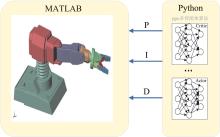
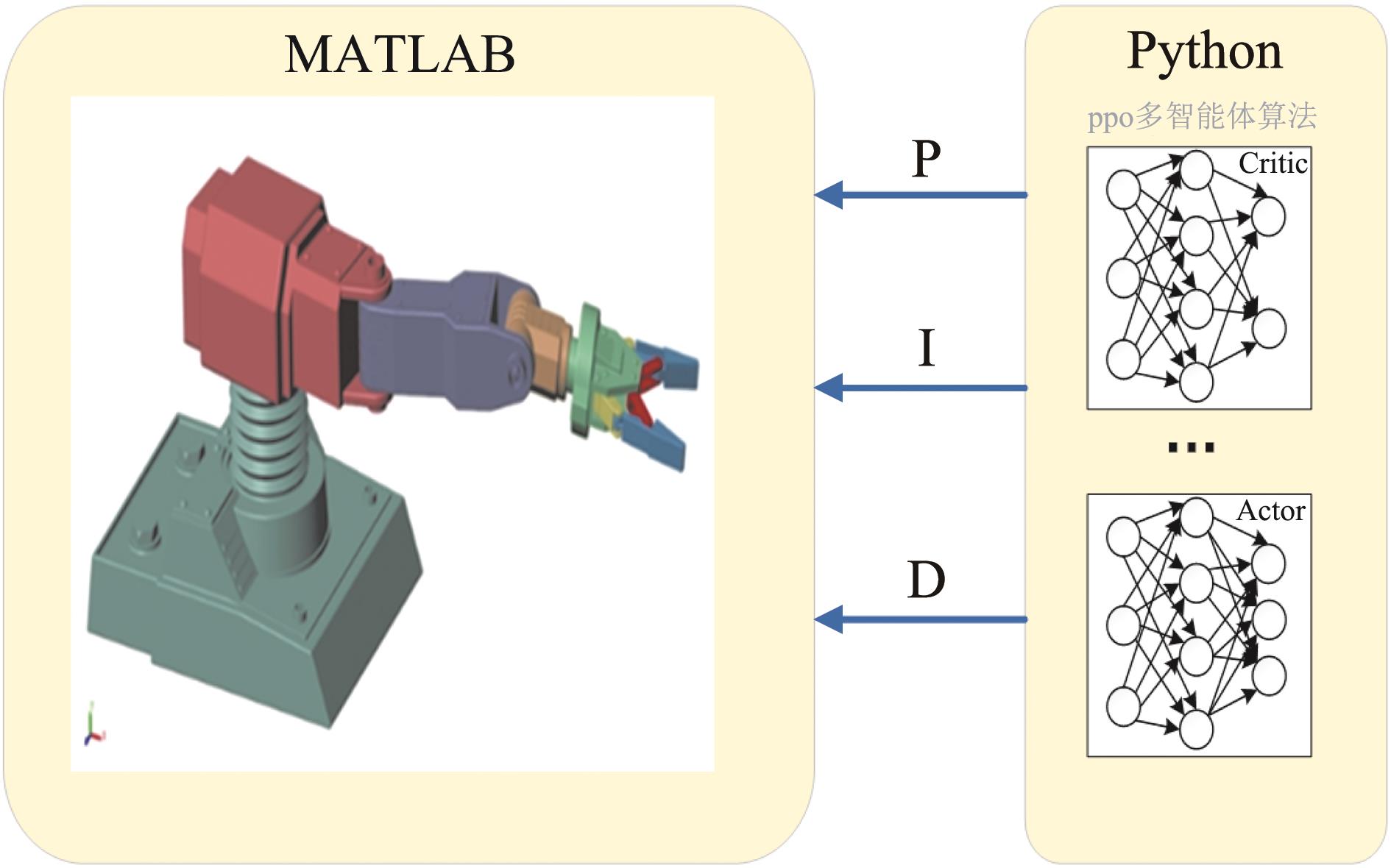
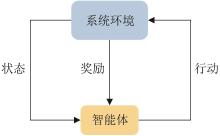
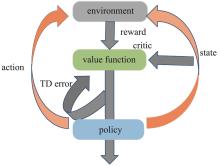
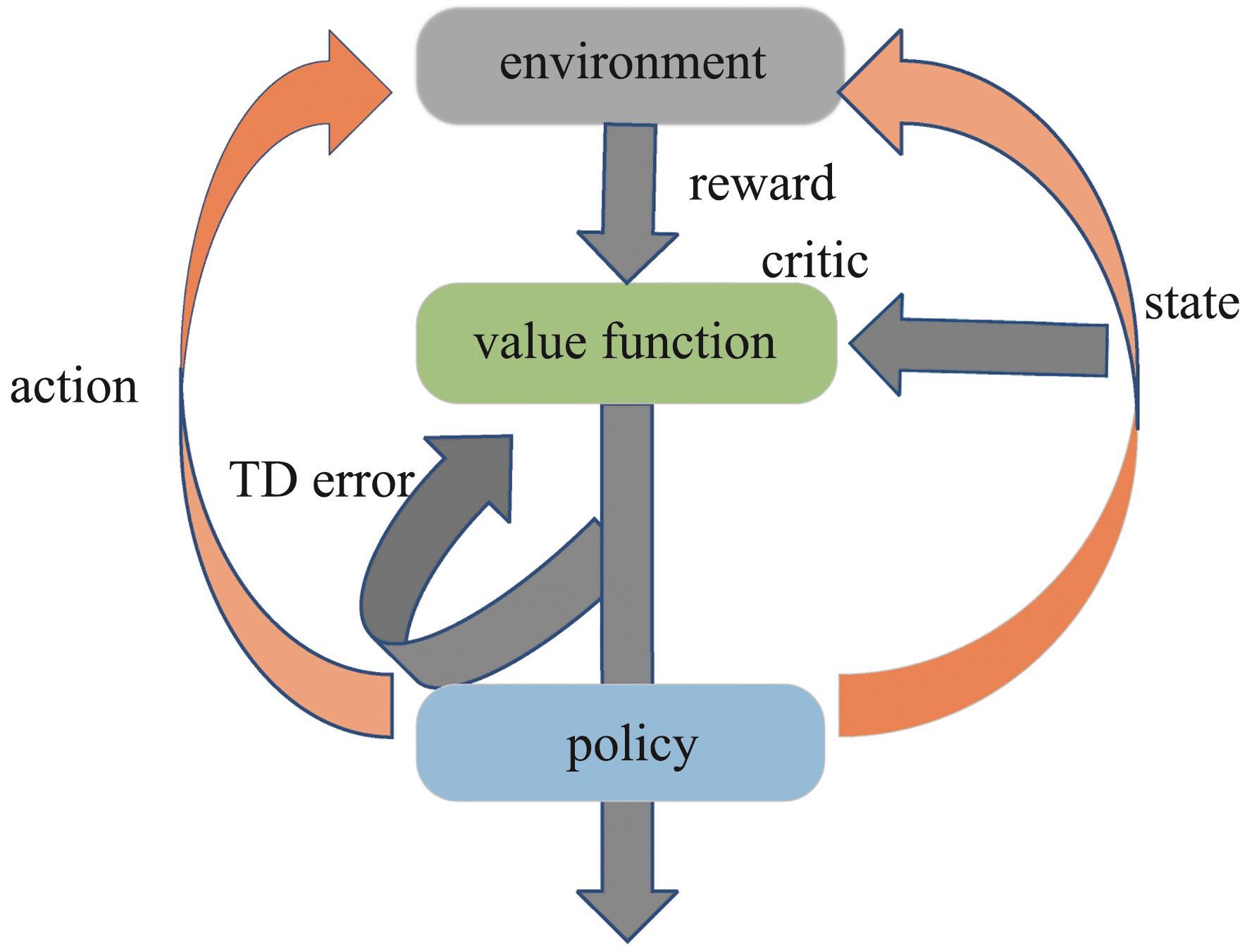
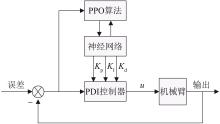
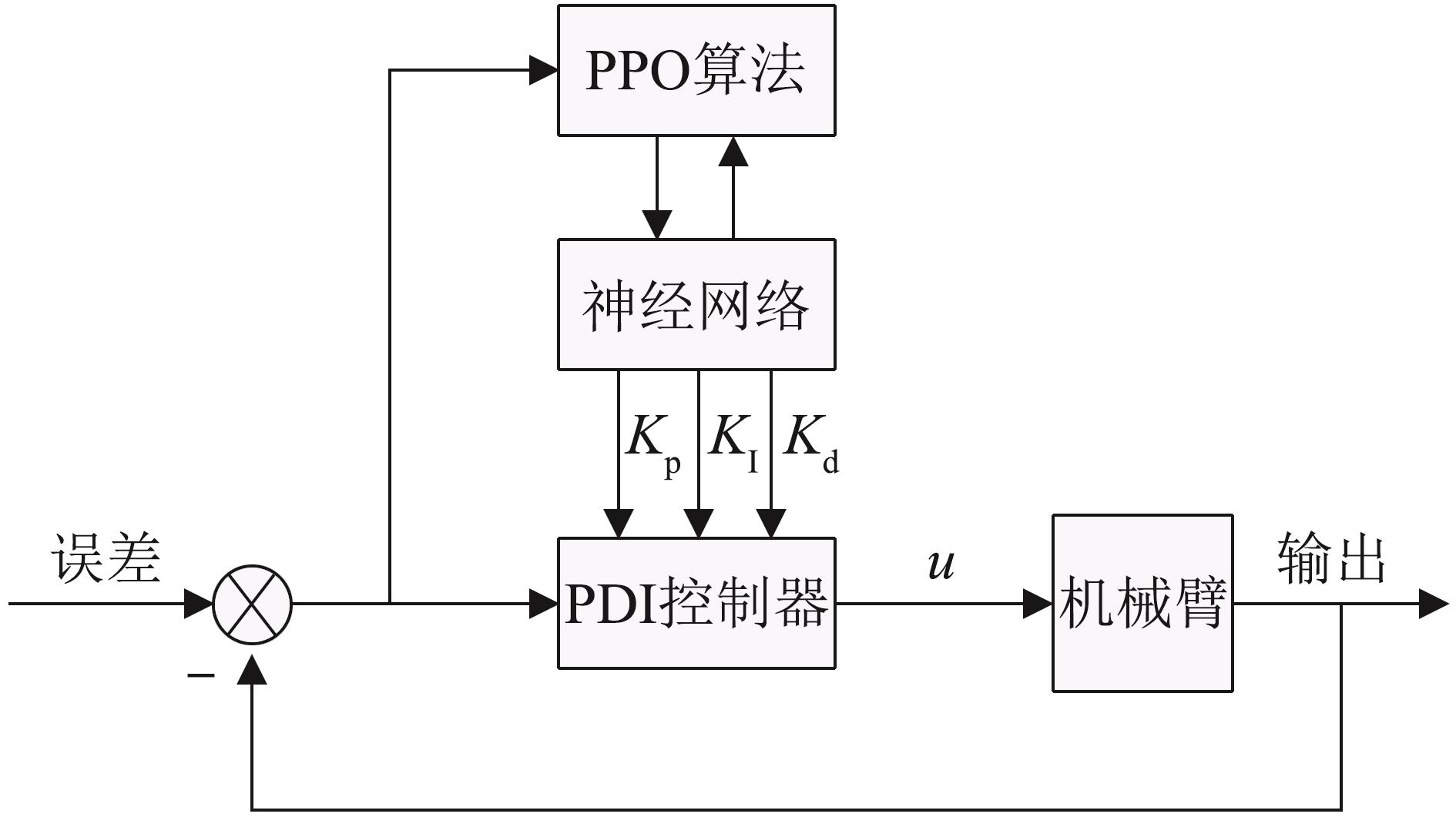
