

Journal of System Simulation ›› 2026, Vol. 38 ›› Issue (1): 73-83.doi: 10.16182/j.issn1004731x.joss.25-0858
• Papers • Previous Articles Next Articles
Zhu He1, Zhou Feng1, Zhang Qi1, Zhu Mengxiao1, Dai Ju2
Received:2025-09-06
Revised:2025-10-22
Online:2026-01-18
Published:2026-01-28
Contact:
Zhou Feng
CLC Number:
Zhu He, Zhou Feng, Zhang Qi, Zhu Mengxiao, Dai Ju. PL-Mamba: A 3D Point Cloud Semantic Segmentation Network Based on Bimodal Fusion[J]. Journal of System Simulation, 2026, 38(1): 73-83.
Fig. 1
Overall overview of PL-Mamba
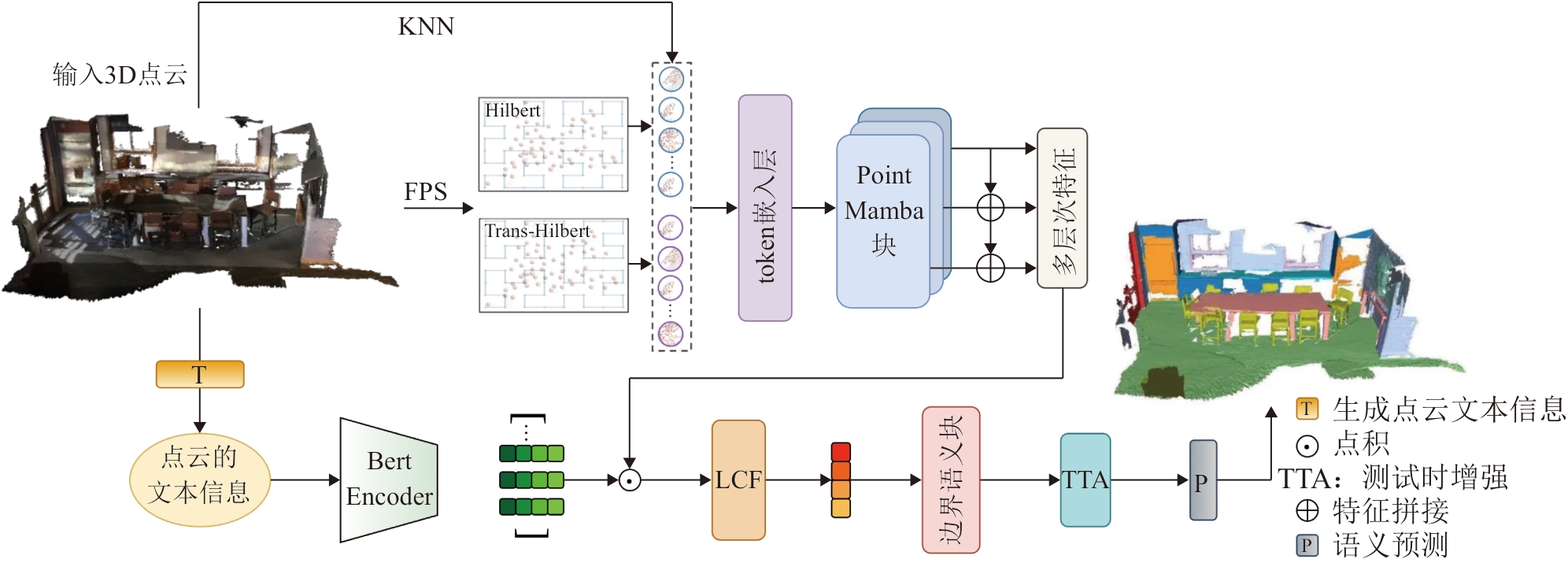
Table 1
Comparison of ScanNet dataset results
| 方法 | mIoU | 墙 | 地 | 柜橱 | 床 | 椅子 | 沙发 |
|---|---|---|---|---|---|---|---|
| CDSegNet[ | 77.9 | ||||||
| OneFormer3D[ | 76.6 | 84.32 | 94.27 | 70.30 | 79.31 | 88.49 | 82.86 |
| ODIN | 77.8 | 85.90 | 95.32 | 67.54 | 81.07 | 89.95 | 82.54 |
| Pamba[ | 77.6 | ||||||
| FEAST-Mamba | 77.8 | ||||||
| BFANet | 78.0 | 86.94 | 94.86 | 67.45 | 79.23 | 89.73 | 79.02 |
| PL-Mamba | 78.21 | 85.53 | 95.44 | 71.65 | 83.51 | 87.52 | 81.34 |
| 方法 | 桌子 | 门 | 窗户 | 书架 | 图片 | 柜台 | 书桌 |
| CDSegNet[ | |||||||
| OneFormer3D[ | 78.43 | 67.44 | 68.71 | 79.41 | 39.56 | 63.89 | 72.11 |
| ODIN | 78.04 | 66.17 | 68.70 | 81.80 | 33.60 | 63.68 | 73.08 |
| Pamba[ | |||||||
| FEAST-Mamba | |||||||
| BFANet | 78.68 | 67.63 | 68.08 | 82.30 | 33.31 | 61.48 | 72.10 |
| PL-Mamba | 79.27 | 66.83 | 69.75 | 80.42 | 36.05 | 65.09 | 72.56 |
Fig. 2
Comparison of visualization results on the ScanNet dataset
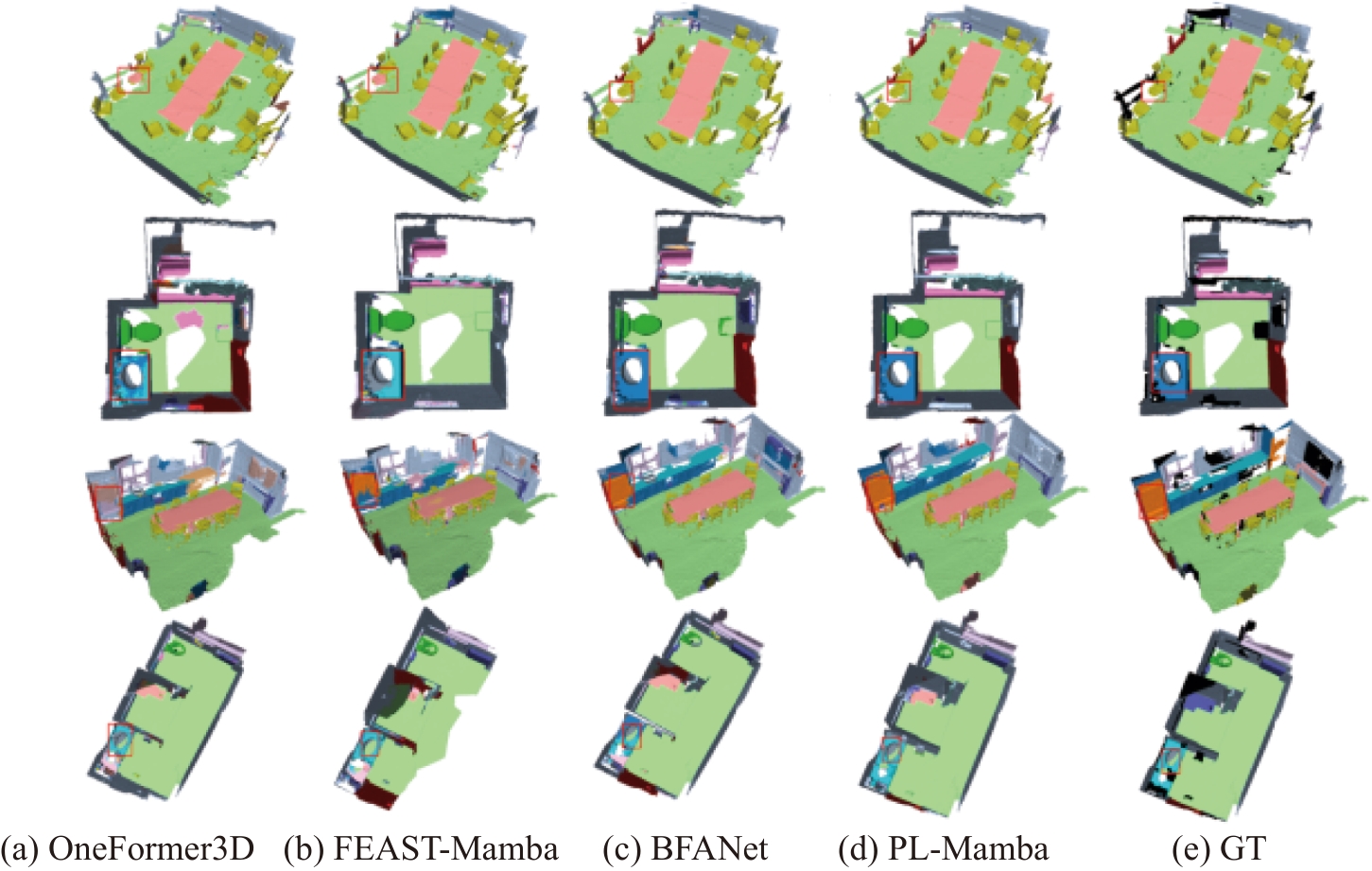
Table 2
Comparison of S3DIS dataset results
| 方法 | OA | mAcc | mIoU | 天花板 | 地板 | 墙 | 梁 | 柱 |
|---|---|---|---|---|---|---|---|---|
| PointNet | 49.0 | 41.1 | 88.8 | 97.3 | 69.8 | 0.1 | 3.9 | |
| PointNet++ | 47.8 | 90.3 | 95.6 | 69.3 | 0.1 | 13.8 | ||
| ODIN-Swin-B | 68.6 | |||||||
| Pamba | 73.5 | |||||||
| OneFormer3D | 72.4 | |||||||
| SegCloud | 57.4 | 48.9 | 90.1 | 96.1 | 69.9 | 0.0 | 18.4 | |
| PointCNN[ | 85.9 | 63.9 | 57.3 | 92.3 | 98.2 | 79.4 | 0.0 | 17.6 |
| FEAST-Mamba | 92.5 | 80.1 | 74.7 | 96.7 | 98.6 | 88.5 | 0.0 | 55.3 |
| BFANet | 91.9 | 79.3 | 73.7 | 90.8 | 92.4 | 86.9 | 0.0 | 59.8 |
| PL-Mamba | 92.8 | 80.3 | 74.9 | 96.5 | 98.9 | 88.8 | 0.0 | 55.0 |
| 方法 | 窗 | 门 | 桌 | 椅 | 沙发 | 书柜 | 板 | 其他 |
| PointNet | 46.3 | 10.8 | 59.0 | 52.6 | 5.9 | 40.3 | 26.4 | 33.2 |
| PointNet++ | 26.7 | 44.1 | 64.3 | 70.0 | 27.8 | 47.8 | 30.8 | 38.1 |
