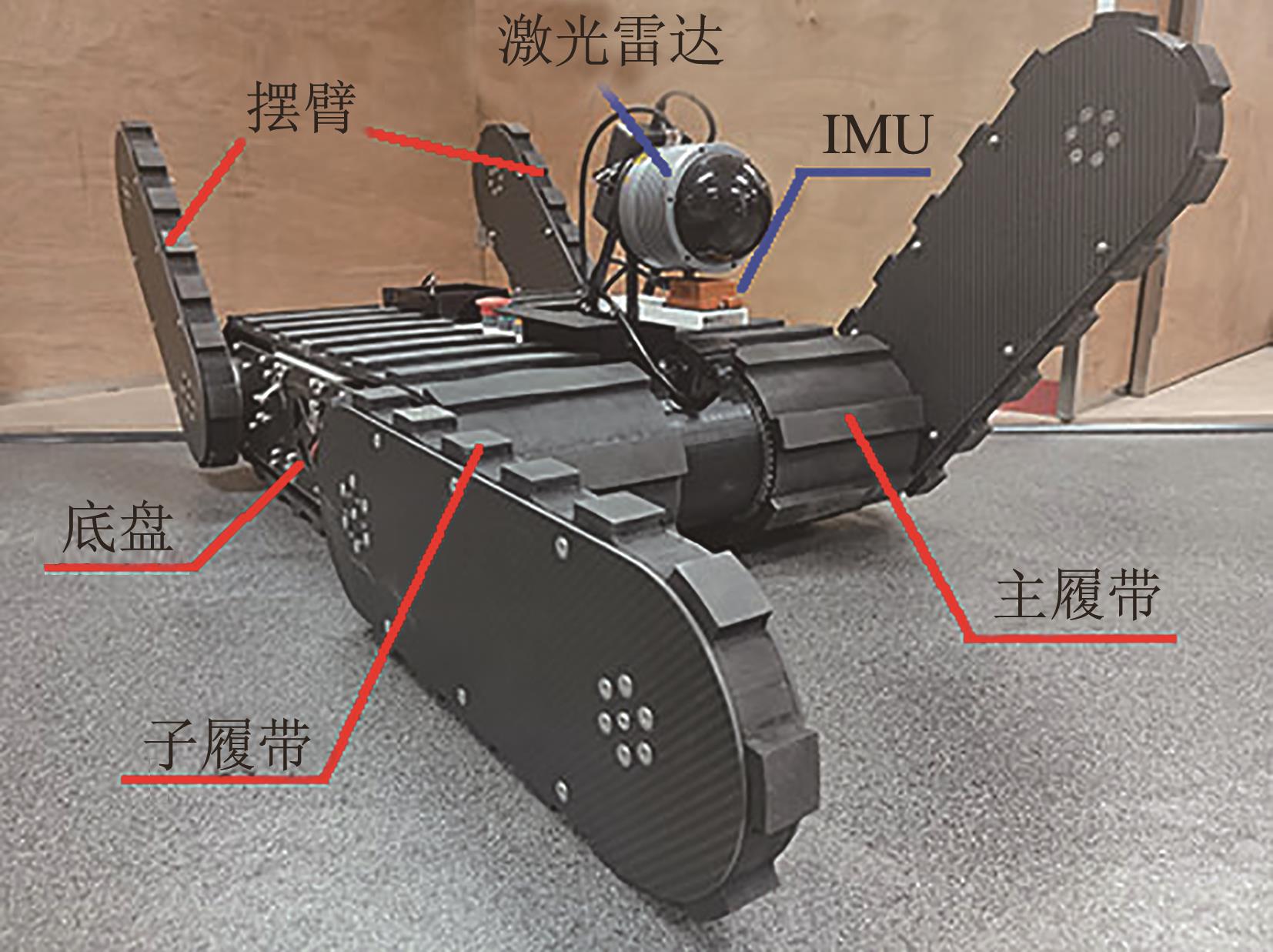
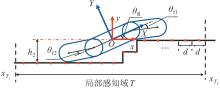
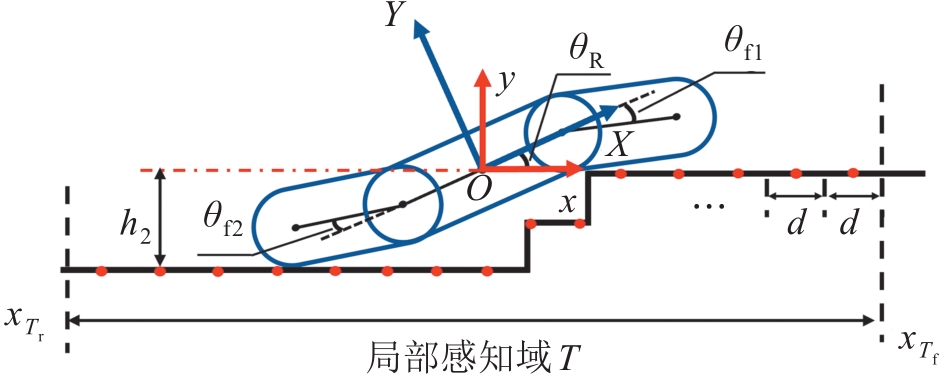
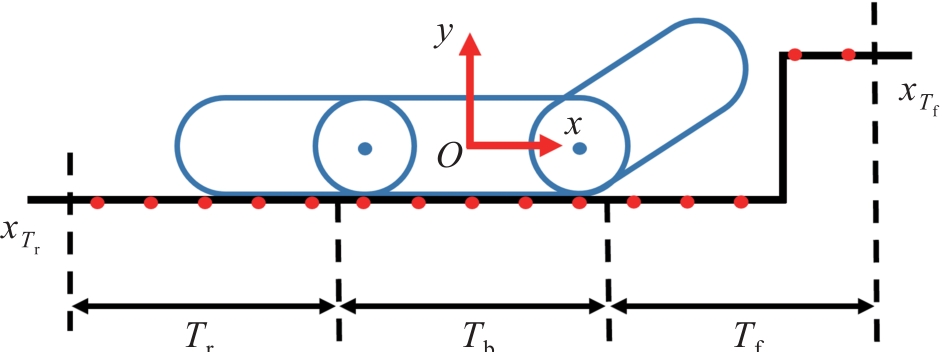
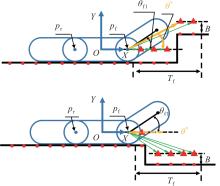
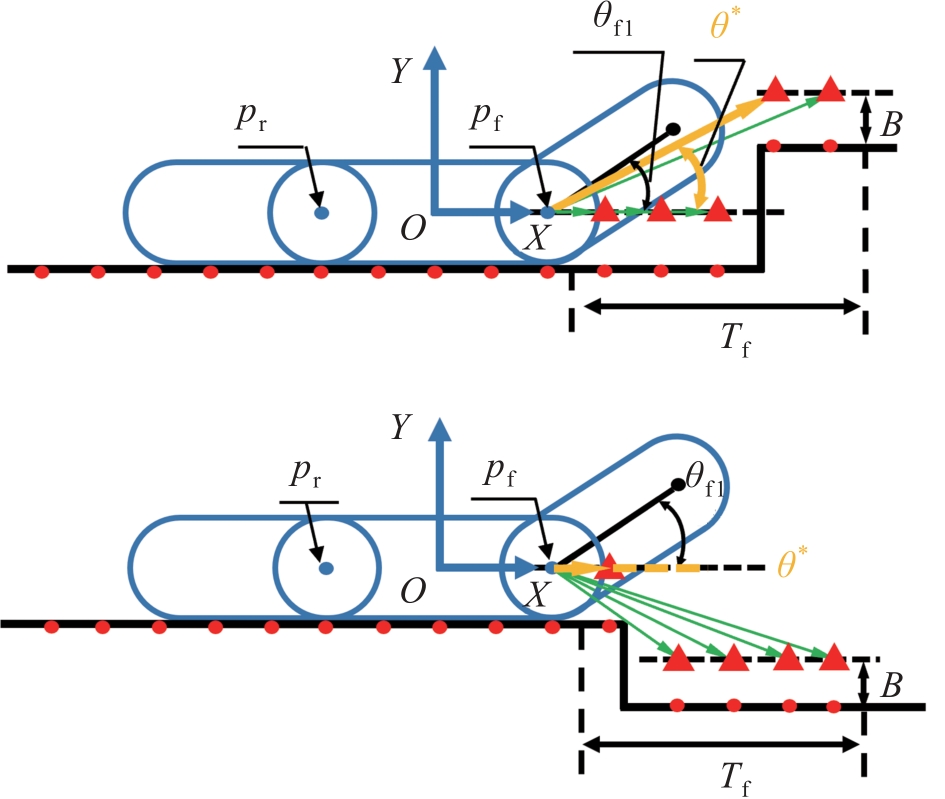
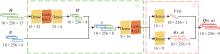
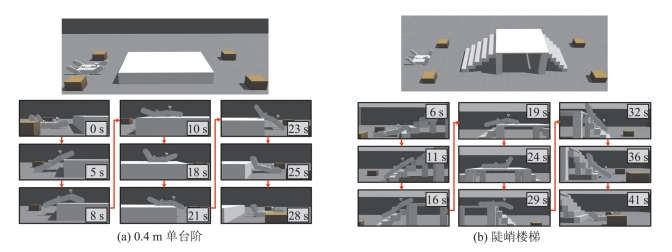
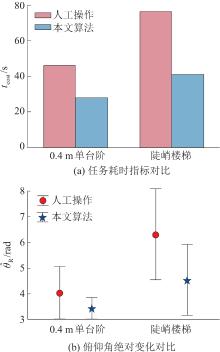
