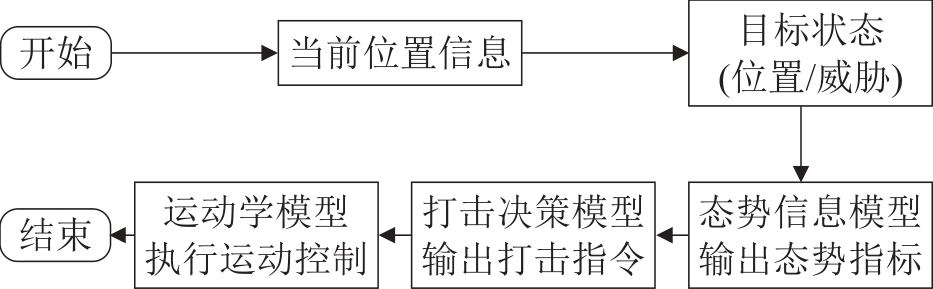
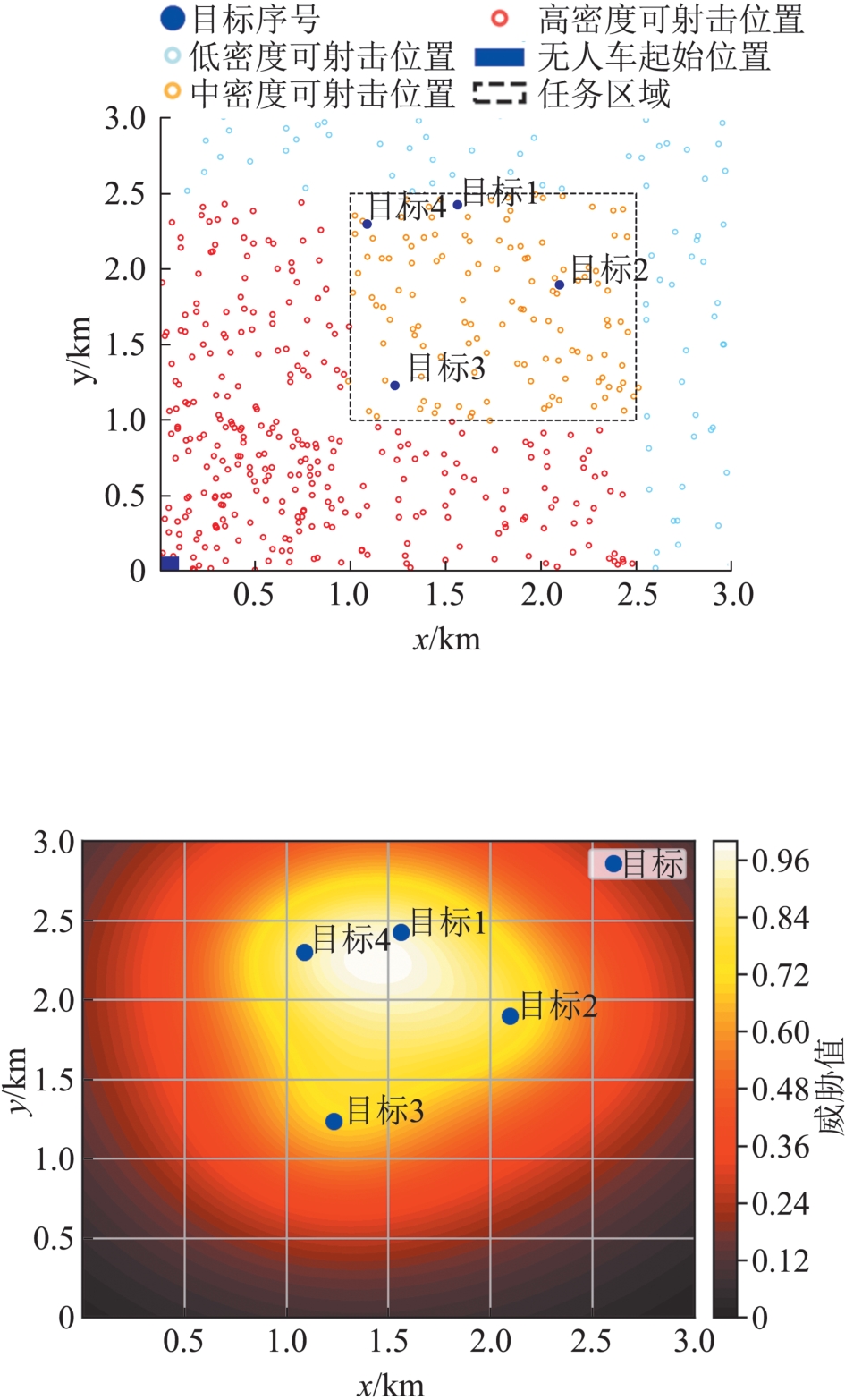
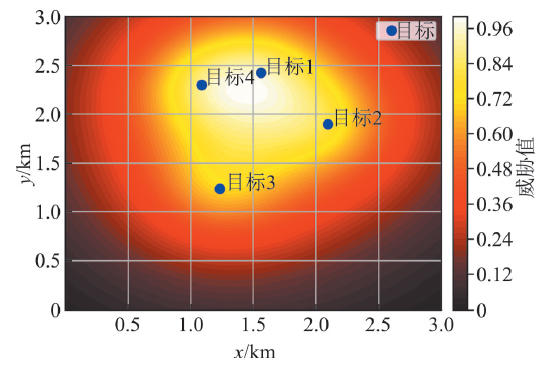
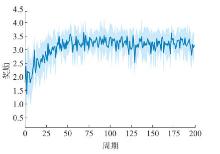
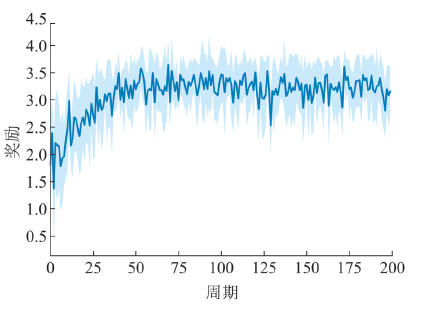
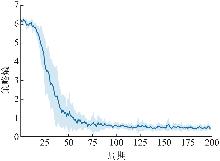
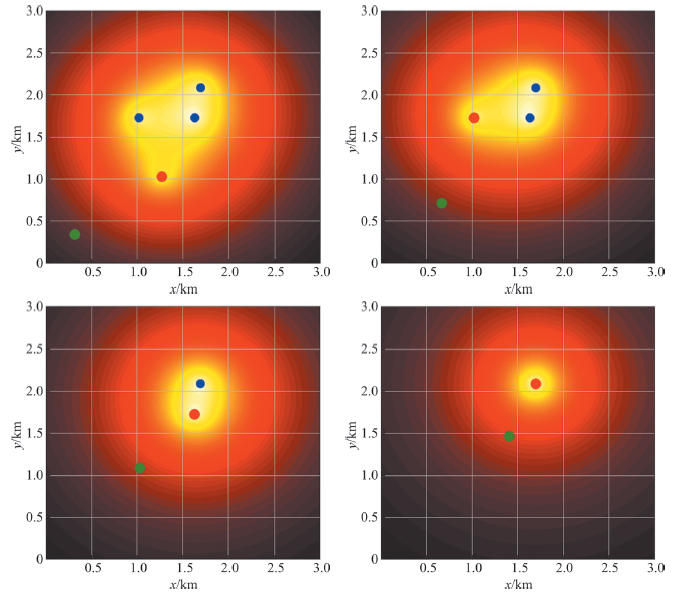
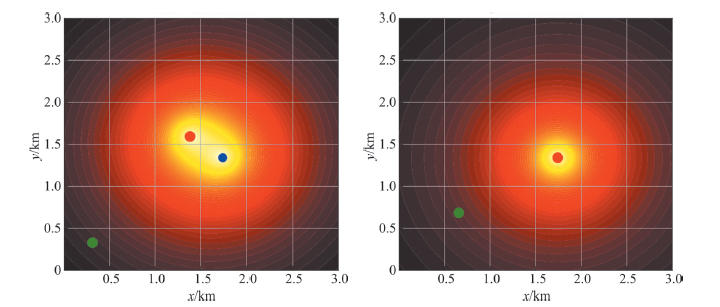
| [1] |
Wang Tong, Fu Liyue, Wei Zhengxian, et al. Unmanned Ground Weapon Target Assignment Based on Deep Q-learning Network with an Improved Multi-objective Artificial Bee Colony Algorithm[J]. Engineering Applications of Artificial Intelligence, 2023, 117, Part B: 105612.
