

系统仿真学报 ›› 2025, Vol. 37 ›› Issue (5): 1169-1187.doi: 10.16182/j.issn1004731x.joss.24-0025
伍国华1, 曾家恒2, 王得志3, 郑龙4, 邹伟5
收稿日期:2024-01-08
修回日期:2024-03-12
出版日期:2025-05-20
发布日期:2025-05-23
通讯作者:
王得志
第一作者简介:伍国华(1986-),男,教授,博士,研究方向为无人机系统与强化学习算法设计。
基金资助:Wu Guohua1, Zeng Jiaheng2, Wang Dezhi3, Zheng Long4, Zou Wei5
Received:2024-01-08
Revised:2024-03-12
Online:2025-05-20
Published:2025-05-23
Contact:
Wang Dezhi
摘要:
受限于模型方程决定的固定结构,传统四旋翼控制器设计难以有效应对模型参数和环境扰动变化带来的控制误差。提出了基于深度强化学习的四旋翼航迹跟踪控制方法,构建了对应的马尔可夫决策模型,并基于PPO框架提出了PPO-SAG(PPO with self adaptive guide)算法。PPO-SAG在学习过程中加入自适应机制,利用PID专家知识进行引导和学习,提高了训练的收敛效果和稳定性。根据问题特点,设计了带有距离约束惩罚和熵策略的目标函数,提出扰动误差信息补充结构和航迹特征选择结构,补充控制误差信息、提取未来航迹关键要素,提高了收敛效果。并利用状态动态标准化、优势函数批标准化及奖励缩放策略,更合理地处理三维空间中的状态表征和奖励优势表达。单种航迹与混合航迹实验表明,所提出的PPO-SAG算法在收敛效果和稳定性上均取得了最好的效果,消融实验说明所提出的改进机制和结构均起到正向作用。所研究的未知扰动下基于深度强化学习的四旋翼航迹跟踪控制问题,为设计更加鲁棒高效的四旋翼控制器提供了解决方案。
中图分类号:
伍国华,曾家恒,王得志等 . 基于深度强化学习的四旋翼航迹跟踪控制方法[J]. 系统仿真学报, 2025, 37(5): 1169-1187.
Wu Guohua,Zeng Jiaheng,Wang Dezhi,et al . A Quadrotor Trajectory Tracking Control Method Based on Deep Reinforcement Learning[J]. Journal of System Simulation, 2025, 37(5): 1169-1187.
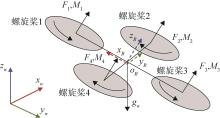
图1
四旋翼无人机结构示意图

图2
四旋翼航迹跟踪任务示意图
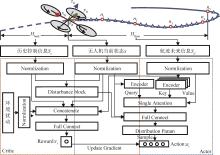
图3
价值与策略网络结构
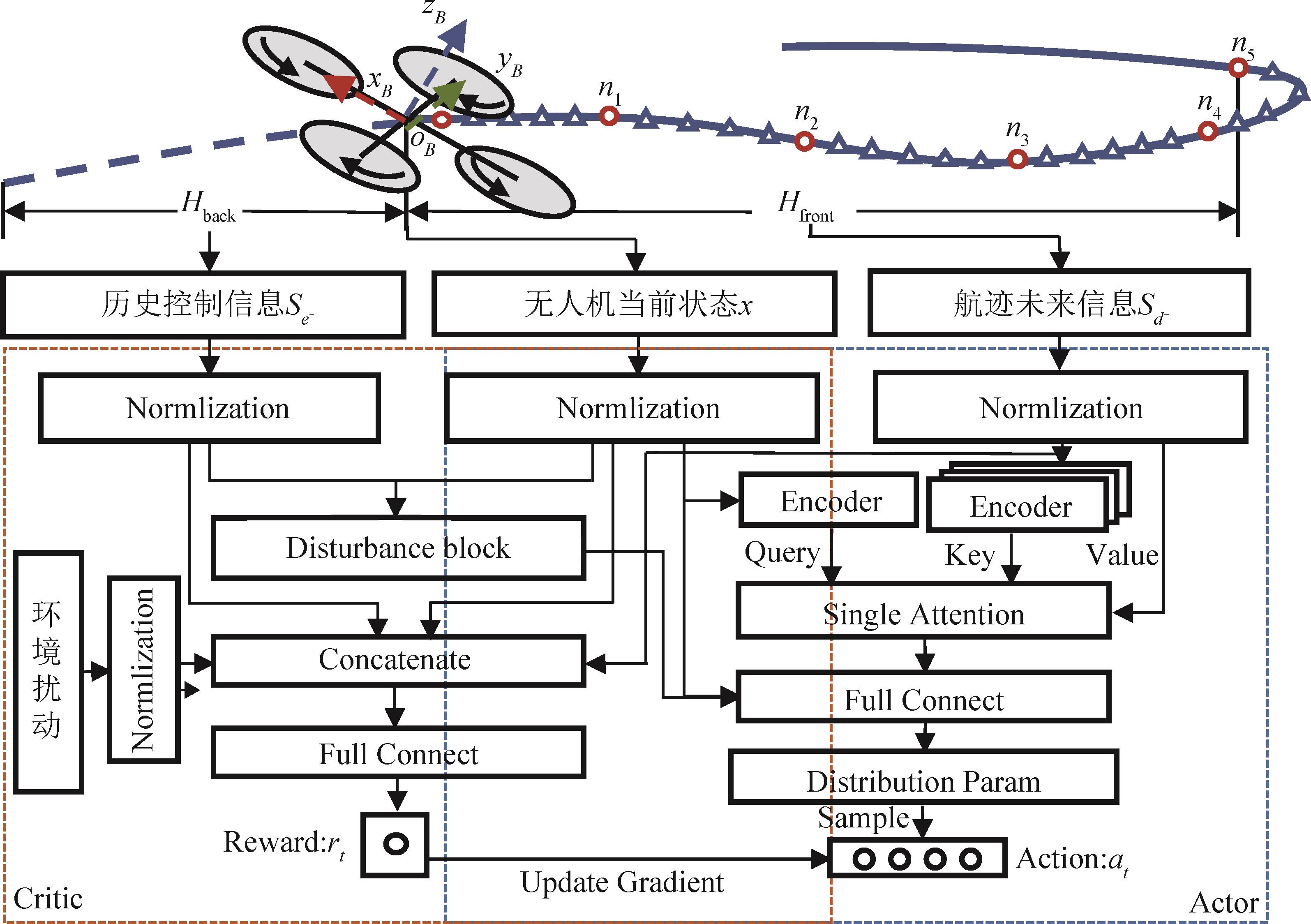
图4
基于PPO-SAG算法的四旋翼航迹跟踪训练流程图
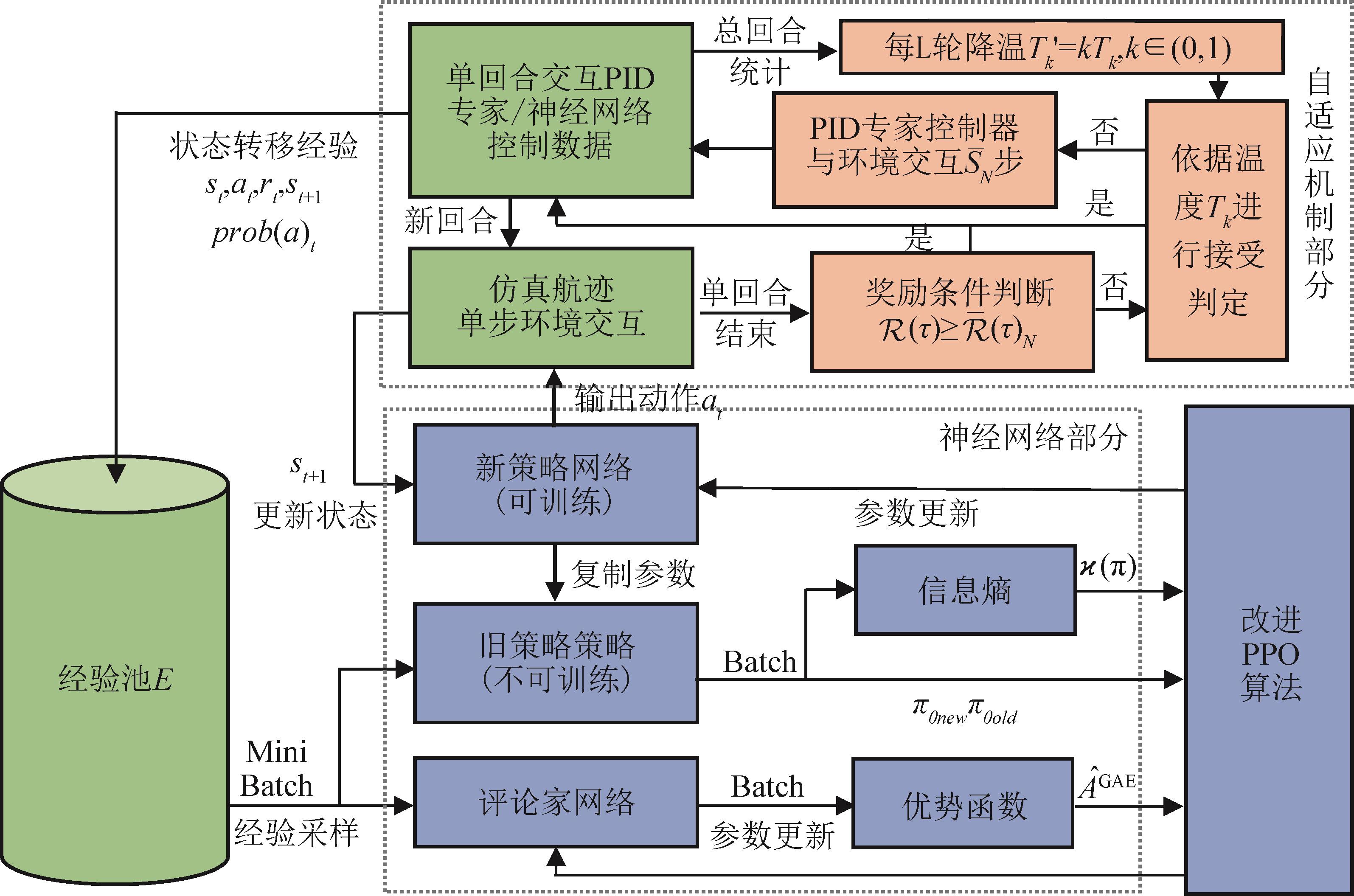
表1
Crazyflie参数及扰动范围设置
| Crazyflie参数 | 标称值 | 扰动 |
|---|---|---|
| 四旋翼质量 | ||
| 转动惯量 | ||
| 重力加速度 | ||
| 四旋翼螺旋桨臂长 | ||
| 最大转速 | ||
| 推力系数 | ||
| 转动矩 |
表2
PID控制算法参数设置
| PID控制参数名称 | 参数设置 |
|---|---|
| 位置误差系数 | |
| 速度误差系数 | |
| 姿态误差系数 | |
| 角速度误差系数 |
表3
深度强化学习算法参数设置
| 参数名称 | 参数设置 | 参数名称 | 参数设置 |
|---|---|---|---|
| 折扣因子 | 最大步长 | ||
| 学习率 | 批训练大小 | ||
| 距离系数 | 回合步长 | ||
| 裁剪率 | 经验池大小 | ||
| 航迹数 | 退火轮次 | ||
| 模拟退火系数 | 初始温度 |

图5
强化学习无人机训练和测试航迹示例
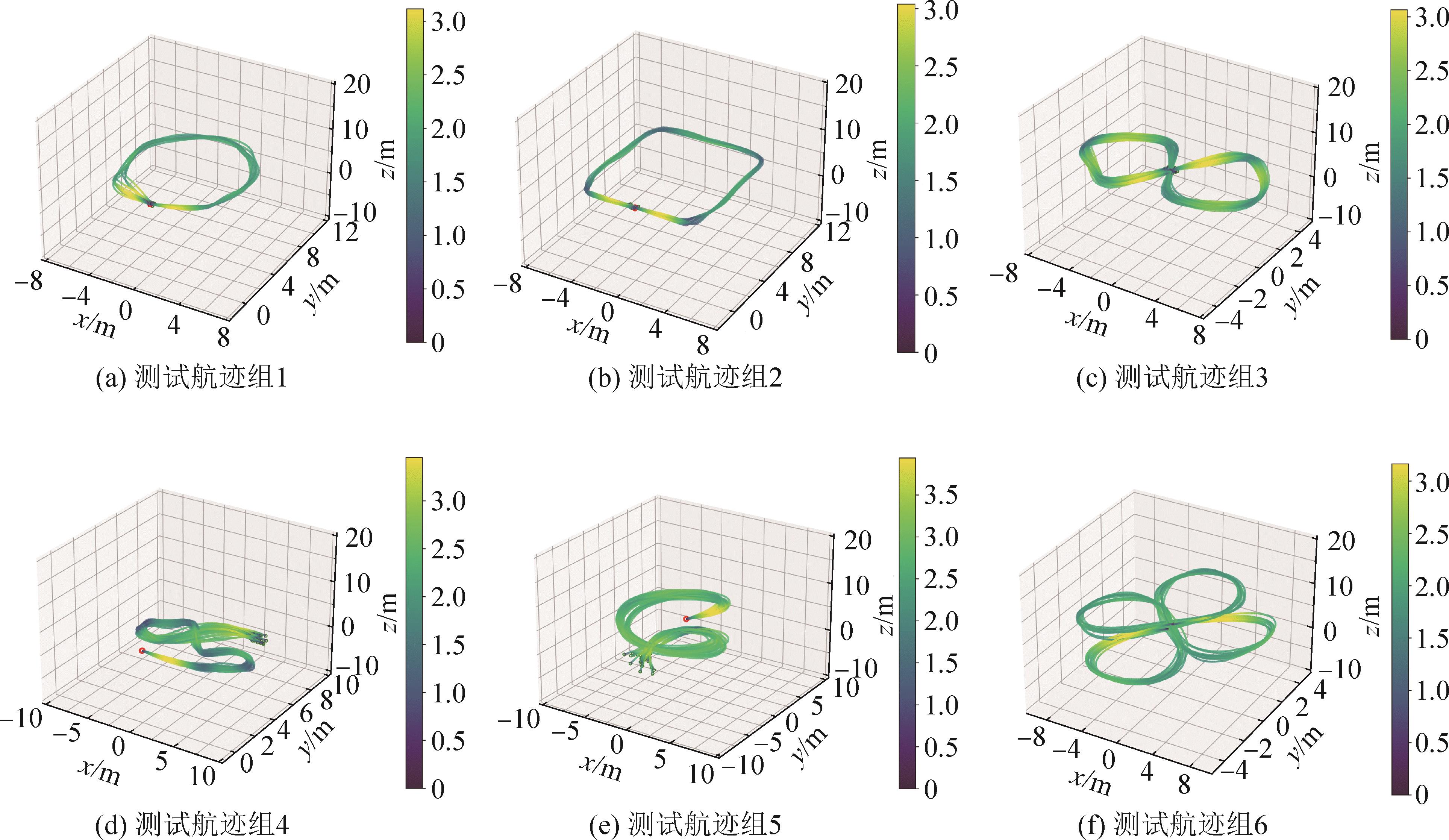
