

Journal of System Simulation ›› 2024, Vol. 36 ›› Issue (6): 1452-1467.doi: 10.16182/j.issn1004731x.joss.23-0349
• Papers • Previous Articles Next Articles
Zhu Jingyu1( ), Zhang Hongli1(), Kuang Minchi2, Shi Heng2, Zhu Jihong2, Qiao zhi2, Zhou Wenqing3
), Zhang Hongli1(), Kuang Minchi2, Shi Heng2, Zhu Jihong2, Qiao zhi2, Zhou Wenqing3
Received:2023-03-29
Revised:2023-05-18
Online:2024-06-28
Published:2024-06-19
Contact:
Zhang Hongli
E-mail:zhujingyu@stu.xju.edu.cn;zhl@xju.edu.cn
CLC Number:
Zhu Jingyu, Zhang Hongli, Kuang Minchi, Shi Heng, Zhu Jihong, Qiao zhi, Zhou Wenqing. Curriculum Learning-based Simulation of UAV Air Combat Under Sparse Rewards[J]. Journal of System Simulation, 2024, 36(6): 1452-1467.
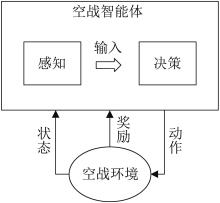
Fig. 1
Basic model of air combat
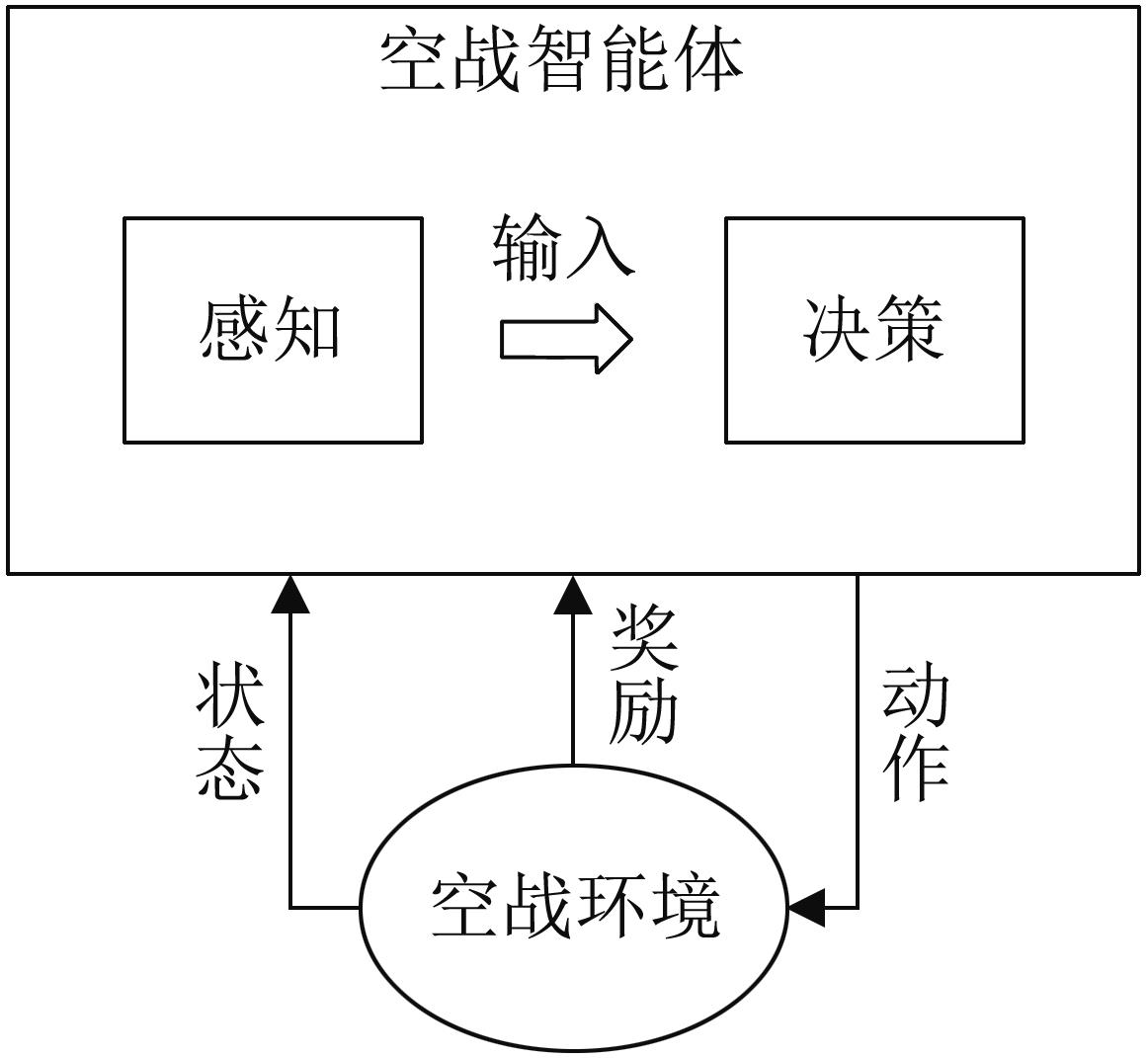
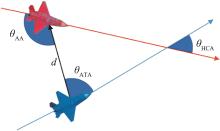
Fig. 2
Air combat angles
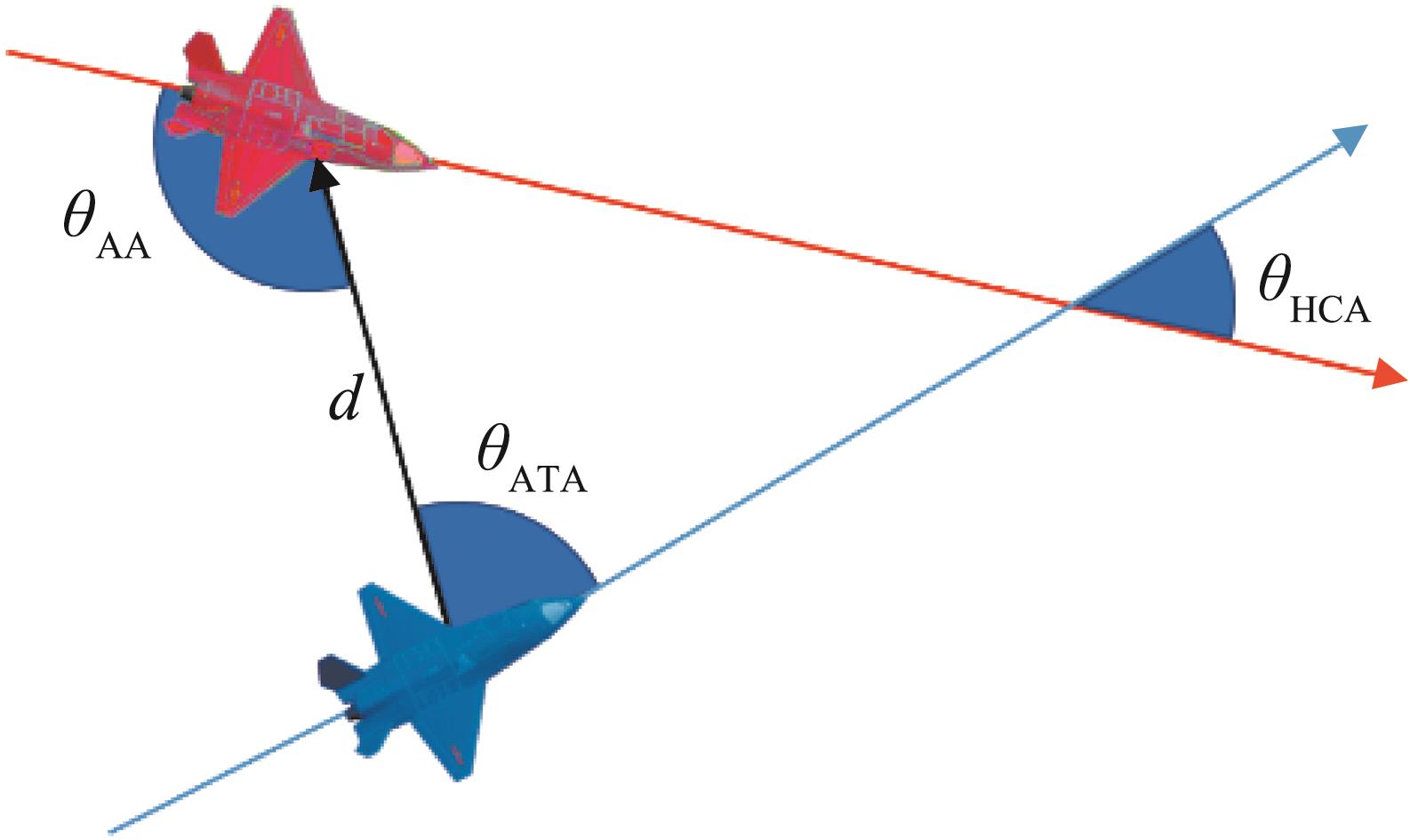
Table 1
Action design
| 类型 | 参数 | 描述 |
|---|---|---|
| 直飞 | 目标俯仰角 | 直飞、拉升和俯冲 |
| 追踪 | 目标位置和方位 | 追踪敌人或预测点 |
| 盘旋 | 滚转角和俯仰轴 | 制定了一系列的固定参数 |
| 筋斗 | 俯仰角 | 用于快速改变方向和位置 |
| 攻击 | 目标预测位置 | 攻击目标预测位置 |
| 躲避 | 报警信息 | 调整机体垂直于报警方向飞行或下高回转 |
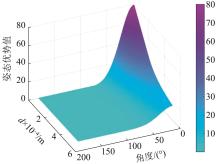
Fig. 3
Aircraft position advantage
Fig. 4
Missile threat reward
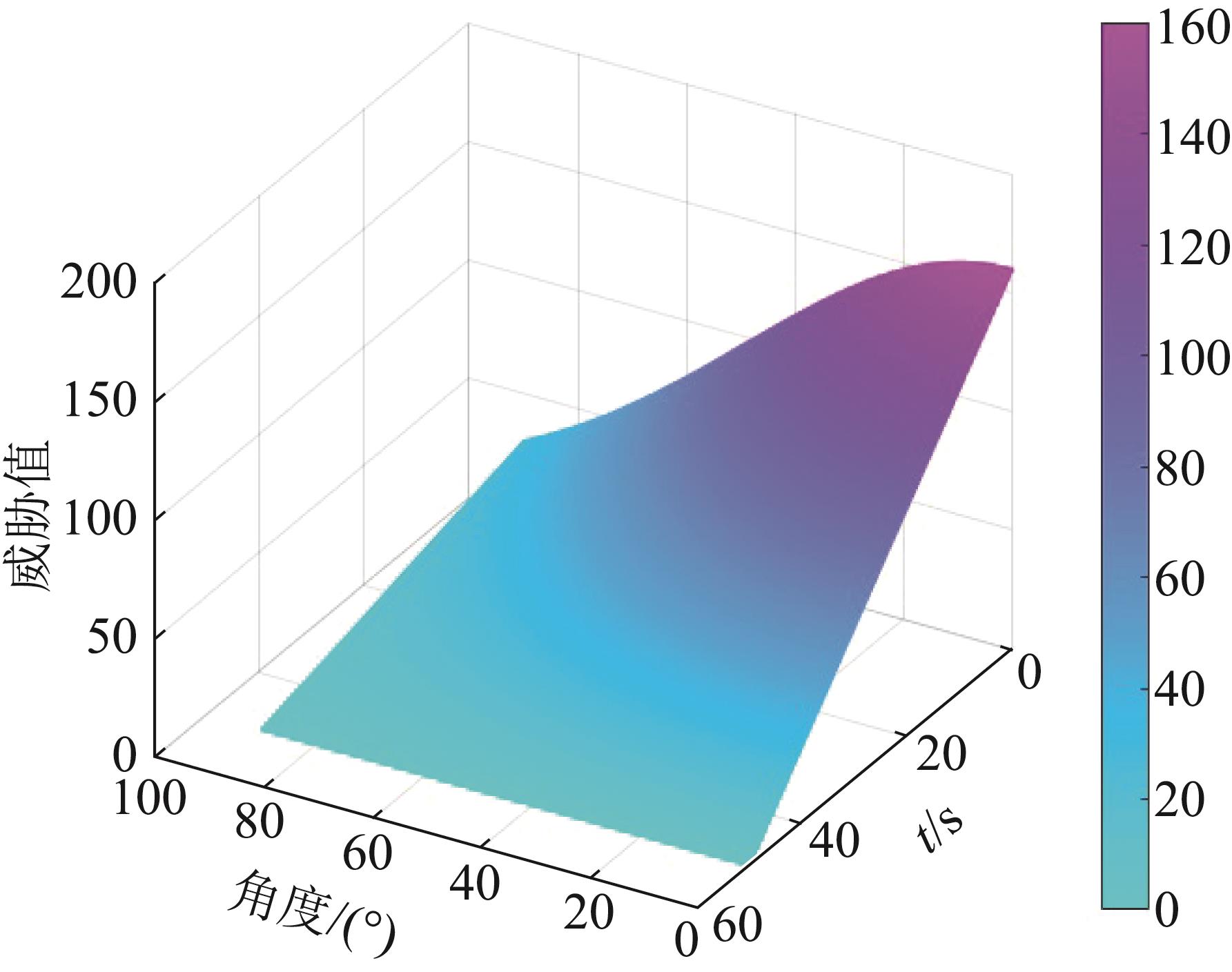
Table 2
Reward design
| 名称 | 奖励 | 奖励类型 | 描述 | 行为意图 |
|---|---|---|---|---|
| 击中 | 640 | 节点事件奖励 | 导弹击中对方敌机 | 鼓励击败敌方 |
| 被击中 | -640 | 节点事件奖励 | 被敌方导弹击中 | 惩罚自身被击中 |
| 发射导弹 | -30~-10 | 节点事件奖励 | 根据剩余导弹变化 | 惩罚发射导弹 |
| 视野 | 20 | 节点事件奖励 | 通过雷达获取到敌方位置 | 鼓励获取敌方视野 |
| 丢失视野 | -20 | 节点事件奖励 | 本机丢失敌方视野 | 惩罚失去敌方视野 |