| ODIN-Swin-B | ||||||||
| Pamba | ||||||||
| OneFormer3D | ||||||||
| SegCloud | 38.4 | 23.1 | 70.4 | 75.9 | 40.9 | 58.4 | 13.0 | 41.6 |
| PointCNN[ | 28.8 | 62.1 | 70.4 | 80.6 | 39.7 | 66.7 | 62.1 | 56.7 |
| FEAST-Mamba | 61.5 | 76.6 | 93.2 | 85.7 | 81.9 | 87.1 | 81.2 | 64.5 |
| BFANet | 77.3 | 72.6 | 81.9 | 78.1 | 70.2 | 49.6 | 44.2 | 73.5 |
| PL-Mamba | 61.8 | 76.4 | 93.5 | 85.5 | 82.2 | 86.9 | 81.5 | 64.7 |

Fig. 3
Comparison of visualization results on the S3DIS dataset

Table 3
Ablation study of the main modules in PL-Mamba
| 模型 | PointMamba | FusionNet | 双模态 | mIoU/% |
|---|---|---|---|---|
| BaseLine | 78.0 | |||
| A1 | √ | √ | 78.11 | |
| A2 | √ | √ | 78.15 | |
| A3 | √ | 78.06 | ||
| PL-Mamba | √ | √ | √ | 78.21 |
| [1] | Kang Zhizhong, Yang Juntao, Yang Zhou, et al. A Review of Techniques for 3D Reconstruction of Indoor Environments[J]. ISPRS International Journal of Geo-information, 2020, 9(5): 330. |
| [2] | Yeshwanth C, Liu Y C, Nießner M, et al. ScanNet++: A High-fidelity Dataset of 3D Indoor Scenes[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 12-22. |
| [3] | Liu Guangzu, Wei Shuangfeng, Zhong Shaobo, et al. Reconstruction of Indoor Navigation Elements for Point Cloud of Buildings with Occlusions and Openings by Wall Segment Restoration from Indoor Context Labeling[J]. Remote Sensing, 2022, 14(17): 4275. |
| [4] | Sun Yuliang, Zhang Xudong, Miao Yongwei. A Review of Point Cloud Segmentation for Understanding 3D Indoor Scenes[J]. Visual Intelligence, 2024, 2(1): 14. |
| [5] | Casado-Coscolla A, Sanchez-Belenguer C, Wolfart E, et al. Rendering Massive Indoor Point Clouds in Virtual Reality[J]. Virtual Reality, 2023, 27(3): 1859-1874. |
| [6] | Mei Luoyu, Wang Shuai, Cheng Yun, et al. ESP-PCT: Enhanced VR Semantic Performance Through Efficient Compression of Temporal and Spatial Redundancies in Point Cloud Transformers[EB/OL]. (2024-09-02) [2025-08-04]. . |
| [7] | Song Youcheng, Sun Zhengxing, Li Qian, et al. Learning indoor Point Cloud Semantic Segmentation from Image-level Labels[J]. The Visual Computer, 2022, 38(9): 3253-3265. |
| [8] | Peng Bohao, Wu Xiaoyang, Jiang Li, et al. OA-CNNs: Omni-Adaptive Sparse CNNs for 3D Semantic Segmentation[C]//2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2024: 21305-21315. |
| [9] | Charles R Q, Su Hao, Mo Kaichun, et al. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2017: 77-85. |
