

Journal of System Simulation ›› 2022, Vol. 34 ›› Issue (9): 1941-1955.doi: 10.16182/j.issn1004731x.joss.21-0363
• Modeling Theory and Methodology • Previous Articles
Junren Luo( ), Wanpeng Zhang(), Weilin Yuan, Zhenzhen Hu, Shaofei Chen, Jing Chen
), Wanpeng Zhang(), Weilin Yuan, Zhenzhen Hu, Shaofei Chen, Jing Chen
Received:2021-04-27
Revised:2021-06-30
Online:2022-09-18
Published:2022-09-23
Contact:
Wanpeng Zhang
E-mail:luojunren17@nudt.edu.cn;wpzhang@nudt.edu.cn
CLC Number:
Junren Luo, Wanpeng Zhang, Weilin Yuan, Zhenzhen Hu, Shaofei Chen, Jing Chen. Research on Opponent Modeling Framework for Multi-agent Game Confrontation[J]. Journal of System Simulation, 2022, 34(9): 1941-1955.
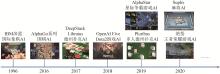
Fig. 1
Research progress of intelligent game confrontation
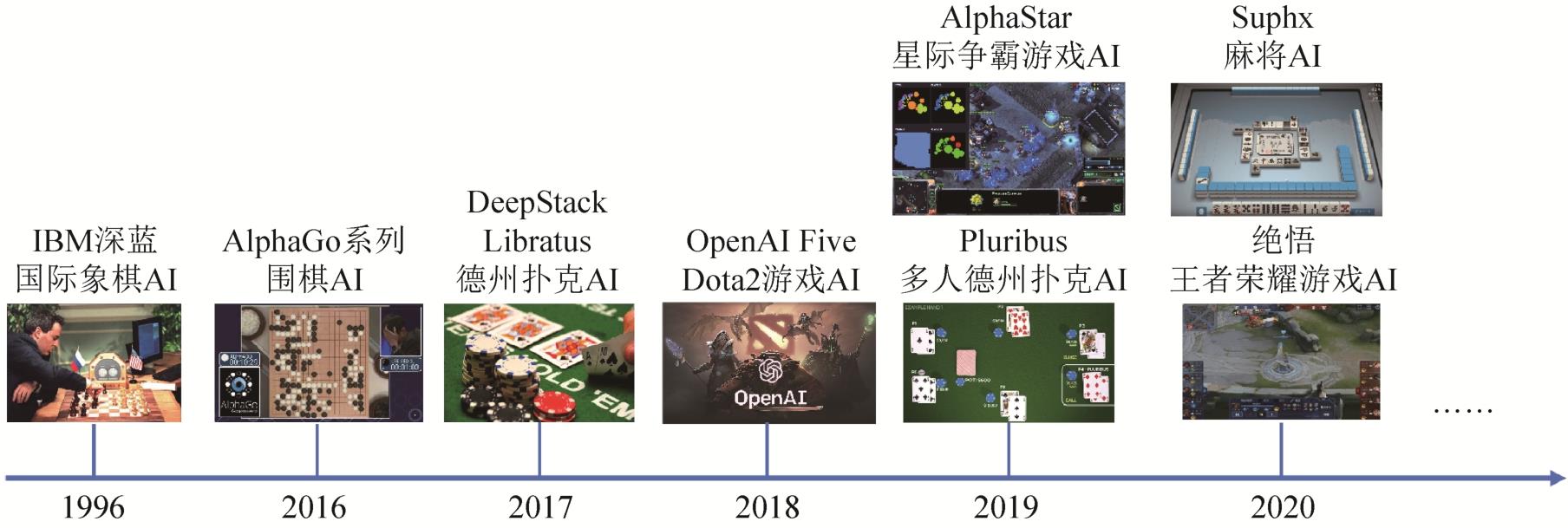
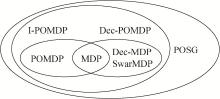
Fig. 2
Related models of partial observation stochastic game
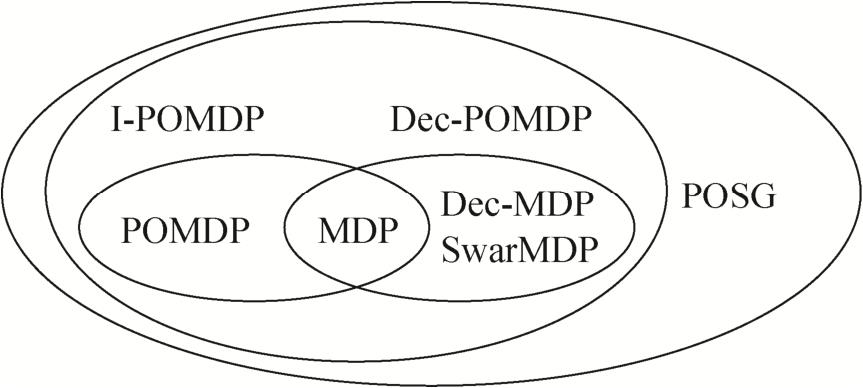
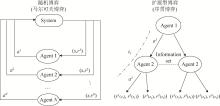
Fig. 3
Typical models of multi-agent game
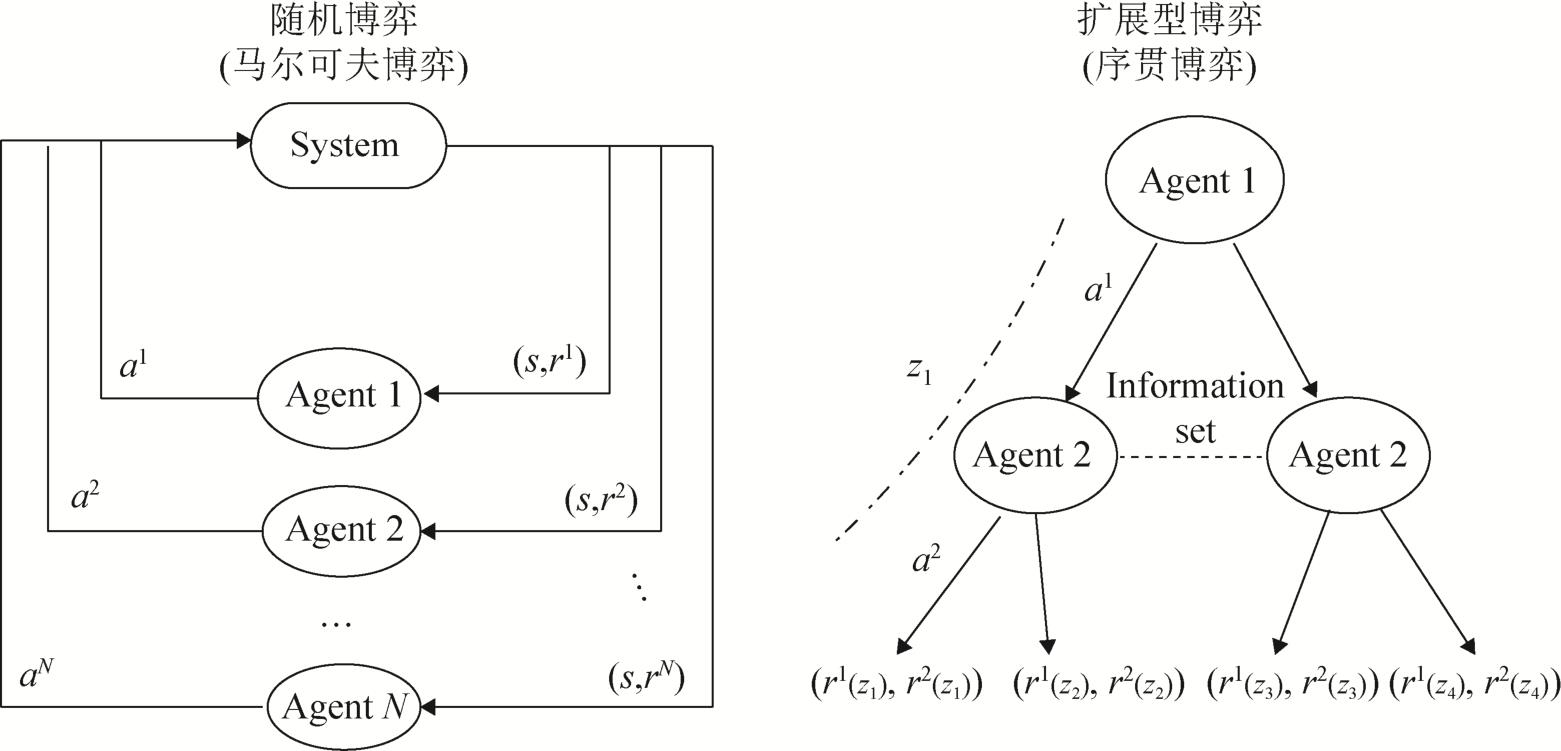
Table 1
Reinforcement learning, game theory and meta-game
| 强化学习(reinforcement learning) | 博弈论(game theory) | 元博弈(meta-game) |
|---|---|---|
| 环境(environment) | 博弈(game) | 博弈(game) |
| 智能体(agent) | 参与方(player) | 种群(population) |
| 行动(action) | 行动(action) | 类型(type) |
| 策略(policy) | 策略(strategy) | 分布(distribution) |
| 奖励(reward) | 收益(payoff) | 适应度(fitness) |
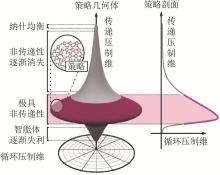
Fig. 4
Geometry of game strategies
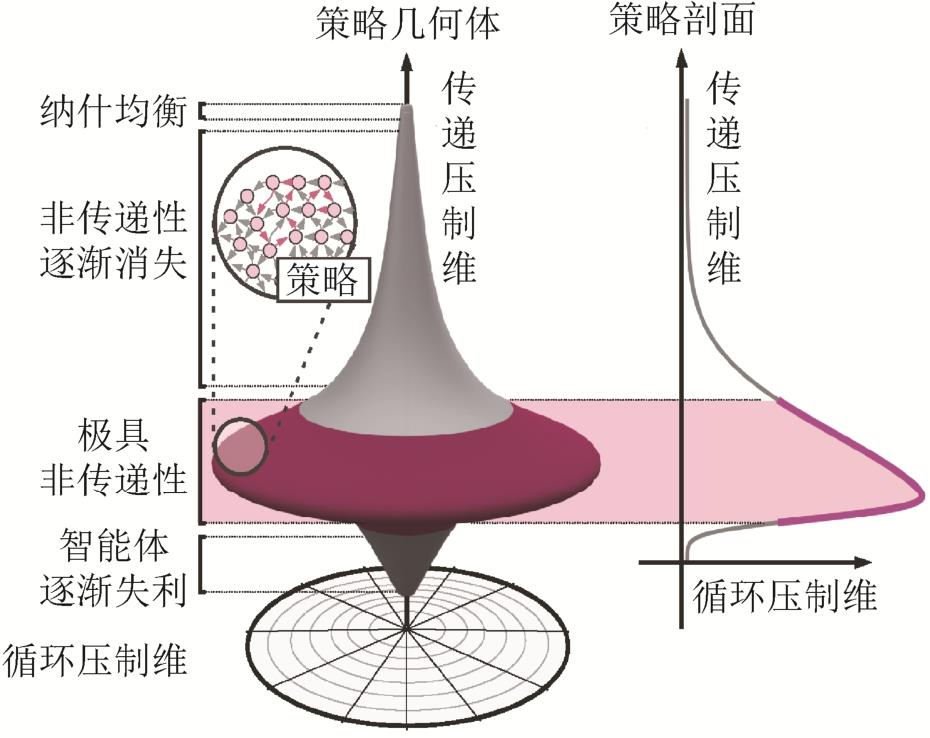

Fig. 5
Strategy learning methods for multi-agent game confrontation

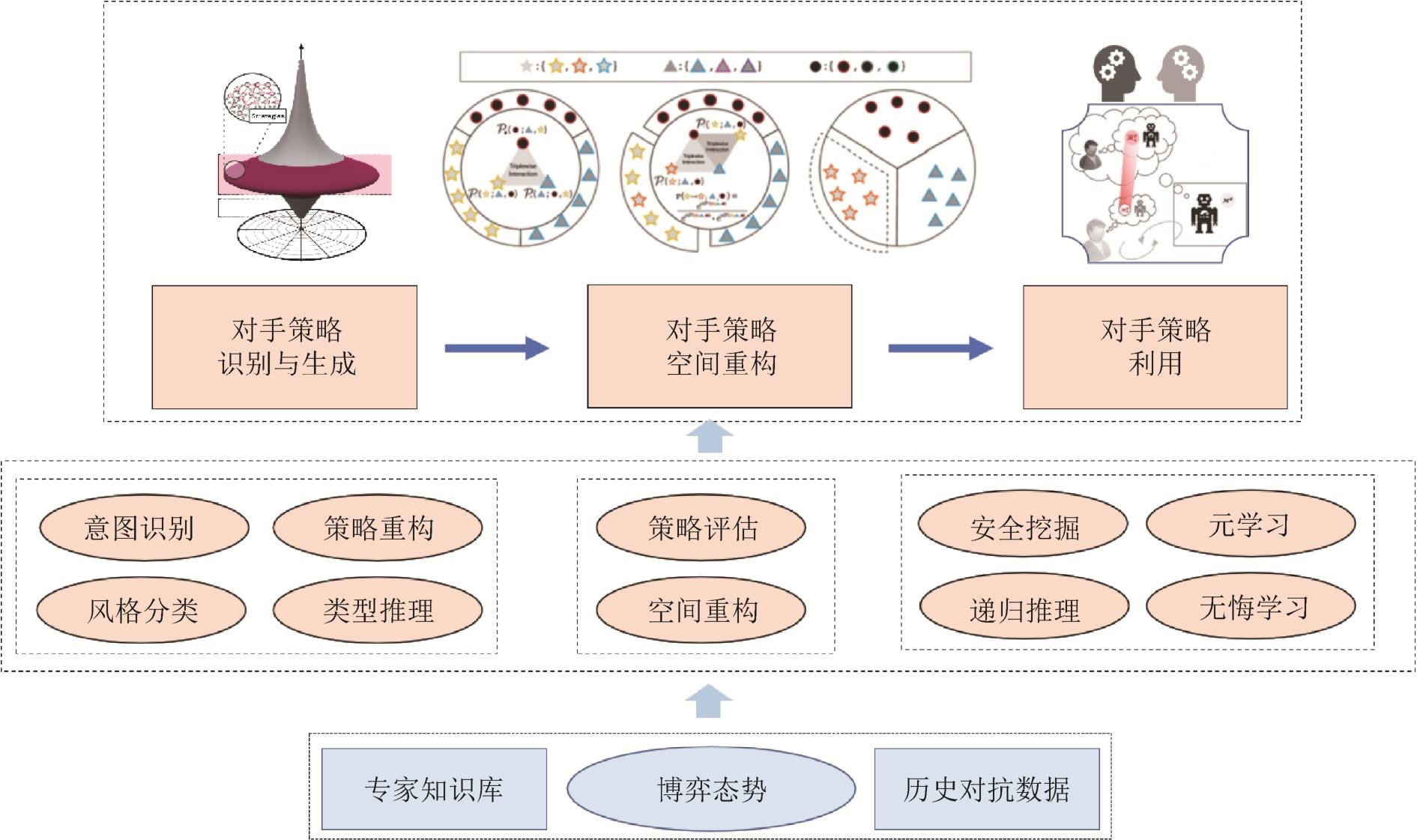
Fig. 6
Opponent modeling framework for multi-agent game confrontation
| [1] | Omidshafiei S, Tuyls K, Czarnecki W M, et al. Navigating the Landscape of Multiplayer Games[J].Nature Communications (S2041-1723), 2020, 11(1): 1-17. |
| [2] | Silver D, Schrittwieser J, Simonyan K, et al. Mastering the Game of Go Without Human Knowledge[J]. Nature (S1476-4687), 2017, 550(7676): 354-359. |
| [3] | Brown N, Sandholm T. Superhuman AI for multiplayer poker[J]. Science (S1095-9203), 2019, 365(6456): 885-890. |
| [4] | Vinyals O, Babuschkin I, Czarnecki W M, et al. Grandmaster Level in StarCraft II Using Multi-agent Reinforcement Learning[J]. Nature (S1476-4687), 2019, 575(7782): 350-354. |
| [5] | Li J, Koyamada S, Ye Q, et al. Suphx: Mastering Mahjong with Deep Reinforcement Learning[EB/OL].(2020-04-01)[2021-01-15]. . |
| [6] | Neu G, Jonsson A, Gómez V. A Unified View of Entropy-Regularized Markov Decision Processes[EB/OL].[2017-05-19]. . |
| [7] | Choy J, Lee K, Oh S. Sparse Actor-Critic: Sparse Tsallis Entropy Regularized Reinforcement Learning in a Continuous Action Space[C]// 17th International Conference on Ubiquitous Robots (UR). Kyoto Japan:IEEE, 2020: 68-73. |
| [8] | Grau Moya J, Leibfried F, Bou Ammar H. Balancing Two-Player Stochastic Games with Soft Q-Learning[C]//27th International Joint Conference on Artificial Intelligence. Stockholm Sweden: AAAI Press, 2018: 268-274. |
| [9] | Oliehoek F A, Amato C. A Concise Introduction to Decentralized POMDPs[M]. Berlin, Heidelberg: Springer, 2016. |
| [10] | Doshi P, Zeng Y, Chen Q. Graphical Models for Interactive POMDPs: Representations and Solutions[J].Autonomous Agents and Multi-agent Systems (S1387-2532), 2009, 18(3): 376-416. |