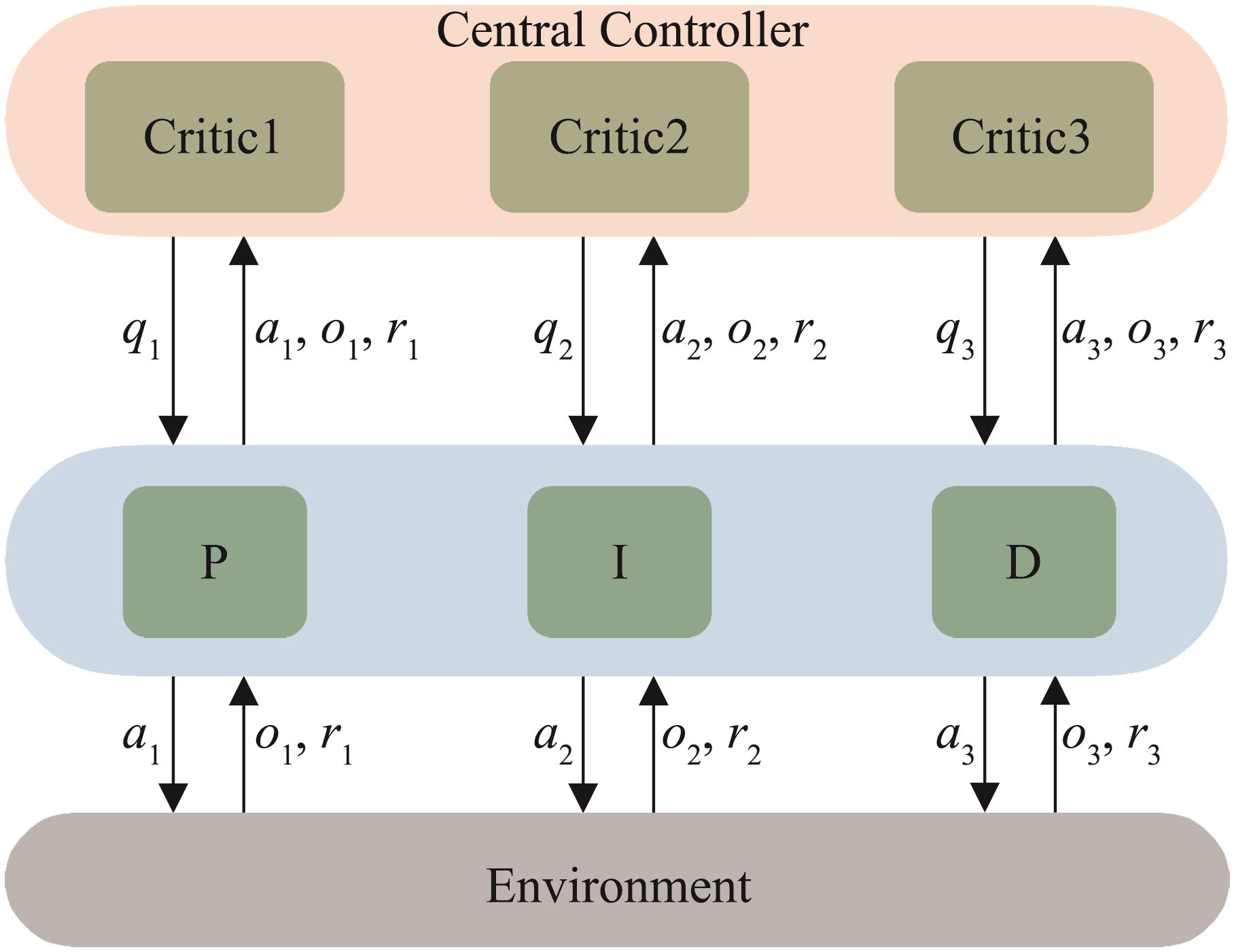
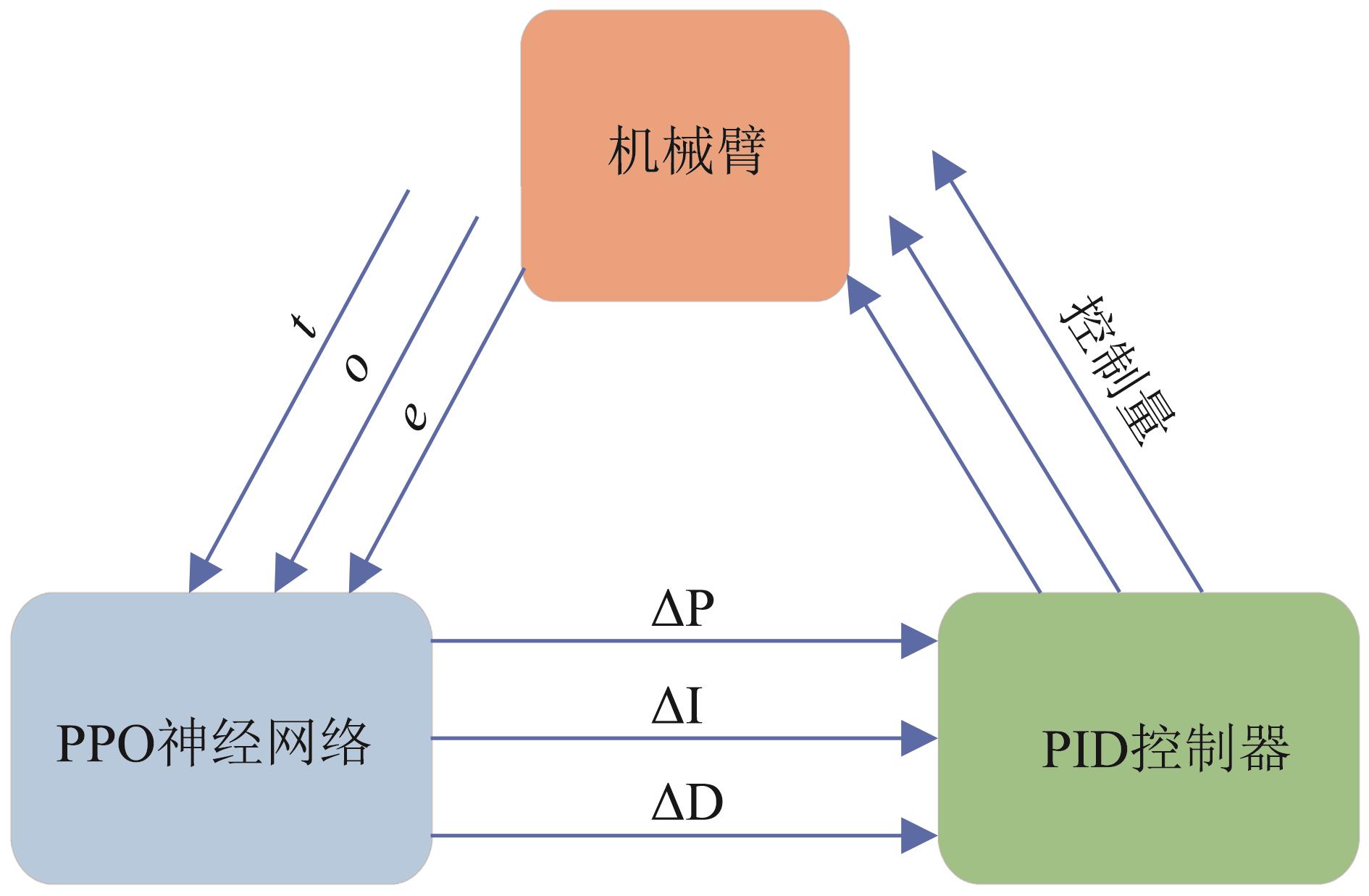
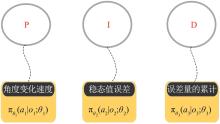
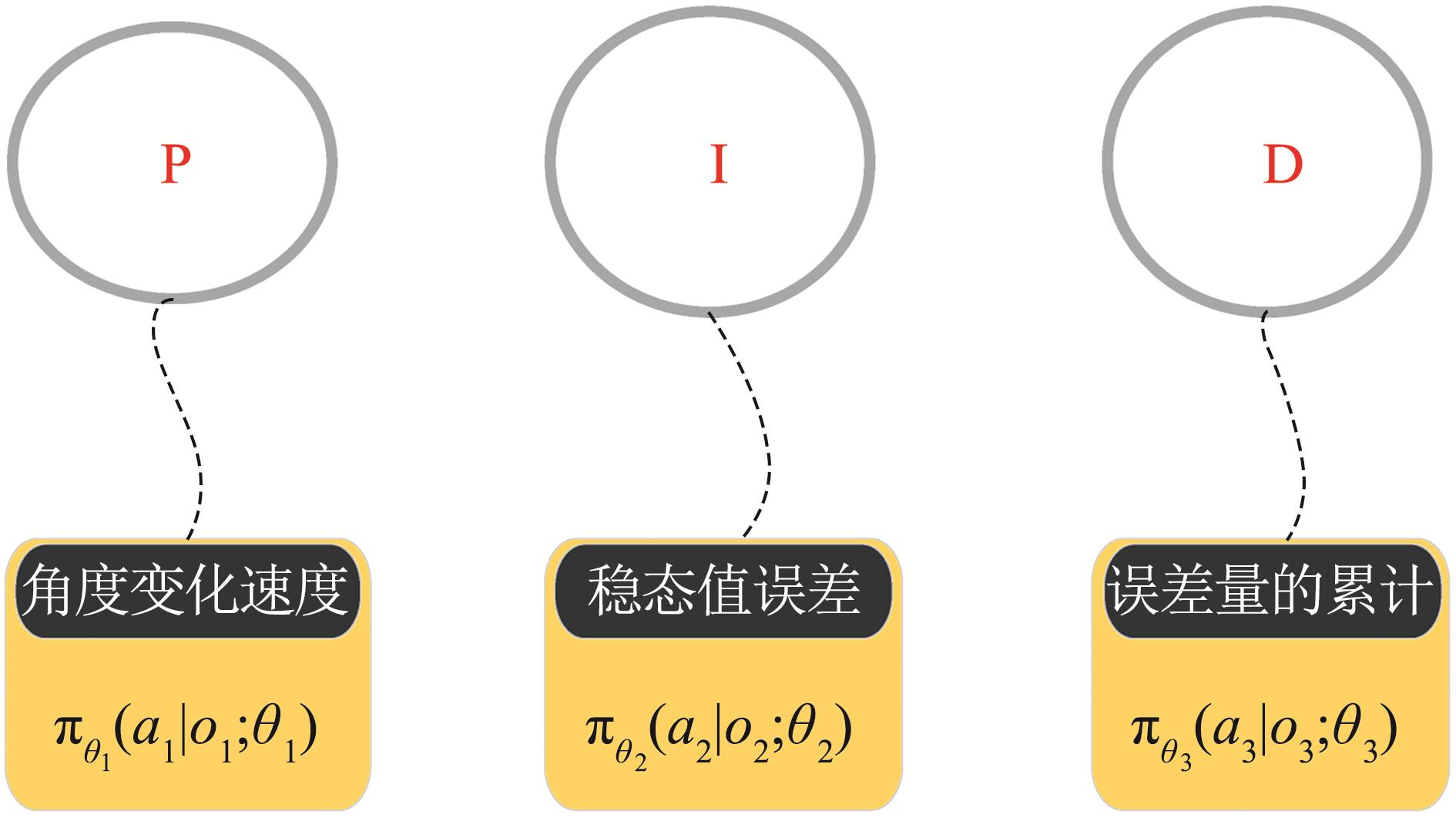
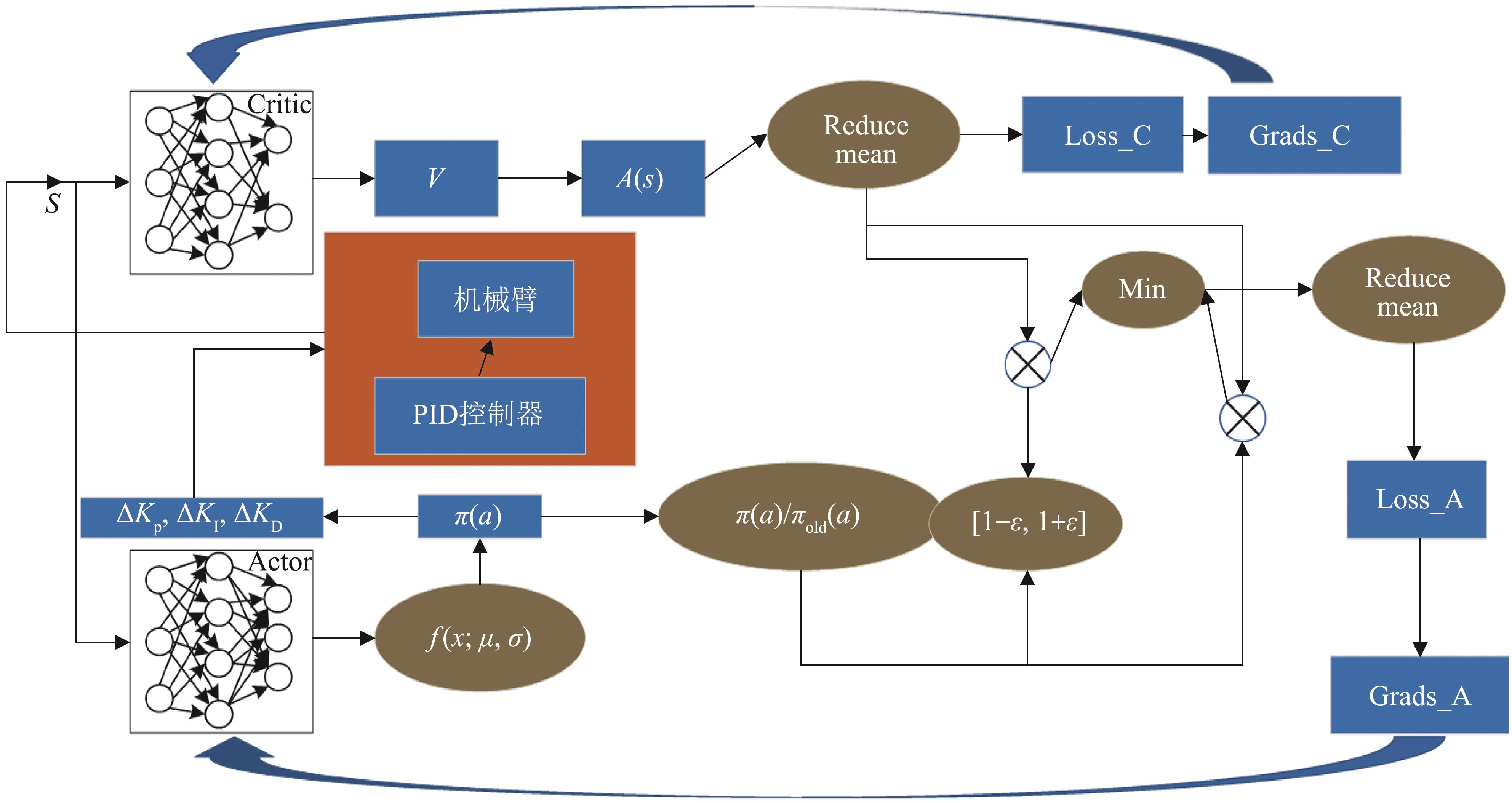
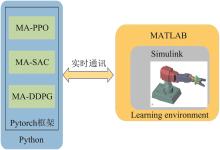
| 1 |
杜宝林, 朱大昌, 盘意华. 机械臂模糊超螺旋二阶滑模轨迹跟踪控制[J]. 系统仿真学报, 2022, 34(6): 1343-1352.