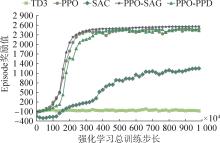
图6
单种航迹(S)收敛曲线(航迹类型4为例)
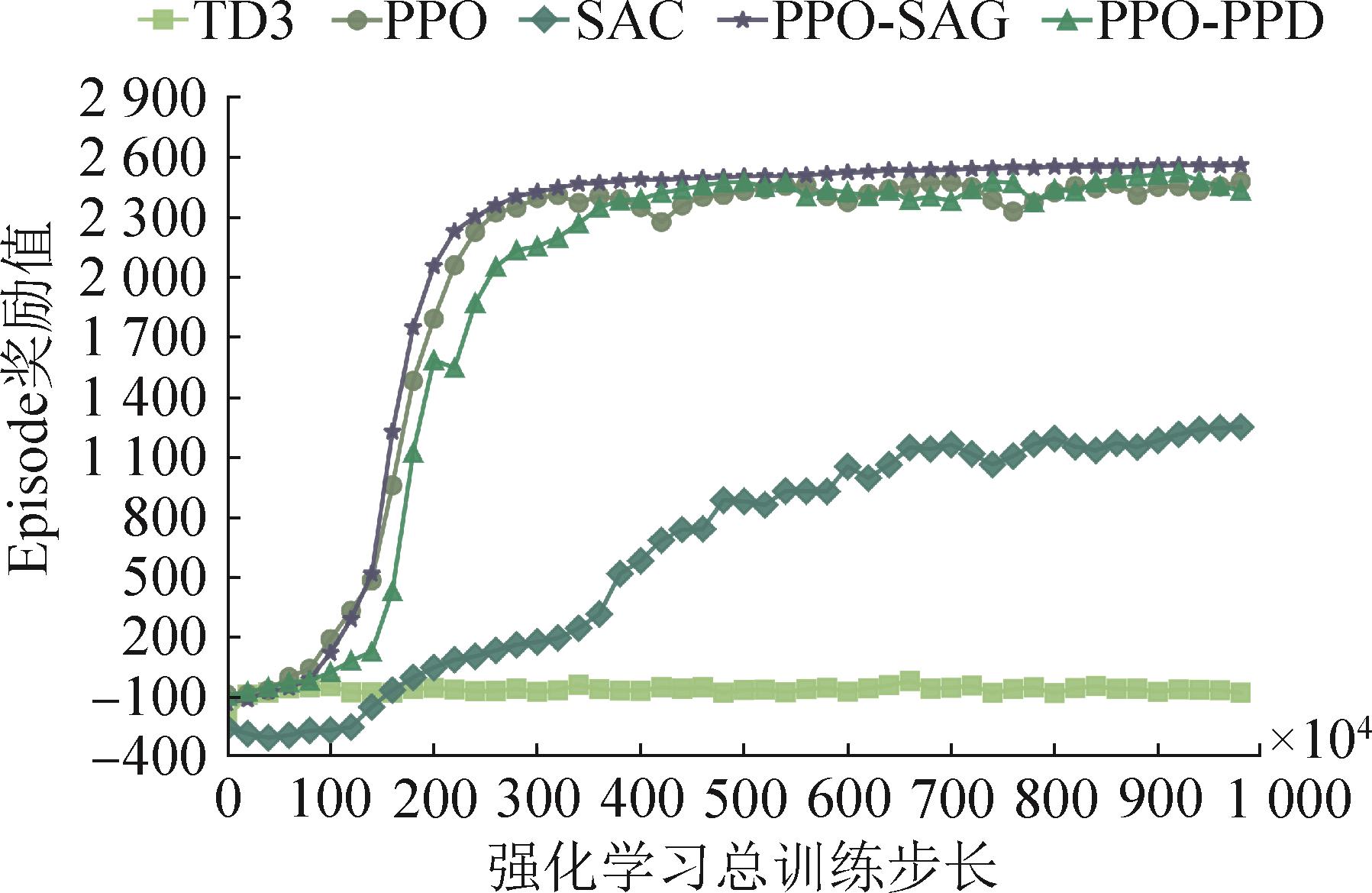
图7
混合航迹(M)收敛曲线
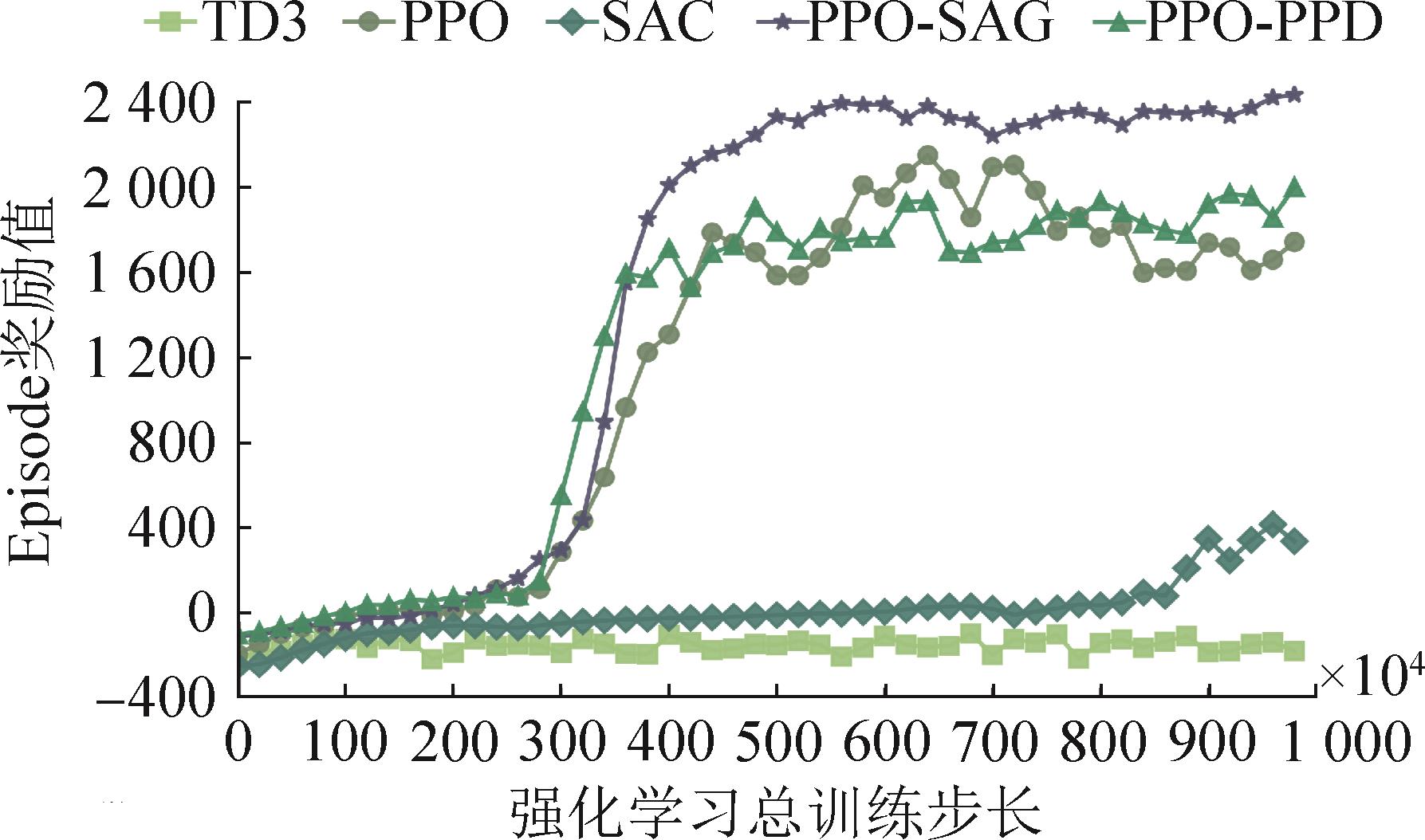
表4
训练误差内多方法航迹跟踪误差比较 (m)
| 航迹 | SAC(S) | PPO(S) | PPO-PPD(S) | PPO-SAG(P) | PPO-SAG(S) | PPO-SAG (FC-M) | PPO-SAG(M) | PID |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.196 ± 0.095 | 0.072 ± 0.036 | 0.061 ± 0.061 | 1.055 ± 0.430 | 0.054 ± 0.037 | 0.092 ± 0.064 | 0.087 ± 0.052 | 0.248 ± 0.073 |
| 2 | 0.473 ± 0.198 | 0.048 ± 0.032 | 0.038 ± 0.032 | 1.024 ± 0.459 | 0.030 ± 0.021 | 0.087 ± 0.074 | 0.075 ± 0.048 | 0.227 ± 0.078 |
| 3 | 0.404 ± 0.128 | 0.092 ± 0.208 | 0.064 ± 0.084 | 1.138 ± 0.369 | 0.038 ± 0.079 | 0.132 ± 0.106 | 0.107 ± 0.077 | 0.267 ± 0.082 |
| 4 | 0.344 ± 0.232 | 0.087 ± 0.105 | 0.073 ± 0.104 | 1.142 ± 0.420 | 0.046 ± 0.026 | 0.151 ± 0.142 | 0.110 ± 0.074 | 0.273 ± 0.212 |
| 5 | 0.979 ± 0.425 | 0.116 ± 0.227 | 0.077 ± 0.079 | 1.372 ± 0.471 | 0.068 ± 0.053 | 0.189 ± 0.371 | 0.152 ± 0.088 | 0.332 ± 0.113 |
| 6 | 0.451 ± 0.197 | 0.121 ± 0.246 | 0.091 ± 0.187 | 1.201 ± 0.436 | 0.062 ± 0.093 | 0.149 ± 0.189 | 0.147 ± 0.124 | 0.279 ± 0.085 |
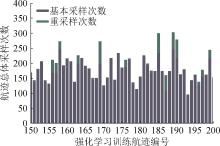
图8
单种航迹(S)采样频率
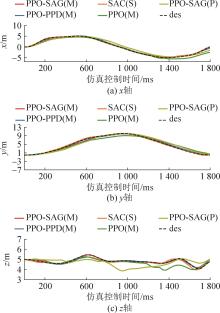
图9
四旋翼位置变化曲线(小扰动)
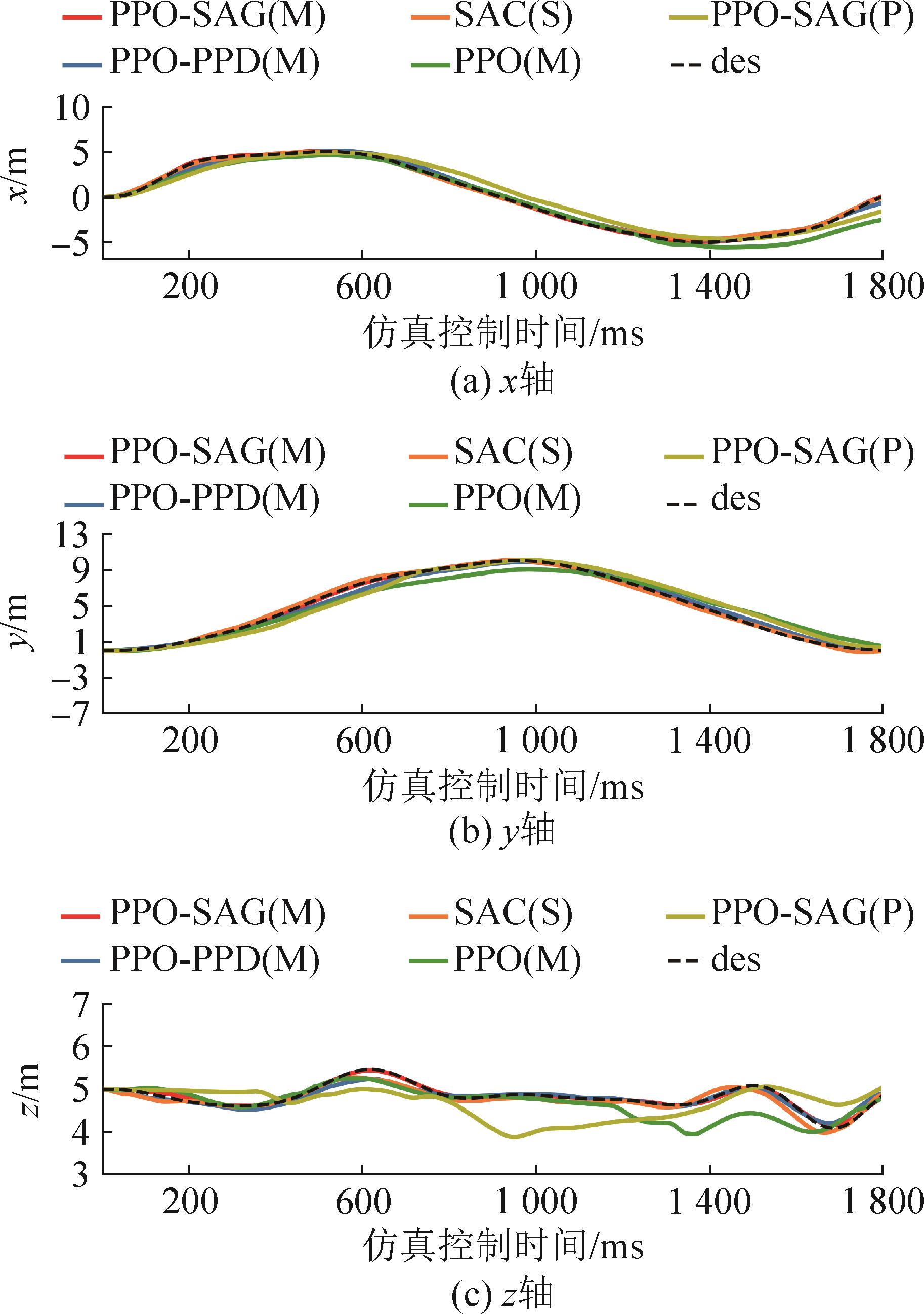
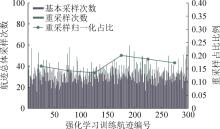
图10
混合航迹(M)采样频率
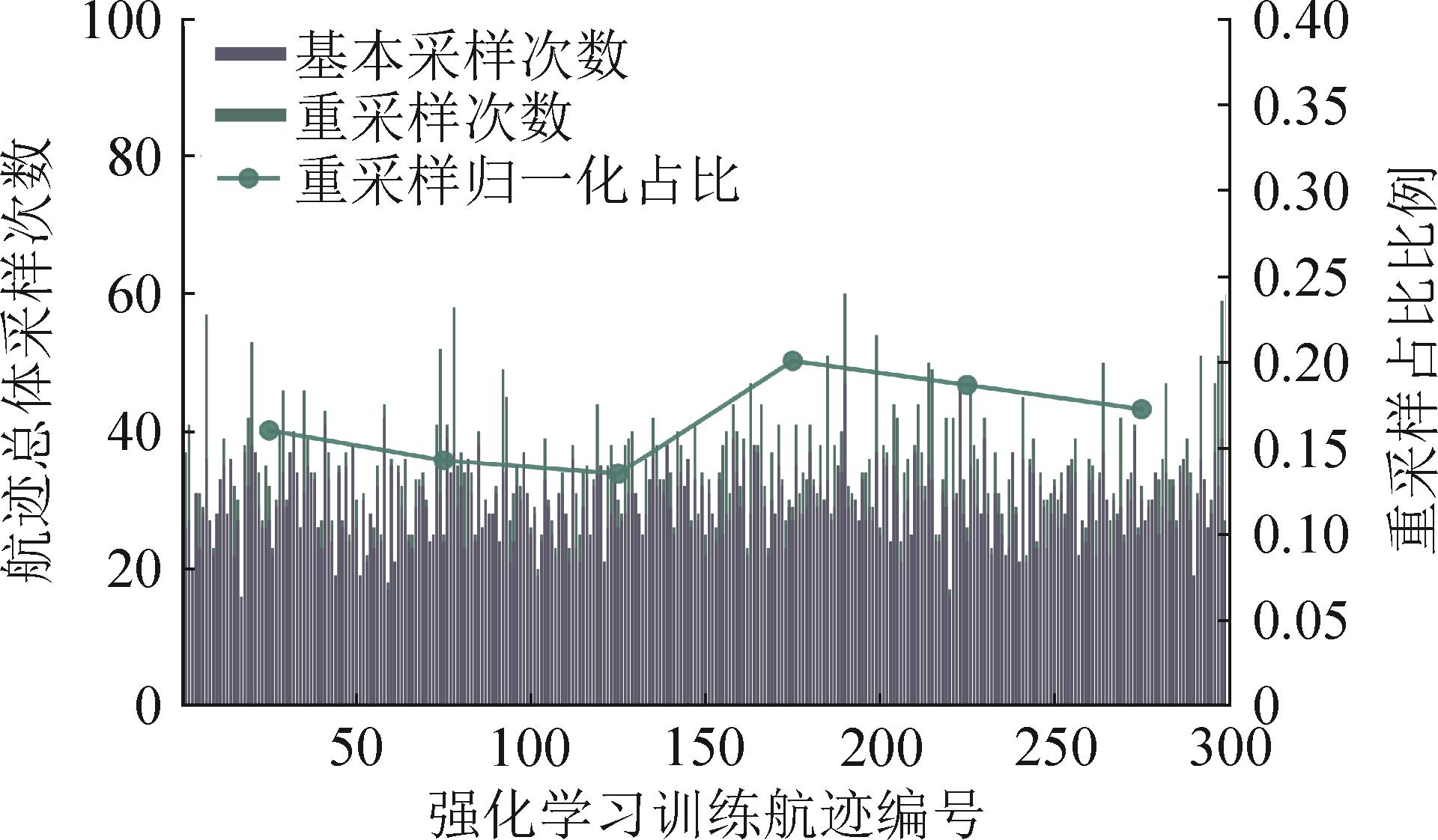
图11
自适应超参数灵敏度分析
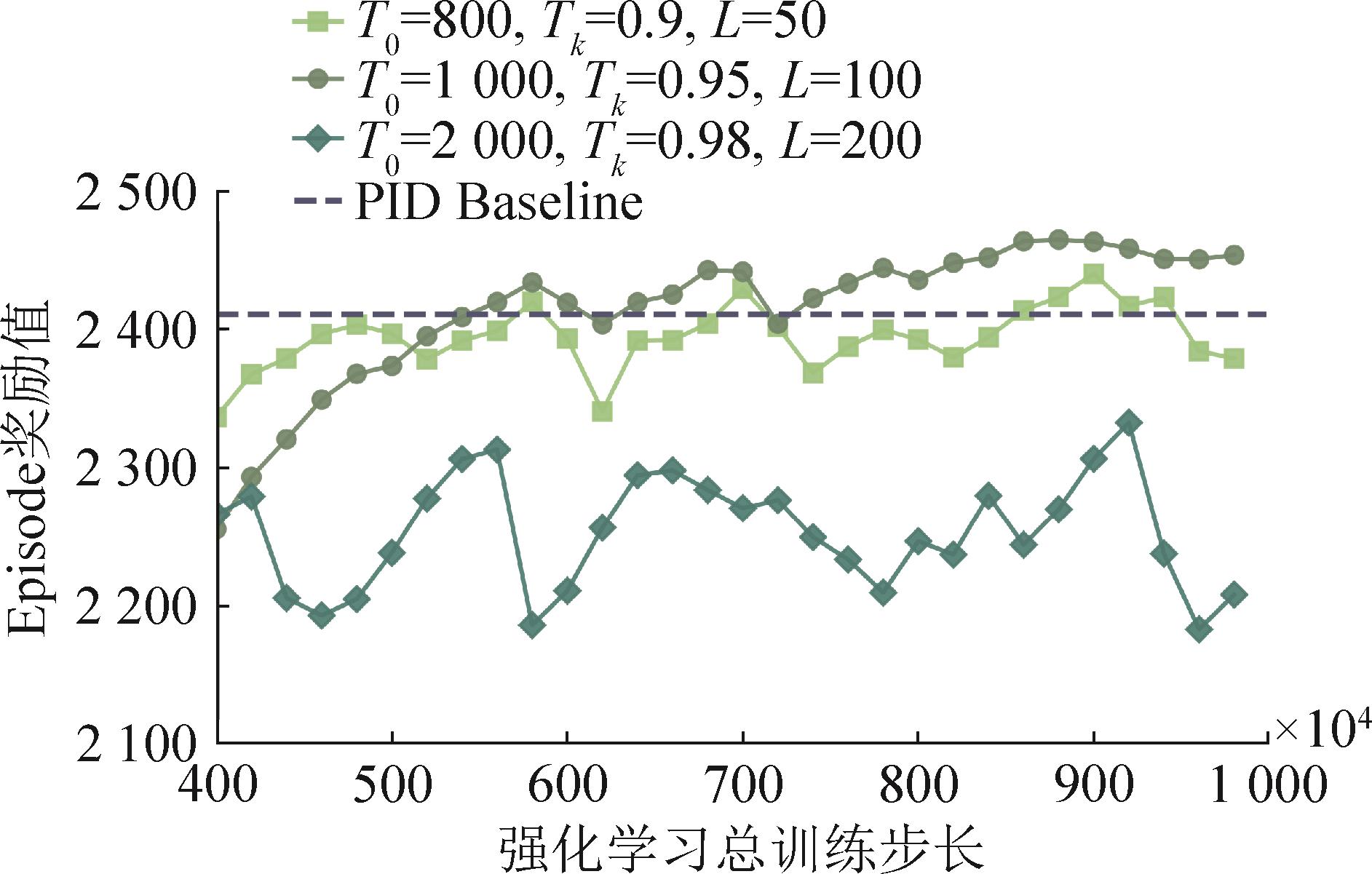
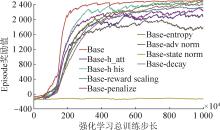
图12
消融实验收敛图
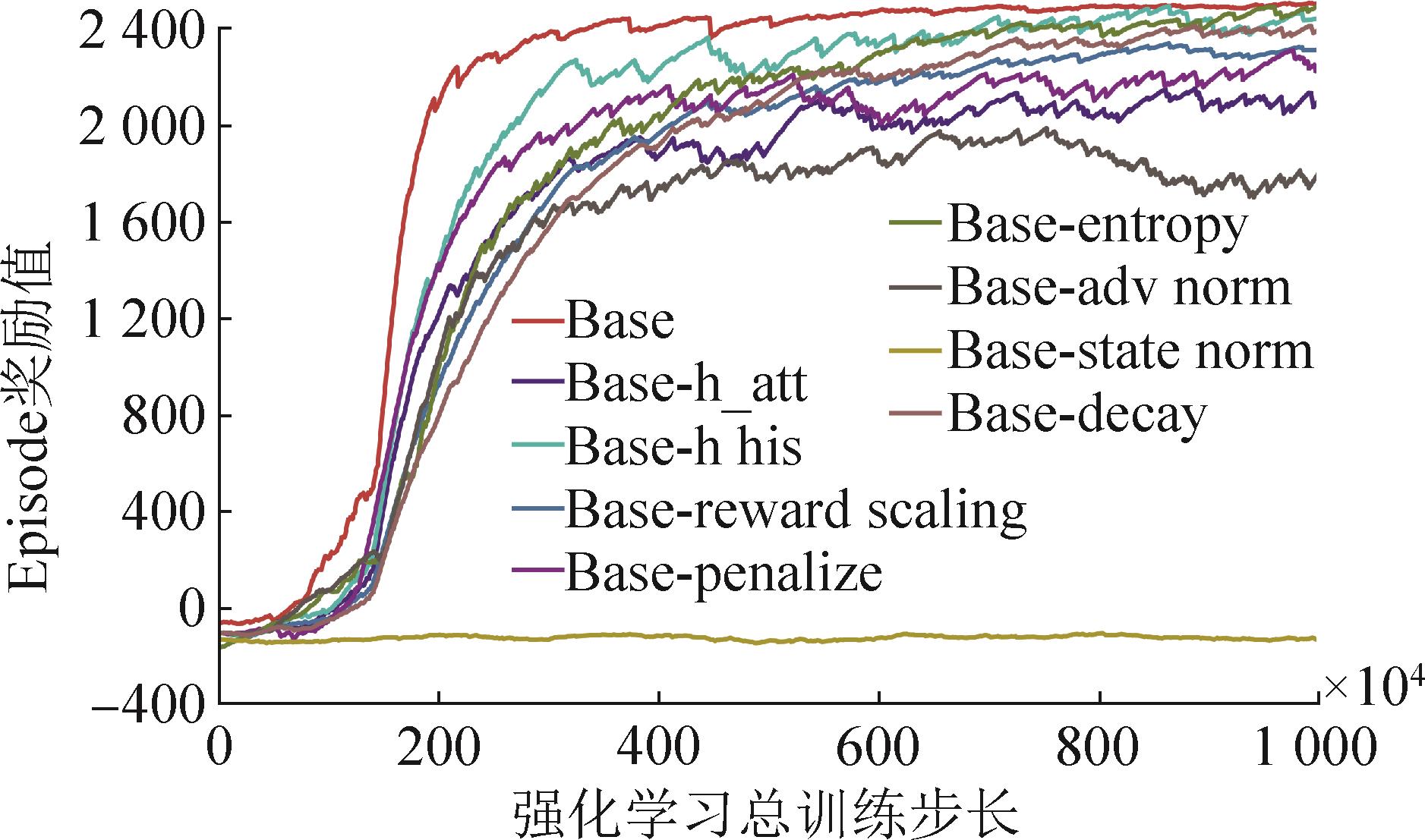
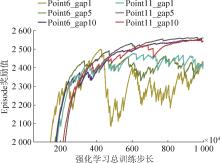
图13
不同注意力机制参数收敛曲线图
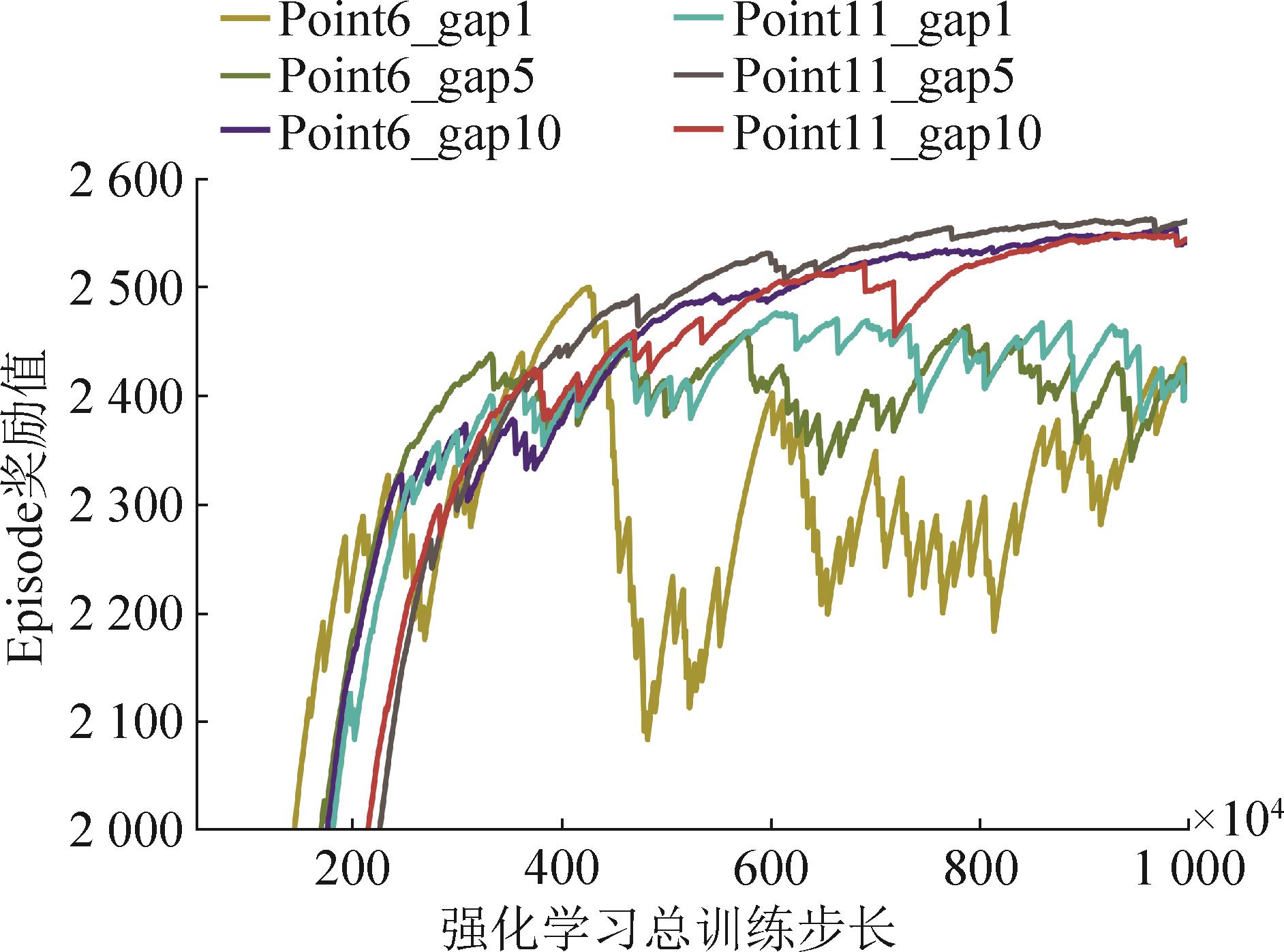
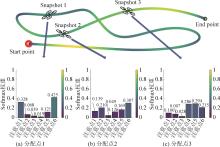
图14
注意力权重变化示意图(航迹4为例)
表5
大扰动范围设置
| 参数名称 | 新扰动范围 | 参数名称 | 新扰动范围 |
|---|---|---|---|
| 四旋翼质量 | |||
| 转动惯量 | |||
| 重力加速度 |
表6
大扰动航迹控制误差对比
| 航迹 | PPO-SAG (S) | PPO-SAG (M) | PID |
|---|---|---|---|