| [11] | Fei Y, Yang Z, Wang Z, et al. Dynamic Regret of Policy Optimization in Non-stationary Environments[C]// 34th International Conference on Neural Information Processing Systems. Vancouver BC Canada: Curran Associates, 2020: 6743-6754. |
| [12] | Hernandez Leal P, Kaisers M, Baarslag T, et al. A Survey of Learning in Multiagent Environments: Dealing with Non-stationarity[EB/OL]. (2017-07-19)[2021-01-21].. |
| [13] | Brafman R I, Tennenholtz M. R-MAX A General Polynomial Time Algorithm for Near-optimal Reinforcement Learning[J]. Journal of Machine Learning Research (S1532-4435), 2002, 3: 213-231. |
| [14] | Lakkaraju H, Kamar E, Caruana R, et al. Identifying Unknown Unknowns in the Open World:Representations and Policies for Guided Exploration[C]// Thirty-First AAAI Conference on Artificial Intelligence. San Francisco California USA:AAAI Press, 2017: 2124-2132. |
| [15] | Hernandez Leal P, Kaisers M. Learning Against Sequential Opponents in Repeated Stochastic Games[C]// The 3rd Multi-disciplinary Conference on Reinforcement Learning and Decision Making. Ann Arbor, Michigan, USA: RLDM, 2017: 25. |
| [16] | Hernandez Leal P, Zhan Y, Taylor M E, et al.. Efficiently Detecting Switches Against Non-stationary Opponents[J].Autonomous Agents and Multi-agent Systems (S1387-2532), 2017, 31(4): 767-789. |
| [17] | Von Der Osten F B, Kirley M, Miller T. The Minds of Many: Opponent Modelling in a Stochastic Game[C]//26th International Joint Conference on Artificial Intelligence. Melbourne Australia: AAAI Press, 2017: 3845-3851. |
| [18] | Bakkes S C J, Spronck P H M, Van Den Herik H J.Opponent Modelling for Case-Based Adaptive Game AI[J]. Entertainment Computing (S1875-953X), 2009, 1(1): 27-37. |
| [19] | Hernandez Leal P, Munoz de Cote E, Sucar L E. A Framework for Learning and Planning Against Switching Strategies in Repeated Games[J]. Connection Science (S1360-0494), 2014, 26(2): 103-122. |
| [20] | Hernandez Leal P, Zhan Y, Taylor M E, et al. An Exploration Strategy for Non-stationary Opponents[J].Autonomous Agents and Multi-agent Systems (S1387-2532), 2017, 31(5): 971-1002. |
| [21] | Papoudakis G, Christianos F, Rahman A, et al. Dealing with Non-stationarity in Multi-agent Deep Reinforcement Learning[EB/OL].[2019-06-19].. |
| [22] | Albrecht S V, Stone P. Autonomous Agents Modelling other Agents: A Comprehensive Survey and Open Problems[J]. Artificial Intelligence (S0004-3702), 2018, 258: 66-95. |
| [23] | Sukthankar G, Gita C, Bui H, et al. Plan, Activity, and Intent Recognition: Theory and Practice[M]. Oxford: Newnes, 2014. |
| [24] | Mirsky R, Keren S, Geib C. Introduction to Symbolic Plan and Goal Recognition[M]. California: Morgan &Claypool publishers, 2021. |
| [25] | Avrahami Zilberbrand D, Kaminka G A. Incorporating Observer Biases in Keyhole Plan Recognition(efficiently!)[C]// 22nd National Conference on Artificial Intelligence. Vancouver British Columbia Canada: AAAI Press, 2007: 944-949. |
| [26] | Geib C W, Goldman R P. Plan Recognition in Intrusion Detection Systems[C]// DARPA Information Survivability Conference and Exposition II. DISCEX'01.Anaheim, CA, USA: IEEE Computer Society, 2001: 46-55. |