| 导弹近距离略过 | 50 | 节点事件奖励 | 己方导弹近距离略过敌机 | 鼓励有效发射导弹 |
| 躲避敌方导弹 | 50 | 节点事件奖励 | 己方近距离躲避敌方导弹 | 鼓励躲避来袭导弹 |
| 机体失速 | -80~0 | 连续变化奖励 | 机体失速 | 惩罚机体失速 |
| 侧滑角限幅 | -40~0 | 连续变化奖励 | 限制侧滑角度 | 惩罚过大侧滑角 |
| 导弹威胁 | 0~160 | 连续变化奖励 | 由相对角和接近时间计算 | 鼓励导弹给敌方带来威胁 |
| 姿态优势 | 0~200 | 连续变化奖励 | 根据弹目距离和角度计算 | 鼓励本机出于优势态势 |
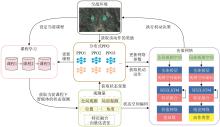
Fig. 5
Air combat model for curriculum learning
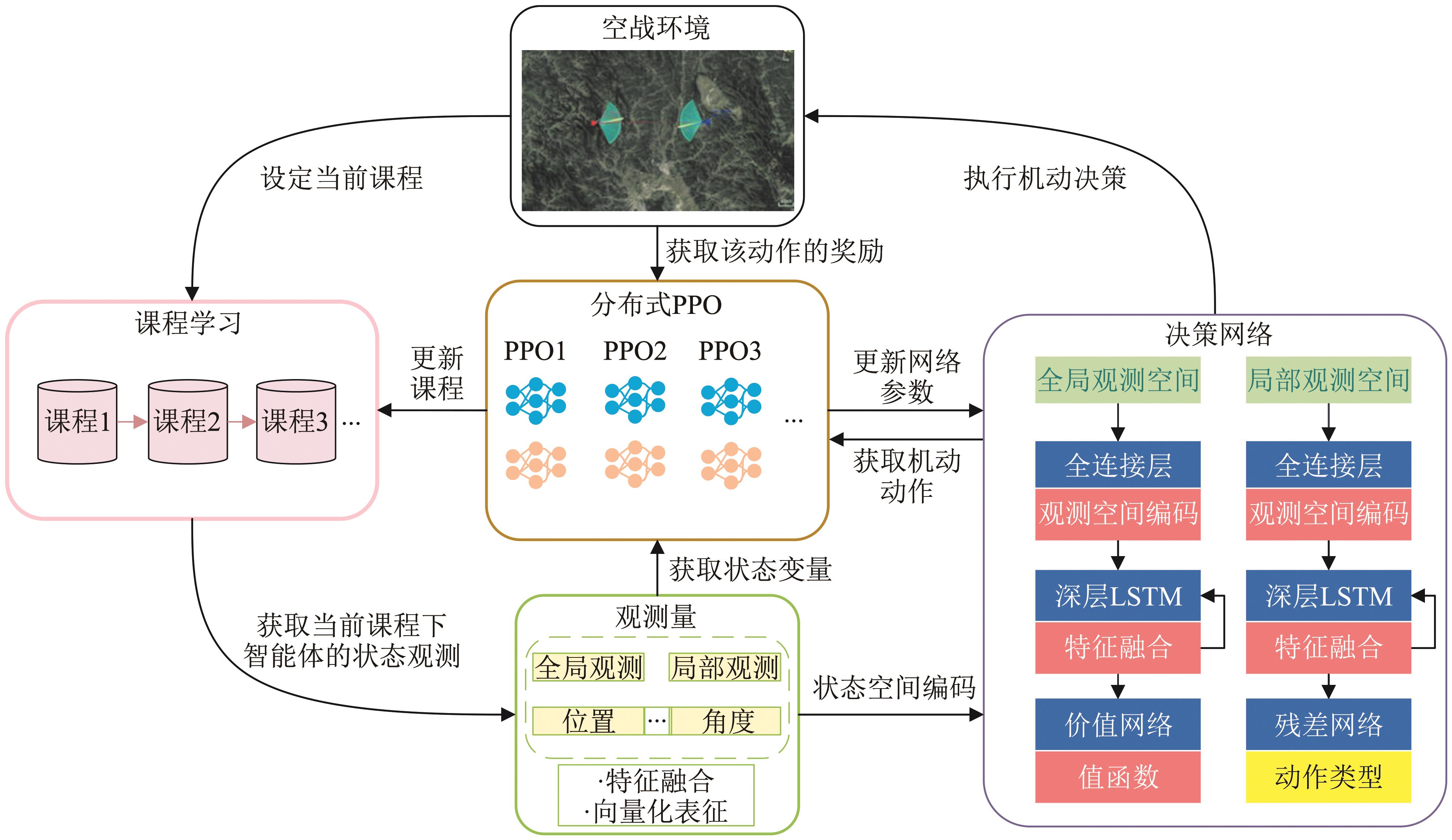
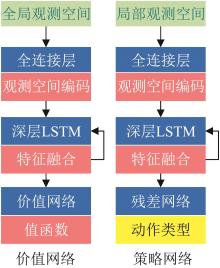
Fig. 6
Decision network architecture
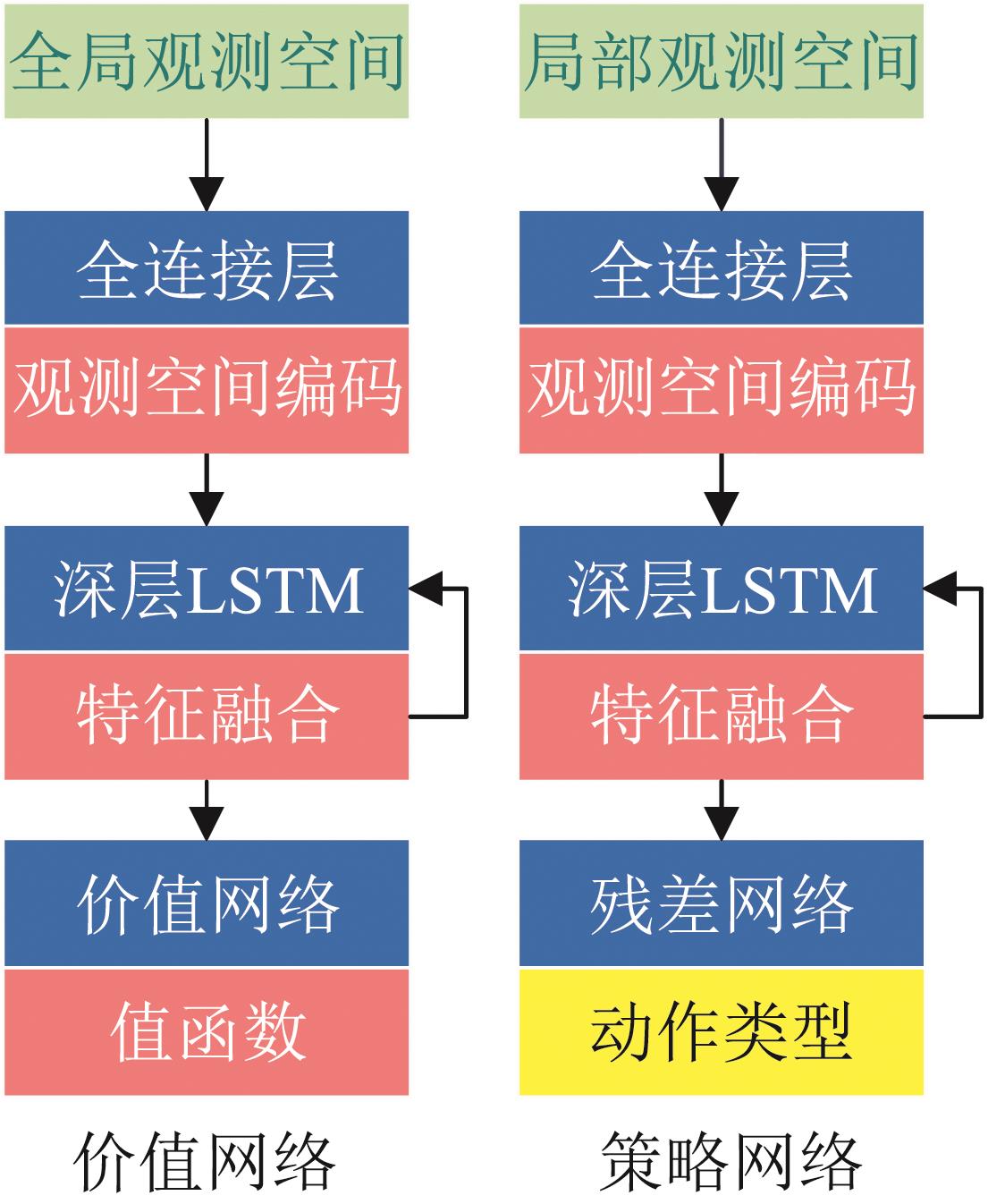
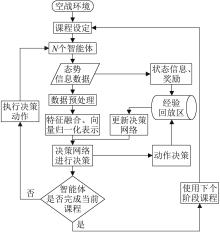
Fig. 7
Single aircraft air combat decision
Fig. 8
Systematic training architecture
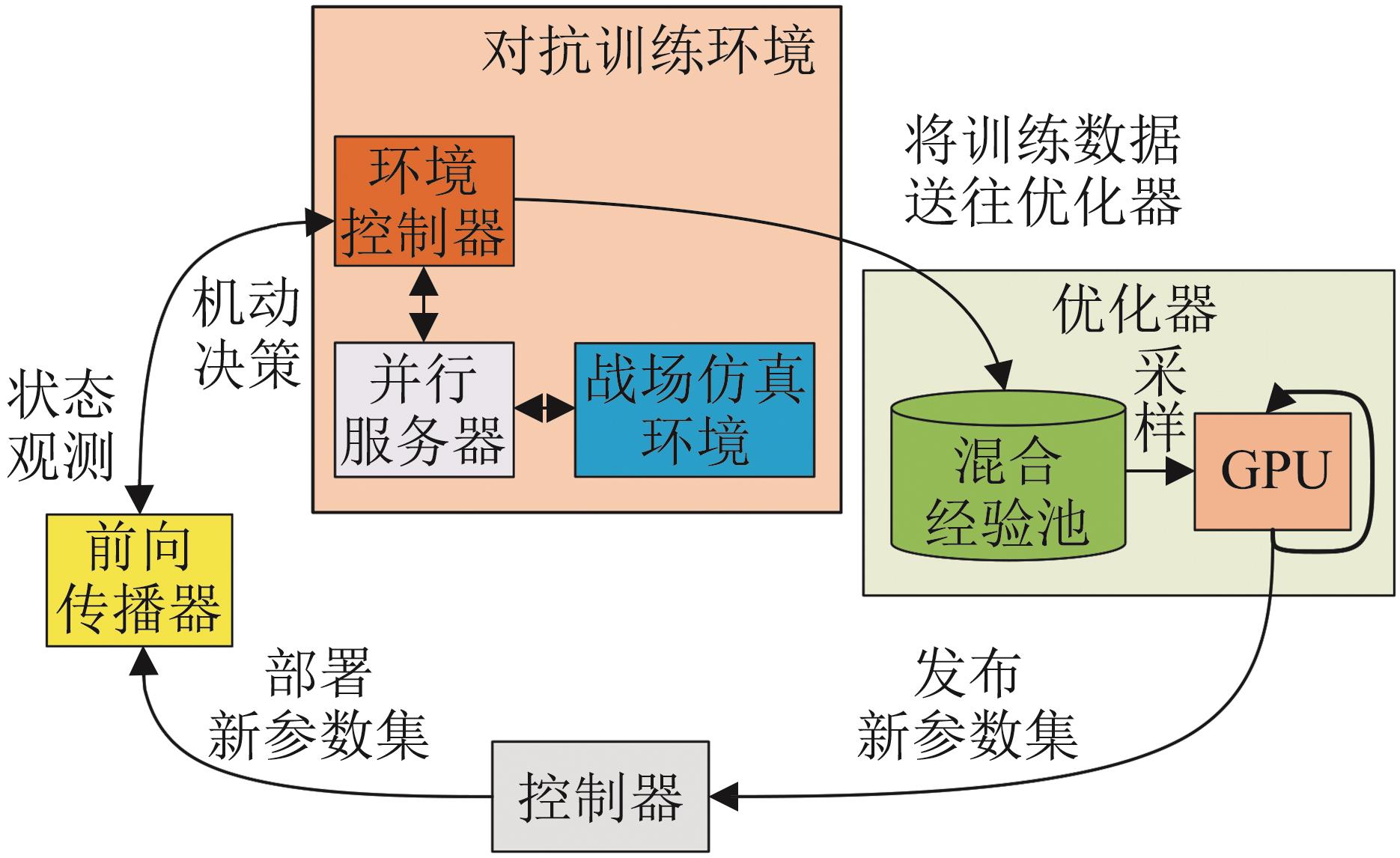
Fig. 9
System architecture
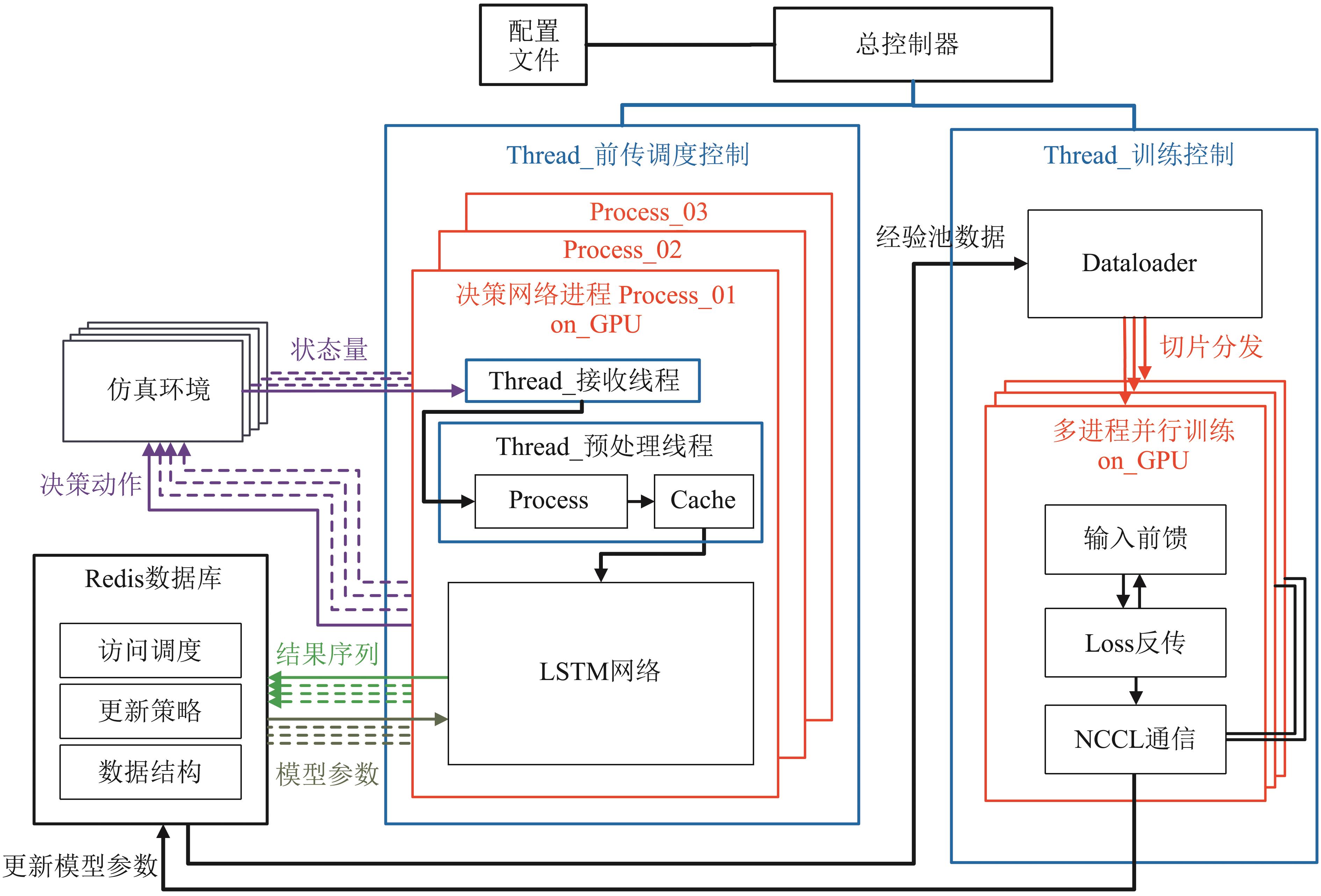
Fig. 10
Red and blue drone combat
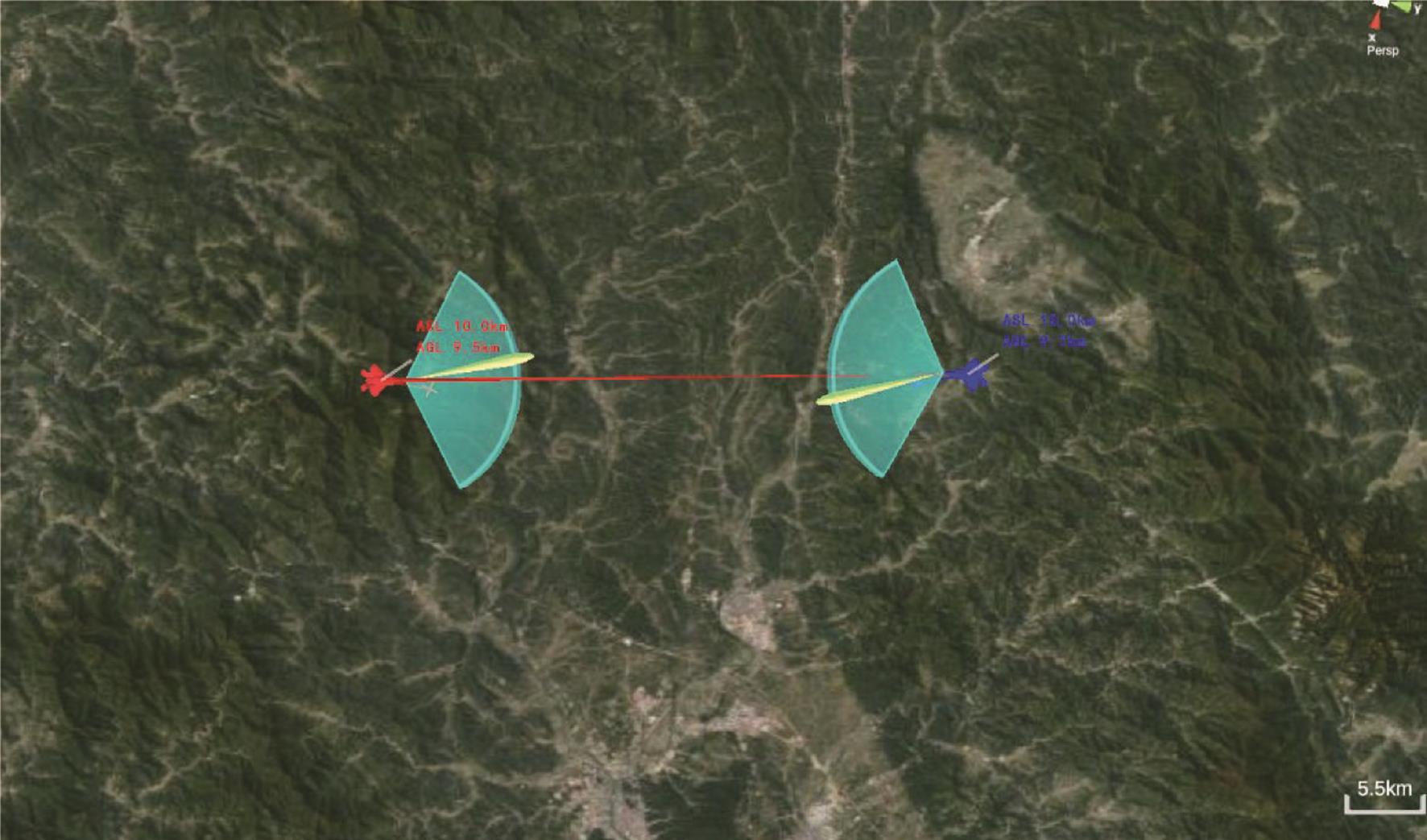

Fig. 11
Distributed parallel battlefield

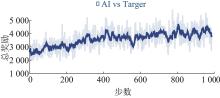
Fig. 12
Total reward for attack curriculum
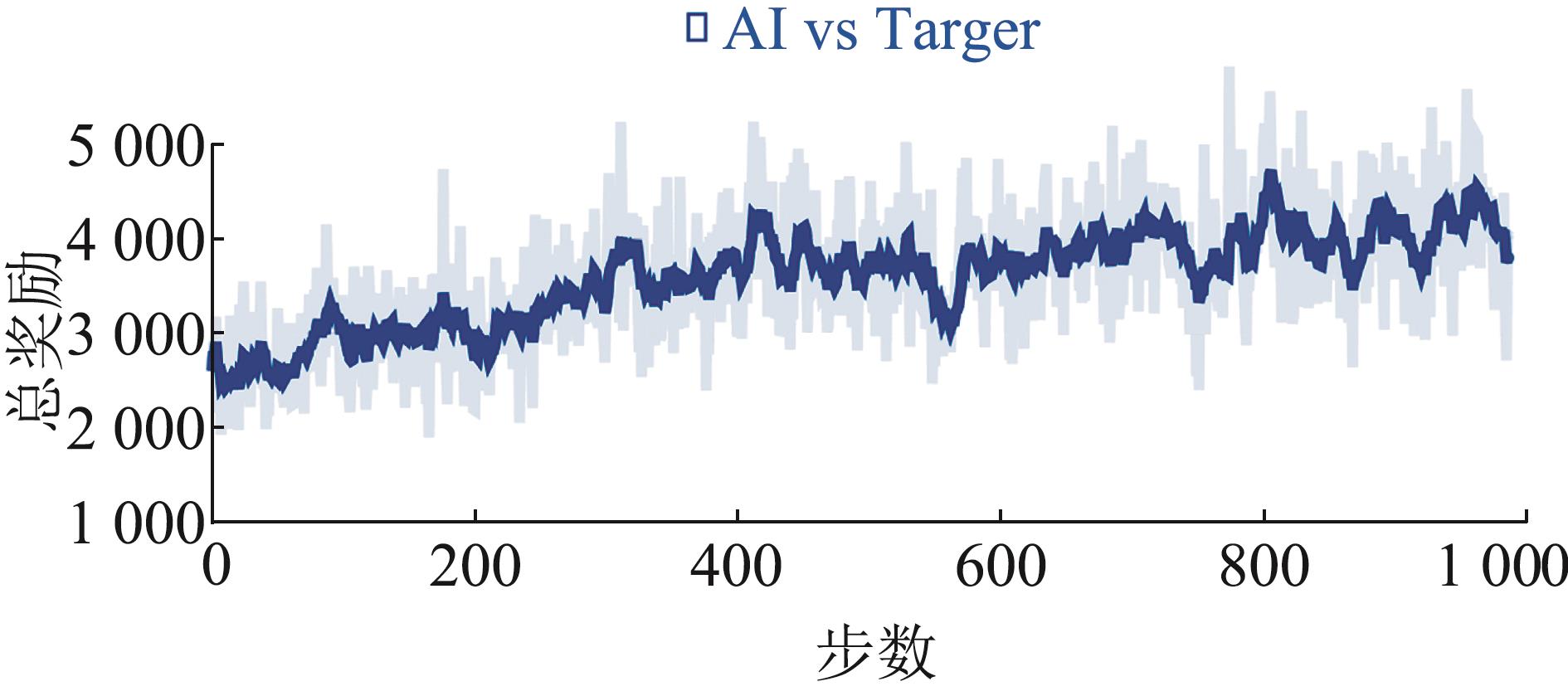
Fig. 13
Loss function of value network
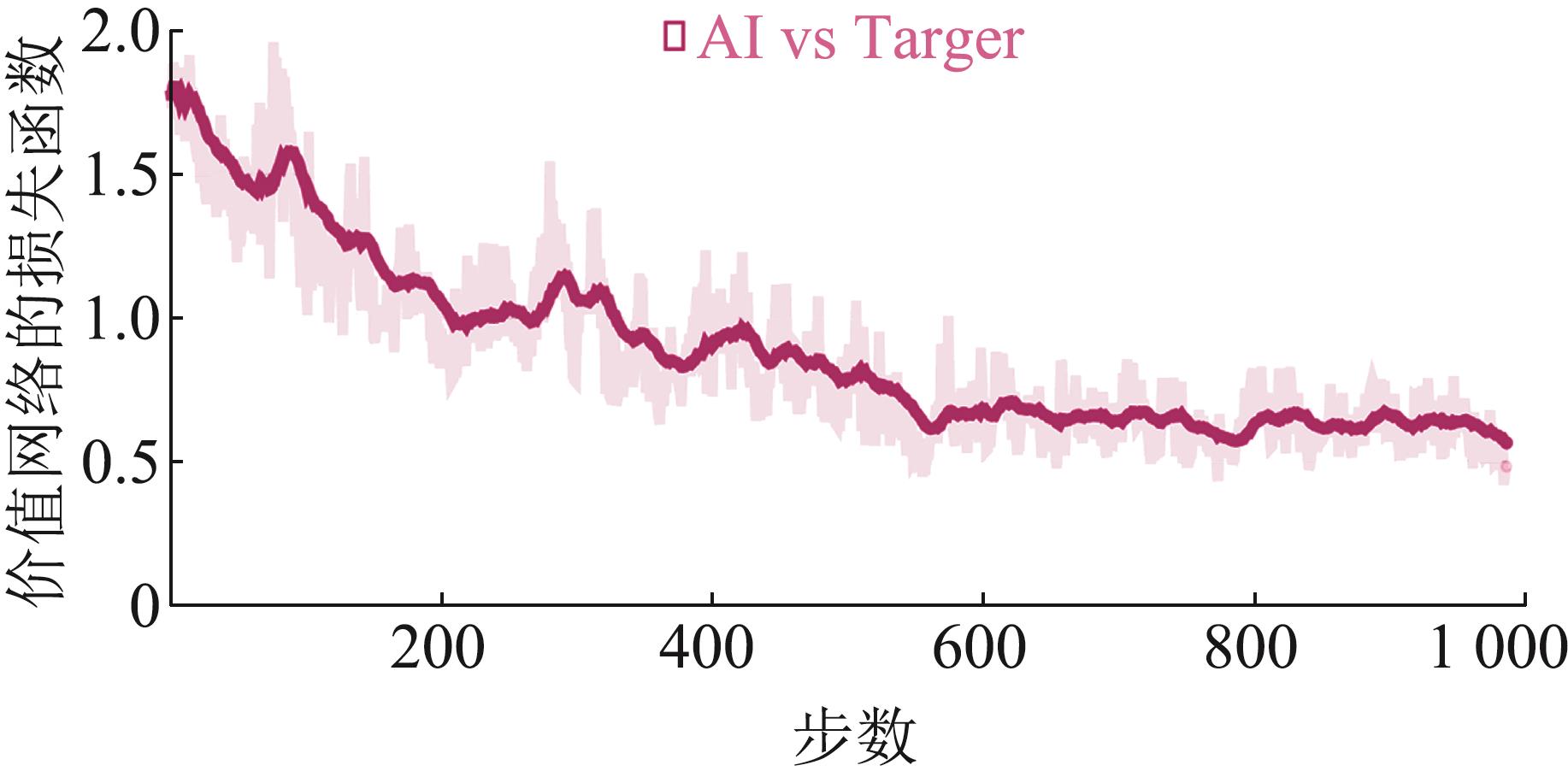
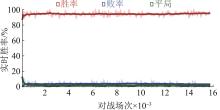
Fig. 14
Real-time win rate against target machines
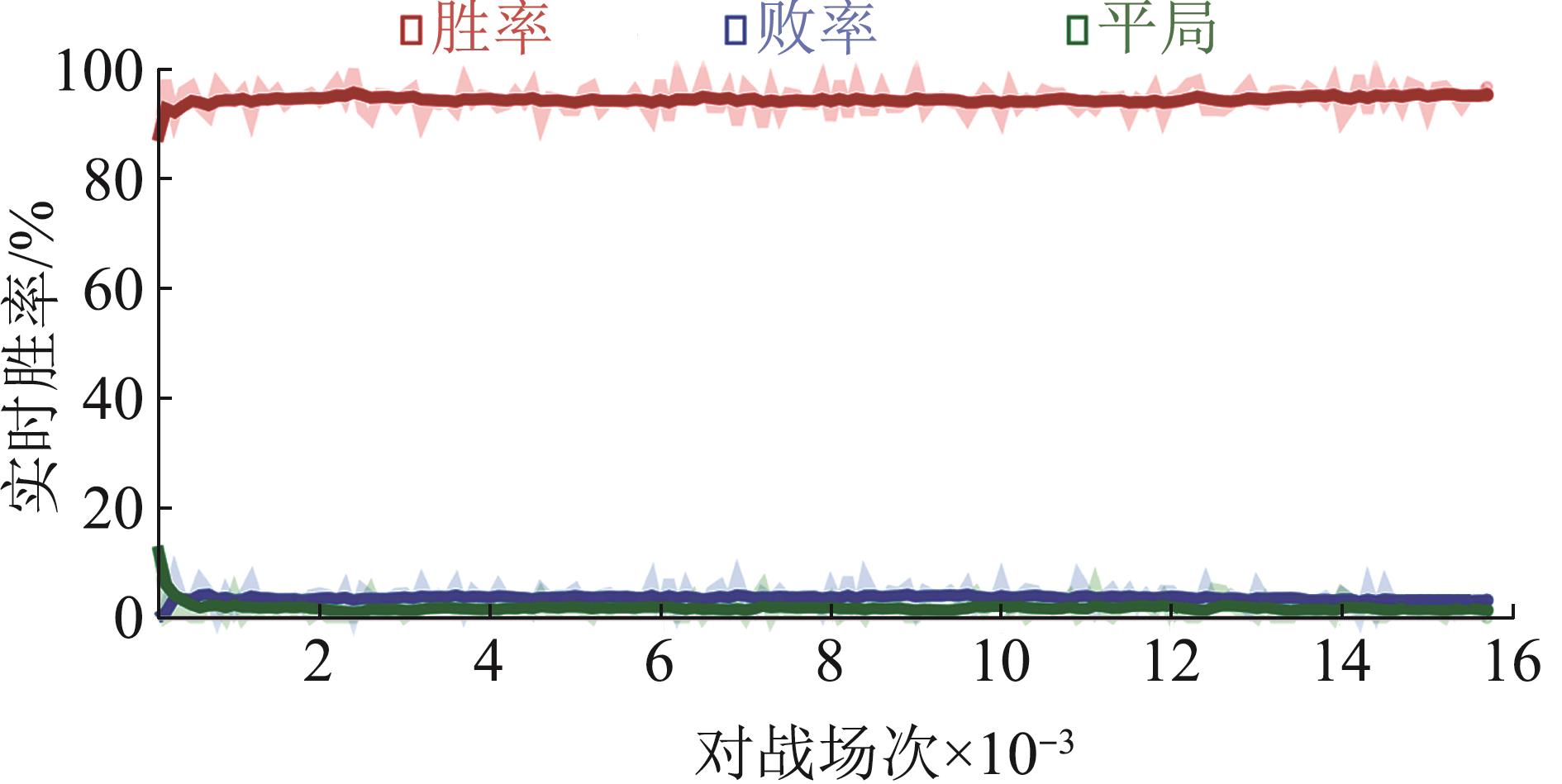

Fig. 15
Real-world scenarios against target aircraft

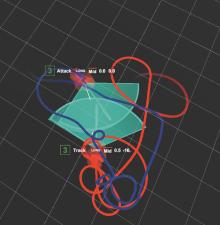
Fig. 16
Defense curriculum practice
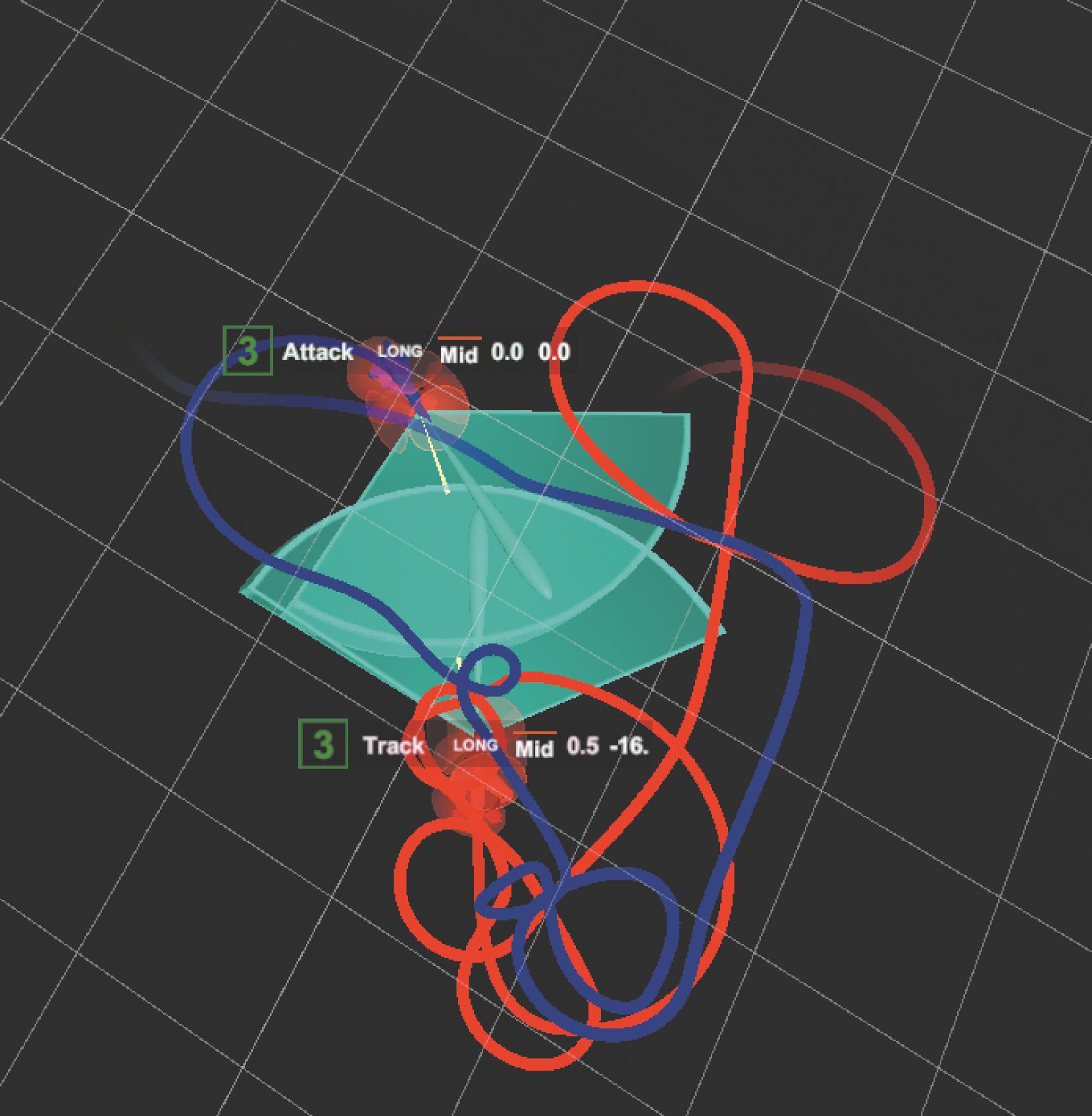
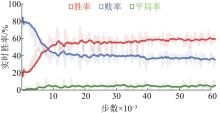
Fig. 17
Real-time win rate for integrated curriculum
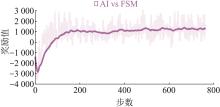
Fig. 18
Total award for integrated curriculum
Table 3
Results of each algorithm against FSM