| [10] | Liang Dingkang, Zhou Xin, Xu Wei, et al. PointMamba: A Simple State Space Model for Point Cloud Analysis[C]//Proceedings of the 38th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2024: 32653-32677. |
| [11] | Rizaldy A, Gloaguen R, Fassnacht F E, et al. HyperPointFormer: Multimodal Fusion in 3-D Space with Dual-branch Cross-attention Transformers[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 21254-21274. |
| [12] | Zhang Yue, Jian Yingzhao, Fan Hehe, et al. Uni3D-MoE: Scalable Multimodal 3D Scene Understanding via Mixture of Experts[EB/OL]. (2025-05-27) [2025-08-04]. . |
| [13] | Yang Yuqi, Guo Yuxiao, Liu Yang. Swin3D++: Effective Multi-source Pretraining for 3D Indoor Scene Understanding[J]. Computational Visual Media, 2025, 11(3): 465-481. |
| [14] | Dong Mingyue, Huan Linxi, Xiong Hanjiang, et al. Shape Anchor Guided Holistic Indoor Scene Understanding[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 21859-21869. |
| [15] | Zhao Weiguang, Zhang Rui, Wang Qiufeng, et al. BFANet: Revisiting 3D Semantic Segmentation with Boundary Feature Analysis[C]//2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2025: 29395-29405. |
| [16] | Koroteev M V. BERT: A Review of Applications in Natural Language Processing and Understanding[EB/OL]. (2021-03-22)[2025-08-04].. |
| [17] | Qi C R, Yi Li, Su Hao, et al. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 5105-5114. |
| [18] | Choy C, Gwak J Y, Savarese S. 4D Spatio-temporal ConvNets: Minkowski Convolutional Neural Networks[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2019: 3070-3079. |
| [19] | Fu Rao, Wen Cheng, Li Qian, et al. BPNet: Bézier Primitive Segmentation on 3D Point Clouds[EB/OL]. (2023-10-15)[2025-08-04].. |
| [20] | Zhao Hengshuang, Jiang Li, Jia Jiaya, et al. Point Transformer[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2021: 16239-16248. |
| [21] | Wu Xiaoyang, Lao Yixing, Jiang Li, et al. Point Transformer V2: Grouped Vector Attention and Partition-Based Pooling[C]//Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 33330-33342. |
| [22] | Singh P D, Tripathi V. Digital Twins: A Comprehensive Study on Models, Platforms, Applications and Challenges[C]//2024 11th International Conference on Computing for Sustainable Global Development (INDIACom). Piscataway: IEEE, 2024: 1072-1077. |