| 1 | 0.084 ± 0.174 | 0.120 ± 0.070 | 0.254 ± 0.096 |
| 2 | 0.054 ± 0.218 | 0.104 ± 0.116 | 0.231 ± 0.100 |
| 3 | 0.086 ± 0.252 | 0.159 ± 0.140 | 0.273 ± 0.103 |
| 4 | 0.105 ± 0.276 | 0.162 ± 0.181 | 0.293 ± 0.185 |
| 5 | 0.125 ± 0.289 | 0.238 ± 0.285 | 0.371 ± 0.472 |
| 6 | 0.131 ± 0.335 | 0.205 ± 0.245 | 0.289 ± 0.137 |
图15
四旋翼位置变化曲线(大扰动)
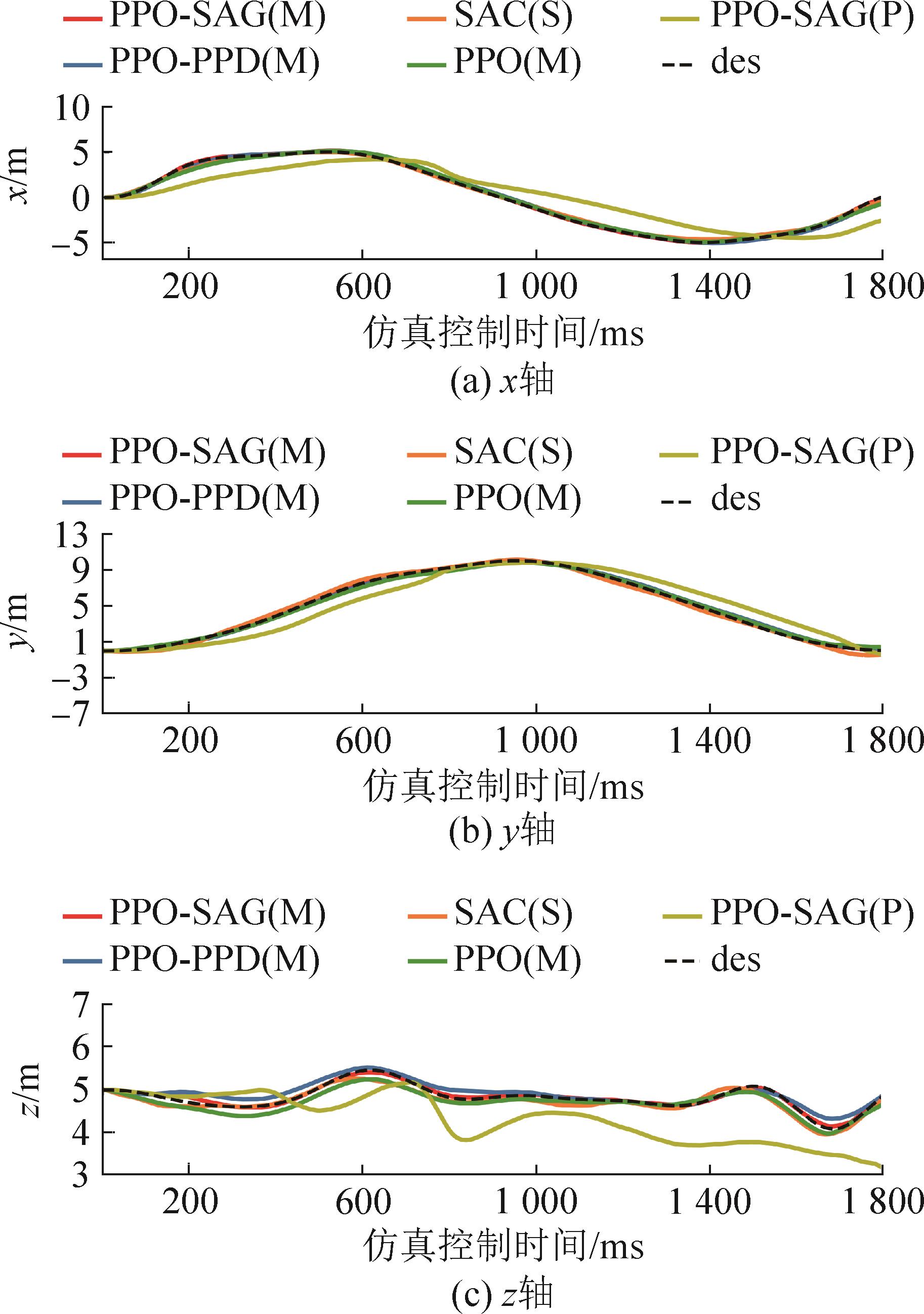

图16
仿真障碍环境下导航示意图
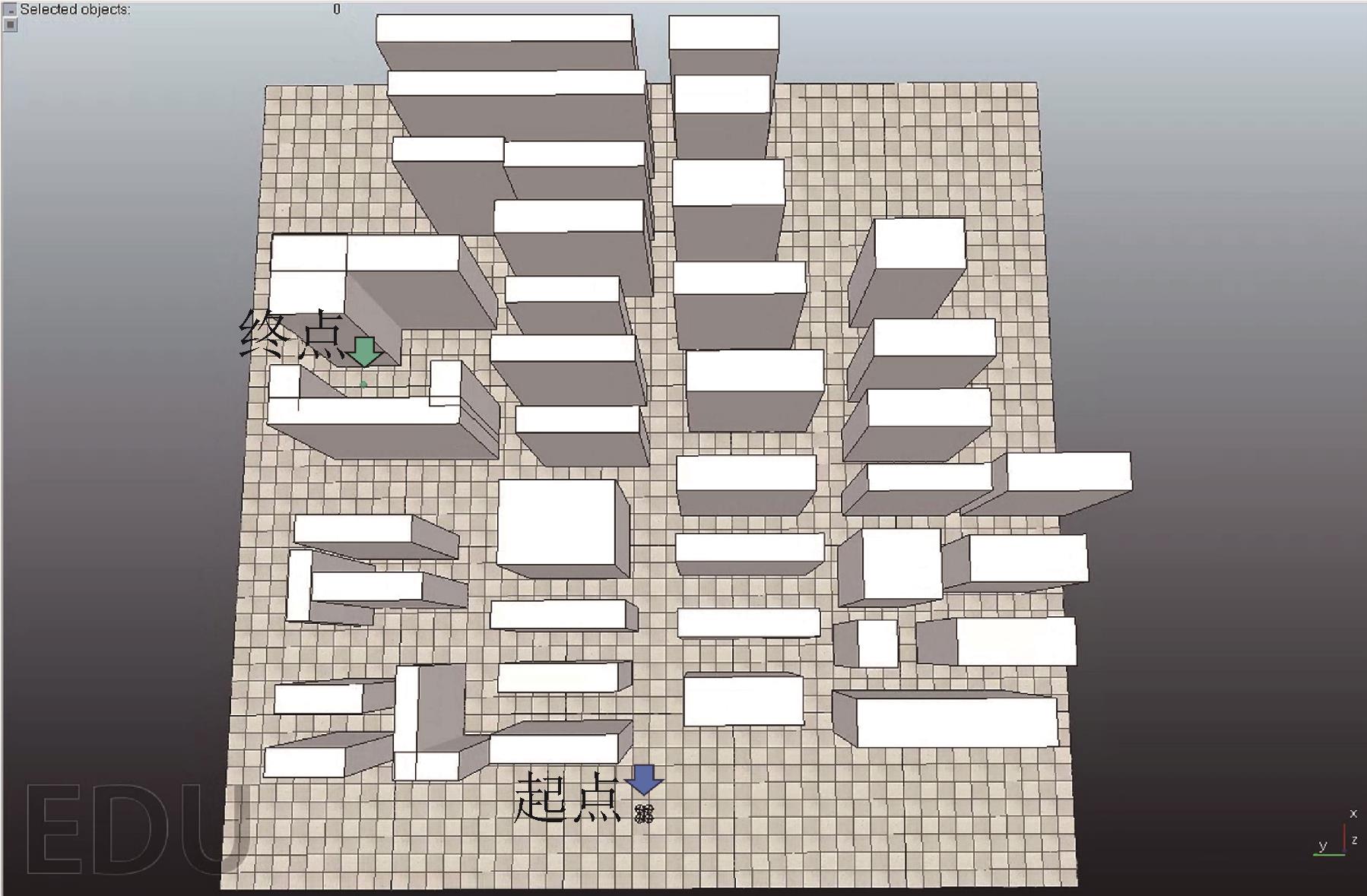
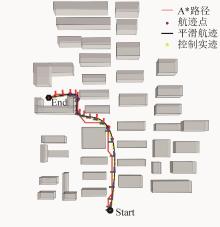
图17
航迹规划与控制飞行结果示意图
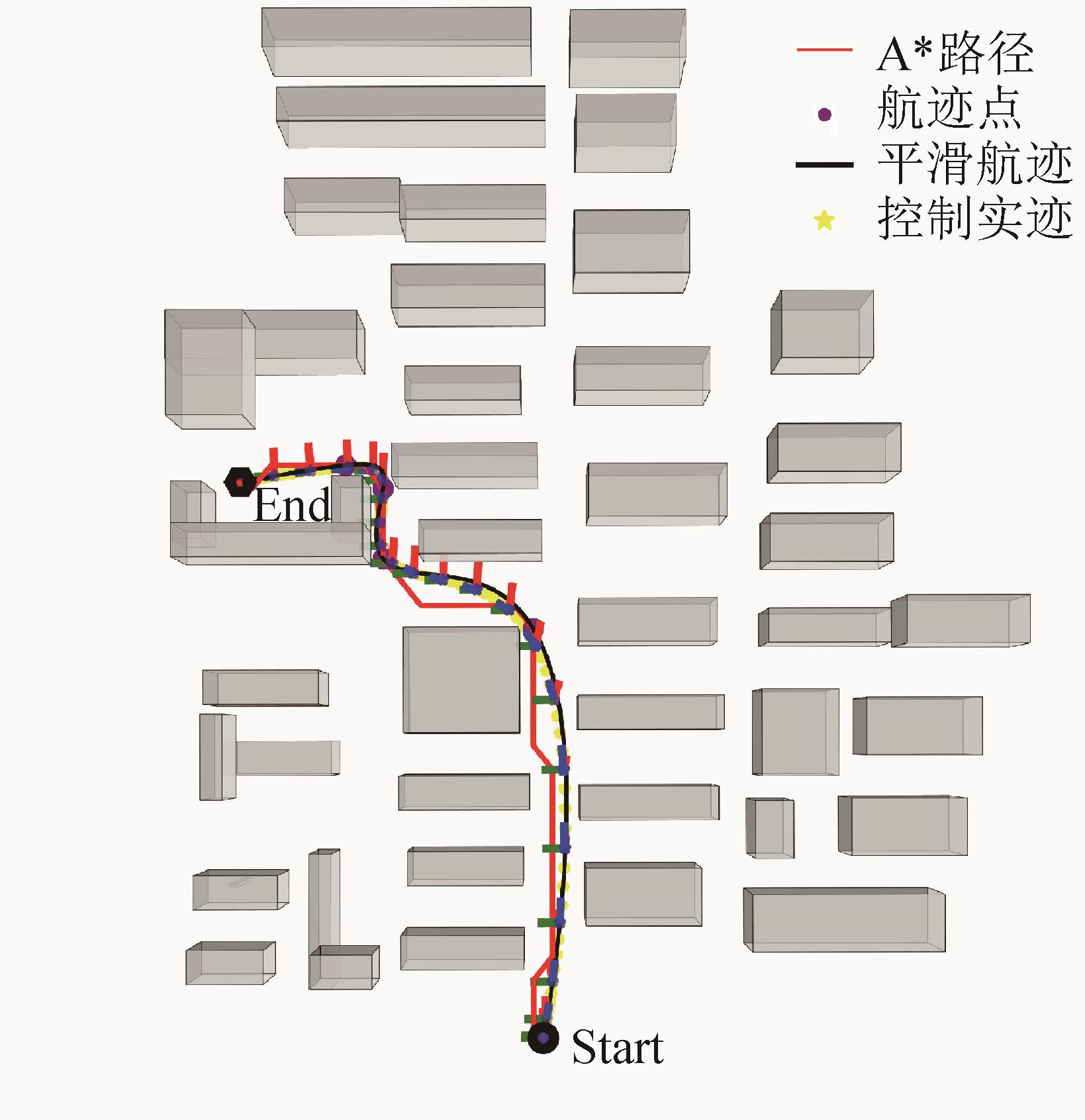
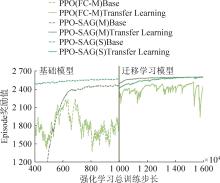
图18
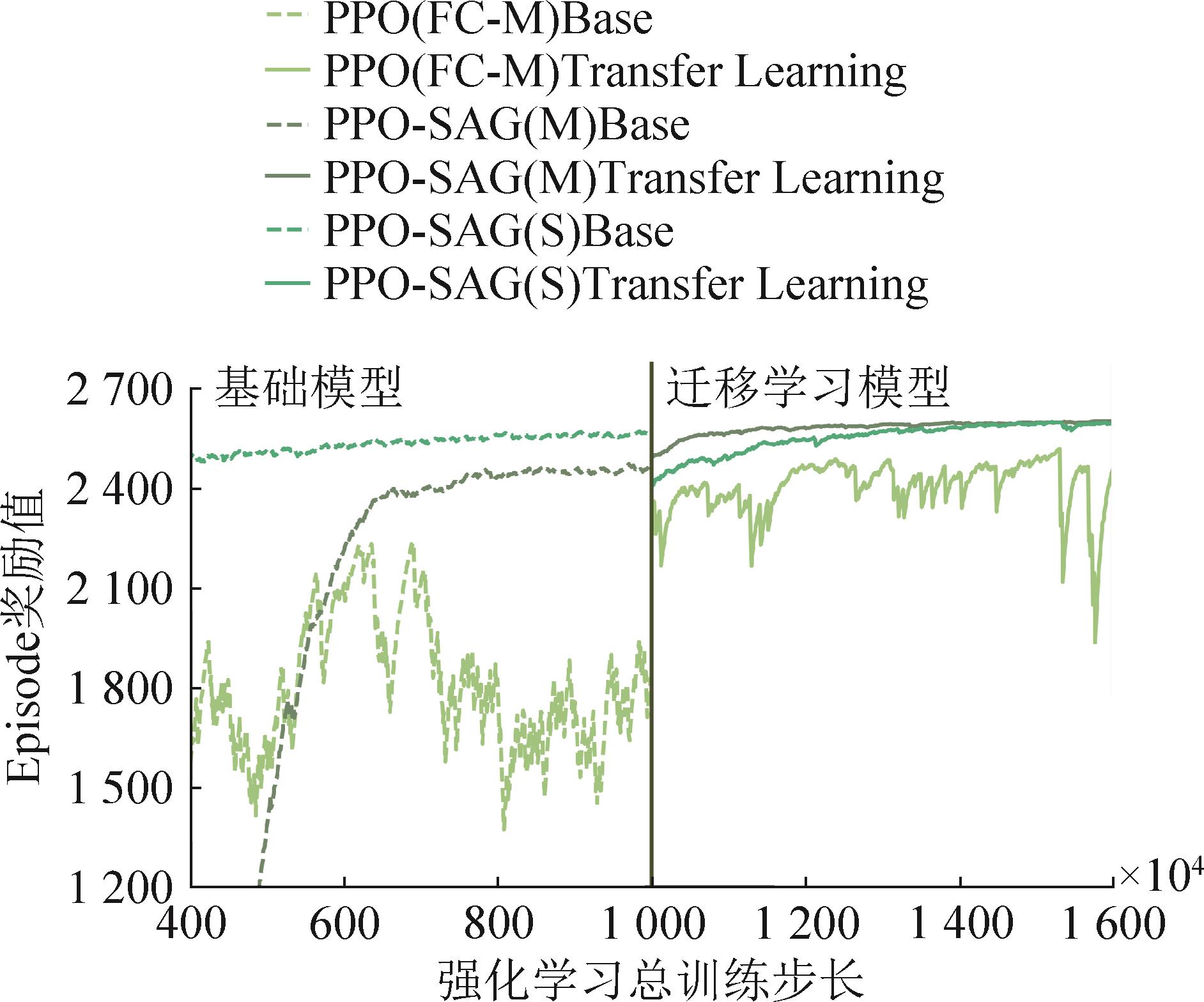
迁移强化学习训练结果
| 1 | 伍国华, 毛妮, 徐彬杰, 等. 基于自适应大规模邻域搜索算法的多车辆与多无人机协同配送方法[J]. 控制与决策, 2023, 38(1): 201-210. |
| Wu Guohua, Mao Ni, Xu Binjie, et al. The Cooperative Delivery of Multiple Vehicles and Multiple Drones Based on Adaptive Large Neighborhood Search[J]. Control and Decision, 2023, 38(1): 201-210. | |
| 2 | AlMahamid F, Grolinger K. Autonomous Unmanned Aerial Vehicle Navigation Using Reinforcement Learning: A Systematic Review[J]. Engineering Applications of Artificial Intelligence, 2022, 115: 105321. |
| 3 | Xue Wentao, Wu Hangxing, Ye Hui, et al. An Improved Proximal Policy Optimization Method for Low-level Control of a Quadrotor[J]. Actuators, 2022, 11(4): 105. |
| 4 | Lee T, Leok M, McClamroch N H. Geometric Tracking Control of a Quadrotor UAV on SE(3)[C]//49th IEEE conference on decision and control (CDC). Piscataway: IEEE, 2010: 5420-5425. |
| 5 | Kamel Mina, Burri Michael, Siegwart Roland. Linear vs Nonlinear MPC for Trajectory Tracking Applied to Rotary Wing Micro Aerial Vehicles[J]. IFAC-PapersOnLine, 2017, 50(1): 3463-3469. |
| 6 | Pi Chenhuan, Ye Weiyuan, Cheng S. Robust Quadrotor Control Through Reinforcement Learning with Disturbance Compensation[J]. Applied Sciences, 2021, 11(7): 3257. |
