

Journal of System Simulation ›› 2026, Vol. 38 ›› Issue (2): 447-459.doi: 10.16182/j.issn1004731x.joss.25-0472
• Wargaming and Simulation-Based Evaluation • Previous Articles Next Articles
Ding Zhengkun, Liu Jiaqi, Xu Junzheng, Xu Yuezhu, Wang Xingmei
Received:2025-05-26
Revised:2025-10-25
Online:2026-02-18
Published:2026-02-11
Contact:
Xu Yuezhu
CLC Number:
Ding Zhengkun, Liu Jiaqi, Xu Junzheng, Xu Yuezhu, Wang Xingmei. Intelligent Air Combat Decision-making Method Based on BiGRU and Priority Dynamic Sampling[J]. Journal of System Simulation, 2026, 38(2): 447-459.
Table 1
Correspondence of UAV's basic actions and control values
| 动作序号 | 基本动作 | 控制值 | ||
|---|---|---|---|---|
| 匀速直行 | 0 | 1 | 0 | |
| 加速直行 | 2 | 1 | 0 | |
| 减速直行 | 1 | 0 | 0 | |
| 匀速左转 | 0 | 8 | -arccos(1/8) | |
| 加速左转 | 2 | 8 | -arccos(1/8) | |
| 减速左转 | 1 | 8 | -arccos(1/8) | |
| 匀速右转 | 0 | 8 | arccos(1/8) | |
| 加速右转 | 2 | 8 | arccos(1/8) | |
| 减速右转 | 1 | 8 | arccos(1/8) | |
| 匀速上仰 | 0 | 8 | 0 | |
| 加速上仰 | 2 | 8 | 0 | |
| 减速上仰 | 1 | 8 | 0 | |
| 匀速俯冲 | 0 | 8 | ||
| 加速俯冲 | 2 | 8 | ||
| 减速俯冲 | 1 | 8 | ||
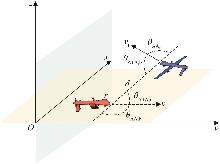
Fig. 1
Relative aerial position relationship of UAVs
Fig. 2
MAPPO-BiGRU-PS-LR algorithm architecture
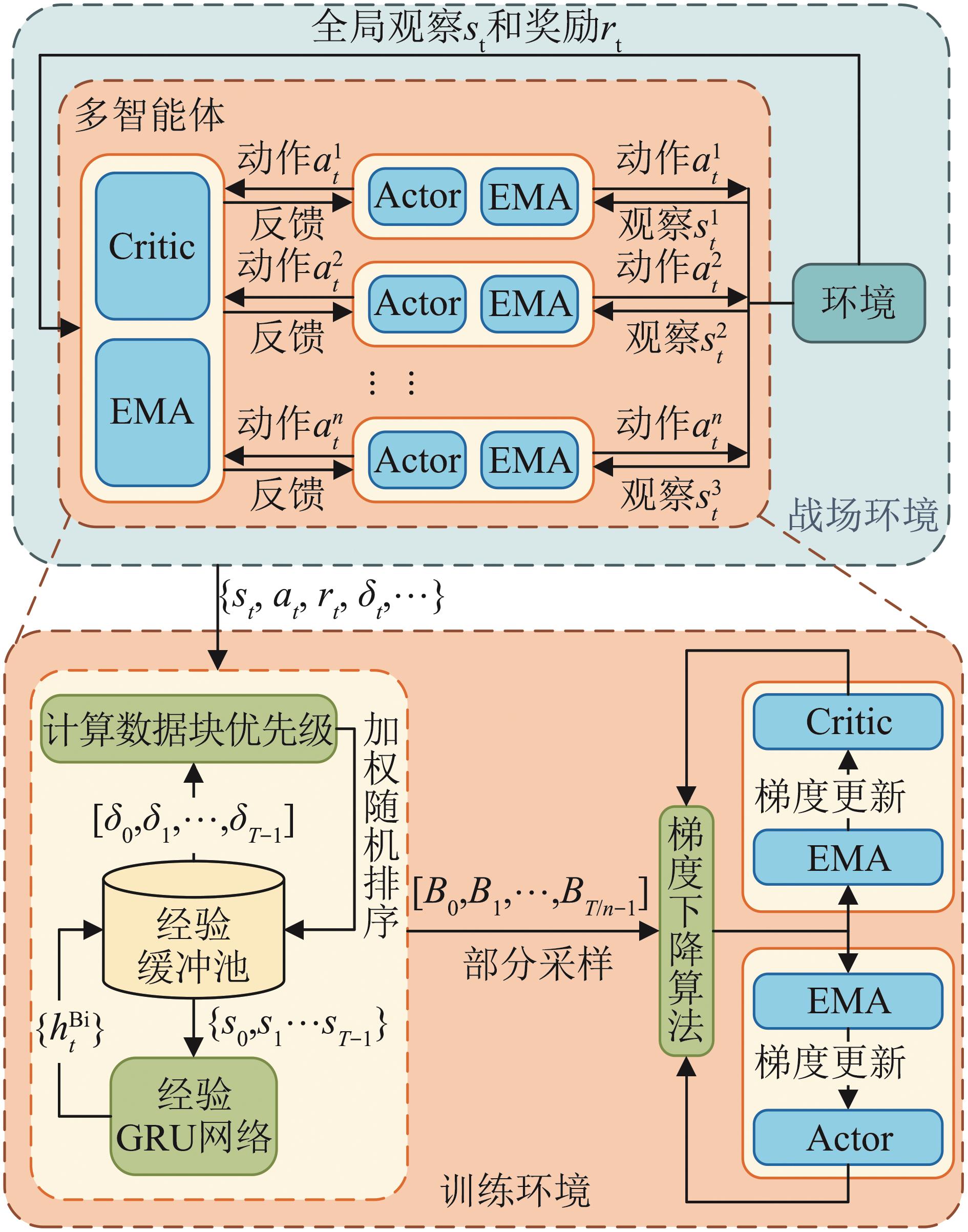
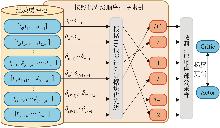
Fig. 3
Priority sampling process
