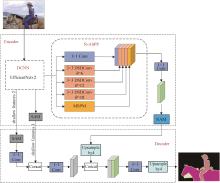
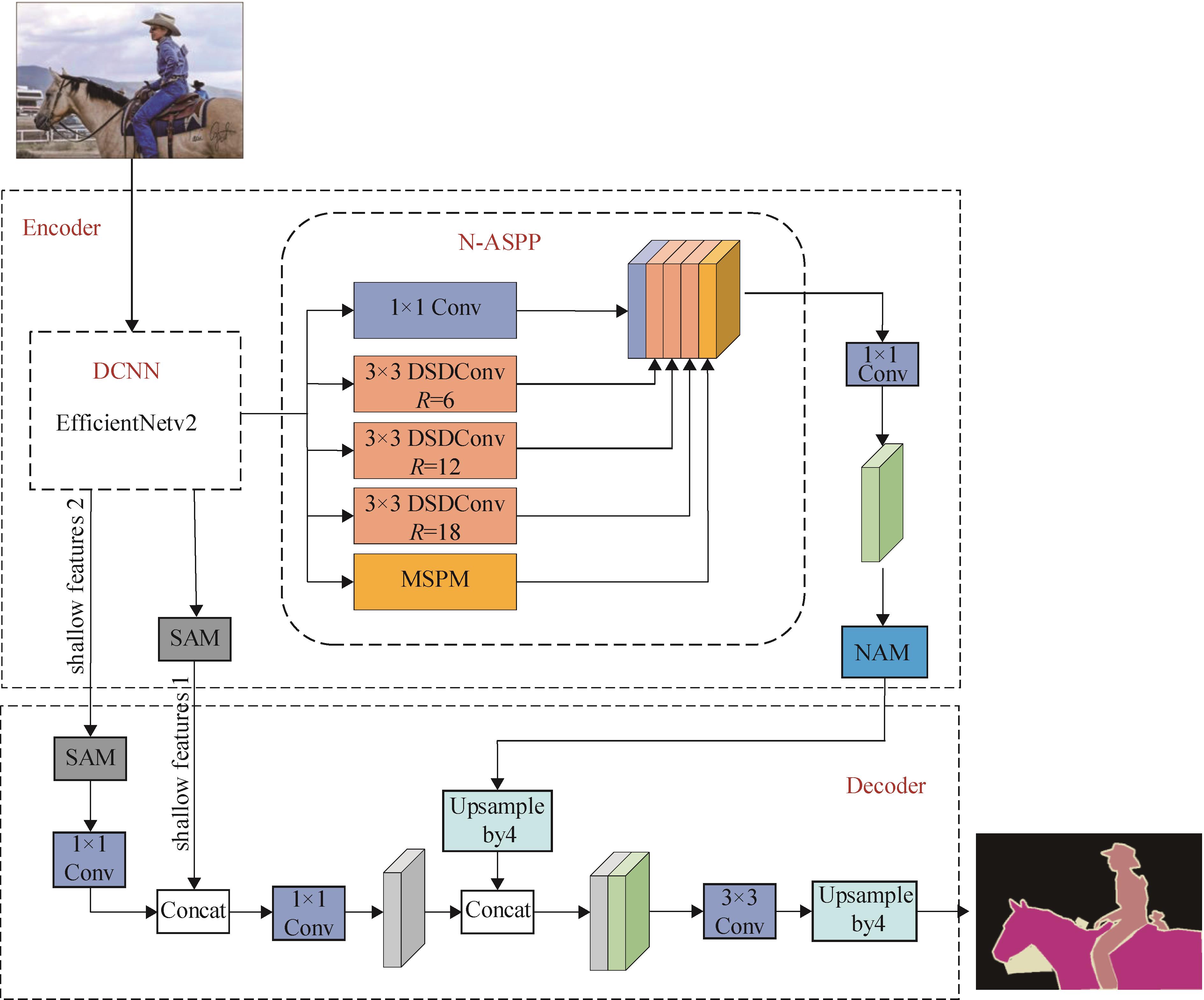
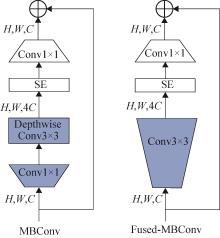
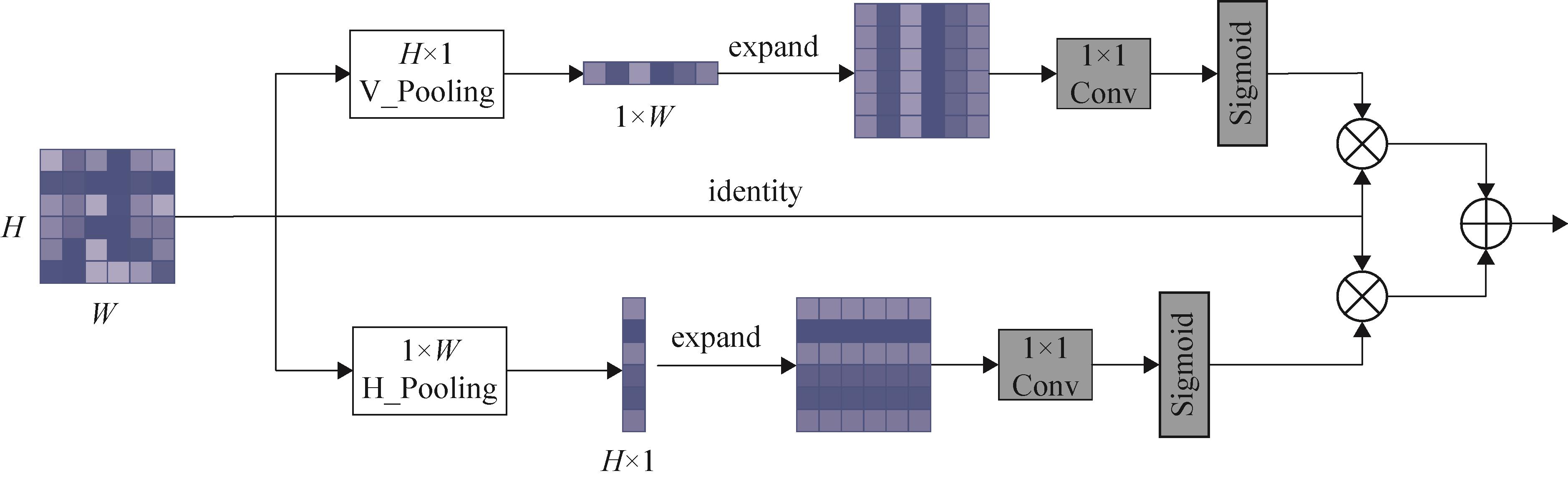
| 1 |
Wang Lei, Wu Jiaji, Liu Xunyu, et al. Semantic Segmentation of Large-scale Point Clouds Based on Dilated Nearest Neighbors Graph[J]. Complex & Intelligent Systems, 2022, 8(5): 3833-3845.
|
| 2 |
田萱, 王亮, 丁琪. 基于深度学习的图像语义分割方法综述[J]. 软件学报, 2019, 30(2): 440-468.
|
|
Tian Xuan, Wang Liang, Ding Qi. Review of Image Semantic Segmentation Based on Deep Learning[J]. Journal of Software, 2019, 30(2): 440-468.
|
| 3 |
Asgari Taghanaki S, Abhishek K, Cohen J P, et al. Deep Semantic Segmentation of Natural and Medical Images: A Review[J]. Artificial Intelligence Review, 2021, 54(1): 137-178.
|
| 4 |
Yuan Xiaohui, Shi Jianfang, Gu Lichuan. A Review of Deep Learning Methods for Semantic Segmentation of Remote Sensing Imagery[J]. Expert Systems with Applications, 2021, 169: 114417.
|
| 5 |
王奕清. 基于计算机视觉的卫星云图反演降水量方法研究[D]. 成都: 电子科技大学, 2021.
|
|
Wang Yiqing. A Computer Vision Method for Precipitation Inversion With Satellite Cloud Images[D]. Chengdu: University of Electronic Science and Technology of China, 2021.