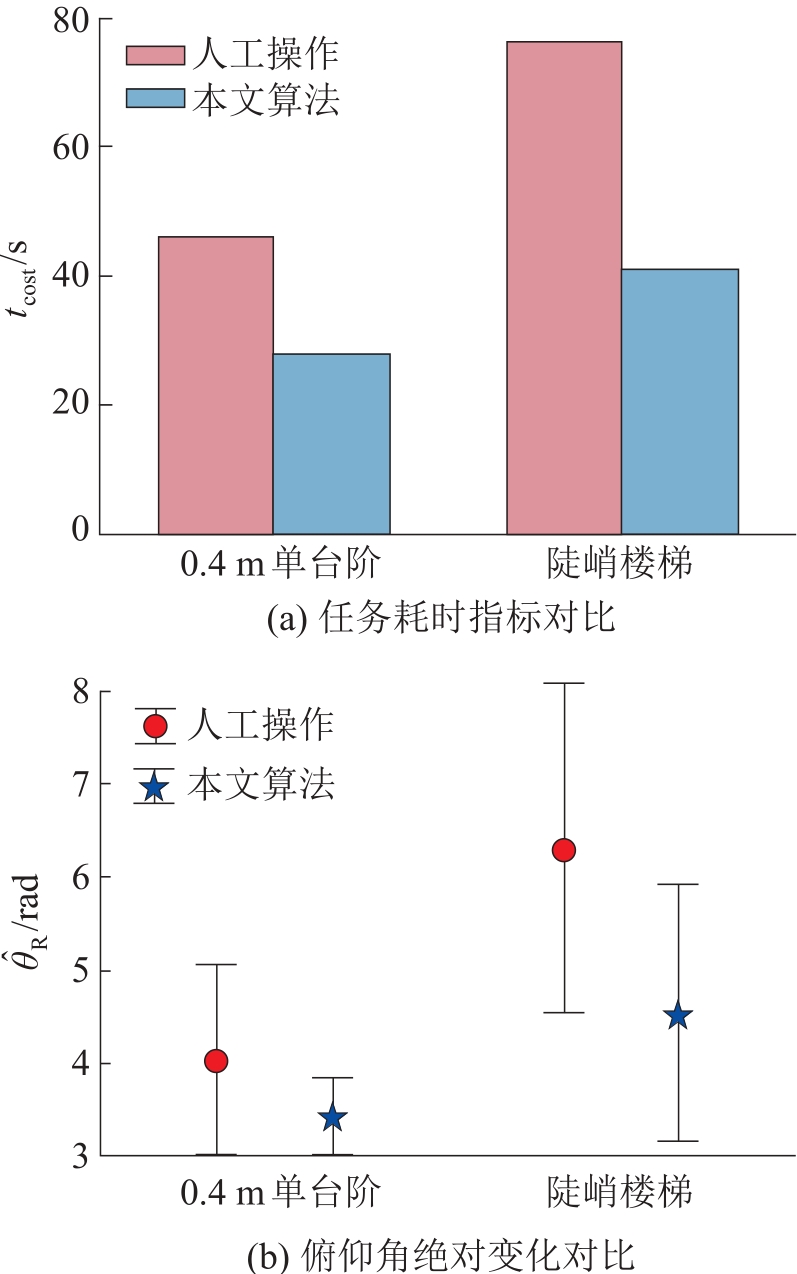
| 1 |
Liu Jinguo, Wang Yuechao, Li Bin, et al. Current Research, Key Performances and Future Development of Search and Rescue Robots[J]. Frontiers of Mechanical Engineering in China, 2007, 2(4): 404-416.
|
| 2 |
Kruijff G J M, Pirri F, Gianni M, et al. Rescue Robots at Earthquake-hit Mirandola, Italy: A Field Report[C]//2012 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR). Piscataway, NJ, USA: IEEE, 2012: 1-8.
|
| 3 |
Kruijff G J M, Janíček M, Keshavdas S, et al. Experience in System Design for Human-robot Teaming in Urban Search and Rescue[M]//Yoshida K, Tadokoro S. Field and Service Robotics: Results of the 8th International Conference. Berlin, Heidelberg: Springer Berlin Heidelberg, 2014: 111-125.