| [23] | Rao Junhua, Wang Xin. Research on Virtual Simulation Algorithm for Internet of Things Intelligent Manufacturing Based on Mixed Reality Technology[C]//2024 International Conference on Distributed Computing and Optimization Techniques (ICDCOT). Piscataway: IEEE, 2024: 1-6. |
| [24] | Kristensen T, Ezeora N J. Simulation of Intelligent Traffic Control for Autonomous Vehicles[C]//2017 IEEE International Conference on Information and Automation (ICIA). Piscataway: IEEE, 2017: 459-465. |
| [25] | Zhou Feng, Zhang Qi, Dai Ju, et al. Position-Aware Guided Point Cloud Completion with CLIP Model[C]//Proceedings of the Thirty-ninth AAAI Conference on Artificial Intelligence and Thirty-seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelligence. Palo Alto: AAAI Press, 2025: 10734-10742. |
| [26] | Zheng Sixiao, Lu Jiachen, Zhao Hengshuang, et al. Rethinking Semantic Segmentation from a Sequence-to-sequence Perspective with Transformers[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2021: 6877-6886. |
| [27] | Liu Yishu, Wu Qingpeng, Zhang Zheng, et al. Multi-granularity Interactive Transformer Hashing for Cross-modal Retrieval[C]//Proceedings of the 31st ACM International Conference on Multimedia. New York: Association for Computing Machinery, 2023: 893-902. |
| [28] | Xu Xing, Wang Tan, Yang Yang, et al. Cross-modal Attention with Semantic Consistence for Image-text Matching[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(12): 5412-5425. |
| [29] | LI Bo, ZHANG Yuanhan, GUO Dong, et al. LLaVA-OneVision: Easy Visual Task Transfer[EB/OL]. (2024-10-26) [2025-08-04]. . |
| [30] | Yu Xumin, Tang Lulu, Rao Yongming, et al. Point-BERT: Pre-training 3D Point Cloud Transformers with Masked Point Modeling[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2022: 19291-19300. |
| [31] | Pang Yatian, Wang Wenxiao, Tay F E H, et al. Masked Autoencoders for Point Cloud Self-supervised Learning[C]//Computer Vision – ECCV 2022. Cham: Springer Nature Switzerland, 2022: 604-621. |
| [32] | Hilbert D. Über die stetige Abbildung einer Linie auf ein Flächenstück[M]//HILBERT D. Dritter Band: Analysis · Grundlagen der Mathematik · Physik Verschiedenes: Nebst Einer Lebensgeschichte. Berlin, Heidelberg: Springer Berlin Heidelberg, 1935: 1-2. |
| [33] | Gu A, Dao T. Mamba: Linear-Time Sequence Modeling with Selective State Spaces[EB/OL]. (2024-05-31) [2025-08-04]. . |
