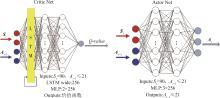
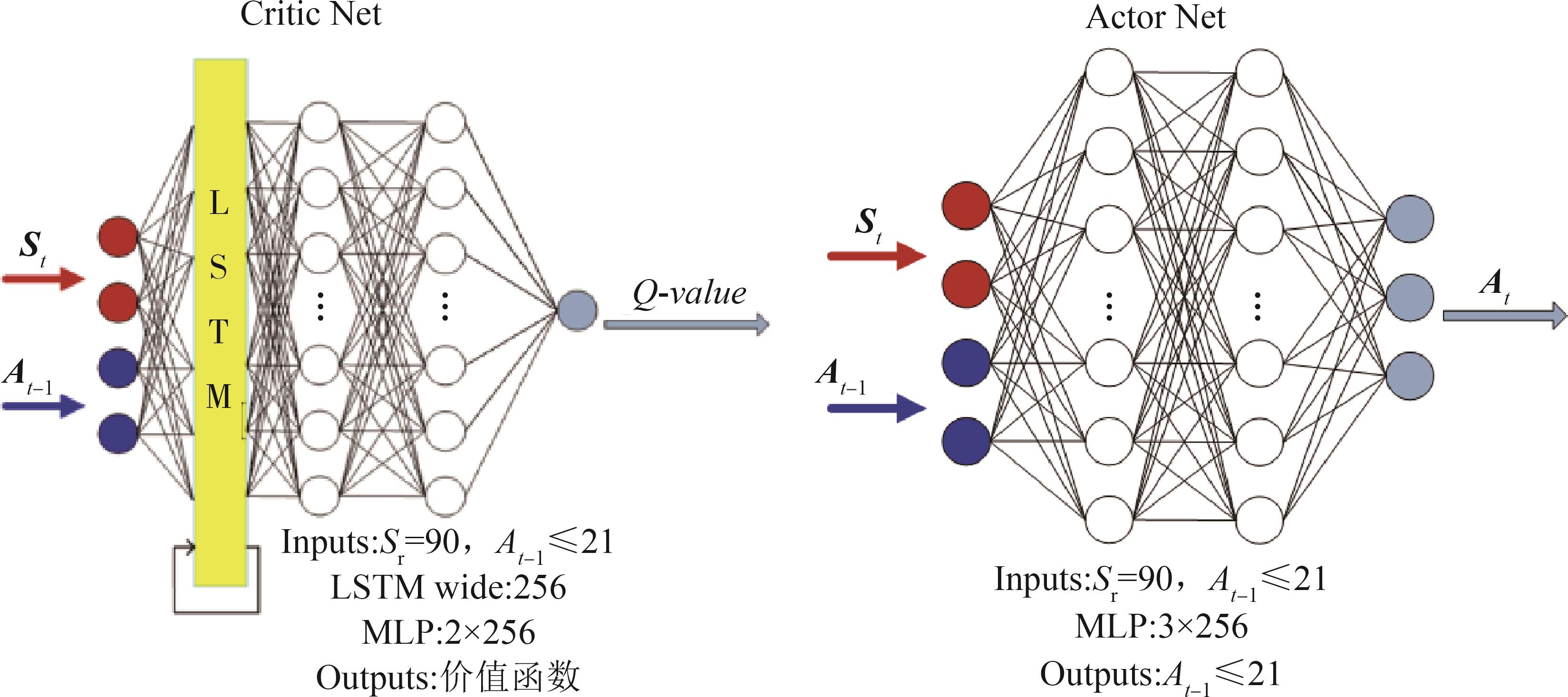
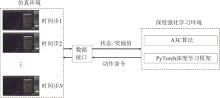
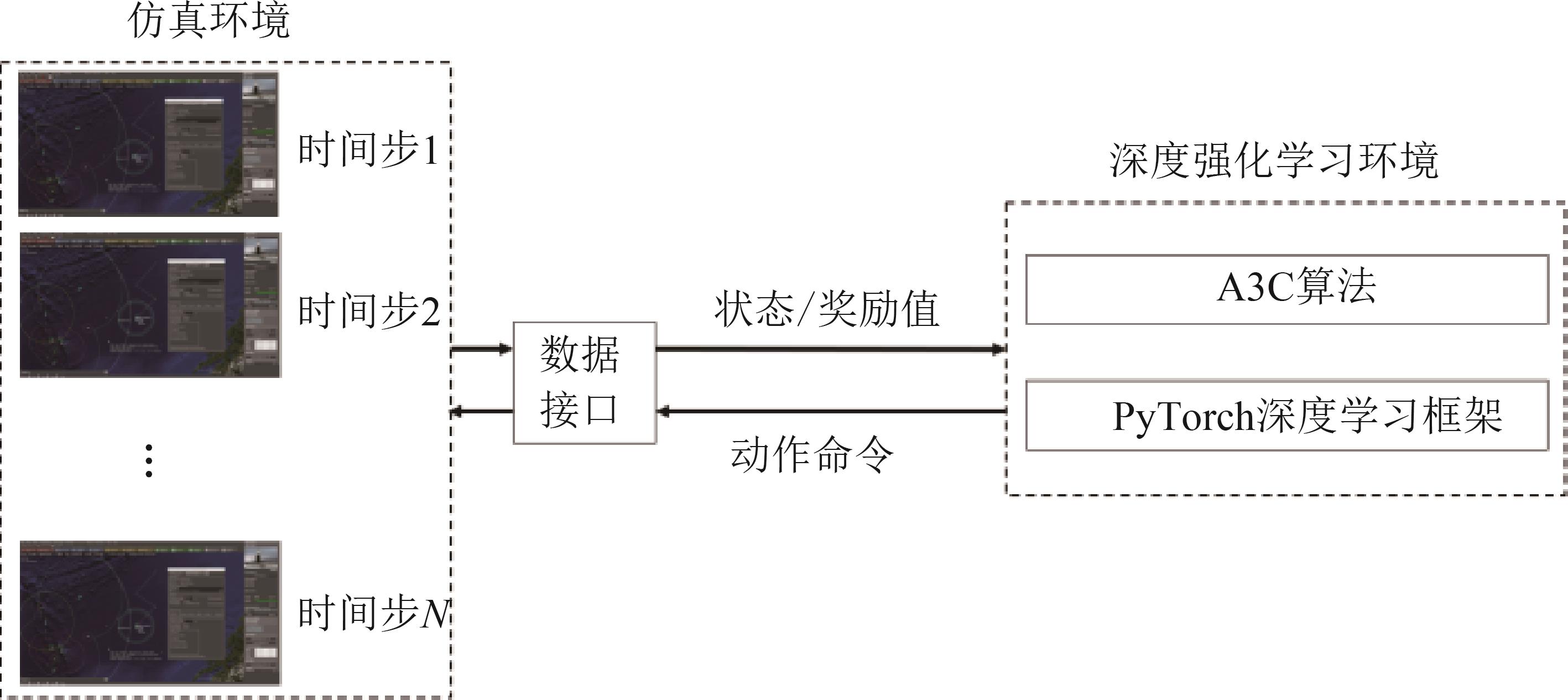
| 1 |
杨峰, 李群, 王维平, 等. 基于仿真的探索性评估方法论[J]. 系统仿真学报, 2003(11): 1561-1564.
|
|
Yang Feng, Li Qun, Wang Weiping, et al. Simulation Based Exploratory Evaluation Methodology[J]. Journal of System Simulation, 2003(11): 1561-1564.
|
| 2 |
杨镜宇, 司光亚, 胡晓峰. 信息化战争体系对抗探索性仿真分析方法研究[J]. 系统仿真学报, 2005(6): 1469-1472, 1496.
|
|
Yang Jingyu, Si Guangya, Hu Xiaofeng. Study on Simulation-based Exploratory Analysis Method of Information Warfare System of System (SoS) Encounter[J]. Journal of System Simulation, 2005(6): 1469-1472, 1496.
|
| 3 |
Payne D. Commond Decision Model Technologey Assess-ment: ADAY34926, 19-5[R]. [S.l.]: [s.n.]: 16-27.