| 7 | Lambert N O, Drew D S, Yaconelli J, et al. Low-level Control of a Quadrotor with Deep Model-based Reinforcement Learning[J]. IEEE Robotics and Automation Letters, 2019, 4(4): 4224-4230. |
| 8 | 董豪, 杨静, 李少波, 等. 基于深度强化学习的机器人运动控制研究进展[J]. 控制与决策, 2022, 37(2): 278-292. |
| Dong Hao, Yang Jing, Li Shaobo, et al. Research Progress of Robot Motion Control Based on Deep Reinforcement Learning[J]. Control and Decision, 2022, 37(2): 278-292. | |
| 9 | Hwangbo Jemin, Sa Inkyu, Siegwart Roland, et al. Control of a Quadrotor with Reinforcement Learning[J]. IEEE Robotics and Automation Letters, 2017, 2(4): 2096-2103. |
| 10 | Koch W, Mancuso R, West R, et al. Reinforcement Learning for UAV Attitude Control[J]. ACM Transactions on Cyber-Physical Systems, 2019, 3(2): 22. |
| 11 | Koch W, Mancuso R, Bestavros A. Neuroflight: Next Generation Flight Control Firmware[EB/OL]. (2019-09-16) [2022-10-06]. . |
| 12 | Guilherme Cano Lopes, Ferreira Murillo, Alexandre da Silva Simões, et al. Intelligent Control of a Quadrotor with Proximal Policy Optimization Reinforcement Learning[C]//2018 Latin American Robotic Symposium, 2018 Brazilian Symposium on Robotics (SBR) and 2018 Workshop on Robotics in Education (WRE). Piscataway: IEEE, 2018: 503-508. |
| 13 | Shehab Mazen, Zaghloul Ahmed, El-Badawy Ayman. Low-level Control of a Quadrotor Using Twin Delayed Deep Deterministic Policy Gradient (TD3)[C]//2021 18th International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE). Piscataway: IEEE, 2021: 1-6. |
| 14 | Gabriel Moraes Barros, Esther Luna Colombini. Using Soft Actor-critic for Low-level UAV Control[EB/OL]. (2020-10-05) [2023-10-06]. . |
| 15 | Wang Yuanda, Sun Jia, He Haibo, et al. Deterministic Policy Gradient with Integral Compensator for Robust Quadrotor Control[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2020, 50(10): 3713-3725. |