|
|
Du Baolin, Zhu Dachang, Pan Yihua. Fuzzy Super-twisting Second Order Sliding Mode Trajectory Tracking Control for Robotic Manipulator[J]. Journal of System Simulation, 2022, 34(6): 1343-1352.
|
| 2 |
张瑞民, 陈巧玉. 基于光滑二阶滑模的机械臂轨迹跟踪控制[J]. 系统仿真学报, 2021, 33(6): 1315-1322.
|
|
Zhang Ruimin, Chen Qiaoyu. Trajectory Tracking Control of Robotic Manipulators Based on Smooth Second-order Sliding Mode[J]. Journal of System Simulation, 2021, 33(6): 1315-1322.
|
| 3 |
Wu Jingda, He Hongwen, Peng Jiankun, et al. Continuous Reinforcement Learning of Energy Management with Deep Q Network for a Power Split Hybrid Electric Bus[J]. Applied Energy, 2018, 222: 799-811.
|
| 4 |
Schulman J, Levine S, Moritz P, et al. Trust Region Policy Optimization[C]//Proceedings of the 32nd International Conference on International Conference on Machine Learning. Chia Laguna Resort, Sardinia, Italy: PMLR, 2015: 1889-1897.
|
| 5 |
Zhang Yao, Deng Zhongliang, Gao Yuhui. Angle of Arrival Passive Location Algorithm Based on Proximal Policy Optimization[J]. Electronics, 2019, 8(12): 1558.
|
| 6 |
Haarnoja T, Zhou A, Abbeel P, et al. Soft Actor-critic: Off-policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor[C]//Proceedings of the 35th International Conference on Machine Learning. Chia Laguna Resort, Sardinia, Italy: PMLR, 2018: 3008-3018.
|
| 7 |
Morales E F, Zaragoza J H. An Introduction to Reinforcement Learning[M]. IEEE, 2011, 11(4): 219-354.