| [27] | Mirsky R, Stern R, Gal K, et al. Sequential Plan Recognition: An Iterative Approach to Disambiguating between Hypotheses[J]. Artificial Intelligence (S1060-0639), 2018, 260: 51-73. |
| [28] | Schadd F, Bakkes S, Spronck P. Opponent Modeling in Real-Time Strategy Games[C]// GAMEON'2007.Bologna Italy: University of Bologna, 2007: 61-70. |
| [29] | Omer E, Volkan S. Learning Strategies for Opponent Modeling in Poker[C]// Workshop of the Twenty-Seventh AAAI Conference on Artificial Intelligence. Washington, USA: AAAI Press, 2013: 1-7. |
| [30] | Mark F, Sam D, Daniel K, James A. Player Style Clustering without Game Variables[C]// International Conference on the Foundations of Digital Games. New York: Association for Computing Machinery, 2020: 1-4. |
| [31] | Ahmad M A, Elidrisi M. Opponent Classification in Poker[C]// International Conference on Social Computing, Behavioral Modeling, and Prediction. Berlin, Heidelberg: Springer, 2010: 398-405. |
| [32] | Barrett S, Stone P, Kraus S, et al. Teamwork with Limited Knowledge of Teammates[C]// AAAI Conference on Artificial Intelligence. Washington, USA:AAAI Press, 2013: 102-108. |
| [33] | Albrecht S, Crandall J, Ramamoorthy S. An Empirical Study on the Practical Impact of Prior Beliefs over Policy Types[C]// AAAI Conference on Artificial Intelligence. Austin, Texas: AAAI Press, 2015: 1988-1994. |
| [34] | Albrecht S V, Ramamoorthy S. On Convergence and Optimality of Best-response Learning with Policy Types in Multiagent Systems[C]// Thirtieth Conference on Uncertainty in Artificial Intelligence. Arlington Virginia:AAAI Press, 2014: 12-21. |
| [35] | Zhang Y, Radulescu R, Mannion P. Opponent Modelling Using Policy Reconstruction for Multi-Objective Normal Form Games[C]// Adaptive Learning Agents workshop at AAMAS. Auckland, New Zealand: ALA, 2020: 1-9. |
| [36] | Chakraborty D, Stone P. Multiagent Learning in the Presence of Memory-Bounded Agents[J]. Autonomous Agents and Multi-agent Systems (S1387-2532), 2014, 28(2): 182-213. |
| [37] | Kolodner J. Case-Based Reasoning[M]. San Francisco: Morgan Kaufmann, 2014. |
| [38] | Carmel D, Markovitch S. Learning Models of Intelligent Agents[C]// Thirteenth National Conference on Artificial Intelligence. Menlo Park, California: AAAI Press, 1996: 62-67. |
| [39] | Baarslag T, Hendrikx M J C, Hindriks K V, et al. Learning about the Opponent in Automated Bilateral Negotiation: A Comprehensive Survey of Opponent Modeling Techniques[J]. Autonomous Agents and Multi-Agent Systems (S1387-2532), 2016, 30(5): 849-898. |
| [40] | Doshi P, Zeng Y, Chen Q. Graphical Models for Interactive POMDPs: Representations and Solutions[J].Autonomous Agents and Multi-agent Systems (S1387-2532), 2009, 18(3): 376-416. |
| [41] | Kott A, McEneaney W M. Adversarial Reasoning: Computational Approaches to Reading the Opponent’s Mind[M]. Florida: Chapman & Hall/CRC Computer and Information Science Series, 2006. |
| [42] | Rusch T, Steixner-Kumar S, Doshi P, et al. Theory of Mind and Decision Science: Towards a Typology of Tasks and Computational Models[J]. Neuropsychologia (S1873-3514), 2020, 146(211): 107488. |
| [43] | Doshi P, Qu X, Goodie A S, et al. Modeling Human Recursive Reasoning Using Empirically Informed Interactive Partially Observable Markov Decision Processes[J]. IEEE Transactions on Systems Man & Cybernetics Part A Systems & Humans (S1083-4427), 2012, 42(6): 1529-1542. |
