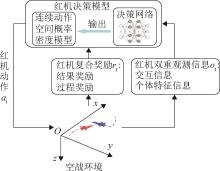
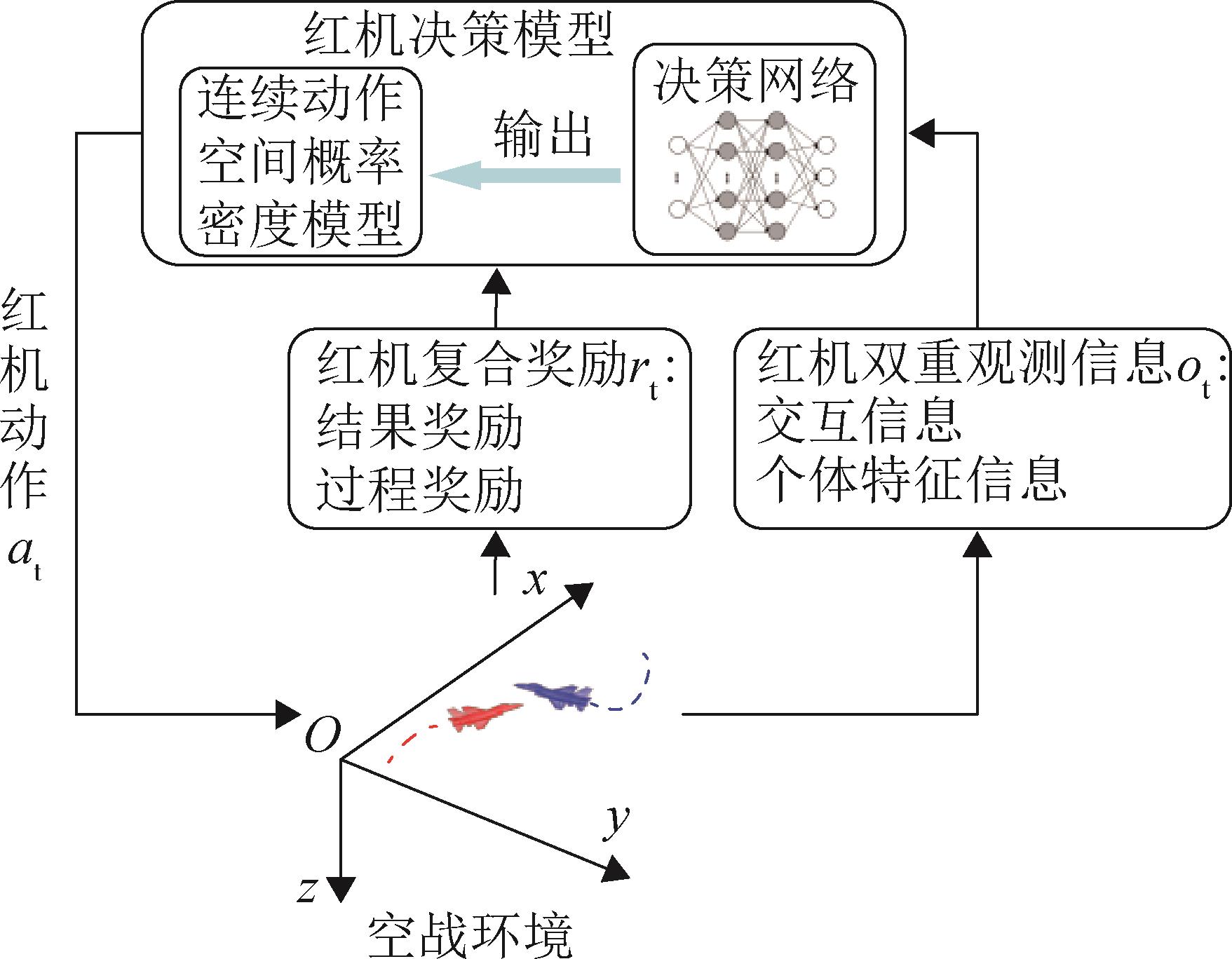
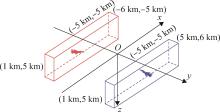
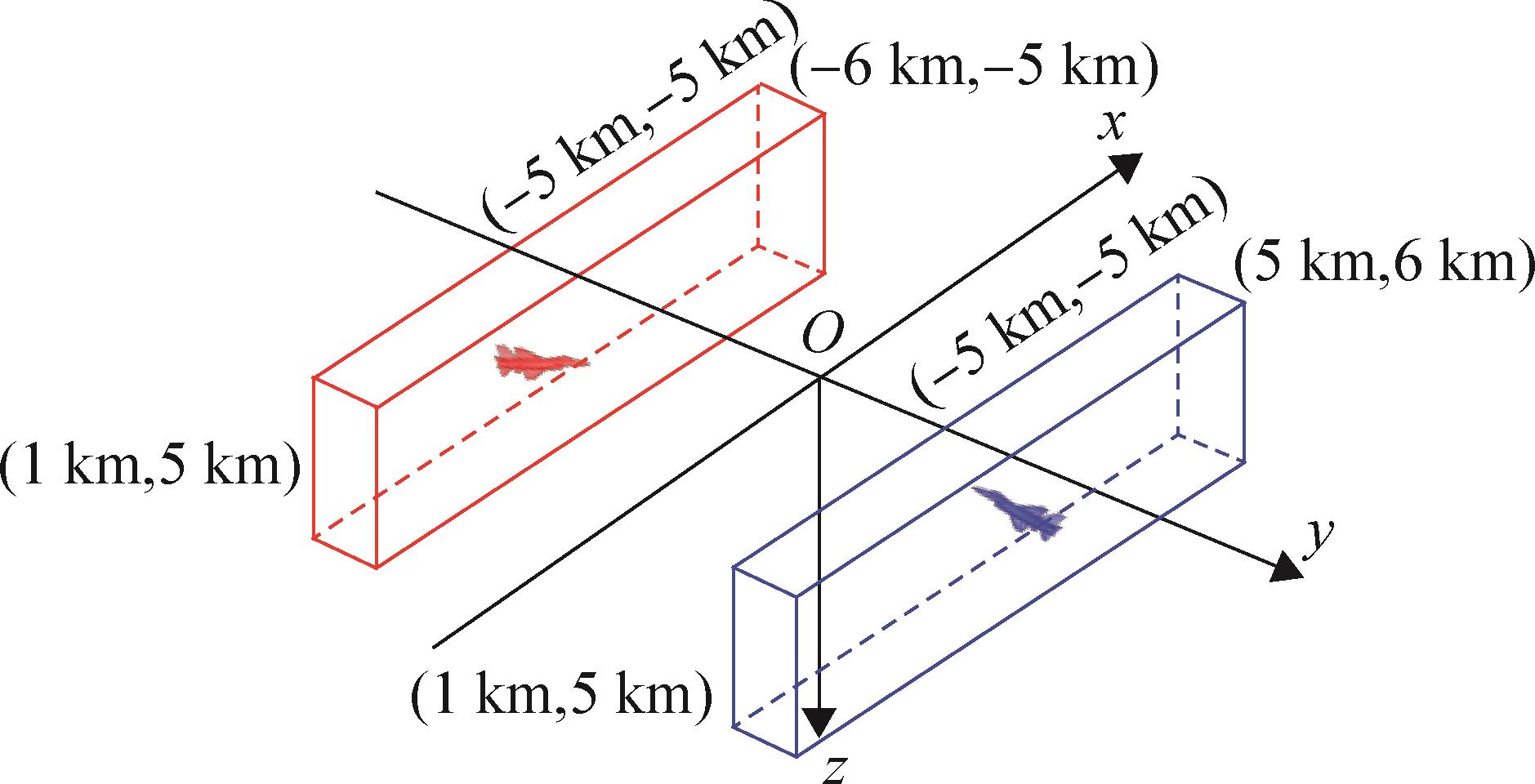
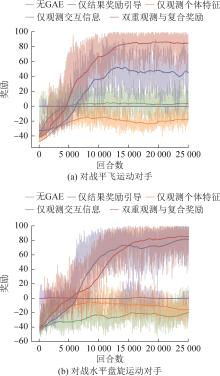
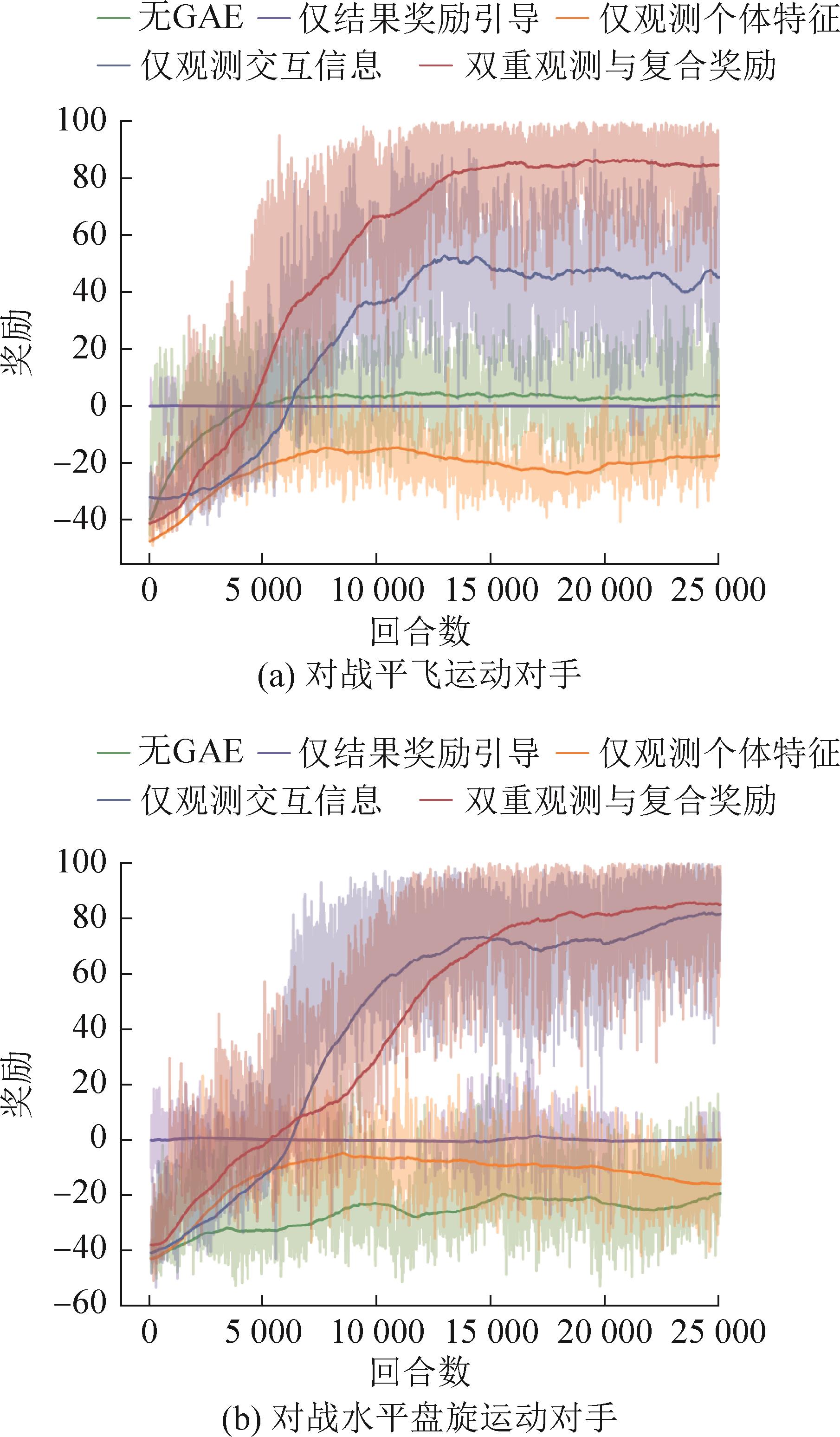
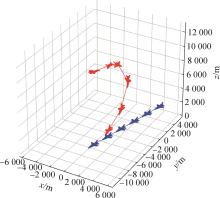