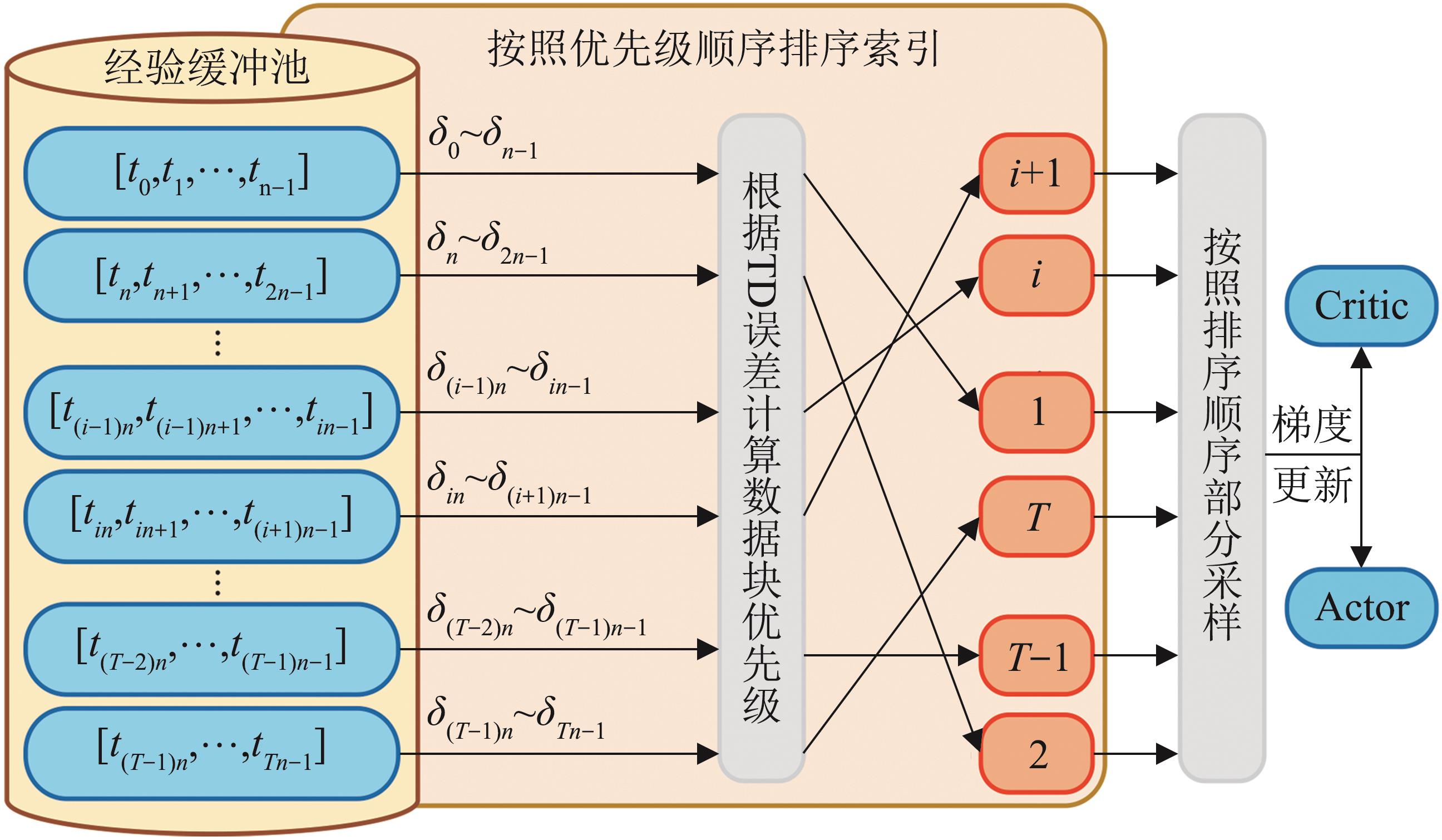
Table 2
Air combat simulation parameters
| 参数 | 取值 |
|---|---|
| 神经网络学习率l | 0.000 5 |
| 折扣因子 | 0.99 |
| 经验缓冲池最大容量 | 2 000 |
| 网络模型训练步数 | 20 000 |
| 回合时间步数 | 200 |
| 仿真时间步长/s | 0.2 |
| 最大攻击距离 | 2 000 |
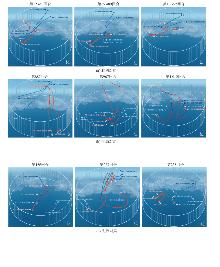
Fig. 4
UAV air combat decision-making trajectory based on MAPPO-BiGRU-PS-LR algorithm
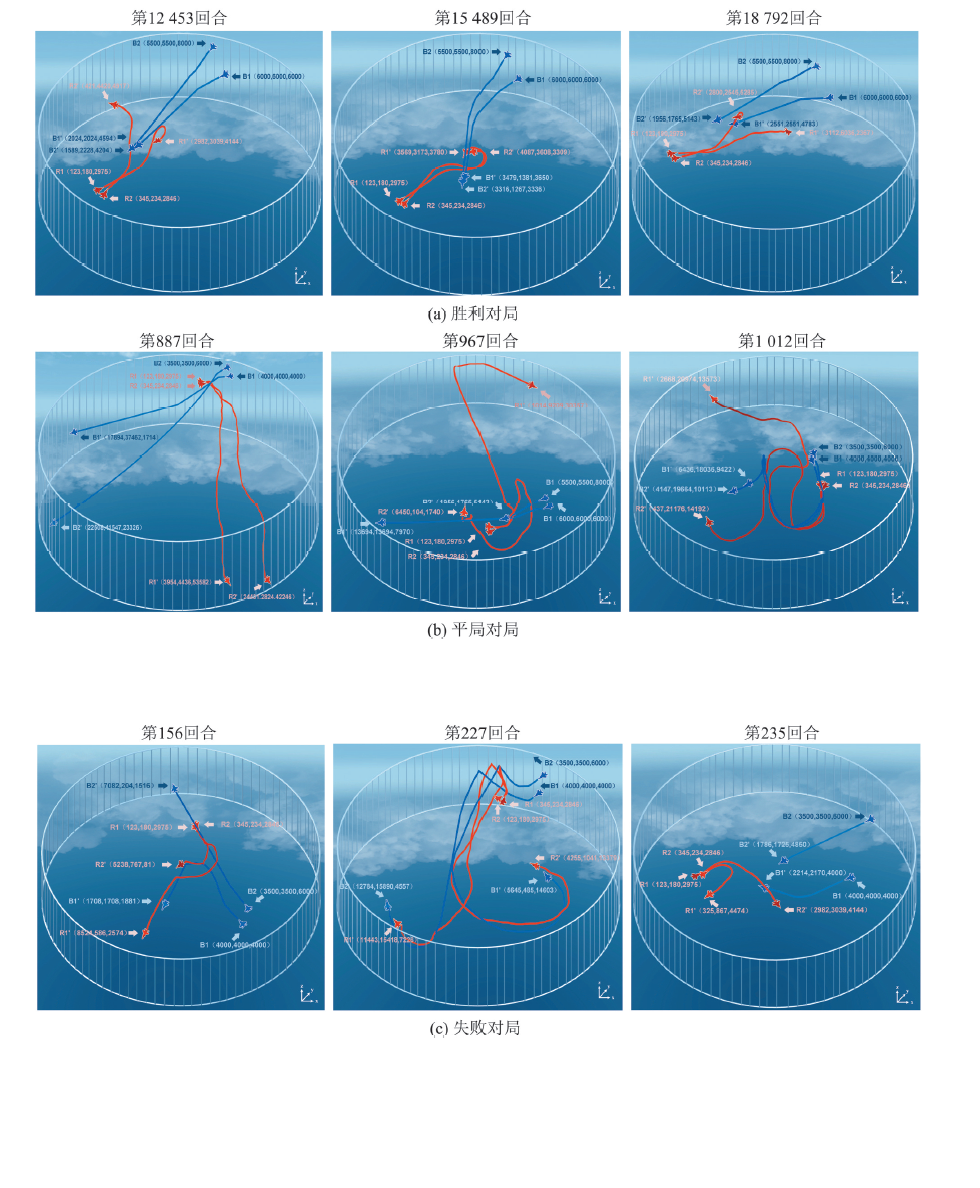
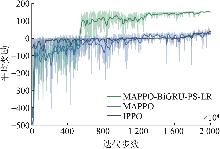
Fig. 5
Comparison of Average reward
Fig.6
Comparison of Average policy loss
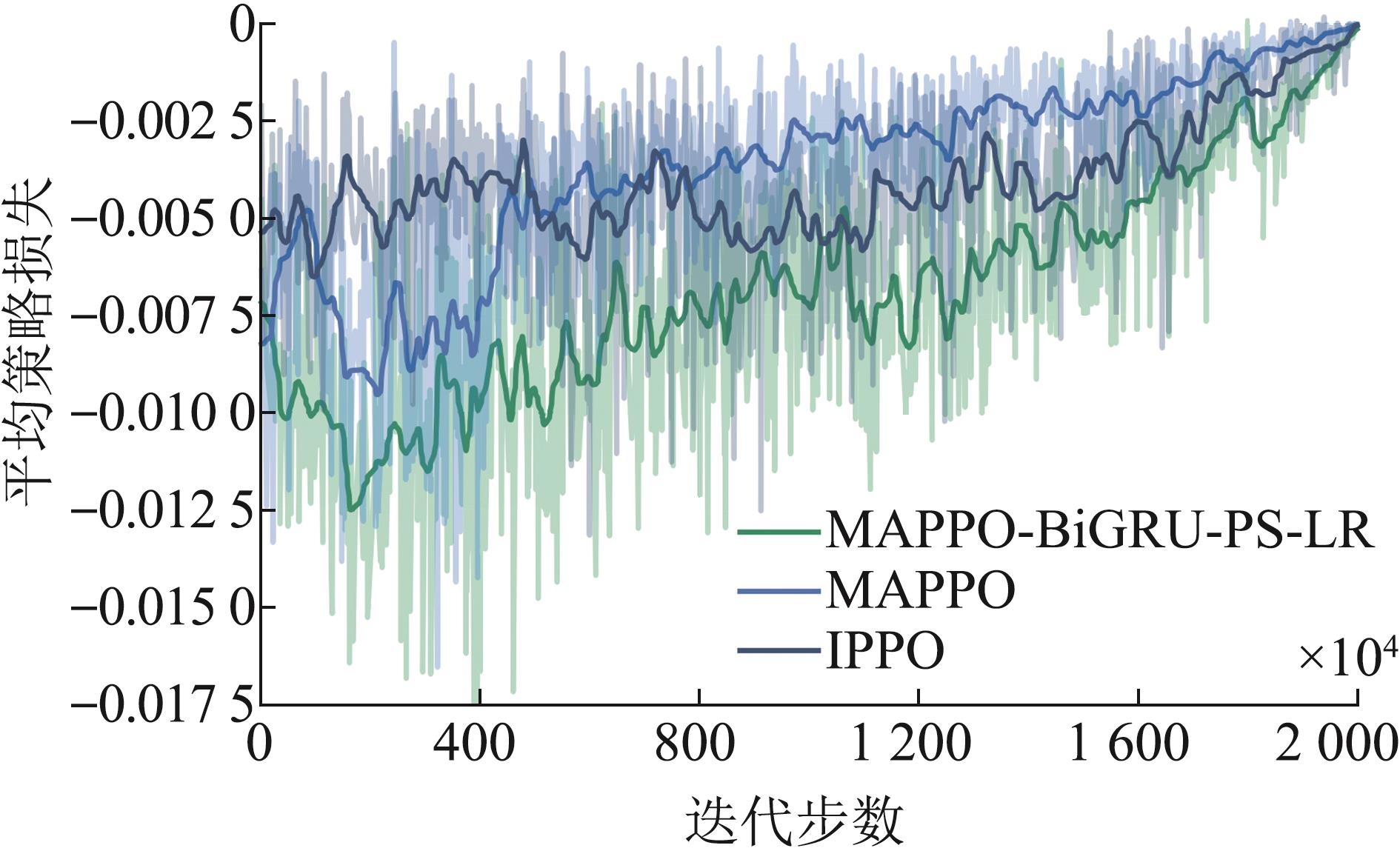
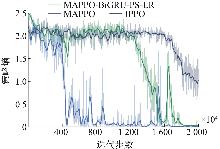
Fig.7
Comparison of Policy entropy
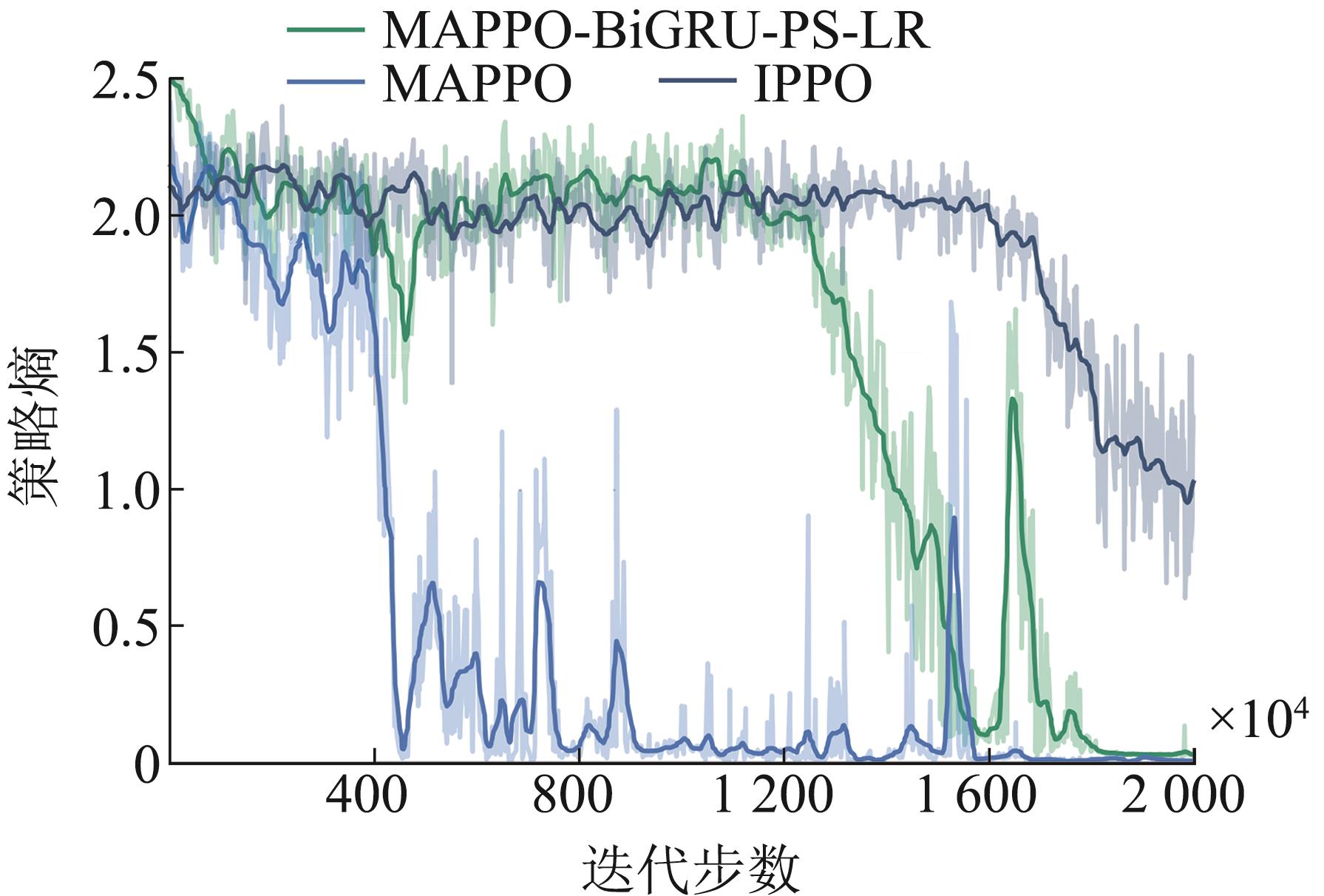
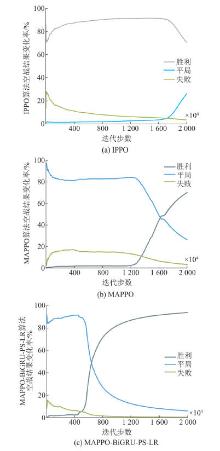
Fig.8
Variation of combat results
Table 3
Ablation experimental settings
| 算法名 | GRU 网络 | 学习率 调整 | 优先级 采样 |
|---|---|---|---|
| MAPPO | × | × | × |
| MAPPO-GRU | 单向 | × | × |
| MAPPO-BiGRU | 双向 | × | × |
| MAPPO-BiGRU-PS | 双向 | × | √ |
| MAPPO-BiGRU-LR | 双向 | √ | × |
| MAPPO-BiGRU-PS-LR | 双向 | √ | √ |
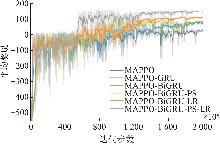
Fig. 9
Average reward changes in ablation experiments

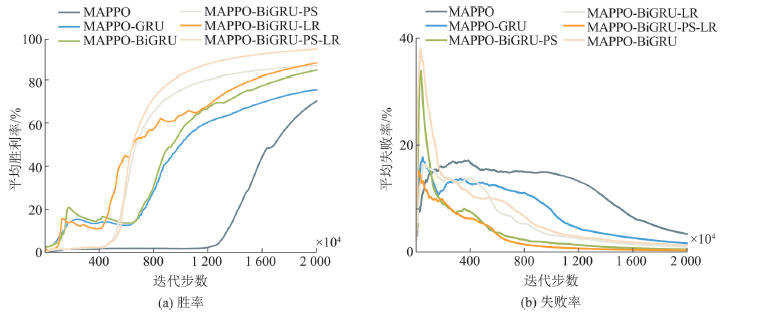
Fig. 10
Combat Result changes in ablation experiments
| [1] | Li Shouyi, Chen Mou, Wang Yuhui, et al. Air Combat Decision-making of Multiple UCAVs Based on Constraint Strategy Games[J]. Defence Technology, 2022, 18(3): 368-383. |