| [44] | Chong J K, Ho T H, Camerer C. A Generalized Cognitive Hierarchy Model of Games[J]. Games &Economic Behavior (S0899-8256), 2016, 99: 257-274. |
| [45] | Wen Y, Yang Y, Luo R, et al. Probabilistic Recursive Reasoning for Multi-agent Reinforcement Learning[EB/OL].[2021-01-20]. . |
| [46] | Wen Y, Yang Y, Luo R, et al. Modelling Bounded Rationality in Multi-Agent Interactions by Generalized Recursive Reasoning[C]// Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence. Pasadena USA: IJCAI, 2021: 414-421. |
| [47] | Doshi P, Gmytrasiewicz P, Durfee E. Recursively Modeling other Agents for Decision Making: A Research Perspective[J]. Artificial Intelligence (S2633-1403), 2020, 279: 103202. |
| [48] | Dai Z, Chen Y, Low K H, et al. R2-B2: Recursive Reasoning-Based Bayesian Optimization for No-Regret Learning in Games[C]// 37th International Conference on Machine Learning. Vienna, Austria: PMLR, 2020: 2291-2301. |
| [49] | Ho T H, X Su. A Dynamic Level-K model in Sequential Games[J]. Management Science (S0025-1909), 2013, 59(2): 452-469 |
| [50] | Ho T H, Park S E, Su X. A Bayesian Level-k Model in n-Person Games[J]. Management Science (S2694-1686), 2021, 67(3): 1622-1638. |
| [51] | Ganzfried S, Sandholm T. Game Theory-Based Opponent Modeling in Large Imperfect-Information Games[C]// 10th International Conference on Autonomous Agents and Multiagent Systems. Taipei Taiwan: Systems, Richland, 2011: 533-540. |
| [52] | Johanson M, Bowling M. Data Biased Robust Counter Strategies[C]// Artificial Intelligence and Statistics.Clearwater, Florida: PMLR, 2009: 264-271. |
| [53] | Černý J, Lisý V, Bošanský B, et al. Computing Quantal Stackelberg Equilibrium in Extensive-Form Games[C/OL]// AAAI Conference on Artificial Intelligence. AAAI, 2021: 5260-5268. . |
| [54] | Milec D, Černý J, Lisý V, et al. Complexity and Algorithms for Exploiting Quantal Opponents in Large Two-Player Games[C]// Thirty-Fifth AAAI Conference on Artificial Intelligence. Palo Alto, California: AAAI Press, 2021: 5575-5583. |
| [55] | Wang Z, Boularias A, Mülling K, et al. Balancing Safety and Exploitability in Opponent Modeling[C]// AAAI Conference on Artificial Intelligence. San Francisco, California: AAAI Press, 2011: 1515-1520. |
| [56] | Ganzfried S, Sandholm T. Safe Opponent Exploitation[J].ACM Transactions on Economics and Computation (TEAC) (S2167-8383), 2015, 3(2): 1-28. |
| [57] | Bard N, Johanson M, Burch N, et al. Online Implicit Agent Modelling[C]// AAMAS '13. St. Paul MN USA:International Foundation for Autonomous Agents and Multiagent Systems, 2013: 255-262. |
| [58] | Wu Z, Li K, Zhao E, et al. L2E: Learning to Exploit Your Opponent[EB/OL].[2021-02-19]. . |
| [59] | Al Shedivat M, Bansal T, Burda Y, et al. Continuous Adaptation via Meta-learning in Nonstationary and Competitive Environments[EB/OL]. (2017-10-10)[2021-01-08]. . |
| [60] | Kim D K, Liu M, Riemer M, et al. A Policy Gradient Algorithm for Learning to Learn in Multiagent Reinforcement Learning[C/OL]// International Conference on Machine Learning. PMLR, 2021:5541-5550. . |
| [61] | Everett R, Roberts S. Learning Against Non-stationary Agents with Opponent Modelling and Deep Reinforcement Learning[C]// 2018 AAAI Spring Symposium Series. Palo Alto, California, AAAI Press, 2018: 1-6. |