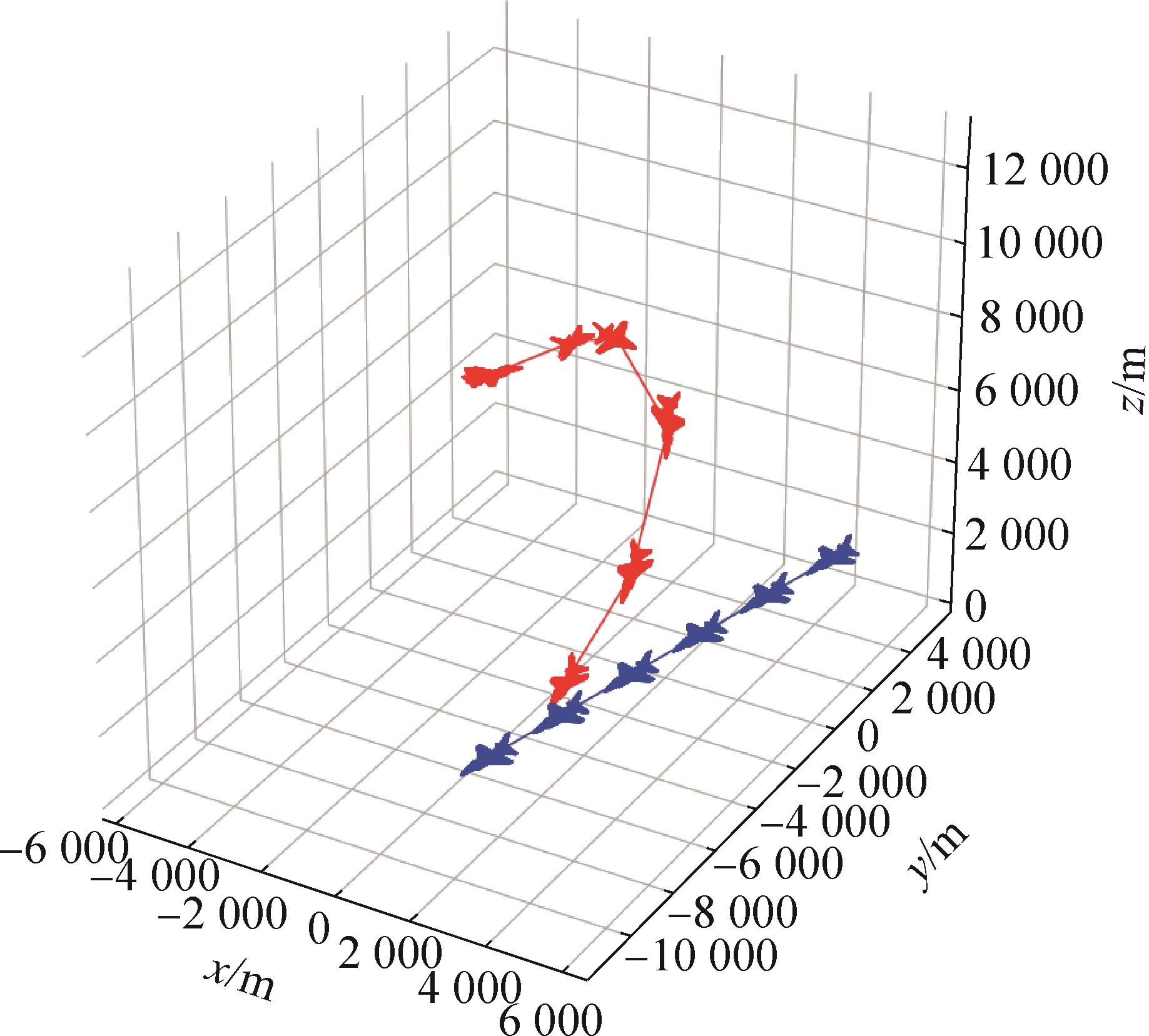
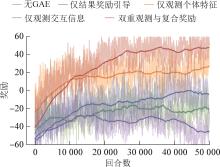
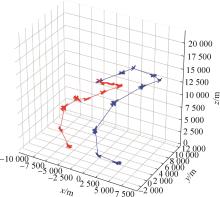
| 1 |
孙智孝, 杨晟琦, 朴海音, 等. 未来智能空战发展综述[J]. 航空学报, 2021, 42(8): 28-42.
|
|
Sun Zhixiao, Yang Shengqi, Haiyin Piao, et al. A Survey of Air Combat Artificial Intelligence[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(8): 28-42.
|
| 2 |
Mitchell R R. Embedding a Tactics Expert System into Air Combat Simulation Software[C]//Proceedings of the IEEE National Aerospace and Electronics Conference. Piscataway, NJ, USA: IEEE, 1989: 1027-1033.
|
| 3 |
Li Qiuni, Wang Fawei, Yang Wanping, et al. Air Combat Maneuver Strategy Algorithm Based on Two-layer Game Decision-making and Distributed Double Game Trees MCTS Under Uncertain Information[J]. Electronics, 2022, 11(16): 2608.