| 算法 | 胜率 | 失败率 | 平局率 |
|---|---|---|---|
| DQN | 35 | 64 | 1 |
SAC DDPG DPPO | 43 40 47 | 53 55 50 | 4 5 3 |
| CLDPPO | 58 | 36 | 6 |
Table 4
Hyperparameter design of CLDPPO
| 参数名 | 参数值 |
|---|---|
| 用于优化的GPU数量 | 5 |
| 批次数量 | 120 |
| 经验库容量 | 480 |
| 衰减系数 | 0.99 |
| GAE | 0.95 |
| PPO 裁剪系数 | 0.2 |
| 数据复用率 | 1 |
| 模型版本替换频率 | 2 |
| Actor 学习率 | 0.000 5 |
| Critic 学习率 | 0.000 2 |
| 动作的熵系数 | 0.01 |
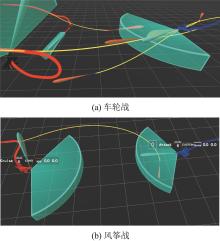
Fig. 19
Tactical performance
Table 5
Ablation experiments for key rewards
| 算法 | 胜率 | 失败率 | 平局率 |
|---|---|---|---|
本文算法 -视野奖励 | 58 56 | 36 37 | 6 7 |
-失速 -侧滑角 -躲避导弹 -近距离导弹 | 55 55 54 53 | 38 39 40 40 | 7 6 6 7 |
-姿态优势 -导弹威胁奖励 | 51 48 | 44 50 | 5 2 |
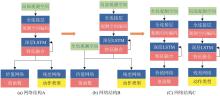
Fig. 20
Comparative experiment of network structure
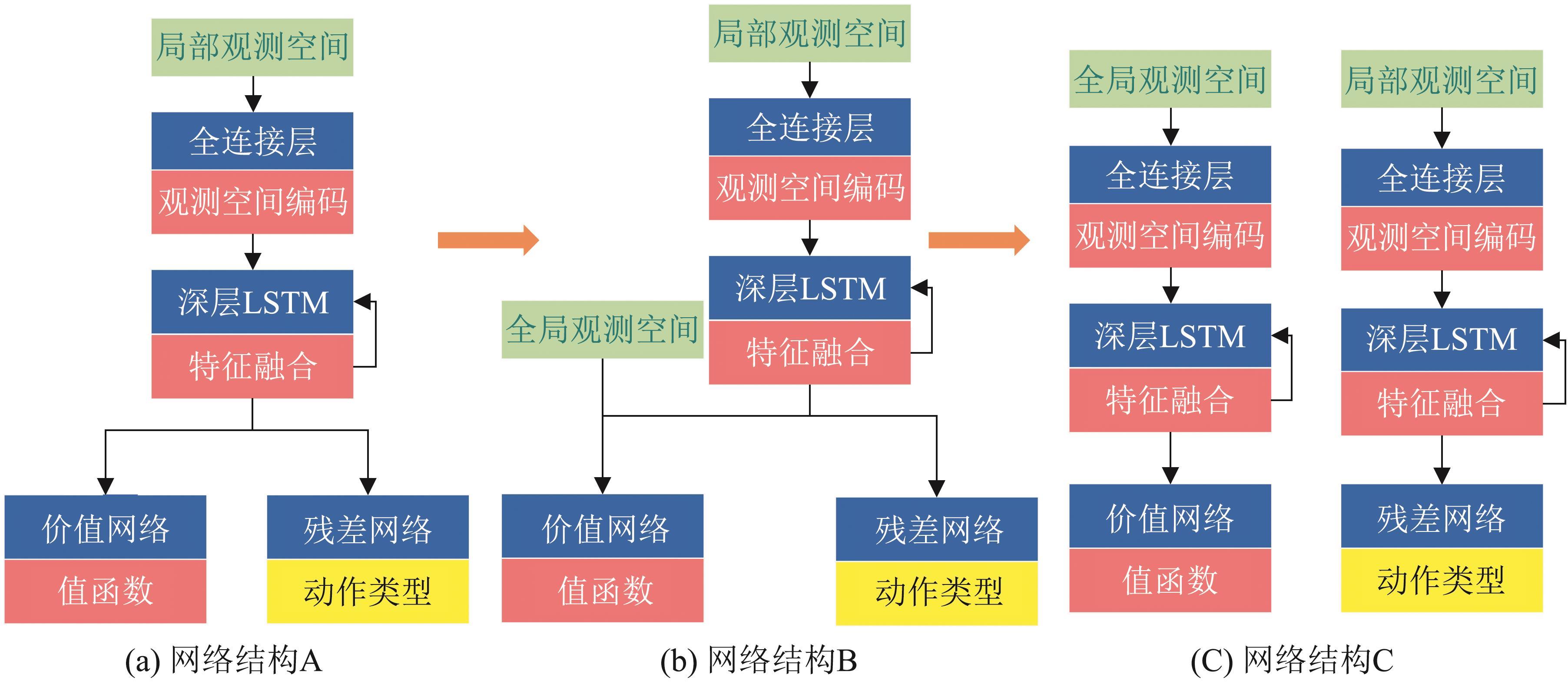
Table 6
Performance of different network architectures %
| 网络结构 | 胜率 | 失败率 | 平局率 |
|---|---|---|---|
| A | 50 | 45 | 5 |
| B | 54 | 41 | 5 |
| C | 58 | 36 | 6 |
| 1 | 孙智孝, 杨晟琦, 朴海音, 等. 未来智能空战发展综述[J]. 航空学报, 2021, 42(8): 28-42. |
| Sun Zhixiao, Yang Shengqi, Haiyin Piao, et al. A Survey of Air Combat Artificial Intelligence[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(8): 28-42. | |
| 2 | Burgin G H, Owens A J. An Adaptive Maneuvering Logic Computer Program for the Simulation of One-to-one Air-to-air Combat. Volume 2: Program Description[EB/OL]. (1975-09-01)[2020-10-02]. . |
| 3 | Geng Wenxue, Kong Fan'e, Ma Dongqian. Study on Tactical Decision of UAV Medium-range Air Combat[C]//The 26th Chinese Control and Decision Conference (2014 CCDC). Piscataway, NJ, USA: IEEE, 2014: 135-139. |