|
| [2] |
Jia Yingjuan, Qu Liangdong, Li Xiaoqin. Automatic Path Planning of Unmanned Combat Aerial Vehicle Based on Double-layer Coding Method with Enhanced Grey Wolf Optimizer[J]. Artificial Intelligence Review, 2023, 56(10): 12257-12314.
|
| [3] |
Ahn Jisoo, Jung Sewoong, Kim Hansom, et al. A Study on Unmanned Combat Vehicle Path Planning for Collision Avoidance with Enemy Forces in Dynamic Situations[J]. Journal of Computational Design and Engineering, 2023, 10(6): 2251-2270.
|
| [4] |
王霄龙, 陈洋, 胡棉, 等. 基于改进深度Q网络的机器人持续监测路径规划[J]. 兵工学报, 2024, 45(6): 1813-1823.
|
|
Wang Xiaolong, Chen Yang, Hu Mian, et al. Robot Path Planning for Persistent Monitoring Based on Improved Deep Q Networks[J]. Acta Armamentarii, 2024, 45(6): 1813-1823.
|
| [5] |
Qu Liangdong, Jia Yingjuan, Li Xiaoqin, et al. Two-stage Control Model Based on Enhanced Elephant Clan Optimization for Path Planning of Unmanned Combat Aerial Vehicle[J]. The Journal of Supercomputing, 2024, 80(17): 24938-24974.
|
| [6] |
Zhang Haojie, Yang Tiantian, Su Zhibao. A Formation Cooperative Reconnaissance Strategy for Multi-UGVs in Partially Unknown Environment[J]. Journal of the Chinese Institute of Engineers, 2023, 46(6): 551-562.
|
| [7] |
Su Wenjia, Gao Min, Gao Xinbao, et al. An Online Attack Decision Method for Unmanned Aerial Vehicle Cluster in Uncertain Environments[J]. IEEE Sensors Journal, 2024, 24(11): 18457-18466.
|
| [8] |
李传浩, 明振军, 王国新, 等. 基于多智能体深度强化学习的无人平台箔条干扰末端防御动态决策方法[J]. 兵工学报, 2025, 46(3): 19-33.
|
|
Li Chuanhao, Ming Zhenjun, Wang Guoxin, et al. Dynamic Decision-making Method of Unmanned Platform Chaff Jamming for Terminal Defense Based on Multi-agent Deep Reinforcement Learning[J]. Acta Armamentarii, 2025, 46(3): 19-33.
|
| [9] |
Wang Ting, Deng Yuxiang, Yang Zhao, et al. Parameterized Deep Reinforcement Learning with Hybrid Action Space for Edge Task Offloading[J]. IEEE Internet of Things Journal, 2024, 11(6): 10754-10767.
|
| [10] |
张森, 代强强. 改进型深度确定性策略梯度的无人机路径规划[J]. 系统仿真学报, 2025, 37(4): 875-881.
|
|
Zhang Sen, Dai Qiangqiang. UAV Path Planning Based on Improved Deep Deterministic Policy Gradients[J]. Journal of System Simulation, 2025, 37(4): 875-881.
|
| [11] |
张建东, 王鼎涵, 杨啟明, 等. 基于分层强化学习的无人机空战多维决策[J]. 兵工学报, 2023, 44(6): 1547-1563.
|
|
Zhang Jiandong, Wang Dinghan, Yang Qiming, et al. Multi-dimensional Decision-making for UAV Air Combat Based on Hierarchical Reinforcement Learning[J]. Acta Armamentarii, 2023, 44(6): 1547-1563.
