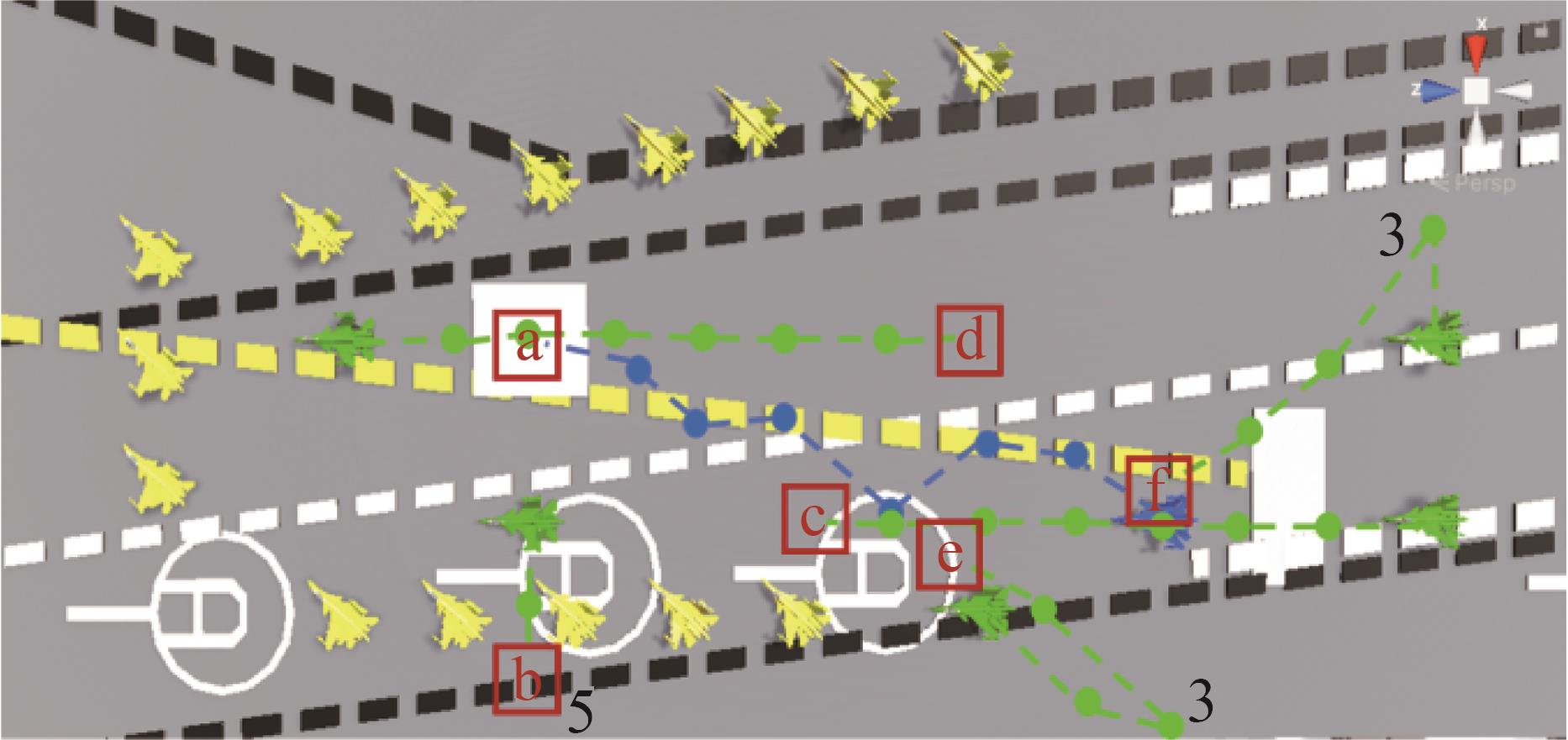
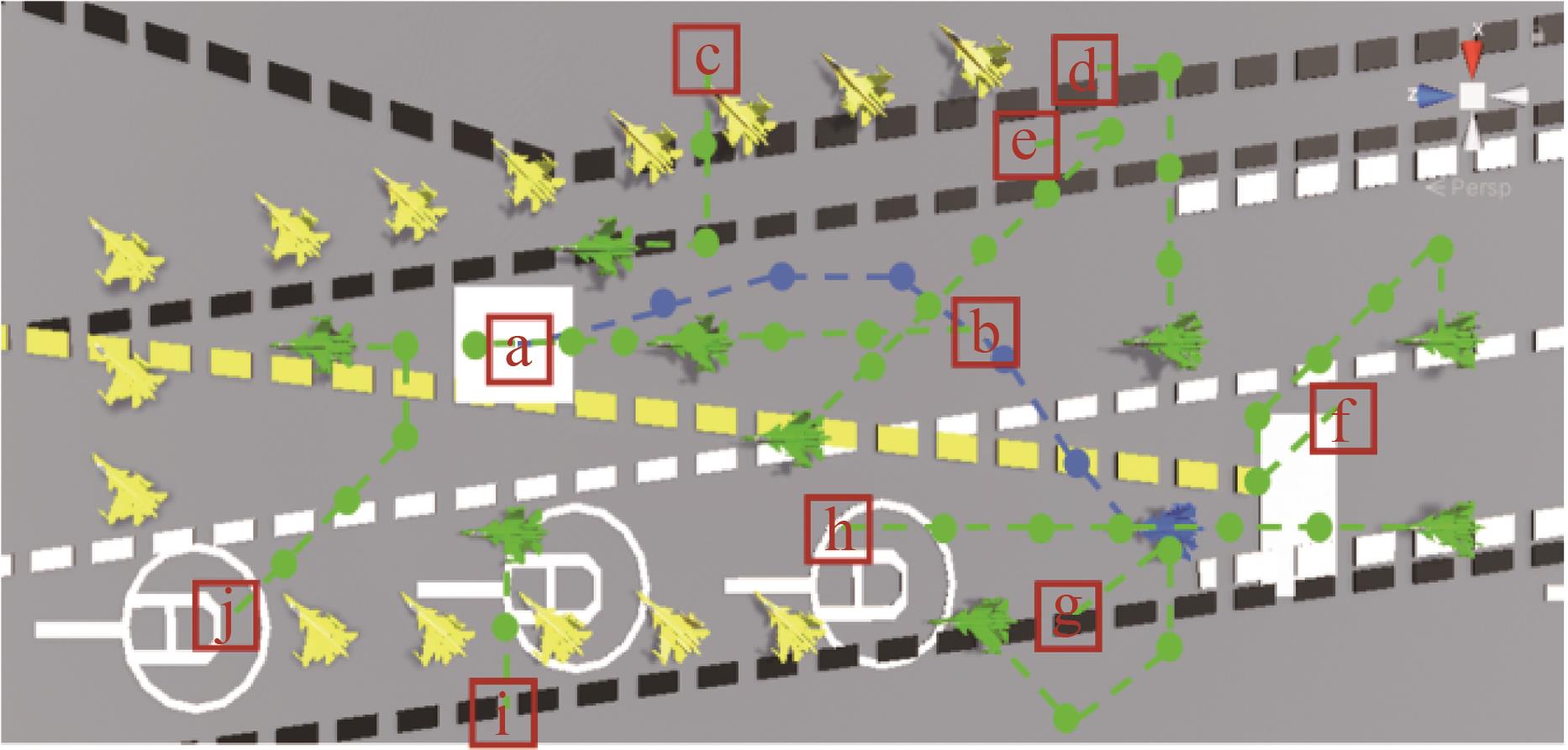
| 1 |
薛均晓, 徐明亮, 李亚飞, 等. 面向航空母舰电子显灵板的多智能体建模技术研究进展[J]. 计算机辅助设计与图形学学报, 2021, 33(10): 1475-1485.
|
|
Xue Junxiao, Xu Mingliang, Li Yafei, et al. Research Progress of Multi-agent Technology for Aircraft Carrier Electronic Display Panel[J]. Journal of Computer Aided Design and Graphics, 2021, 33(10): 1475-1485.
|
| 2 |
Wang J, Meng M Q H. Optimal Path Planning Using Generalized Voronoi Graph and Multiple Potential Functions[J]. IEEE Transactions on Industrial Electronics (S0278-0046), 2020, 67(12): 10621-10630.
|
| 3 |
Dang T, Mascarich F, Khattak S, et al. Graph-Based Path Planning for Autonomous Robotic Exploration in Subterranean Environments[C]// 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). China: IEEE, 2019: 3105-3112.