| [2] | 雍宇晨, 李子豫, 董琦. 基于分层多智能体强化学习的多无人机视距内空战[J]. 智能系统学报, 2025, 20(3): 548-556. |
| Yong Yuchen, Li Ziyu, Dong Qi. Multi-UAV Within-visual-range Air Combat Based on Hierarchical Multiagent Reinforcement Learning[J]. CAAI Transactions on Intelligent Systems, 2025, 20(3): 548-556. | |
| [3] | Wu Mingxi. Intelligent Warfare: Prospects of Military Development in the Age of AI[M]. London: Routledge, 2022. |
| [4] | Murat Perit Çakır, Gürakar Gökhan. Towards Intelligent Flight Simulator Training[J]. The Journal of the JAPCC, 2023, 36: 46-53. |
| [5] | Jordan Javier. The Future of Unmanned Combat Aerial Vehicles: an Analysis Using the Three Horizons Framework[J]. Futures, 2021, 134: 102848. |
| [6] | 梁晓龙, 杨爱武, 张佳强, 等. 无人集群博弈对抗系统仿真验证及决策关键技术综述[J]. 系统仿真学报, 2024, 36(4): 805-816. |
| Liang Xiaolong, Yang Aiwu, Zhang Jiaqiang, et al. Simulation Verification and Decision-making Key Technologies of Unmanned Swarm Game Confrontation: A Survey[J]. Journal of System Simulation, 2024, 36(4): 805-816. | |
| [7] | Li Yuxi. Deep Reinforcement Learning: An Overview[EB/OL]. (2017-01-25) [2025-05-02]. . |
| [8] | Wang Xinwei, Wang Yihui, Su Xichao, et al. Deep Reinforcement Learning-based Air Combat Maneuver Decision-making: Literature Review, Implementation Tutorial and Future Direction[J]. Artificial Intelligence Review, 2024, 57(1): 1. |