|
| [12] |
李超, 王瑞星, 黄建忠, 等. 稀疏奖励下基于强化学习的无人集群自主决策与智能协同[J]. 兵工学报, 2023, 44(6): 1537-1546.
|
|
Li Chao, Wang Ruixing, Huang Jianzhong, et al. Autonomous Decision-making and Intelligent Collaboration of UAV Swarms Based on Reinforcement Learning with Sparse Rewards[J]. Acta Armamentarii, 2023, 44(6): 1537-1546.
|
| [13] |
Ma Chengdong, Liu Jianan, He Saichao, et al. Confrontation and Obstacle-avoidance of Unmanned Vehicles Based on Progressive Reinforcement Learning[J]. IEEE Access, 2023, 11: 50398-50411.
|
| [14] |
Yue Longfei, Yang Rennong, Zhang Ying, et al. Deep Reinforcement Learning for UAV Intelligent Mission Planning[J]. Complexity, 2022, 2022: 3551508.
|
| [15] |
Liu Wei, Zhang Tao, Huang Shengjun, et al. A Hybrid Optimization Framework for UAV Reconnaissance Mission Planning[J]. Computers & Industrial Engineering, 2022, 173: 108653.
|
| [16] |
Xiong Jiechao, Wang Qing, Yang Zhuoran, et al. Parametrized Deep Q-networks Learning: Reinforcement Learning with Discrete-continuous Hybrid Action Space[EB/OL]. (2018-10-10) [2025-04-01]. .
|
| [17] |
Fan Zhou, Su Rui, Zhang Weinan, et al. Hybrid Actor-Critic Reinforcement Learning in Parameterized Action Space[C]//Proceedings of the 28th International Joint Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 2279-2285.
|
| [18] |
Cao Jingyu, Dong Lu, Sun Changyin. Hierarchical Reinforcement Learning for Kinematic Control Tasks with Parameterized Action Spaces[J]. Neural Computing and Applications, 2024, 36(1): 323-336.
|
| [19] |
Han Guangjie, Feng Zixiao, Wang Hao, et al. Underwater Multi-target Node Path Planning in Hybrid Action Space: A Deep Reinforcement Learning Approach[J]. IEEE Transactions on Mobile Computing, 2024, 23(12): 13033-13047.
|
| [20] |
Xu Yahao, Wei Yiran, Jiang Keyang, et al. Action Decoupled SAC Reinforcement Learning with Discrete-continuous Hybrid Action Spaces[J]. Neurocomputing, 2023, 537: 141-151.
|
| [21] |
He Yufei, Hu Ruiqi, Liang Kewei, et al. Deep Reinforcement Learning Algorithm with Long Short-term Memory Network for Optimizing Unmanned Aerial Vehicle Information Transmission[J]. Mathematics, 2025, 13(1): 46.
|
| [22] |
Zhang Cheng, Tao Chengyang, Xu Yuelei, et al. Autonomous Defense of Unmanned Aerial Vehicles Against Missile Attacks Using a GRU-based PPO Algorithm[J]. International Journal of Aeronautical and Space Sciences, 2024, 25(3): 1034-1049.
|
| [23] |
Hao Shuhui, Guan Wei, Cui Zhewen, et al. USV Collision Avoidance Decision-making Based on the Improved PPO Algorithm in Restricted Waters[J]. Journal of Marine Science and Engineering, 2024, 12(8): 1428.
|
| [24] |
Schulman J, Wolski F, Dhariwal P, et al. Proximal Policy Optimization Algorithms[EB/OL]. (2017-08-28) [2025-02-10]. .
|
| [25] |
姜凌峰, 李新凯, 张海, 等. 基于改进TD3算法的无人机动态环境无地图导航[J]. 航空学报, 2025, 46(8): 292-307.
|
|
Jiang Lingfeng, Li Xinkai, Zhang Hai, et al. Mapless Navigation of UAVs in Dynamic Environments Based on an Improved TD3 Algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(8): 292-307.
|