| [34] | Li Chade, Zhang Pengju, Liu Bo, et al. FEAST-Mamba: Feature and Spatial Aware Mamba Network with Bidirectional Orthogonal Fusion for Cross-modal Point Cloud Segmentation[C]//Proceedings of the Thirty-ninth AAAI Conference on Artificial Intelligence and Thirty-seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelligence. Palo Alto: AAAI Press, 2025: 4634-4642. |
| [35] | Qu Wentao, Wang Jing, Gong Yongshun, et al. An End-to-end Robust Point Cloud Semantic Segmentation Network with Single-step Conditional Diffusion Models[C]//2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2025: 27325-27335. |
| [36] | Kolodiazhnyi M, Vorontsova A, Konushin A, et al. OneFormer3D: One Transformer for Unified Point Cloud Segmentation[C]//2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2024: 20943-20953. |
| [37] | Li Zhuoyuan, Ai Yubo, Lu Jiahao, et al. Pamba: Enhancing Global Interaction in Point Clouds Via State Space Model[C]//Proceedings of the Thirty-ninth AAAI Conference on Artificial Intelligence and Thirty-seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelligence. Palo Alto: AAAI Press, 2025: 5092-5100. |
| [38] | Tchapmi L, Choy C, Armeni I, et al. SEGCloud: Semantic Segmentation of 3D Point Clouds[C]//2017 International Conference on 3D Vision (3DV). Piscataway: IEEE, 2017: 537-547. |
| [39] | Li Yangyan, Bu Rui, Sun Mingchao, et al. PointCNN: Convolution on Χ-transformed Points[C]//Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 828-838. |
| [40] | Wang Pengshuai. OctFormer: Octree-based Transformers for 3D Point Clouds[J]. ACM Transactions on Graphics, 2023, 42(4): 155. |
| [1] | Shi Min, Guo Shisheng, Wang Suqin, Li Zhaoxin, Zhu Dengming. Annotation-free 6-DoF Grasp Detection Method Integrating Physical and Geometric Priors [J]. Journal of System Simulation, 2026, 38(5): 1290-1302. |
| [2] | Wan Fei, Yin Yong. Large-scale Scene Registration Technology Based on 3D Gaussian Splatting Fusing GPS Prior Information [J]. Journal of System Simulation, 2026, 38(3): 563-571. |
| [3] | Li Mingyu, Lin Jiaquan. Lightweight Driver Face Object Detection Algorithm Based on YOLOv8-DF [J]. Journal of System Simulation, 2025, 37(8): 2103-2114. |
| [4] | Yang Lu, Pei Junying. Aerial Target Detection Algorithm Fused with Multi-scale Features [J]. Journal of System Simulation, 2025, 37(6): 1486-1498. |