| 4 | Li Shouyi, Chen Mou, Wang Yuhui, et al. Air Combat Decision-making of Multiple UCAVs Based on Constraint Strategy Games[J]. Defence Technology, 2022, 18(3): 368-383. |
| 5 | Li Weihua, Shi Jingping, Wu Yunyan, et al. A Multi-UCAV Cooperative Occupation Method Based on Weapon Engagement Zones for Beyond-visual-range Air Combat[J]. Defence Technology, 2022, 18(6): 1006-1022. |
| 6 | 左家亮, 杨任农, 张滢, 等. 基于启发式强化学习的空战机动智能决策[J]. 航空学报, 2017, 38(10): 212-225. |
| Zuo Jialiang, Yang Rennong, Zhang Ying, et al. Intelligent Decision-making in Air Combat Maneuvering Based on Heuristic Reinforcement Learning[J]. Acta Aeronautica et Astronautica Sinica, 2017, 38(10): 212-225. | |
| 7 | Liu Pin, Ma Yaofei. A Deep Reinforcement Learning Based Intelligent Decision Method for UCAV Air Combat[C]//Modeling, Design and Simulation of Systems. Singapore: Springer Singapore, 2017: 274-286. |
| 8 | Yang Qiming, Zhu Yan, Zhang Jiandong, et al. UAV Air Combat Autonomous Maneuver Decision Based on DDPG Algorithm[C]//2019 IEEE 15th International Conference on Control and Automation (ICCA). Piscataway, NJ, USA: IEEE, 2019: 37-42. |
| 9 | Lei Xie, Ding Dali, Wei Zhenglei, et al. Moving Time UCAV Maneuver Decision Based on the Dynamic Relational Weight Algorithm and Trajectory Prediction[J]. Mathematical Problems in Engineering, 2021, 2021: 6641567. |
| 10 | Pope A P, Ide J S, Mićović Daria, et al. Hierarchical Reinforcement Learning for Air-to-air Combat[C]//2021 International Conference on Unmanned Aircraft Systems (ICUAS). Piscataway, NJ, USA: IEEE, 2021: 275-284. |
