategy Planning Method of Unmanned Ground Vehicles Based on Improved PPO Algorithm [J]. Journal of System Simulation, 2026, 38(2): 372-386. |
| [5] | Liu Quan, Wang Yu, Liu Linyue, Chen Hao, Huang Jian. Knowledge Closed-loop Driving-based Intelligent Game Confrontation Simulation [J]. Journal of System Simulation, 2026, 38(2): 416-432. |
| [6] | Wang Yifan, Yang Bin, Wang Congjun. Simulation Method for Multi-crew Construction Processes Based on Large Language Model-powered Agent [J]. Journal of System Simulation, 2026, 38(2): 488-500. |
| [7] | Zhao Zejing, Shang Junliang, Qin Yanpei. Kill Chain Efficiency Evaluation Model Based on Gray DEMATEL-ANP [J]. Journal of System Simulation, 2025, 37(9): 2375-2386. |
| [8] | Dong Zhiming, Hu Zhongqi, Liu Zhaoyang, Zhou Heyang. A Review of Intelligent Generation of Combat Simulation Scenarios [J]. Journal of System Simulation, 2025, 37(7): 1665-1683. |
| [9] | Wang Ziyi, Zhang Kai, Qian Dianwei, Liu Yuzhen. A DRL⁃based Approach for Distributed Equipment Nodes Selection [J]. Journal of System Simulation, 2025, 37(6): 1565-1573. |
| [10] | Yao Changhua, Bi Shanning, Ma Rufei, Yu Xiaohan, Li Jiaqiang, Chen Jinli. Method for Dynamic Coalition Formation of Wargame Agent for Force Cooperation [J]. Journal of System Simulation, 2025, 37(5): 1188-1196. |
| [11] | Zhang Sen, Dai Qiangqiang. UAV Path Planning Based on Improved Deep Deterministic Policy Gradients [J]. Journal of System Simulation, 2025, 37(4): 875-881. |
| [12] | Li Min, Zhang Sen, Zeng Xiangguang, Wang Gang, Zhang Tongwei, Xie Dijie, Ren Wenzhe, Zhang Tao. Trajectory Planning of Quadruped Robot Over Obstacle with Single Leg Based on Deep Reinforcement Learning [J]. Journal of System Simulation, 2025, 37(4): 895-909. |
| [13] | Wang He, Xu Jianing, Yan Guangyu. Research on Pedestrian Avoidance Strategy for AGV Based on Deep Reinforcement Learning [J]. Journal of System Simulation, 2025, 37(3): 595-606. |
| [14] | Zhang Bin, Lei Yonglin, Li Qun, Gao Yuan, Chen Yong, Zhu Jiajun, Bao Chenlong. Reinforcement Learning Modeling of Missile Penetration Decision Based on Combat Simulation [J]. Journal of System Simulation, 2025, 37(3): 763-774. |
| [15] | Huang Sijin, Wen Jia, Chen Zheyi. Intelligent Service Migration towards MEC-based IoV Systems [J]. Journal of System Simulation, 2025, 37(2): 379-391. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