|
| 4 |
Ernest N, Carroll D, Schumacher C, et al. Genetic Fuzzy Based Artificial Intelligence for Unmanned Combat Aerial Vehicle Control in Simulated Air Combat Missions[J]. Journal of Defense Management, 2016, 6(1): 1000144.
|
| 5 |
Hu Dongyuan, Yang Rennong, Zuo Jialiang, et al. Application of Deep Reinforcement Learning in Maneuver Planning of Beyond-visual-range Air Combat[J]. IEEE Access, 2021, 9: 32282-32297.
|
| 6 |
Wang Xu, Wang Sen, Liang Xingxing, et al. Deep Reinforcement Learning: A Survey[J/OL]. IEEE Transactions on Neural Networks and Learning Systems. (2022-09-28) [2022-11-18]. .
|
| 7 |
黄晓冬, 苑海涛, 毕敬, 等. 基于DQN的海战场舰船路径规划及仿真[J]. 系统仿真学报, 2021, 33(10): 2440-2448.
|
|
Huang Xiaodong, Yuan Haitao, Bi Jing, et al. DQN-based Path Planning Method and Simulation for Submarine and Warship in Naval Battlefield[J]. Journal of System Simulation, 2021, 33(10): 2440-2448.
|
| 8 |
曾贲, 房霄, 孔德帅, 等. 一种数据驱动的对抗博弈智能体建模方法[J]. 系统仿真学报, 2021, 33(12): 2838-2845
|
|
Zeng Ben, Fang Xiao, Kong Deshuai, et al. A Data-driven Modeling Method for Game Adversity Agent[J]. Journal of System Simulation, 2021, 33(12): 2838-2845.
|
| 9 |
Nam Tran Duc, Quan Tran Hai, Dat Nguyen Van, et al. An Approach for UAV Indoor Obstacle Avoidance Based on AI Technique with Ensemble of ResNet8 and Res-DQN[C]//2019 6th NAFOSTED Conference on Information and Computer Science (NICS). Piscataway, NJ, USA: IEEE, 2019: 330-335.
|
| 10 |
李永丰, 史静平, 章卫国, 等. 深度强化学习的无人作战飞机空战机动决策[J]. 哈尔滨工业大学学报, 2021, 53(12): 33-41.
|
|
Li Yongfeng, Shi Jingping, Zhang Weiguo, et al. Maneuver Decision of UCAV in Air Combat Based on Deep Reinforcement Learning[J]. Journal of Harbin Institute of Technology, 2021, 53(12): 33-41.
|
| 11 |
王昱, 任田君, 范子琳. 基于引导Minimax-DDQN的无人机空战机动决策[J]. 计算机应用, 2023, 43(8): 2636-2643.
|
|
Wang Yu, Ren Tianjun, Fan Zilin. Air Combat Maneuver Decision-making of Unmanned Aerial Vehicle Based on Guided Minimax-DDQN[J]. Journal of Computer Applications, 2023, 43(8): 2636-2643.
|
| 12 |
Hu Dongyuan, Zuo Jialiang, Zhang Wanze, et al. Research on Application of LSTM-QDN in Intelligent Air Combat Simulation[J]. Journal of Physics: Conference Series, 2021, 1746(1): 012028.
|
| 13 |
Jing Xianyong, Hou Manyi, Wu Gaolong, et al. Research on Maneuvering Decision Algorithm Based on Improved Deep Deterministic Policy Gradient[J]. IEEE Access, 2022, 10: 92426-92445.
|
| 14 |
Pope A P, Ide J S, Mićović Daria, et al. Hierarchical Reinforcement Learning for Air Combat at DARPA's AlphaDogfight Trials[J]. IEEE Transactions on Artificial Intelligence, 2023, 4(6): 1371-1385.
|
| 15 |
Schulman J, Wolski F, Dhariwal P, et al. Proximal Policy Optimization Algorithms[EB/OL]. (2017-08-28) [2022-11-27]. .
|
| 16 |
康扬名. 多无人机协同对抗系统智能决策与控制研究[D]. 北京: 中国科学院大学, 2020.
|
|
Kang Yangming. Research on Intelligent Decision and Control of Multi-UAV Cooperative Countermeasure System[D]. Beijing: University of Chinese Academy of Sciences, 2020.
|