|
| 8 |
Nguyen Cong Luong, Dinh Thai Hoang, Gong Shimin, et al. Applications of Deep Reinforcement Learning in Communications and Networking: A Survey[J]. IEEE Communications Surveys & Tutorials, 2019, 21(4): 3133-3174.
|
| 9 |
李鹤宇, 赵志龙, 顾蕾, 等. 基于深度强化学习的机械臂控制方法[J]. 系统仿真学报, 2019, 31(11): 2452-2457.
|
|
Li Heyu, Zhao Zhilong, Gu Lei, et al. Robot Arm Control Method Based on Deep Reinforcement Learning[J]. Journal of System Simulation, 2019, 31(11): 2452-2457.
|
| 10 |
江达, 蔡志勤, 刘忠振, 等. 基于强化学习的连续型机械臂自适应跟踪控制[J]. 系统仿真学报, 2022, 34(10): 2264-2271.
|
|
Jiang Da, Cai Zhiqin, Liu Zhongzhen, et al. Reinforcement-learning-based Adaptive Tracking Control for a Space Continuum Robot Based on Reinforcement Learning[J]. Journal of System Simulation, 2022, 34(10): 2264-2271.
|
| 11 |
Elsisi Mahmoud, Mahmoud Karar, Lehtonen Matti, et al. An Improved Neural Network Algorithm to Efficiently Track Various Trajectories of Robot Manipulator Arms[J]. IEEE Access, 2021, 9: 11911-11920.
|
| 12 |
Tran Duc-Thien, Truong Hoai-Vu-Anh, Kyoung Kwan Ahn. Adaptive Nonsingular Fast Terminal Sliding Mode Control of Robotic Manipulator Based Neural Network Approach[J]. International Journal of Precision Engineering and Manufacturing, 2021, 22(3): 417-429.
|
| 13 |
Yang Shichun, Xie Hehui, Chen Fei, et al. Research on Manipulator Trajectory Tracking Based on Adaptive Fuzzy Sliding Mode Control[C]//2020 Chinese Automation Congress (CAC). Piscataway, NJ, USA: IEEE, 2020: 3086-3091.
|
| 14 |
Ahmed Saim, Wang Haoping, Tian Yang. Adaptive High-order Terminal Sliding Mode Control Based on Time Delay Estimation for the Robotic Manipulators with Backlash Hysteresis[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2021, 51(2): 1128-1137.
|
| 15 |
Ma Yajun, Zhao Hui, Li Tao. Robust Adaptive Dual Layer Sliding Mode Controller: Methodology and Application of Uncertain Robot Manipulator[J]. Transactions of the Institute of Measurement and Control, 2022, 44(4): 848-860.
|
| 16 |
Mohammadi F, Mohammadi-Ivatloo B, Gharehpetian G B, et al. Robust Control Strategies for Microgrids: A Review[J]. IEEE Systems Journal, 2022, 16(2): 2401-2412.
|
| 17 |
Konar Amit, Indrani Goswami Chakraborty, Sapam Jitu Singh, et al. A Deterministic Improved Q-learning for Path Planning of a Mobile Robot[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2013, 43(5): 1141-1153.
|
| 18 |
Zhou Changjiu, Meng Qingchun. Dynamic Balance of a Biped Robot Using Fuzzy Reinforcement Learning Agents[J]. Fuzzy Sets and Systems, 2003, 134(1): 169-187.
|
| 19 |
Wu Hui, Song Shiji, You Keyou, et al. Depth Control of Model-free AUVs via Reinforcement Learning[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2019, 49(12): 2499-2510.
|
| 20 |
魏楠哲. 空间机械臂柔性关节高精度控制研究[D]. 北京: 北京邮电大学, 2016.
|
|
Wei Nanzhe. Study on Flexible Joint Control System with High Precision for Space Manipulator[D]. Beijing: Beijing University of Posts and Telecommunications, 2016.
|
| 21 |
Schulman J, Wolski F, Dhariwal P, et al. Proximal Policy Optimization Algorithms[EB/OL]. (2017-08-28) [2023-01-12]. .
|
 ), 莫非1, 赵凯2, 郝云波2, 钱宇峰1
), 莫非1, 赵凯2, 郝云波2, 钱宇峰1