|
| 4 |
商德勇. 薄煤层综采工作面巡检机器人运动分析及试验研究[D]. 北京: 中国矿业大学(北京), 2016.
|
|
Shang Deyong. Study on Motion Analysis and Experiment of the Inspection Robot for Fully-mechanized Workface in Thin Coal Seam[D]. Beijing: China University of Mining & Technology(Beijing), 2016.
|
| 5 |
Ohno K, Morimura S, Tadokoro S, et al. Semi-autonomous Control System of Rescue Crawler Robot Having Flippers for Getting Over Unknown-steps[C]//2007 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, NJ, USA: IEEE, 2007: 3012-3018.
|
| 6 |
Nagatani K, Yamasaki A, Yoshida K, et al. Semi-autonomous Traversal on Uneven Terrain for a Tracked Vehicle Using Autonomous Control of Active Flippers[C]//2008 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, NJ, USA: IEEE, 2008: 2667-2672.
|
| 7 |
Okada Y, Nagatani K, Yoshida K, et al. Shared Autonomy System for Tracked Vehicles on Rough Terrain Based on Continuous Three-dimensional Terrain Scanning[J]. Journal of Field Robotics, 2011, 28(6): 875-893.
|
| 8 |
Kober J, Bagnell J A, Peters J, et al. Reinforcement Learning in Robotics: A Survey[J]. The International Journal of Robotics Research, 2013, 32(11): 1238-1274.
|
| 9 |
Zimmermann K, Zuzanek P, Reinstein M, et al. Adaptive Traversability of Unknown Complex Terrain with Obstacles for Mobile Robots[C]//2014 IEEE International Conference on Robotics and Automation (ICRA). Piscataway, NJ, USA: IEEE, 2014: 5177-5182.
|
| 10 |
Paolo G, Tai Lei, Liu Ming. Towards Continuous Control of Flippers for a Multi-terrain Robot Using Deep Reinforcement Learning[J]. (2017-09-25) [2022-09-19]. .
|
| 11 |
Mitriakov A, Papadakis P, Mai Nguyen S, et al. Staircase Traversal via Reinforcement Learning for Active Reconfiguration of Assistive Robots[C]//2020 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE). Piscataway, NJ, USA: IEEE, 2020: 1-8.
|
| 12 |
Mitriakov A, Papadakis P, Mai Nguyen S, et al. Staircase Negotiation Learning for Articulated Tracked Robots with Varying Degrees of Freedom[C]//2020 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR). Piscataway, NJ, USA: IEEE, 2020: 394-400.
|
| 13 |
李允旺, 葛世荣, 朱华, 等. 四履带双摆臂机器人越障机理及越障能力[J]. 机器人, 2010, 32(2): 157-165.
|
|
Li Yunwang, Ge Shirong, Zhu Hua, et al. Obstacle-surmounting Mechanism and Capability of Four-track Robot with Two Swing Arms[J]. Robot, 2010, 32(2): 157-165.
|
| 14 |
Suzuki S, Hasegawa S, Okugawa M. Remote Control System of Disaster Response Robot with Passive Sub-crawlers Considering Falling Down Avoidance[J]. ROBOMECH Journal, 2014, 1(1): 20.
|
| 15 |
Silver D, Singh S, Precup D, et al. Reward Is Enough[J]. Artificial Intelligence, 2021, 299: 103535.
|
| 16 |
Hasselt H. Double Q-learning[C]//Advances in Neural Information Processing Systems. San Francisco, CA, USA: Curran Associates Inc., 2010: 2613-2621.
|
| 17 |
Wang Ziyu, Schaul T, Hessel M, et al. Dueling Network Architectures for Deep Reinforcement Learning[C]//Proceedings of the 33rd International Conference on International Conference on Machine Learning. Cambridge: JMLR, 2016: 1995-2003.
|
| 18 |
Pecka M, Zimmermann K, Svoboda Tomáš. Fast Simulation of Vehicles with Non-deformable Tracks[C]//2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway, NJ, USA: IEEE, 2017: 6414-6419.
|
| 19 |
Zhang Ji, Singh S. LOAM: Lidar Odometry and Mapping in Real-time[C]//Robotics: Science and Systems Conference(RSS). [S.l.]: [s.n.], 2014, 10(7): 1-9.
|
| 20 |
Pecka M, Šalanský Vojtěch, Zimmermann K, et al. Autonomous Flipper Control with Safety Constraints[C]//2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway, NJ, USA: IEEE, 2016: 2889-2894.
|
 ), 陈柏良, 黄开宏(
), 陈柏良, 黄开宏(