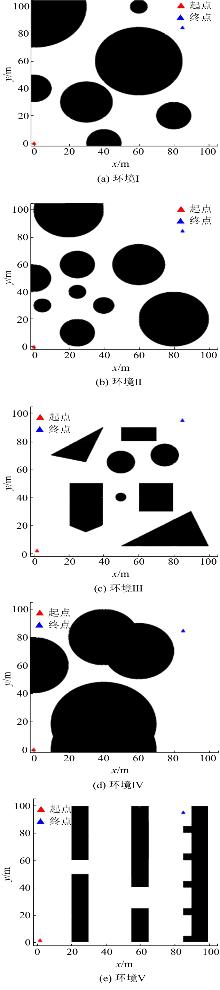
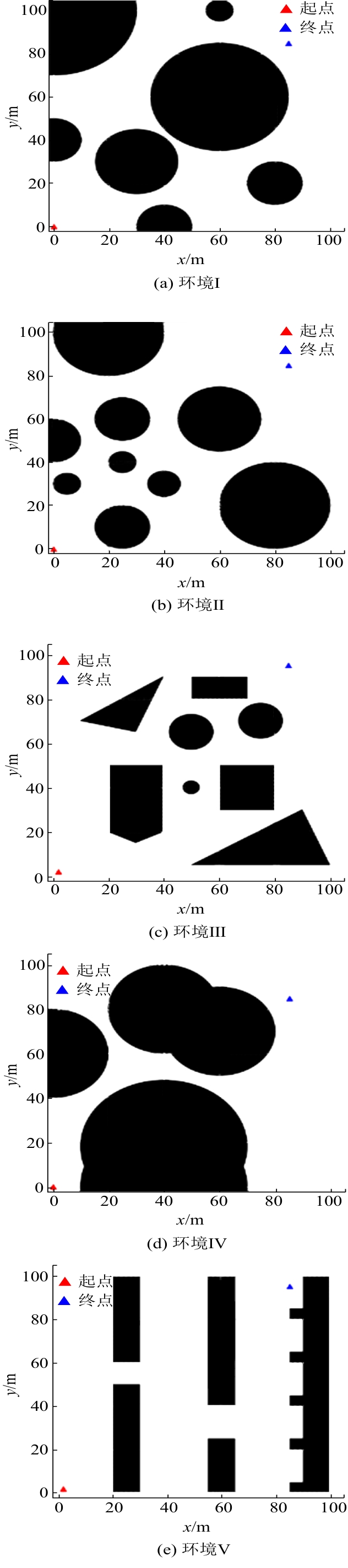
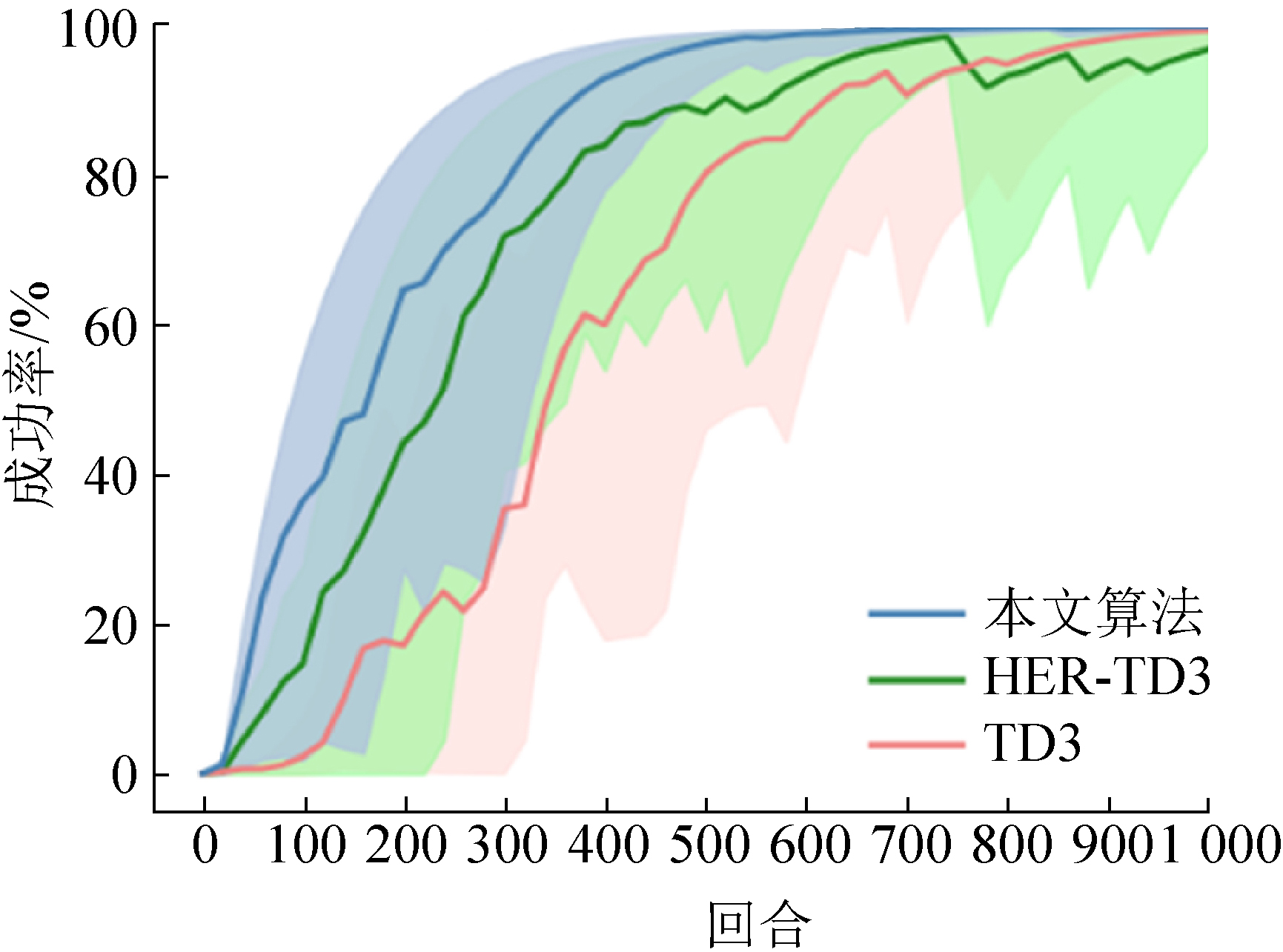
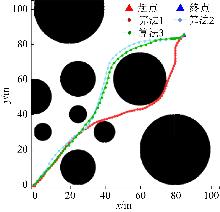
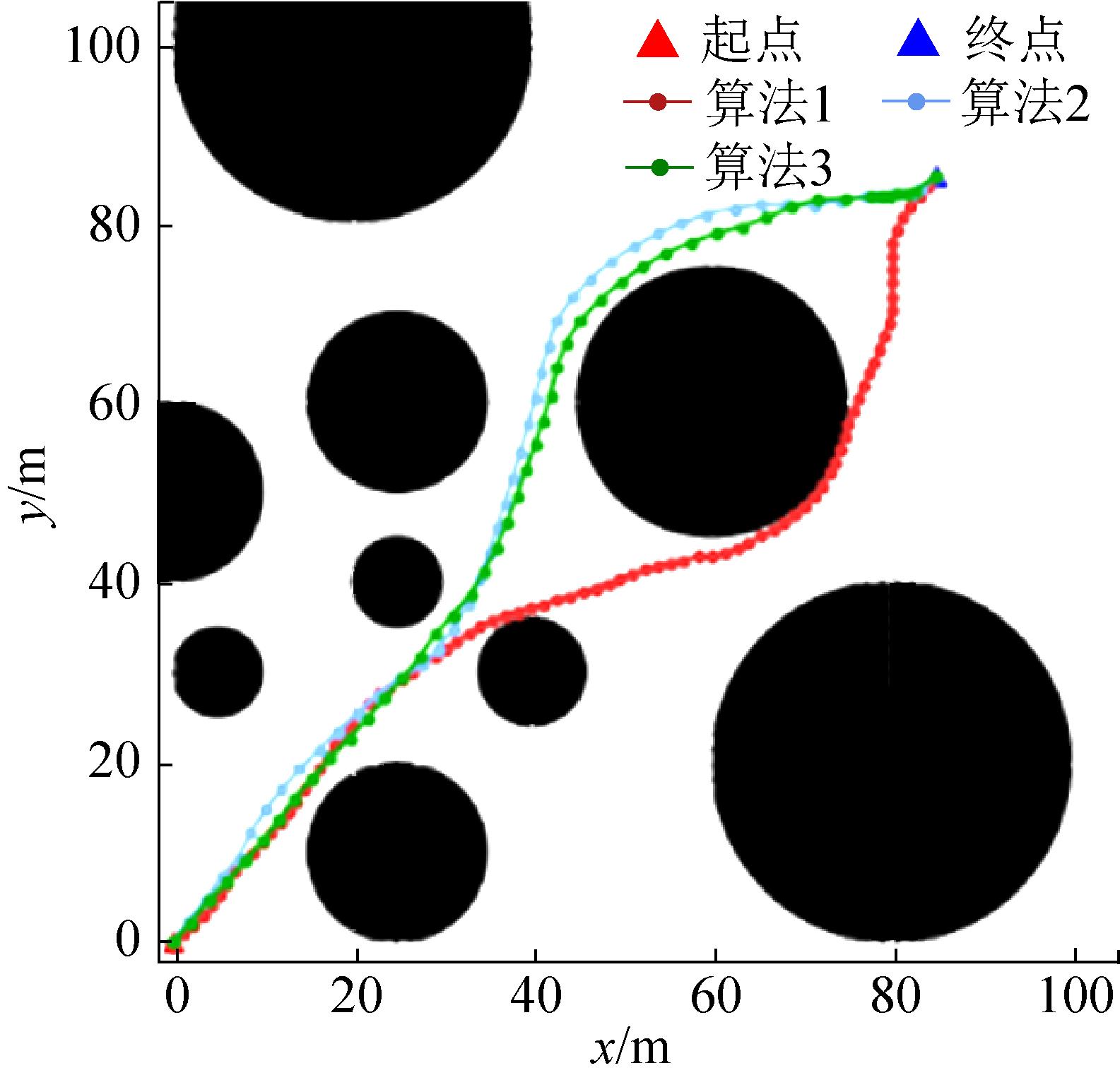
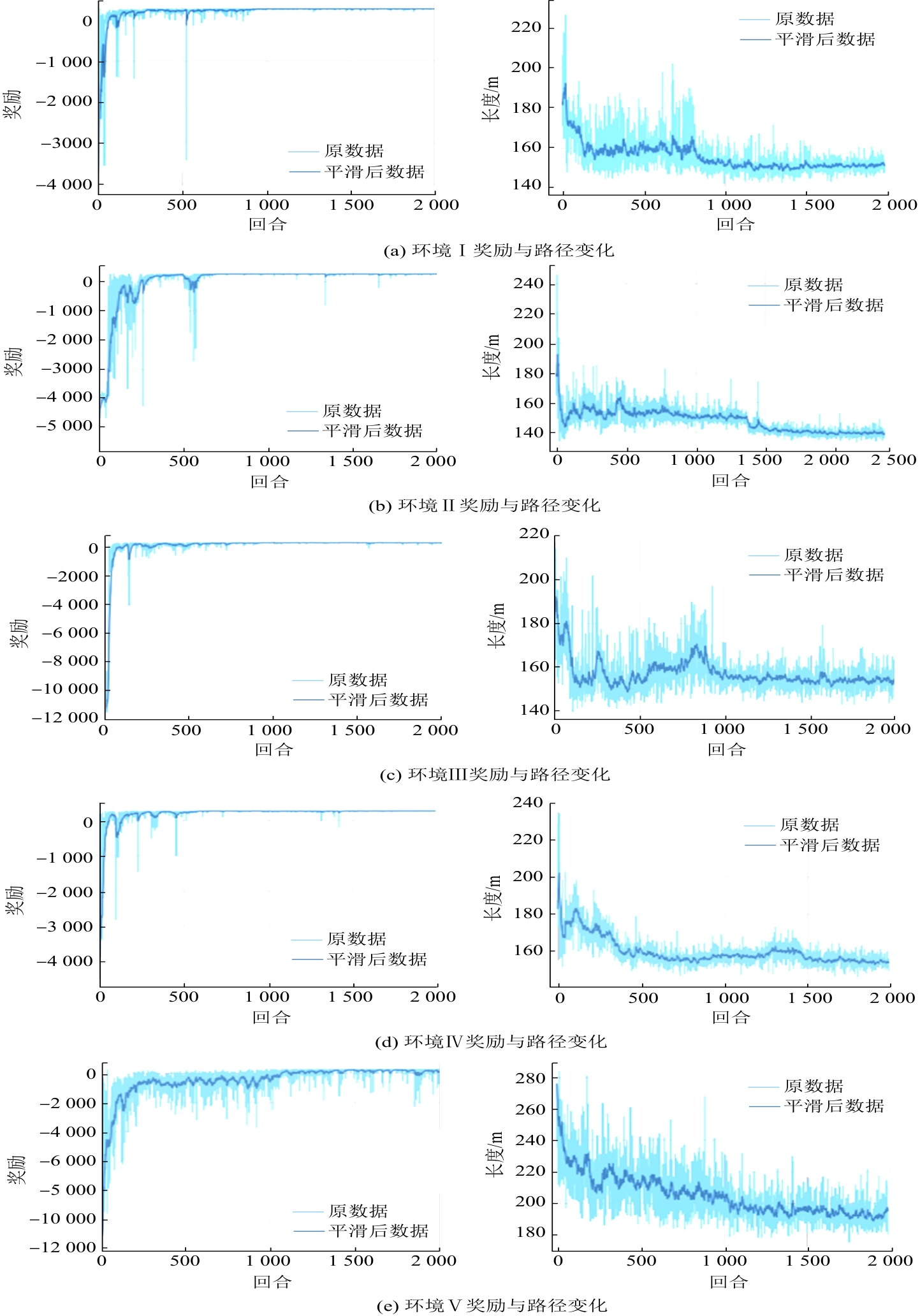
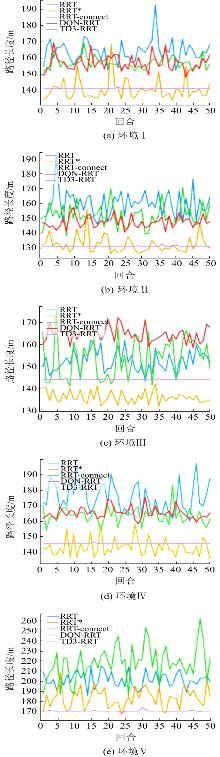