| [5] | Li Jie, Liu Yang, Li Liang, Su Bengan, Wei Jialong, Zhou Guangda, Shi Yanmin, Zhao Zhen. Remote Sensing Small Object Detection Based on Cross-stage Two-branch Feature Aggregation [J]. Journal of System Simulation, 2025, 37(4): 1025-1040. |
| [6] | Li Weigang, Zou Shaofeng, Wang Yongqiang, Yu Chuxiang. Intensity-based Feature Filtering for LiDAR-based SLAM [J]. Journal of System Simulation, 2025, 37(2): 392-403. |
| [7] | Du Yuanhao, Geng Xiuli, Xu Chengzhi, Liu Yinhua. Point Cloud Registration Method Based on Improved Grey Wolf Algorithm and Adaptive Splitting KD-Tree [J]. Journal of System Simulation, 2025, 37(2): 424-435. |
| [8] | Wu Shuheng, Liu Yongkui, Zhang Lin, Xiao Yingying, Wang Lihui. Lightweight Assembly Workpiece Detection Algorithm Based on Improved YOLOv8 [J]. Journal of System Simulation, 2025, 37(12): 3099-3111. |
| [9] | Liu Jia, Zhang Zengwei, Chen Dapeng, Huang Nanxuan, Wang Bin, Song Hong. Improvement of SLAM Localization Accuracy in AR by Enhancing YOLOv8 [J]. Journal of System Simulation, 2025, 37(11): 2701-2713. |
| [10] | Li Weigang, Gan Lei, Wang Yongqiang. Dynamic Scene Point Cloud Mapping Method Based on LiDAR-IMU [J]. Journal of System Simulation, 2025, 37(1): 95-106. |
| [11] | Huo Hanlin, Zou Xiangjun, Chen Yan, Zhou Xinzhao, Chen Mingyou, Li Chengen, Pan Yaoqiang, Tang Yunchao. Visual Robot Obstacle Avoidance Planning and Simulation Using Mapped Point Clouds [J]. Journal of System Simulation, 2024, 36(9): 2149-2158. |
| [12] | Wang Haichao, Yin Yong, Jing Qianfeng, Cong Lin. Estimation of the Berthing Parameter of Unmanned Surface Vessels Based on 3D LiDAR [J]. Journal of System Simulation, 2024, 36(8): 1737-1748. |
| [13] | Ge Chengpeng, Zhao Dong, Wang Rui, Ma Qinghua. Section Point Cloud Denoising Method Based on Enhanced DBSCAN and Distance Consensus Evaluation [J]. Journal of System Simulation, 2024, 36(8): 1800-1809. |
| [14] | Shi Lanxi, Yan Wenxu, Ni Hongyu, Zhao Feng. Research on Dynamic Scene SLAM Based on Improved Object Detection [J]. Journal of System Simulation, 2024, 36(4): 1028-1042. |
| [15] | Wang Gaihua, Li Kehong, Long Qian, Yao Jingxuan, Zhu Bolun, Zhou Zhengshu, Pan Xuran. Object Detection of Lightweight Transformer Based on Knowledge Distillation [J]. Journal of System Simulation, 2024, 36(11): 2517-2527. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