| 16 | Barzegar Ali, Jin Lee Deok. Deep Reinforcement Learning-based Adaptive Controller for Trajectory Tracking and Altitude Control of an Aerial Robot[J]. Applied Sciences, 2022, 12(9): 4764. |
| 17 | 梁吉, 王立松, 黄昱洲, 等. 基于深度强化学习的四旋翼无人机自主控制方法[J]. 计算机科学, 2023, 50(增2): 1-7. |
| Liang Ji, Wang Lisong, Huang Yuzhou, et al. Autonomous Control Algorithm for Quadrotor Based on Deep Reinforcement Learning[J]. Computer Science, 2023, 50(S2): 1-7. | |
| 18 | 王伟, 吴昊, 刘鸿勋, 等. 基于深度强化学习的无人机姿态控制器设计[J]. 科学技术与工程, 2023, 23(34): 14888-14895. |
| Wang Wei, Wu Hao, Liu Hongxun, et al. An Attitude Controller for Quadrotor Drone Using RM-DDPG[J]. Science Technology and Engineering, 2023, 23(34): 14888-14895. | |
| 19 | 孙丹, 高东, 郑建华, 等. 引入积分补偿的四旋翼确定性策略梯度控制器[J]. 计算机工程与设计, 2023, 44(1): 255-261. |
| Sun Dan, Gao Dong, Zheng Jianhua, et al. Deterministic Policy Gradient Controller with integral compensator for quadrotor[J]. Computer Engineering and Design, 2023, 44(1): 255-261. | |
| 20 | 杨志鹏, 李波, 甘志刚, 等. 基于深度强化学习的四旋翼无人机航线跟随[J]. 指挥与控制学报, 2022, 8(4): 477-482. |
| Yang Zhipeng, Li Bo, Gan Zhigang, et al. Route Following of Quadrotor UAV Based on Deep Reinforcement Learning[J]. Journal of Command and Control, 2022, 8(4): 477-482. | |
| 21 | 孙丹, 高东, 郑建华, 等. 示教知识辅助的无人机强化学习控制算法[J]. 北京航空航天大学学报, 2023, 49(6): 1424-1433. |
| Sun Dan, Gao Dong, Zheng Jianhua, et al. UAV Reinforcement Learning Control Algorithm with Demonstrations[J]. Journal of Beijing University of Aeronautics and Astronautics, 2023, 49(6): 1424-1433. | |
| 22 | 刘安林, 时正华. 基于DDPG策略的四旋翼飞行器目标高度控制[J]. 陕西科技大学学报, 2021, 39(6): 141-147. |
| Liu Anlin, Shi Zhenghua. Desired Height Control of Quadrotor Vehicle Based on DDPG Strategy[J]. Journal of Shaanxi University of Science & Technology, 2021, 39(6): 141-147. | |