| [62] | Bard N. Online Agent Modelling in Human-Scale Problems[D]. Edmonton: University of Alberta, 2016. |
| [63] | Lu S. Online Enhancement of Existing Nash Equilibrium Poker Agents[D]. Darmstadt: Technische Universität Darmstadt, 2016. |
| [64] | Rosenberg A, Mansour Y. Online Convex Optimization in Adversarial Markov Decision Processes[C]//International Conference on Machine Learning.California USA: PMLR, 2019: 5478-5486. |
| [65] | Farina G, Kroer C, Sandholm T. Online Convex Optimization for Sequential Decision Processes and Extensive-Form Games[C]// Thirty-Third AAAI Conference on Artificial Intelligence. Honolulu, Hawaii:AAAI Press, 2019: 1917-1925. |
| [66] | Mealing R. Dynamic Opponent Modelling in Two-Player Games[D]. UK: University of Manchester Manchester, 2015. |
| [67] | Farina G, Sandholm T. Model-Free Online Learning in Unknown Sequential Decision Making Problems and Games[C]// Thirty-Fifth AAAI Conference on Artificial Intelligence. Palo Alto, California: AAAI Press, 2021: 5381-5390. |
| [68] | Farina G, Schmucker R, Sandholm T. Bandit Linear Optimization for Sequential Decision Making and Extensive-Form Games[C]// Thirty-Fifth AAAI Conference on Artificial Intelligence. Palo Alto, California: AAAI Press, 2021: 5372-5380. |
| [69] | Foerster J, Chen R Y, Al-Shedivat M, et al. Learning with Opponent-Learning Awareness[EB/OL].(2018-09-19)[2020-12-15]. . |
| [70] | Davies I, Tian Z, Wang J. Learning to Model Opponent Learning[C]// AAAI Conference on Artificial Intelligence. New York: AAAI Press, 2020: 13771-13772. |
| [71] | Letcher A, Foerster J, D Balduzzi, et al. Stable Opponent Shaping in Differentiable Games[EB/OL]. (2018-11-19)[2020-12-11]. . |
| [72] | Hakli R. Cooperative Human-Robot Planning with Team Reasoning[J]. International Journal of Social Robotics (S1875-4791), 2017, 9(5): 643-658. |
| [73] | Ouessai A, Salem M, Mora A M. Online Adversarial Planning in μRTS: A Survey[C]// 2019 International Conference on Theoretical and Applicative Aspects of Computer Science (ICTAACS). Skikda, Algeria: IEEE, 2019: 1-8. |
| [74] | Gunning D, Aha D. DARPA’s Explainable Artificial Intelligence (XAI) Program[J]. AI Magazine (S2634-9523), 2019, 40(2): 44-58. |
| [75] | Chakraborti T, Kulkarni A, Sreedharan S, et al. Explicability? Legibility? Predictability? Transparency?Privacy? Security? The Emerging Landscape of Interpretable Agent Behavior[C]// Twenty-Ninth International Conference on Automated Planning and Scheduling. Palo Alto, California: AAAI Press, 2019: 86-96. |
| [76] | Abbass H, Bender A, Gaidow S, et al. Computational Red Teaming: Past, Present and Future[J]. IEEE Computational Intelligence Magazine (S1556-6048), 2011, 6(1): 30-42. |
| [77] | Ettingery D, Jehiel P. Towards a Theory of Deception[R].London: UCLA Department of Economics, 2004. |
| [78] | Latimer J. Deception in War[M]. London: Abrams, 2015. |
| [79] | Zhu Q. Game Theory for Cyber Deception A Tutorial[C]// 6th Annual Symposium on Hot Topics in the Science of Security. New York: Association for Computing Machinery, 2019: 1-3. |
| [80] | Fugate S, Ferguson-Walter K. Artificial Intelligence and Game Theory Models for Defending Critical Networks with Cyber Deception[J]. AI Magazine (S2634-9523), 2019, 40(1): 49-62. |
