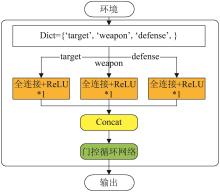
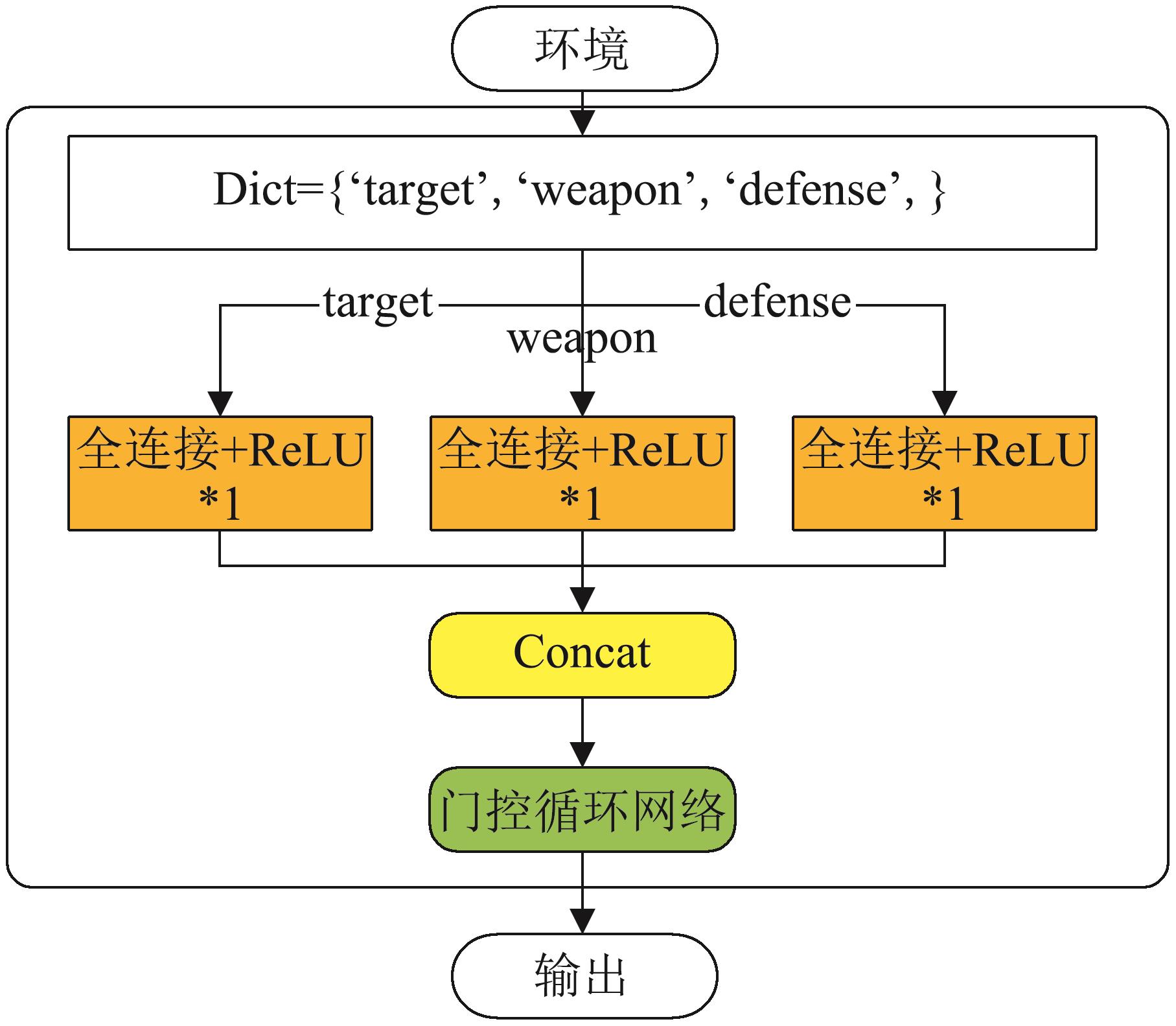
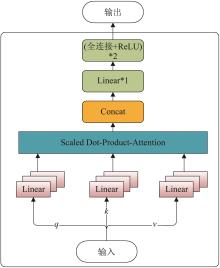
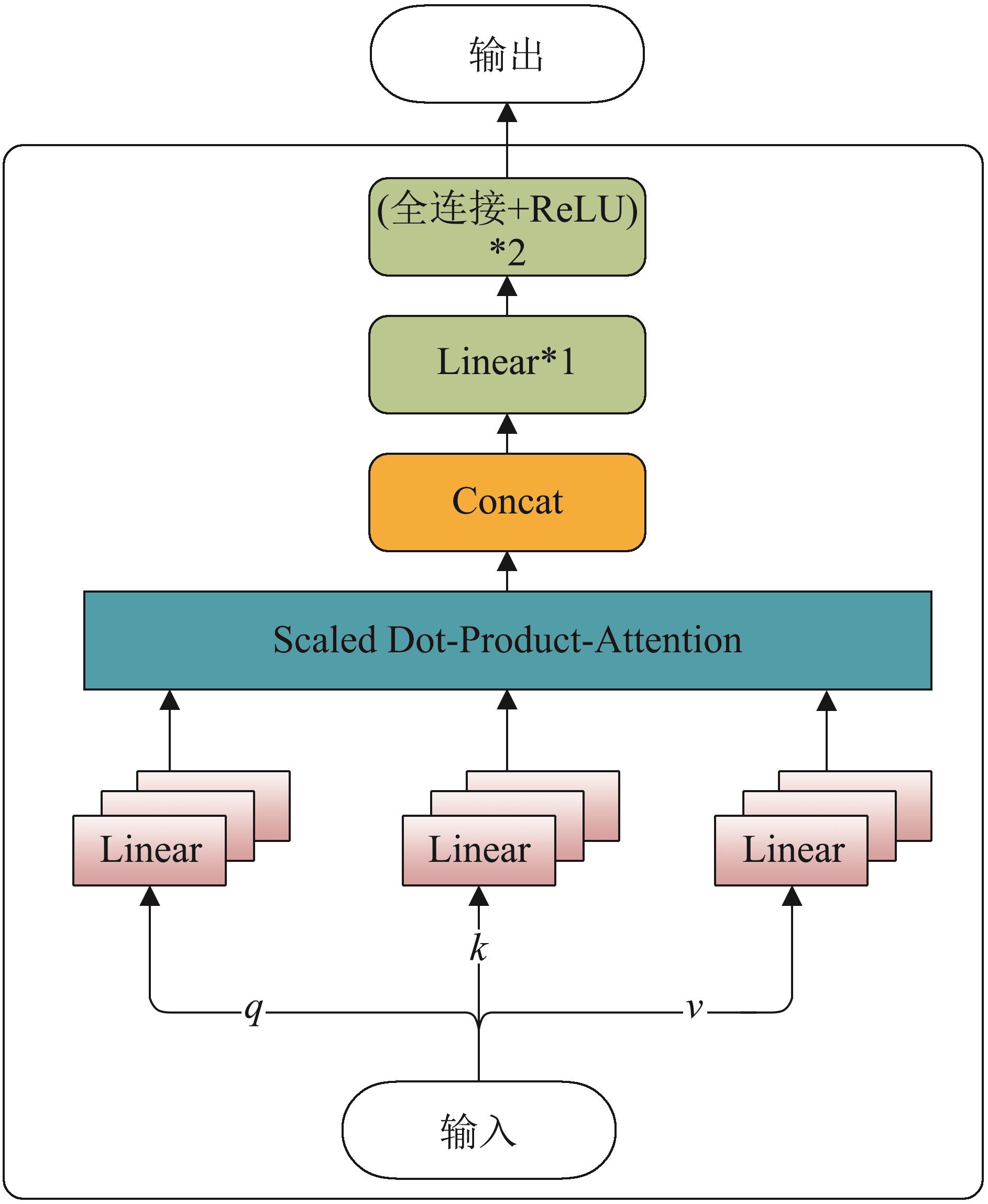
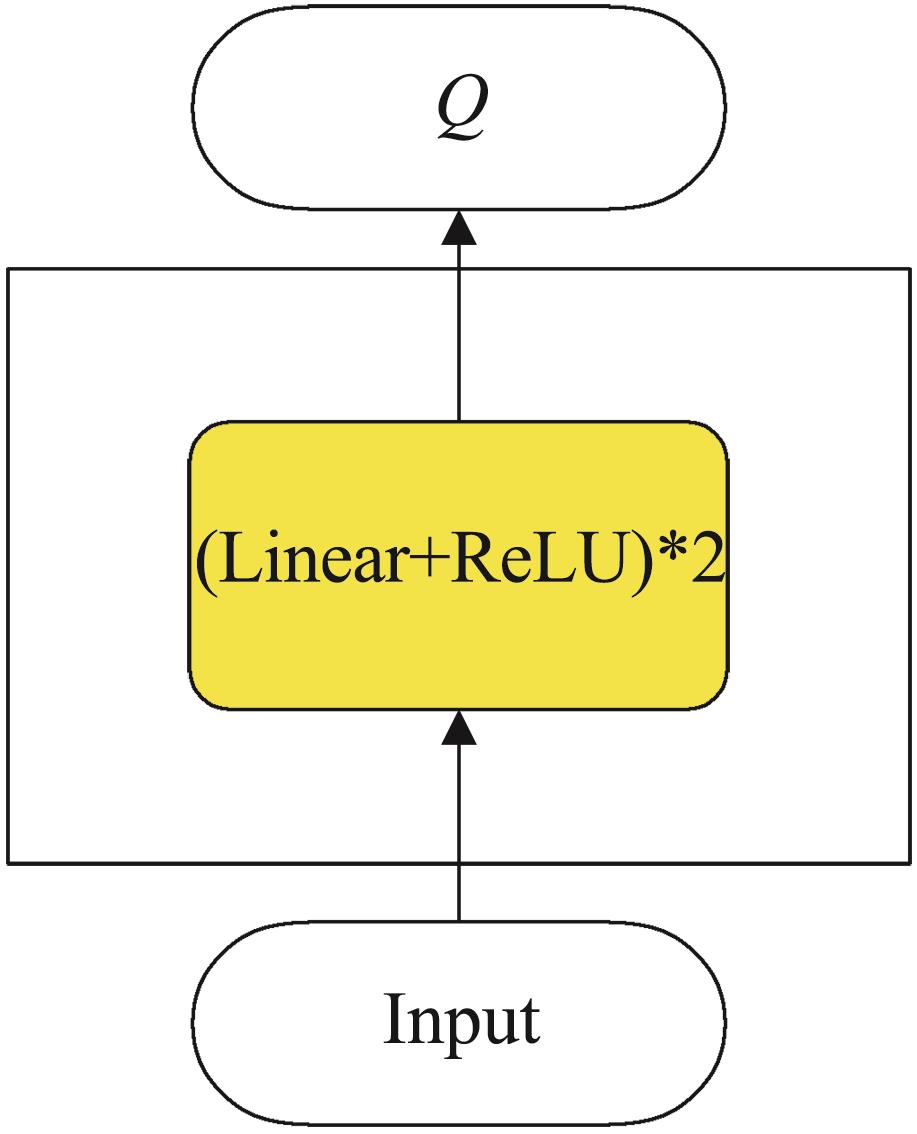
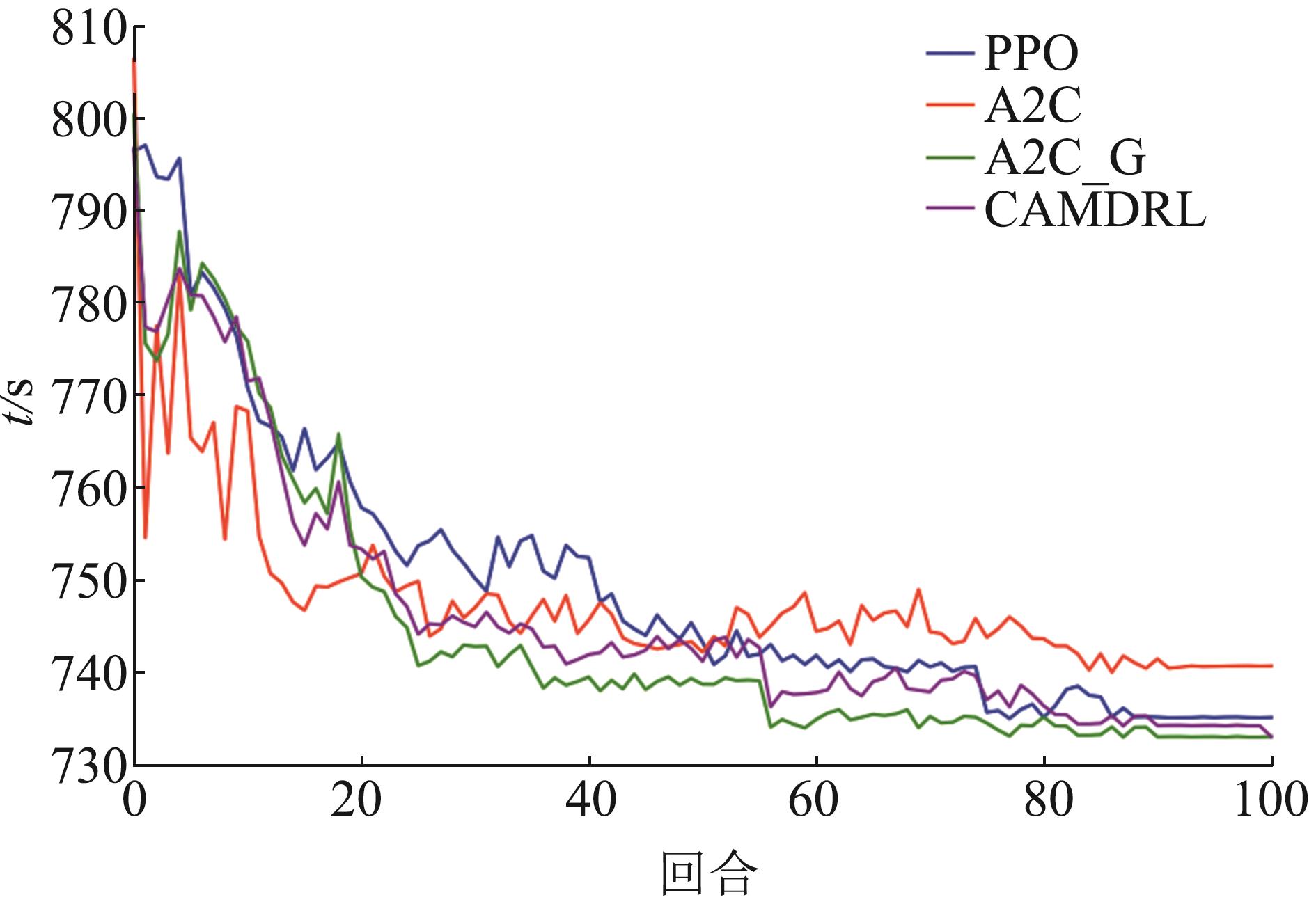
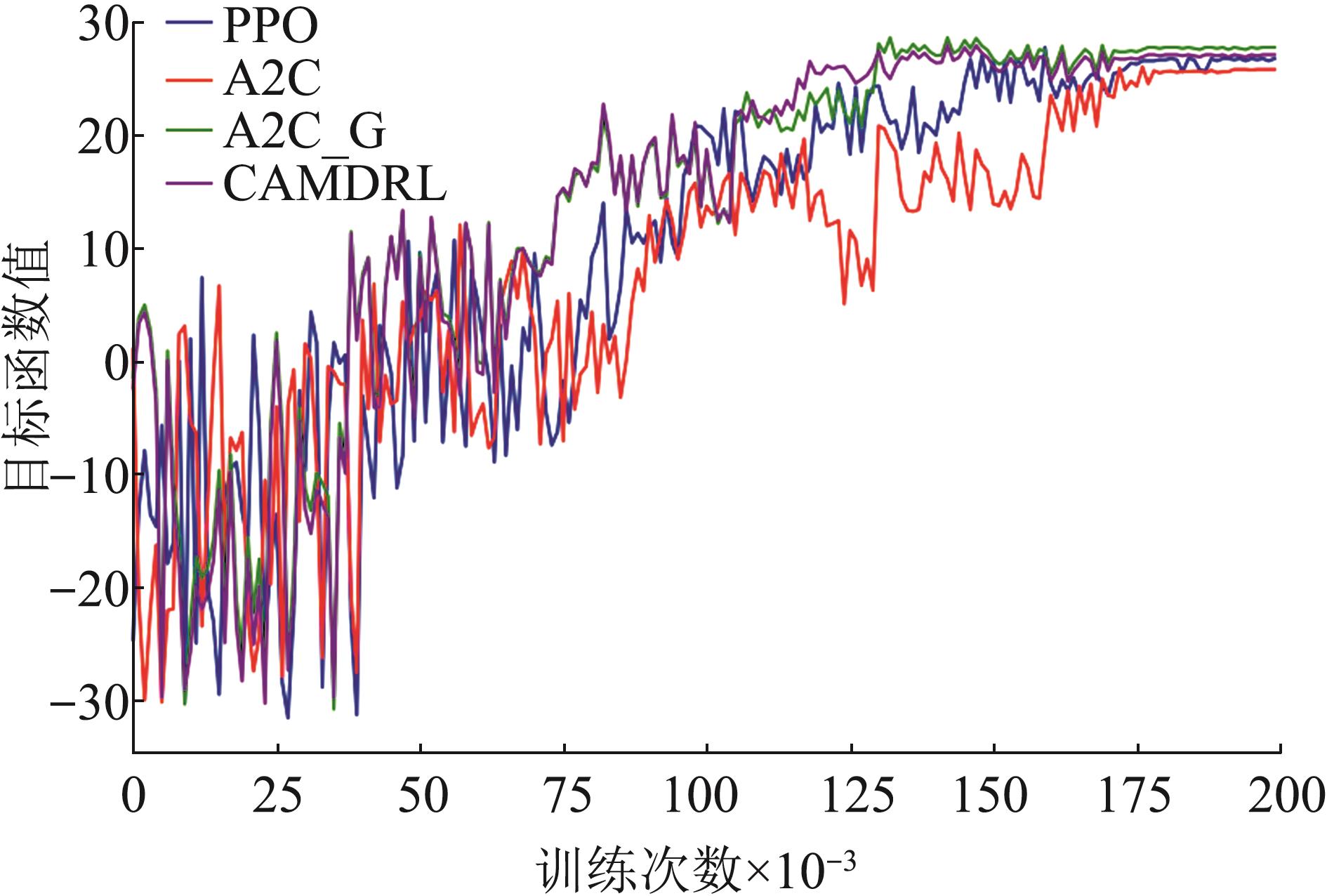
| 1 |