| [9] | BENGIO Y, GOODFELLOW I, COURVILLE A. Deep Learning[M].Cambridge, Massachusetts: University Press of the Massachusetts Institute of Technology, 2017. |
| [10] | SUTTON R S, BARTO A G. Reinforcement Learning: An Introduction[M]. Cambridge, Massachusetts: University Press of the Massachusetts Institute of Technology, 2018. |
| [11] | Li Yurui, Chen Yuxuan, Zhang Li, et al. The Composite Task Challenge for Cooperative Multi-Agent Reinforcement Learning[EB/OL]. (2025-02-01) [2025-05-02]. . |
| [12] | 施伟, 冯旸赫, 程光权, 等. 基于深度强化学习的多机协同空战方法研究[J]. 自动化学报, 2021, 47(7): 1610-1623. |
| Shi Wei, Feng Yanghe, Cheng Guangquan, et al. Research on Multi-aircraft Cooperative Air Combat Method Based on Deep Reinforcement Learning[J]. Acta Automatica Sinica, 2021, 47(7): 1610-1623. | |
| [13] | Foerster J N, Farquhar G, Afouras T, et al. Counterfactual Multi-agent Policy Gradients[C]//Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence. Palo Alto: AAAI Press, 2018: 363. |
| [14] | Li Shaowei, Jia Yuhong, Yang Fan, et al. Collaborative Decision-making Method for Multi-UAV Based on Multiagent Reinforcement Learning[J]. IEEE Access, 2022, 10: 91385-91396. |
| [15] | Liu Xiaoxiong, Yin Yi, Su Yuzhan, et al. A Multi-UCAV Cooperative Decision-making Method Based on an MAPPO Algorithm for Beyond-visual-range Air Combat[J]. Aerospace, 2022, 9(10): 563. |