|
| 4 |
DIJKSTRA E W. A Note on Two Problems in Connexion with Graphs[J]. Numerische Mathematik (S0299-599X), 1959, 1(1): 2569-271.
|
| 5 |
Hart P E, Nilsson N J, Raphael B. A Formal Basis for The Heuristic Determination of Minimum Cost Paths[J]. Acm Sigart Bulletin (S0029-599X), 1972, 4(2): 28-29.
|
| 6 |
Hwang Y K, Ahuja N. A Potential Field Approach to Path Planning[J]. IEEE Transactions on Robotics and Automation (S1070-9932) 1992, 8(1): 23-32.
|
| 7 |
Bruce J, Veloso M M. Real-Time Randomized Path Planning for Robot Navigation[C]// Robot Soccer World Cup. Lausanne, Switzerland: Springer; 2002: 288-295.
|
| 8 |
Stentz A. Intelligent Unmanned Ground Vehicles[M]. Germany: Springer, 1997: 203-220.
|
| 9 |
Dorigo M, Gambardella L M. Ant Colony System: A Cooperative Learning Approach to the Traveling Salesman Problem[J]. IEEE Trans on Evolutionary Computation (S1089-778X), 1997, 1(1): 53-66.
|
| 10 |
Li G, Chou W. Path Planning for Mobile Robot Using Self-adaptive Learning Particle Swarm Optimization[J]. Science China Information Sciences (S1674-733X), 2018, 61(5): 052204.
|
| 11 |
Katoch S, Chauhan S S, Kumar V. A Review on Genetic Algorithm: Past, Present, and Future[J]. Multimedia Tools and Applications (S1380-7501), 2021, 80(5): 8091-8126.
|
| 12 |
Zhang H, Lin W, Chen A. Path Planning for the Mobile Robot: A Review[J]. Symmetry (S2073-8994), 2018, 10(10): 450.
|
| 13 |
Sutton R S, Barto A G. Reinforcement Learning: An Introduction[M]. England: MIT press, 2018.
|
| 14 |
Yan C, Xiang X. A Path Planning Algorithm for UAV Based on Improved Q-learning[C]// 2nd International Conference on Robotics and Automation Sciences (ICRAS).Wuhan, China: IEEE, 2018: 1-5.
|
| 15 |
Bouhamed O, Ghazzai H, Besbes H, et al. Q-learning Based Routing Scheduling for a Multi-task Autonomous Agent[C]// 2019 IEEE 62nd International Midwest Symposium on Circuits and Systems (MWSCAS). USA: IEEE, 2019: 634-637.
|
| 16 |
Sichkar V N. Reinforcement Learning Algorithms in Global Path Planning for Mobile Robot[C]// 2019 International Conference on Industrial Engineering, Applications and Manufacturing (ICIEAM). Sochi, Russia: IEEE, 2019: 1-5.
|
| 17 |
Watkins C J, Dayan P. Q-learning[J]. Machine Learning (S0885-6125), 1992 (3/4): 279-292.
|
| 18 |
Sewak Mohit. Deep Reinforcement Learning[M]. Germany: Springer, 2019: 95-108.
|
| 19 |
Sun Yushan, Ran Xiangrui, Zhang Guocheng, et al. AUV 3D Path Planning Based on the Improved Hierarchical Deep Q Network[J]. Journal of Marine Science and Engineering (S2077-1312), 2020, 8(2): 145.
|
| 20 |
薛均晓, 孔祥燕, 郭毅博, 等. 基于深度强化学习的舰载机动态避障方法[J]. 计算机辅助设计与图形学学报(S1003-9775), 2021, 33(7): 1102-1112.
|
|
Xue Junxiao, Kong Xiangyan, Guo Yibo, et al. Dynamic Obstacle Avoidance Method for Carrier Aircraft Based on Deep Reinforcement Learning[J]. Journal of Computer Aided Design and Graphics (S1003-9775), 2021, 33(7): 1102-1112.
|
| 21 |
Zhang Xi, Liu Youbo, Duan Jiajun, et al. DDPG-based Multi-agent Framework for SVC Tuning in Urban Power Grid with Renewable Energy Resources[J]. IEEE Transactions on Power Systems (S1558-0679), 2021, 36(6): 5465-5475.
|
 ), 孔祥燕1(
), 孔祥燕1(