李龙跃, 刘付显, 赵麟锋. 对多波次目标直接分配到弹的反导火力规划方法[J]. 系统工程与电子技术, 2014(11): 2206-2212.
|
|
Li Longyue, Liu Fuxian, Zhao Linfeng. Direct Interceptor Allocation Method in Antimissile Firepower Planning for Multiple Wave Targets[J]. Systems Engineering and Electronics, 2014(11): 2206-2212.
|
| 2 |
姚继帅. 多导弹武器-目标分配关键技术研究[D]. 长沙: 国防科技大学, 2020.
|
|
Yao Jishuai. Research on Key Technology of Multi-missile Weapon-target Assignment[D]. Changsha: National University of Defense Technology, 2020.
|
| 3 |
Matlin S. A Review of the Literature on the Missile-allocation Problem[J]. Operations Research, 1970, 18(2): 334-373.
|
| 4 |
Kline A, Ahner D, Hill R. The Weapon-target Assignment Problem[J]. Computers & Operations Research, 2019, 105: 226-236.
|
| 5 |
李梦杰, 常雪凝, 石建迈, 等. 武器目标分配问题研究进展: 模型、算法与应用[J]. 系统工程与电子技术, 2023, 45(4): 1049-1071.
|
|
Li Mengjie, Chang Xuening, Shi Jianmai, et al. Developments of Weapon Target Assignment: Models, Algorithms, and Applications[J]. Systems Engineering and Electronics, 2023, 45(4): 1049-1071.
|
| 6 |
宋贵宝, 强裕功, 刘铁, 等. 动态武器目标分配问题的现状与进展[J]. 兵器装备工程学报, 2022, 43(12): 83-88.
|
|
Song Guibao, Qiang Yugong, Liu Tie, et al. The Present Situation and Progress of Dynamic Weapon Target Assignment[J]. Journal of Ordnance Equipment Engineering, 2022, 43(12): 83-88.
|
| 7 |
葛志欣. 基于深度强化学习的多智能体协同决策研究[D]. 大连: 大连理工大学, 2021.