| [16] | Xiaohong Nian, Li Mengmeng, Wang Haibo, et al. Large-scale UAV Swarm Confrontation Based on Hierarchical Attention Actor-critic Algorithm[J]. Applied Intelligence, 2024, 54(4): 3279-3294. |
| [17] | 符小卫, 王辉, 徐哲. 基于DE-MADDPG的多无人机协同追捕策略[J]. 航空学报, 2022, 43(5): 522-535. |
| Fu Xiaowei, Wang Hui, Xu Zhe. Cooperative Pursuit Strategy for Multi-UAVs Based on DE-MADDPG Algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2022, 43(5): 522-535. | |
| [18] | 陈灿, 莫雳, 郑多, 等. 非对称机动能力多无人机智能协同攻防对抗[J]. 航空学报, 2020, 41(12): 336-348. |
| Chen Can, Mo Li, Zheng Duo, et al. Cooperative Attack-defense Game of Multiple UAVs with Asymmetric Maneuverability[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41(12): 336-348. | |
| [19] | 孙智孝, 杨晟琦, 朴海音, 等. 未来智能空战发展综述[J]. 航空学报, 2021, 42(8): 28-42. |
| Sun Zhixiao, Yang Shengqi, Haiyin Piao, et al. A Survey of Air Combat Artificial Intelligence[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(8): 28-42. | |
| [20] | TALAY T A. Introduction to the Aerodynamics of Flight[EB/OL]. (1975-01-01) [2025-05-02]. . |
| [21] | SHAW R L. Fighter Combat[M]. Annapolis, Maryland: Tactics and Maneuvering, 1985: 62-97. |
| [22] | Zheng Zhiqiang, Duan Haibin. UAV Maneuver Decision-making Via Deep Reinforcement Learning for Short-range Air Combat[J]. Intelligence & Robotics, 2023, 3(1): 76-94. |