| 23 | Molchanov A, Chen Tao, Hönig Wolfgang, et al. Sim-to-(multi)-real: Transfer of Low-level Robust Control Policies to Multiple Quadrotors[C]//2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway: IEEE, 2019: 59-66. |
| 24 | Kaufmann Elia, Bauersfeld Leonard, Scaramuzza Davide. A Benchmark Comparison of Learned Control Policies for Agile Quadrotor Flight[C]//2022 International Conference on Robotics and Automation (ICRA). Piscataway: IEEE, 2022: 10504-10510. |
| 25 | Song Yunlong, Steinweg Mats, Kaufmann Elia, et al. Autonomous Drone Racing with Deep Reinforcement Learning[C]//2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway: IEEE, 2021: 1205-1212. |
| 26 | Penicka Robert, Song Yunlong, Kaufmann Elia, et al. Learning Minimum-time Flight in Cluttered Environments[J]. IEEE Robotics and Automation Letters, 2022, 7(3): 7209-7216. |
| 27 | Wu Guohua, Mao Ni, Luo Qizhang, et al. Collaborative Truck-drone Routing for Contactless Parcel Delivery During the Epidemic[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(12): 25077-25091. |
| 28 | Xu Binjie, Zhao Kexin, Luo Qizhang, et al. A GV-drone Arc Routing Approach for Urban Traffic Patrol by Coordinating a Ground Vehicle and Multiple Drones[J]. Swarm and Evolutionary Computation, 2023, 77: 101246. |
| 29 | Faessler Matthias, Franchi Antonio, Scaramuzza Davide. Differential Flatness of Quadrotor Dynamics Subject to Rotor Drag for Accurate Tracking of High-speed Trajectories[J]. IEEE Robotics and Automation Letters, 2018, 3(2): 620-626. |
| 30 | Hart P E, Nilsson N J, Raphael B. A Formal Basis for the Heuristic Determination of Minimum Cost Paths[J]. IEEE Transactions on Systems Science and Cybernetics, 1968, 4(2): 100-107. |
| 31 | Mellinger D, Kumar V. Minimum Snap Trajectory Generation and Control for Quadrotors[C]//2011 IEEE international conference on robotics and automation. Piscataway: IEEE, 2011: 2520-2525. |