| 11 | Crumpacker J B, Robbins M J, Jenkins P R. An Approximate Dynamic Programming Approach for Solving an Air Combat Maneuvering Problem[J]. Expert Systems with Applications, 2022, 203: 117448. |
| 12 | 曾贲, 房霄, 孔德帅, 等. 一种数据驱动的对抗博弈智能体建模方法[J]. 系统仿真学报, 2021, 33(12): 2838-2845. |
| Zeng Ben, Fang Xiao, Kong Deshuai, et al. A Data-driven Modeling Method for Game Adversity Agent[J]. Journal of System Simulation, 2021, 33(12): 2838-2845. | |
| 13 | 赵毓, 郭继峰, 颜鹏, 等. 稀疏奖励下多航天器规避决策自学习仿真[J]. 系统仿真学报, 2021, 33(8): 1766-1774. |
| Zhao Yu, Guo Jifeng, Yan Peng, et al. Self-learning-based Multiple Spacecraft Evasion Decision Making Simulation Under Sparse Reward Condition[J]. Journal of System Simulation, 2021, 33(8): 1766-1774. | |
| 14 | Haiyin Piao, Sun Zhixiao, Meng Guanglei, et al. Beyond-visual-range Air Combat Tactics Auto-generation by Reinforcement Learning[C]//2020 International Joint Conference on Neural Networks (IJCNN). Piscataway, NJ, USA: IEEE, 2020: 1-8. |
| 15 | 施伟, 冯旸赫, 程光权, 等. 基于深度强化学习的多机协同空战方法研究[J]. 自动化学报, 2021, 47(7): 1610-1623. |
| Shi Wei, Feng Yanghe, Cheng Guangquan, et al. Research on Multi-aircraft Cooperative Air Combat Method Based on Deep Reinforcement Learning[J]. Acta Automatica Sinica, 2021, 47(7): 1610-1623. | |
| 16 | Kong Weiren, Zhou Deyun, Yang Zhen. Air Combat Strategies Generation of CGF Based on MADDPG and Reward Shaping[C]//2020 International Conference on Computer Vision, Image and Deep Learning (CVIDL). Piscataway, NJ, USA: IEEE, 2020: 651-655. |
| 17 | McGrew J S, How J P, Williams B, et al. Air-combat Strategy Using Approximate Dynamic Programming[J]. Journal of Guidance, Control, and Dynamics, 2010, 33(5): 1641-1654. |