|
|
Ge Zhixin. Research on Collaborative Decision of Multi-agent Based on Deep Reinforcement Learning[D]. Dalian: Dalian University of Technology, 2021.
|
| 8 |
张梦钰, 豆亚杰, 陈子夷, 等. 深度强化学习及其在军事领域中的应用综述[J]. 系统工程与电子技术, 2024, 46(4): 1297-1308.
|
|
Zhang Mengyu, Dou Yajie, Chen Ziyi, et al. Review of Deep Reinforcement Learning and Its Applications in Military Field[J]. Systems Engineering and Electronics, 2024, 46(4): 1297-1308.
|
| 9 |
李冬雪. 基于深度强化学习的资源分配问题研究[D]. 北京: 北京交通大学, 2021.
|
|
Li Dongxue. Research on Resource Assignment Problem Based on Deep Reinforcement Learning[D]. Beijing: Beijing Jiaotong University, 2021.
|
| 10 |
熊蓉玲, 段春怡, 冉华明, 等. 基于深度强化学习的智能决策方法[J]. 电讯技术, 2023, 63(1): 1-6.
|
|
Xiong Rongling, Duan Chunyi, Ran Huaming, et al. An Intelligent Decision Making Method Based on Deep Reinforcement Learning[J]. Telecommunications Technology, 2023, 63(1): 1-6.
|
| 11 |
Li Xiaoyang, Zhou Deyun, Yang Zhen, et al. A Novel Genetic Algorithm for the Synthetical Sensor-weapon-target Assignment Problem[J]. Applied Sciences, 2019, 9(18): 3803.
|
| 12 |
Chang Tianqing, Kong Depeng, Hao Na, et al. Solving the Dynamic Weapon Target Assignment Problem by an Improved Artificial Bee Colony Algorithm with Heuristic Factor Initialization[J]. Applied Soft Computing, 2018, 70: 845-863.
|
| 13 |
Chang Yizhe, Li Zhanwu, Kou Yingxin, et al. A New Approach to Weapon-target Assignment in Cooperative Air Combat[J]. Mathematical Problems in Engineering, 2017, 2017(1): 2936279.
|
| 14 |
龙腾, 刘震宇, 史人赫, 等. 基于神经网络的防空武器目标智能分配方法[J]. 空天防御, 2021, 4(1): 1-7.
|
|
Long Teng, Liu Zhenyu, Shi Renhe, et al. Neural Network Based Air Defense Weapon Target Intelligent Assignment Method[J]. Air & Space Defense, 2021, 4(1): 1-7.
|
| 15 |
肖友刚, 金升成, 毛晓, 等. 基于深度强化学习的舰船导弹目标分配方法[J/OL]. 控制理论与应用. (2023-06-12) [2023-09-24]. .
|
|
Xiao Yougang, Jin Shengcheng, Mao Xiao, et al. Deep Reinforcement Learning Based Target Assignment Method for Ship Missile[J/OL]. Control Theory & Applications. (2023-06-12) [2023-09-24]. .
|
| 16 |
李思远. 面向智能军事决策的深度强化学习算法研究[D]. 太原: 中北大学, 2022.
|
|
Li Siyuan. Research on Deep Reinforcement Learning Algorithm for Intelligent Military Decision[D]. Taiyuan: North University of China, 2022.
|
| 17 |
朱建文, 赵长见, 李小平, 等. 基于强化学习的集群多目标分配与智能决策方法[J]. 兵工学报, 2021, 42(9): 2040-2048.
|
|
Zhu Jianwen, Zhao Changjian, Li Xiaoping, et al. Multi-target Assignment and Intelligent Decision Based on Reinforcement Learning[J]. Acta Armamentarii, 2021, 42(9): 2040-2048.
|
| 18 |
Junyoung Chung, Gulcehre Caglar, Cho KyungHyun, et al. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling[EB/OL]. (2014-12-11) [2023-10-08]. .
|
| 19 |
Lipton Z C, Berkowitz J, Elkan C. A Critical Review of Recurrent Neural Networks for Sequence Learning[EB/OL]. (2015-10-17) [2023-10-08]. .
|
| 20 |
Vaswani A, Shazeer N, Parmar N, et al. Attention Is All You Need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010.
|