| 32 | Kirkpatrick S, Gelatt C D Jr, Vecchi M P. Optimization by Simulated Annealing[J]. Science, 1983, 220(4598): 671-680. |
| 33 | Schulman J, Levine S, Moritz P, et al. Trust Region Policy Optimization[C]//Proceedings of the 32nd International Conference on International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2015: 1889-1897. |
| 34 | Williams R J. Simple Statistical Gradient-following Algorithms for Connectionist Reinforcement Learning[J]. Machine Learning, 1992, 8(3): 229-256. |
| 35 | Schulman J, Moritz P, Levine S, et al. High-dimensional Continuous Control Using Generalized Advantage Estimation[EB/OL]. (2018-10-20) [2023-10-06]. . |
| 36 | Schulman J, Wolski F, Dhariwal P, et al. Proximal Policy Optimization Algorithms[EB/OL]. (2017-08-28) [2023-10-06]. . |
| 37 | Ilyas A, Engstrom L, Santurkar S, et al. Are Deep Policy Gradient Algorithms Truly Policy Gradient Algorithms?[EB/OL]. (2020-05-25) [2023-10-06]. . |
| 38 | Chu Xiangxiang. Policy Optimization with Penalized Point Probability Distance: An Alternative to Proximal Policy Optimization[EB/OL]. (2019-02-14) [2023-10-06]. . |
| 39 | Haarnoja T, Tang Haoran, Abbeel P, et al. Reinforcement Learning with Deep Energy-based Policies[C]//Proceedings of the 34th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2017: 1352-1361. |
| 40 | Tucker G, Bhupatiraju S, Gu Shixiang, et al. The Mirage of Action-dependent Baselines in Reinforcement Learning[C]//Proceedings of the 35th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2018: 5015-5024. |
| 41 | Engstrom L, Ilyas A, Santurkar S, et al. Implementation Matters in Deep Policy Gradients: A Case Study on PPO and TRPO[EB/OL]. (2020-05-25) [2023-10-06]. . |
| 42 | Vaswani A, Shazeer N, Parmar N, et al. Attention Is All You Need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 43 | Kingma D P, Ba J. Adam: A Method for Stochastic Optimization[EB/OL]. (2017-01-30) [2023-10-06]. . |