|
| 6 |
Ivanovs M, Ozols K, Dobrajs A, et al. Improving Semantic Segmentation of Urban Scenes for Self-driving Cars with Synthetic Images[J]. Sensors, 2022, 22(6): 2252.
|
| 7 |
Kontschieder P, Samuel Rota Bulò, Bischof H, et al. Structured Class-labels in Random Forests for Semantic Image Labelling[C]//2011 International Conference on Computer Vision. Piscataway, NJ, USA: IEEE, 2011: 2190-2197.
|
| 8 |
Martijn van den Heuvel, Mandl R, Hulshoff Pol H. Normalized Cut Group Clustering of Resting-state FMRI Data[J]. PLoS One, 2008, 3(4): e2001.
|
| 9 |
Cherkassky V, Ma Yunqian. Practical Selection of SVM Parameters and Noise Estimation for SVM Regression[J]. Neural Networks, 2004, 17(1): 113-126.
|
| 10 |
Hu Yaosi, Chen Zhenzhong, Lin Weiyao. RGB-D Semantic Segmentation: A Review[C]//2018 IEEE International Conference on Multimedia & Expo Workshops (ICMEW). Piscataway, NJ, USA: IEEE, 2018: 1-6.
|
| 11 |
Kamilaris A, Prenafeta-Boldú Francesc X. Deep Learning in Agriculture: A Survey[J]. Computers and Electronics in Agriculture, 2018, 147: 70-90.
|
| 12 |
刘瑞军, 王向上, 张晨, 等. 基于深度学习的视觉SLAM综述[J]. 系统仿真学报, 2020, 32(7): 1244-1256.