| 18 | 周文卿, 朱纪洪, 匡敏驰, 等. 基于预知博弈树的多无人机群智协同空战算法[J]. 中国科学(技术科学), 2023, 53(2): 187-199. |
| Zhou Wenqing, Zhu Jihong, Kuang Minchi, et al. Multi-UAV Cooperative Swarm Algorithm in Air Combat Based on Predictive Game Tree[J]. Scientia Sinica(Technologica), 2023, 53(2): 187-199. | |
| 19 | Bengio Y, Louradour Jérôme, Collobert R, et al. Curriculum Learning[C]//Proceedings of the 26th Annual International Conference on Machine Learning. New York, NY, USA: Association for Computing Machinery, 2009: 41-48. |
| 20 | Schulman J, Wolski F, Dhariwal P, et al. Proximal Policy Optimization Algorithms[EB/OL]. (2017-08-28) [2021-01-21]. . |
| 21 | Schulman J, Moritz P, Levine S, et al. High-dimensional Continuous Control Using Generalized Advantage Estimation[EB/OL]. (2018-10-20) [2021-02-22]. . |
| 22 | Berner C, Brockman G, Chan B, et al. Dota 2 with Large Scale Deep Reinforcement Learning[J]. (2019-12-13) [2021-12-03]. . |
| 23 | 周文卿, 朱纪洪, 匡敏驰. 一种基于群体智能的无人空战系统[J]. 中国科学(信息科学), 2020, 50(3): 363-374. |
| Zhou Wenqing, Zhu Jihong, Kuang Minchi. An Unmanned Air Combat System Based on Swarm Intelligence[J]. Scientia Sinica(Informationis), 2020, 50(3): 363-374. | |
| 24 | Silver D, Lever G, Heess N, et al. Deterministic Policy Gradient Algorithms[C]//Proceedings of the 31st International Conference on International Conference on Machine Learning. Chia Laguna Resort, Sardinia, Italy: PMLR, 2014: 387-395. |
| 25 | Haarnoja T, Zhou A, Abbeel P, et al. Soft Actor-critic: Off-policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor[C]//Proceedings of the 35th International Conference on Machine Learning. Chia Laguna Resort, Sardinia, Italy: PMLR, 2018: 1861-1870. |