| 44 | Rohmer Eric, Singh S P N, Freese Marc. V-REP: A Versatile and Scalable Robot Simulation Framework[C]//2013 IEEE/RSJ international conference on intelligent robots and systems. Piscataway: IEEE, 2013: 1321-1326. |
| 45 | James S, Freese M, Davison A J. PyRep: Bringing V-REP to Deep Robot Learning[EB/OL]. (2019-06-26) [2023-10-06]. . |
| 46 | Förster Julian. System Identification of the Crazyflie 2.0 Nano Quadrocopter[D]. Zurich: ETH Zurich, 2015. |
| [1] | 陈燕军, 周敏, 查蒙, 张美洲. 基于CCL-YOLOv8的汽车轮毂表面缺陷检测算法研究与分析[J]. 系统仿真学报, 2026, 38(3): 670-686. |
| [2] | 吴舒霞, 张俊杰, 陈德珑, 陈哲毅. 面向边缘实时视频分析的资源高效持续学习框架[J]. 系统仿真学报, 2026, 38(2): 294-306. |
| [3] | 杨灿, 陈凯, 朱峰. 多约束条件下基于强化学习的无人机团队定向优化方法[J]. 系统仿真学报, 2026, 38(2): 360-371. |
| [4] | 王秉坤, 王越, 杨妹, 张鹏年, 樊浡昊, 唐杰. 基于改进近端策略优化算法的无人车打击策略规划方法[J]. 系统仿真学报, 2026, 38(2): 372-386. |
| [5] | 丁拯坤, 刘佳奇, 徐军政, 徐悦竹, 王兴梅. 基于BiGRU与优先级动态采样的智能空战决策方法[J]. 系统仿真学报, 2026, 38(2): 447-459. |
| [6] | 陶彩霞, 陈乃焜, 高锋阳, 张建刚. 基于多智能体强化学习的综合能源分布式优化[J]. 系统仿真学报, 2026, 38(2): 476-487. |
| [7] | 王继恒, 胡阳, 宋子秋, 房方, 刘吉臻. 基于多模态混合深度学习的大型风电机组入流风场预测[J]. 系统仿真学报, 2026, 38(2): 501-517. |
| [8] | 江明, 何韬. 基于深度强化学习的带容量约束车辆路径问题求解[J]. 系统仿真学报, 2025, 37(9): 2177-2187. |
| [9] | 姜彦吉, 张颖阳, 董浩, 张晓光, 王美惠. 基于实例关联的暗光下车道线检测[J]. 系统仿真学报, 2025, 37(9): 2188-2199. |
| [10] | 马仑, 杨跃, 王迨贺, 廖桂生, 李幸. 联合自注意力机制与权值共享的人体行为识别模型[J]. 系统仿真学报, 2025, 37(9): 2409-2419. |
| [11] | 倪培龙, 毛鹏军, 王宁, 杨孟杰. 基于改进A-DDQN算法的机器人路径规划[J]. 系统仿真学报, 2025, 37(9): 2420-2430. |
| [12] | 鲁斌, 杨烜, 杨振宇, 高啸天. 自适应采样与重影多尺度特征融合的轻量化焊缝缺陷检测[J]. 系统仿真学报, 2025, 37(8): 1978-1990. |
| [13] | 刘子龙, 张磊. 自然环境下改进YOLOv5对小目标苹果的检测[J]. 系统仿真学报, 2025, 37(8): 2124-2138. |
| [14] | 陈真, 吴卓屹, 张霖. 深度强化学习中策略表征研究简述[J]. 系统仿真学报, 2025, 37(7): 1753-1769. |
| [15] | 王子怡, 张凯, 钱殿伟, 刘玉贞. 一种基于DRL的分布式装备体系优选方法[J]. 系统仿真学报, 2025, 37(6): 1565-1573. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