| [23] | Yang Qiming, Zhang Jiandong, Shi Guoqing, et al. Maneuver Decision of UAV in Short-range Air Combat Based on Deep Reinforcement Learning[J]. IEEE Access, 2020, 8: 363-378. |
| [24] | Cho Kyunghyun, van Merriënboer Bart, Gulcehre Caglar, et al. Learning Phrase Representations Using RNN Encoder-decoder for Statistical Machine Translation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Stroudsburg: ACL, 2014: 1724-1734. |
| [25] | SCHAUL T, Quan J, ANTONOGLOU I, et al. Prioritized Experience Replay[C]//4th International Conference on Learning Representations. Puerto Rico: ICLR, 2016: 1-13. |
| [26] | Sutton R S. Learning to Predict by the Methods of Temporal Differences[J]. Machine Learning, 1988, 3(1): 9-44. |
| [27] | KINGMA D P, Ba J. Adam: A Method for Stochastic Optimization[C]//3rd International Conference on Learning Representations. San Diego: ICLR 2015: 1-15. |
| [28] | Lowe Ryan, Wu Yi, Tamar A, et al. Multi-agent Actor-critic for Mixed Cooperative-competitive Environments[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6382-6393. |
| [1] | Tao Caixia, Chen Naikun, Gao Fengyang, Zhang Jiangang. Distributed Optimization for Integrated Energy Based on Multi-agent Reinforcement Learning [J]. Journal of System Simulation, 2026, 38(2): 476-487. |