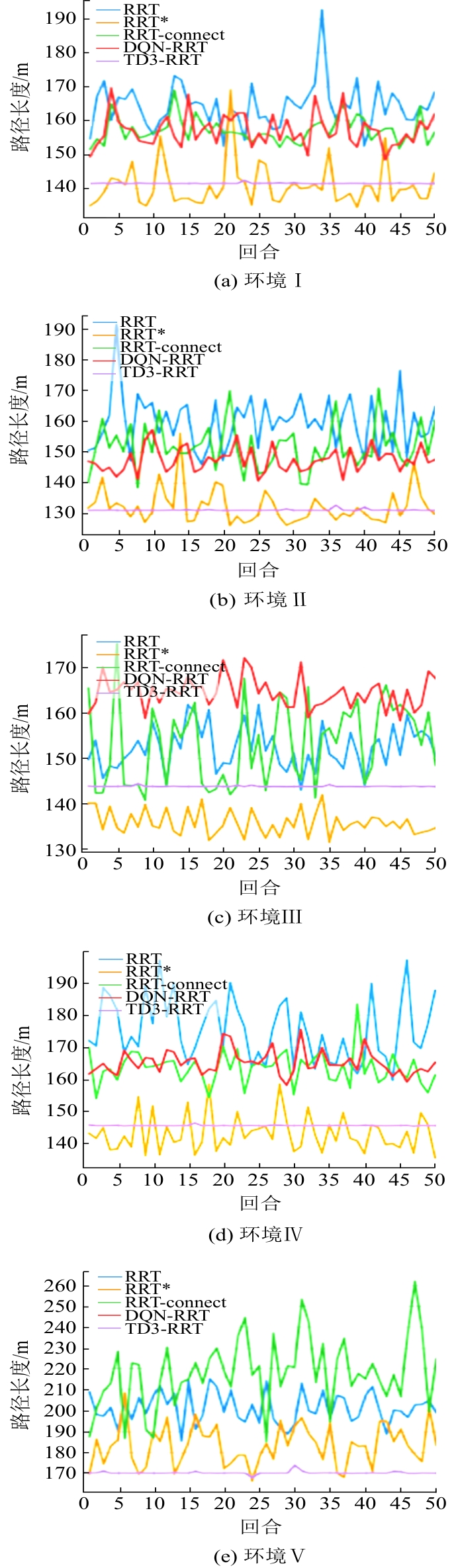
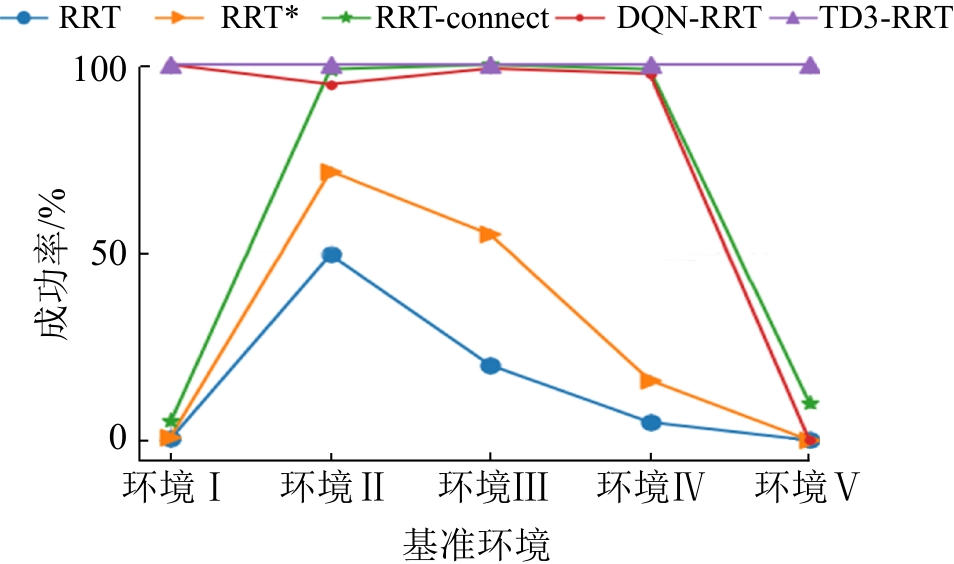
| [1] |
Zhang Dengxing, Chen Chen, Zhang Guanyu. AGV Path Planning Based on Improved A-star Algorithm[C]//2024 IEEE 7th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC). Piscataway: IEEE, 2024: 1590-1595.
|
| [2] |
Fan Xiaojing, Guo Yinjing, Liu Hui, et al. Improved Artificial Potential Field Method Applied for AUV Path Planning[J]. Mathematical Problems in Engineering, 2020, 2020(1): 6523158.
|
| [3] |
Ubaidillah Achmad, Sukri Hanifudin. Application of Odometry and Dijkstra Algorithm as Navigation and Shortest Path Determination System of Warehouse Mobile Robot[J]. Journal of Robotics and Control, 2023, 4(3): 413-423.
|
| [4] |
Zhang Jingcheng, An Yuqiang, Cao Jianing, et al. UAV Trajectory Planning for Complex Open Storage Environments Based on an Improved RRT Algorithm[J]. IEEE Access, 2023, 11: 23189-23204.
|
| [5] |
Chen Zihong, Zhang Xing, Wang Liangyan, et al. A Fast Path Planning Method Based on RRT Star Algorithm[C]//2023 3rd International Conference on Consumer Electronics and Computer Engineering (ICCECE). Piscataway: IEEE, 2023: 258-262.