| [81] | Oey L, Schachner A, Vul E. Designing Good Deception:Recursive Theory of Mind in Lying and Lie Detection[C]// Annual Meeting of the Cognitive Science Society. Montreal, Canada: CogSci, 2019: 897-903. |
| [82] | Mealing R, Shapiro J L. Opponent Modeling by Expectation-Maximization and Sequence Prediction in Simplified Poker[J]. IEEE Transactions on Computational Intelligence and AI in Games (S1943-0698), 2017, 9(1): 11-25. |
| [83] | Bontrager P, Khalifa A, Anderson D, et al. Superstition in the Network: Deep Reinforcement Learning Plays Deceptive Games[C]// AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment. Palo Alto, California: AAAI Press, 2019: 10-16. |
| [84] | Schneider J, Meske C, Vlachos M, et al. Deceptive AI Explanations-Creation and Detection[EB/OL].(2020-09-19)[2020-12-30]. . |
| [85] | Timbers F, Lockhart E, Schmid M, et al. Approximate Exploitability: Learning a Best Response in Large Games[EB/OL]. (2020-04-20)[2020-12-18]. . |
| [86] | Lockhart E, Lanctot M, J Pérolat, et al. Computing Approximate Equilibria in Sequential Adversarial Games by Exploitability Descent[C]// 28th International Joint Conference on Artificial Intelligence. Macao China:AAAI Press, 2019: 464-470. |
| [87] | Sam G. Computing Strong Game-Theoretic Strategies and Exploiting Suboptimal Opponents in Large Games[D]. Pittsburgh: Carnegie Mellon University, 2015. |
| [88] | Li X. Opponent Modeling and Exploitation in Poker Using Evolved Recurrent Neural Networks[D]. Austin: University of Texas, 2018. |
| [89] | Freeman R, Pennock D M, Podimata C, et al. No-Regret and Incentive-Compatible Online Learning[C]//International Conference on Machine Learning. Vienna, Austria: PMLR, 2020: 3270-3279. |
| [90] | Shen M, How J P. Robust Opponent Modeling via Adversarial Ensemble Reinforcement Learning in Asymmetric Imperfect-Information Games[EB/OL].(2020-09-18)[2020-12-10]. . |
| [91] | Smith M O, Anthony T, Wang Y. Learning to Play against Any Mixture of Opponents[EB/OL]. (2020-09-29)[2020-12-13]. . |
| [92] | Rădulescu R, Verstraeten T, Zhang Y, et al. Opponent Learning Awareness and Modelling in Multi-objective Normal form Games[J]. Neural Computing and Applications (S0941-0643), 2022, 34(3): 1759-1781. |
| [93] | Mccracken P, Bowling M. Safe Strategies for Agent Modelling in Games[C]// In AAAI Fall Symposium on Artificial Multi-agent Learning. Washington, USA:AAAI Press, 2004: 103-110. |
| [94] | Ling C K, Brown N. Safe Search for Stackelberg Equilibria in Extensive-Form Games[C]// AAAI Conference on Artificial Intelligence. Palo Alto, California, USA: AAAI Press, 2021: 5541-5548. |
| [95] | Brown N, Sandholm T. Safe and Nested Endgame Solving for Imperfect-Information Games[C]//Workshops at the Thirty-First AAAI Conference on Artificial Intelligence. San Francisco, California, USA:AAAI Press, 2017: 1-8. |
| [96] | Nieves N P, Yang Y D, Slumbers O, et al. Modelling Behavioural Diversity for Learning in Open-Ended Games[C/OL]// International Conference on Machine Learning. PMLR, 2021: 8514-8524. . |
| [97] | Lanctot M, Zambaldi V, Gruslys A, et al. A Unified Game-Theoretic Approach to Multi-agent Reinforcement Learning[C]// 31st International Conference on Neural Information Processing Systems. Long Beach California:Curran Associates, 2017: 4193-4206. |
| [98] | Muller P, Omidshafiei S, Rowland M, et al. A Generalized Training Approach for Multi-agent Learning[C]// 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: ICLR, 2020: 1-35. |