| [2] | Jiang Ming, He Tao. Solving the Vehicle Routing Problem Based on Deep Reinforcement Learning [J]. Journal of System Simulation, 2025, 37(9): 2177-2187. |
| [3] | Ni Peilong, Mao Pengjun, Wang Ning, Yang Mengjie. Robot Path Planning Based on Improved A-DDQN Algorithm [J]. Journal of System Simulation, 2025, 37(9): 2420-2430. |
| [4] | Chen Zhen, Wu Zhuoyi, Zhang Lin. Research on Policy Representation in Deep Reinforcement Learning [J]. Journal of System Simulation, 2025, 37(7): 1753-1769. |
| [5] | Wu Guohua, Zeng Jiaheng, Wang Dezhi, Zheng Long, Zou Wei. A Quadrotor Trajectory Tracking Control Method Based on Deep Reinforcement Learning [J]. Journal of System Simulation, 2025, 37(5): 1169-1187. |
| [6] | Bai Zhenzu, Hou Yizhi, He Zhangming, Wei Juhui, Zhou Haiyin, Wang Jiongqi. Optimization of Dynamic Weapon Target Assignment Considering Random Disturbances [J]. Journal of System Simulation, 2025, 37(12): 2967-2980. |
| [7] | Zheng Jiayu, Mai Zhuxue, Chen Zheyi. Optimization of Service Caching and Computation Offloading in Digital Twin Cloud-edge Networks [J]. Journal of System Simulation, 2025, 37(11): 2741-2753. |
| [8] | Di Jian, Wan Xue, Jiang Limei. Evolutionary Reinforcement Learning Based on Elite Instruction and Random Search [J]. Journal of System Simulation, 2025, 37(11): 2877-2887. |