|
| [6] |
Tu Zhixin, Zhuang Wenbing, Leng Yuquan, et al. Accelerated Informed RRT*: Fast and Asymptotically Path Planning Method Combined with RRT*-connect and APF[C]//International Conference on Intelligent Robotics and Applications. Singapore: Springer Nature Singapore, 2023: 279-292.
|
| [7] |
Tu Haiyan, Deng Yizhao, Li Qiyang, et al. Improved RRT Global Path Planning Algorithm Based on Bridge Test[J]. Robotics and Autonomous Systems, 2024, 171: 104570.
|
| [8] |
Gu Qiyong, Zhen Rong, Liu Jialun, et al. An Improved RRT Algorithm Based on Prior AIS Information and DP Compression for Ship Path Planning[J]. Ocean Engineering, 2023, 279: 114595.
|
| [9] |
Huang Jie, Sun Wei. A Method of Feasible Trajectory Planning for UAV Formation Based on Bi-directional Fast Search Tree[J]. Optik, 2020, 221: 165213.
|
| [10] |
Nguyen T T, Nguyen N D, Nahavandi S. Deep Reinforcement Learning for Multiagent Systems: A Review of Challenges, Solutions, and Applications[J]. IEEE Transactions on Cybernetics, 2020, 50(9): 3826-3839.
|
| [11] |
Sun Qingqiang, Ge Zhiqiang. A Survey on Deep Learning for Data-driven Soft Sensors[J]. IEEE Transactions on Industrial Informatics, 2021, 17(9): 5853-5866.
|
| [12] |
Wang Ruihui, Xu Li. Application of Deep Reinforcement Learning in UAVs: A Review[C]//2022 34th Chinese Control and Decision Conference (CCDC). Piscataway: IEEE, 2022: 4096-4103.
|
| [13] |
Wang Haodong, Hao Jiangyu, Wu Wenhao, et al. A New AGV Path Planning Method Based on PPO Algorithm[C]//2023 42nd Chinese Control Conference (CCC). Piscataway: IEEE, 2023: 3760-3765.
|
| [14] |
李昭莹, 欧一鸣, 石若凌. 基于深度Q网络的改进RRT路径规划算法[J]. 空天防御, 2021, 4(3): 17-23.
|
|
Li Zhaoying, Yiming Ou, Shi Ruoling. Improved RRT Path Planning Algorithm Based on Deep Q-network[J]. Air & Space Defense, 2021, 4(3): 17-23.
|
| [15] |
Qiu Yue, Zhou Suyang, Xia Dong, et al. Local Integrated Energy System Operational Optimization Considering Multi-type Uncertainties: A Reinforcement Learning Approach Based on Improved TD3 Algorithm[J]. IET Renewable Power Generation, 2023, 17(9): 2236-2256.
|
| [16] |
Bhourji R S, Mozaffari S, Alirezaee S. Reinforcement Learning DDPG–PPO Agent-based Control System for Rotary Inverted Pendulum[J]. Arabian Journal for Science and Engineering, 2024, 49(2): 1683-1696.
|
| [17] |
Hu Yutao, Zhao Yuntao, Feng Yongxin, et al. OneR-DQN: A Botnet Traffic Detection Model Based on Deep Q Network Algorithm in Deep Reinforcement Learning[J]. International Journal of Security and Networks, 2024, 19(1): 31-42.
|
| [18] |
Liu Yuchen, Man K L, Li Gangmin, et al. Evaluating and Selecting Deep Reinforcement Learning Models for Optimal Dynamic Pricing: A Systematic Comparison of PPO, DDPG, and SAC[C]//Proceedings of the 2024 8th International Conference on Control Engineering and Artificial Intelligence. New York: ACM, 2024: 215-219.
|
| [19] |
Schramm L, Deng Yunfu, Granados E, et al. USHER: Unbiased Sampling for Hindsight Experience Replay[C]//Proceedings of the 6th Conference on Robot Learning. Chia Laguna Resort: PMLR, 2023: 2073-2082.
|
| [20] |
Shi Chengchun, Zhu Jin, Shen Ye, et al. Off-policy Confidence Interval Estimation with Confounded Markov Decision Process[J]. Journal of the American Statistical Association, 2024, 119(545): 273-284.
|