| [99] | Pell B. Strategy Generation and Evaluation for Meta-Game Playing[J]. KI-Künstliche Intelligenz (S1610-1987), 2011, 25(1): 71-72. |
| [100] | Karl T, Julien P, Marc Lanctot, et al. A Generalised Method for Empirical Game Theoretic Analysis[C]//17th International Conference on Autonomous Agents and MultiAgent Systems. Stockholm Sweden: Systems Richland, 2018: 77-85. |
| [101] | Czarnecki W M, Gidel G, Tracey B, et al. Real World Games Look Like Spinning Tops[C]// 34th International Conference on Neural Information Processing Systems.New York: Curran Associates, 2020: 17443-17454. |
| [102] | Balduzzi D, Garnelo M, Bachrach Y, et al. Open-ended Learning in Symmetric Zero-sum Games[C]//International Conference on Machine Learning.California USA: PMLR, 2019: 434-443. |
| [103] | Tošić P T, Vilalta R. A Unified Framework for Reinforcement Learning, Co-learning and Meta-learning How to Coordinate in Collaborative Multi-agent Systems[J]. Procedia Computer Science (S1877-0509), 2010, 1(1): 2217-2226. |
| [104] | Heinrich J, Lanctot M, Silver D. Fictitious Self-Play in Extensive-Form Games[C]// International Conference on Machine Learning. Lille France: PMLR, 2015: 805-813. |
| [105] | Omidshafiei S, Papadimitriou C, Piliouras G, et al. α-Rank: Multi-agent Evaluation by Evolution[J]. Scientific Reports (S1663-6325), 2019, 9(1): 9937. |
| [106] | Yang Y, Tutunov R, Sakulwongtana P, et al. αα-Rank:Practically Scaling α-Rank through Stochastic Optimisation[C]// AAMAS '20. Auckland New Zealand:International Foundation for Autonomous Agents and Multiagent Systems, 2020: 1575-1583. |
| [107] | Yan R, Duan X, Shi Z, et al. Policy Evaluation and Seeking for Multi-Agent Reinforcement Learning via Best Response[J]. IEEE Transactions on Automatic Control (S1558-2523), 2021, 67(4): 1898-1913. |
| [108] | Stephen M, John L, Fox R, et al. Pipeline PSRO: A Scalable Approach for Finding Approximate Nash Equilibria in Large Games[C]// 34th International Conference on Neural Information Processing Systems.Vancouver BC Canada: Curran Associates, 2020: 20238-20248. |
| [109] | Liu X, Jia H, Wen Y, et al. Towards Unifying Behavioral and Response Diversity for Open-ended Learning in Zero-sum Games[C]// 34th International Conference on Neural Information Processing Systems. Vancouver BC Canada: Curran Associates, 2020: 941-952. |
| [110] | Escovedo T, Koshiyama A, Da Cruz A A, et al. Neuroevolutionary Learning in Nonstationary Environments[J]. Applied Intelligence (S0887-1469), 2020, 50(5): 1590-1608. |
| [111] | Qian L. Evolutionary Population Curriculum for Scaling Multi-agent Reinforcement Learning[D]. Pittsburgh: Carnegie Mellon University, 2020. |
| [112] | Yang Y, Luo J, Wen Y, et al. Diverse Auto-Curriculum is Critical for Successful Real-World Multiagent Learning Systems[EB/OL]. (2021-02-15)[2021-03-13]. . |
| [113] | Golowich N, Pattathil S, Daskalakis C, et al. Tight Last-iterate Convergence Rates for No-regret Learning in Multi-player Games[C]// 34th International Conference on Neural Information Processing Systems.Vancouver BC Canada: Curran Associates, 2020: 20766-20778. |