| [9] | Xu Zhongkai, Chu Chenyang, Xie Kai, Zhao Ruizhuo, Ke Wenjun. Optimization Dispatch Method for High-proportion Renewable Energy Power Systems Based on SC-PPO [J]. Journal of System Simulation, 2025, 37(10): 2511-2521. |
| [10] | Liang Xiuman, Liu Ziliang, Liu Zhendong. Path Planning of Improved RRT Algorithm Based on Deep Reinforcement Learning [J]. Journal of System Simulation, 2025, 37(10): 2578-2593. |
| [11] | Jiang Jiachen, Jia Zhengxuan, Xu Zhao, Lin Tingyu, Zhao Pengpeng, Ou Yiming. Decision Modeling and Solution Based on Game Adversarial Complex Systems [J]. Journal of System Simulation, 2025, 37(1): 66-78. |
| [12] | Qin Baoxin, Zhang Yuxiao, Wu Sirui, Cao Weichong, Li Zhan. Intelligent Optimization of Coal Terminal Unloading Scheduling Based on Improved D3QN Algorithm [J]. Journal of System Simulation, 2024, 36(3): 770-781. |
| [13] | Li Ming, Ye Wangzhong, Yan Jiehua. Path Planning of Desert Robot Based on Deep Reinforcement Learning [J]. Journal of System Simulation, 2024, 36(12): 2917-2925. |
| [14] | Zhang Yongfu, Liu Yang, Yuan He. A Method for Key Node Identification in Operational Target System Based on War Gaming [J]. Journal of System Simulation, 2024, 36(11): 2654-2661. |
| [15] | An Jing, Si Guangya, Zhang Lei. Strategy Optimization Method of Multi-dimension Projection Based on Deep Reinforcement Learning [J]. Journal of System Simulation, 2024, 36(1): 39-49. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