|
|
Liu Ruijun, Wang Xiangshang, Zhang Chen, et al. A Survey on Visual SLAM Based on Deep Learning[J]. Journal of System Simulation, 2020, 32(7): 1244-1256.
|
| 13 |
罗荣, 王亮, 肖玉杰. 深度学习技术应用现状分析与发展趋势研究[J]. 计算机教育, 2019(10): 19-22.
|
| 14 |
Yu Changqian, Wang Jingbo, Peng Chao, et al. BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation[C]//Computer Vision – ECCV 2018. Cham: Springer International Publishing, 2018: 334-349.
|
| 15 |
Zhang Fan, Chen Yanqin, Li Zhihang, et al. ACFNet: Attentional Class Feature Network for Semantic Segmentation[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE, 2019: 6797-6806.
|
| 16 |
Wu Tianyi, Tang Sheng, Zhang Rui, et al. CGNet: A Light-weight Context Guided Network for Semantic Segmentation[J]. IEEE Transactions on Image Processing, 2021, 30: 1169-1179.
|
| 17 |
Zhao Yaochi, Liu Shiguang, Hu Zhuhua. Focal Learning on Stranger for Imbalanced Image Segmentation[J]. IET Image Processing, 2022, 16(5): 1305-1323.
|
| 18 |
Zhao Yaochi, Liu Shiguang, Hu Zhuhua. Dynamically Balancing Class Losses in Imbalanced Deep Learning[J]. Electronics Letters, 2022, 58(5): 203-206.
|
| 19 |
Long J, Shelhamer E, Darrell T. Fully Convolutional Networks for Semantic Segmentation[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2015: 3431-3440.
|
| 20 |
Guo Yanming, Liu Yu, Georgiou T, et al. A Review of Semantic Segmentation Using Deep Neural Networks[J]. International Journal of Multimedia Information Retrieval, 2018, 7(2): 87-93.
|
| 21 |
Badrinarayanan V, Kendall A, Cipolla R. SegNet: A Deep Convolutional Encoder-decoder Architecture for Image Segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495.
|
| 22 |
Ronneberger O, Fischer P, Brox T. U-Net: Convolutional Networks for Biomedical Image Segmentation[C]//Medical Image Computing and Computer-Assisted Intervention-MICCAI 2015. Cham: Springer International Publishing, 2015: 234-241.
|
| 23 |
Schönfeld Edgar, Schiele B, Khoreva A. A U-net Based Discriminator for Generative Adversarial Networks[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2020: 8204-8213.
|
| 24 |
Jaeger P F, Kohl S A A, Bickelhaupt S, et al. Retina U-net: Embarrassingly Simple Exploitation of Segmentation Supervision for Medical Object Detection[C]//Proceedings of the Machine Learning for Health NeurIPS Workshop. Chia Laguna Resort, Sardinia, Italy: PMLR, 2020: 171-183.
|
| 25 |
Chen L C, Papandreou G, Kokkinos I, et al. Semantic Image Segmentation With Deep Convolutional Nets and Fully Connected CRFs[EB/OL]. (2016-06-07) [2022-05-30]. .
|
| 26 |
Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-scale Image Recognition[EB/OL]. (2015-04-10) [2022-05-30]. .
|
| 27 |
Chen L C, Papandreou G, Kokkinos I, et al. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848.
|
| 28 |
Chen L C, Papandreou G, Schroff F, et al. Rethinking Atrous Convolution for Semantic Image Segmentation[EB/OL]. (2017-12-05) [2022-05-30]. .
|
| 29 |
Chen L C, Zhu Yukun, Papandreou G, et al. Encoder-decoder With Atrous Separable Convolution for Semantic Image Segmentation[C]//Computer Vision-ECCV 2018. Cham: Springer International Publishing, 2018: 833-851.
|
| 30 |
Tan Mingxing, Le Q. EfficientNetV2: Smaller Models and Faster Training[C]//Proceedings of the 38th International Conference on Machine Learning. Chia Laguna Resort, Sardinia, Italy: PMLR, 2021: 10096-10106.
|
| 31 |
Tan Mingxing, Le Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks[C]//Proceedings of the 36th International Conference on Machine Learning. Chia Laguna Resort, Sardinia, Italy: PMLR, 2019: 6105-6114.
|
| 32 |
Hou Qibin, Zhang Li, Cheng Mingming, et al. Strip Pooling: Rethinking Spatial Pooling for Scene Parsing[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2020: 4002-4011.
|
| 33 |
Liu Yichao, Shao Zongru, Teng Yueyang, et al. NAM: Normalization-based Attention Module[EB/OL]. (2021-11-24) [2022-05-30]. .
|
| 34 |
Hu Jie, Shen Li, Sun Gang. Squeeze-and-excitation Networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2018: 7132-7141.
|
| 35 |
Woo S, Park J, Lee J Y, et al. CBAM: Convolutional Block Attention Module[C]//Computer Vision-ECCV 2018. Cham: Springer International Publishing, 2018: 3-19.
|
 ), 陈雨2(
), 陈雨2(