| [114] | Papoudakis G, Christianos F, Albrecht S. Agent Modelling under Partial Observability for Deep Reinforcement Learning[C/OL]// 35th International Conference on Neural Information Processing Systems.Curran Associates, 2021: 19210-19222. . |
| [1] | Zhou Zicong, Zeng Junjie, Hu Yue, Zhu Zhengqiu, Yin Quanjun. Multi-agent Reinforcement Learning Method for Wargame Simulation Based on Suboptimal Demonstration Guidance [J]. Journal of System Simulation, 2026, 38(5): 1277-1289. |
| [2] | Li Jiting, Sun Yi, Wang Yirong, Lin Yiqin, Jia Jun, Ding Gangsong. LLM-driven Multi-agent Social Network Simulation: Interdisciplinary Integration and Cutting-edge Development [J]. Journal of System Simulation, 2026, 38(2): 235-260. |
| [3] | Tao Caixia, Chen Naikun, Gao Fengyang, Zhang Jiangang. Distributed Optimization for Integrated Energy Based on Multi-agent Reinforcement Learning [J]. Journal of System Simulation, 2026, 38(2): 476-487. |
| [4] | Wang Yifan, Yang Bin, Wang Congjun. Simulation Method for Multi-crew Construction Processes Based on Large Language Model-powered Agent [J]. Journal of System Simulation, 2026, 38(2): 488-500. |
| [5] | Zhang Yue, Zhang Wenliang, Feng Qiang, Guo Xing, Ren Yi, Wang Zili. Combat-oriented Comprehensive Simulation and Verification Technology for Equipment System RMS [J]. Journal of System Simulation, 2025, 37(7): 1823-1835. |
| [6] | Gu Xueqiang, Luo Junren, Zhou Yanzhong, Zhang Wanpeng. Survey on Large Language Agent Technologies for Intelligent Game Theoretic Decision-making [J]. Journal of System Simulation, 2025, 37(5): 1142-1157. |
| [7] | Yao Changhua, Bi Shanning, Ma Rufei, Yu Xiaohan, Li Jiaqiang, Chen Jinli. Method for Dynamic Coalition Formation of Wargame Agent for Force Cooperation [J]. Journal of System Simulation, 2025, 37(5): 1188-1196. |
| [8] | Xiong Jun, Zhang Wenbo, Xiong Zhi, Zhou Feng, Yang Bo. Survey of Cooperative Multi-Agent Path Finding [J]. Journal of System Simulation, 2025, 37(12): 3033-3049. |
| [9] | Huang Zhiqin, Lu Tianying, Chen Zheyi. Multi-UAV Deployment and Collaborative Offloading for Large-scale IoT Systems [J]. Journal of System Simulation, 2025, 37(1): 25-39. |
| [10] | Jiang Quan, Wei Jingxuan. Real-time Scheduling Method for Dynamic Flexible Job Shop Scheduling [J]. Journal of System Simulation, 2024, 36(7): 1609-1620. |
| [11] | Yu Lei, Zhu Xichou, Liao Huaming, Guo Jiafeng, Cheng Xueqi. Interaction Between Virus Transmission Variation and Population Crossover Activity and Diffusion Model [J]. Journal of System Simulation, 2024, 36(7): 1713-1728. |
| [12] | Zhou Zhiyong, Mo Fei, Zhao Kai, Hao Yunbo, Qian Yufeng. Adaptive PID Control Algorithm Based on PPO [J]. Journal of System Simulation, 2024, 36(6): 1425-1432. |
| [13] | Yan Xingyu, Li Dayan, Wang Niya, Zhang Kaixiang, Mao Jianlin. Multi-agent Path Planning with Obstacle Penalty Factor [J]. Journal of System Simulation, 2024, 36(3): 673-685. |
| [14] | Zhang Guohui, Gao Ang, Zhang Ya'nan. Combat Effectiveness Evaluation Method of Homogeneous Cluster Equipment System Based on RLoMAG+EAS [J]. Journal of System Simulation, 2024, 36(1): 160-169. |
| [15] | Luo Junren, Zhang Wanpeng, Xiang Fengtao, Jiang Chaoyuan, Chen Jing. Survey on Intelligent Wargaming: Tactical & Campaign Wargame and Strategic Game from Game-Theoretic Perspective [J]. Journal of System Simulation, 2023, 35(9): 1871-1894. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