|
| 4 |
李斌, 刘苏洋, 李春洪, 等. 探索性仿真实验仿真想定空间筛选[J]. 火力与指挥控制, 2013, 38(5): 152-156.
|
|
Li Bin, Liu Suyang, Li Chunhong, et al. Screening the Simulation Scenario Space in Exploratory Simulation Experiment [J]. Fire Control & Command Control, 2013, 38(5): 152-156.
|
| 5 |
喻飞飞, 赵志敏, 包俊. 探索性仿真分析框架下的实验点设计方法[J]. 指挥控制与仿真, 2014, 36(2): 80-84.
|
|
Yu Feifei, Zhao Zhimin, Bao Jun. Experiment Points Design Methods Under the Framework of Exploratory Simulation Analysis[J]. Command Control & Simulation, 2014, 36(2): 80-84.
|
| 6 |
姚桐, 王越, 董岩, 等. 深度强化学习在作战任务规划中的应用[J]. 飞航导弹, 2020(4): 16-21.
|
| 7 |
吴昭欣, 李辉, 王壮, 等. 基于深度强化学习的智能仿真平台设计[J]. 战术导弹技术, 2020(4): 193-200.
|
|
Wu Zhaoxin, Li Hui, Wang Zhuang, et al. The Design of Intelligence Simulation Platform Based on DRL[J]. Tactical Missile Technology, 2020(4): 193-200.
|
| 8 |
于博文, 吕明, 张捷. 基于分层强化学习的联合作战仿真作战决策算法[J]. 火力与指挥控制, 2021, 46(10): 140-146.
|
|
Yu Bowen, Ming Lü, Zhang Jie. Joint Operation Simulation Decision-making Algorithm Based on Hierarchical Reinforcement Learning[J]. Fire Control & Command Control, 2021, 46(10): 140-146.
|
| 9 |
石鼎, 燕雪峰, 宫丽娜, 等. 强化学习驱动的海战场多智能体协同作战仿真算法[J]. 系统仿真学报, 2023, 35(4): 786-796.
|
|
Shi Ding, Yan Xuefeng, Gong Lina, et al. Multi-agent Cooperative Combat Simulation in Naval Battlefield with Reinforcement Learning[J]. Journal of System Simulation, 2023, 35(4): 786-796.
|
| 10 |
Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous Control with Deep Reinforcement Learning[J]. (2019-07-05) [2022-06-26]. .
|
| 11 |
Schulman J, Wolski F, Dhariwal P, et al. Proximal Policy Optimization Algorithms[EB/OL]. (2017-08-28) [2022-06-26]. .
|
| 12 |
Mnih V, Adrià Puigdomènech Badia, Mirza M, et al. Asynchronous Methods for Deep Reinforcement Learning[C]//Proceedings of the 33rd International Conference on International Conference on Machine Learning. Cambridge: JMLR, 2016: 1928-1937.
|
| 13 |
曹雷. 基于深度强化学习的智能博弈对抗关键技术[J]. 指挥信息系统与技术, 2019, 10(5): 1-7.
|
|
Cao Lei. Key Technologies of Intelligent Game Confrontation Based on Deep Reinforcement Learning[J]. Command Information System and Technology, 2019, 10(5): 1-7.
|
| 14 |
孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题[J]. 自动化学报, 2020, 46(7): 1301-1312.
|
|
Sun Changyin, Mu Chaoxu. Important Scientific Problems of Multi-agent Deep Reinforcement Learning[J]. Acta Automatica Sinica, 2020, 46(7): 1301-1312.
|
| 15 |
孙彧, 李清伟, 徐志雄, 等. 基于多智能体深度强化学习的空战博弈对抗策略训练模型[J]. 指挥信息系统与技术, 2021, 12(2): 16-20.
|
|
Sun Yu, Li Qingwei, Xu Zhixiong, et al. Game Confrontation Strategy Training Model for Air Combat Based on Multi-agent Deep Reinforcement Learning[J]. Command Information System and Technology, 2021, 12(2): 16-20.
|
 ), 司光亚3(
), 司光亚3(