| [1] | Zhou Zicong, Zeng Junjie, Hu Yue, Zhu Zhengqiu, Yin Quanjun. Multi-agent Reinforcement Learning Method for Wargame Simulation Based on Suboptimal Demonstration Guidance [J]. Journal of System Simulation, 2026, 38(5): 1277-1289. |
| [2] | Li Qiuni, Wang Dong, Wang Chaozhe, Liu Zongcheng. A BiLSTM+Attention Method for Predicting the Intentions of Air Combat Targets Based on Multi-feature Continuous Time Series [J]. Journal of System Simulation, 2026, 38(4): 948-958. |
| [3] | Zheng Wei, Tang Jiahao, Xiong Xiaoping, Fan Xin. Intelligent Decision-making Method in Imbalanced Air Combat Based on Asymmetric Self-play [J]. Journal of System Simulation, 2026, 38(2): 433-446. |
| [4] | Zhang Ziyao, Ji Yunfeng. Simulation of Robotic Arm Ball-catching Strategy Based on Curriculum RL of Transformer [J]. Journal of System Simulation, 2026, 38(2): 321-331. |
| [5] | Ding Zhengkun, Liu Jiaqi, Xu Junzheng, Xu Yuezhu, Wang Xingmei. Intelligent Air Combat Decision-making Method Based on BiGRU and Priority Dynamic Sampling [J]. Journal of System Simulation, 2026, 38(2): 447-459. |
| [6] | Yu Xiang, Deng Qianrui, Duan Sirui, Jiang Chen. A Multi-UAV Collaborative Priority Coverage Search Algorithm [J]. Journal of System Simulation, 2024, 36(4): 991-1000. |
| [7] | Cheng Jie, Zheng Yuan, Li Chenglong, Jiang Bo. Multi-UAV Collaborative Trajectory Planning Algorithm for Urban Ultra-low-altitude Air Transportation Scenario [J]. Journal of System Simulation, 2024, 36(1): 50-66. |
| [8] | Tuo Zhao, Hanqiang Deng, Jialong Gao, Jian Huang. Dynamic Target Assignment of Multiple Unmanned Aerial Vehicles Based on Clustering of Network Nodes [J]. Journal of System Simulation, 2023, 35(4): 695-708. |
| [9] | Wang Yukun, Wang Ze, Dong Liwei, Li Ni. Research on Multi-aircraft Air Combat Behavior Modeling Based on Hierarchical Intelligent Modeling Methods [J]. Journal of System Simulation, 2023, 35(10): 2249-2261. |
| [10] | Wang Chenguang, Bai Jinpeng, Li Tingting, Miao Lifeng, Wang Kaifeng. Reliability Evaluation Method of Radar Simulation Model Based on Air Combat Mechanism [J]. Journal of System Simulation, 2023, 35(10): 2113-2121. |
| [11] | Sen Zhang, Mengyan Zhang, Jingping Shao, Jiexin Pu. Multi-UAVs 3D Path Planning Method Based on Random Strategy Search [J]. Journal of System Simulation, 2022, 34(6): 1286-1295. |
| [12] | Zhao Yu, Guo Jifeng, Yan Peng, Bai Chengchao. Self-learning-based Multiple Spacecraft Evasion Decision Making Simulation Under Sparse Reward Condition [J]. Journal of System Simulation, 2021, 33(8): 1766-1774. |
| [13] | Zhou Nan, Ai Jianliang. Speech Control Scheme Design and Simulation for UAV Based on HMM and RNN [J]. Journal of System Simulation, 2020, 32(3): 464-471. |
| [14] | Cao Huimin, Huang Anxiang, Lei Xiang. Evaluation Method of Imminent Battle Situation in Air Combat [J]. Journal of System Simulation, 2019, 31(2): 257-263. |
| [15] | Kou Ya’nan, Jiang Longting, Wang Dong. High-order reconstruction of maneuvering decision-making process in close air combat [J]. Journal of System Simulation, 2019, 31(10): 2085-2092. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
