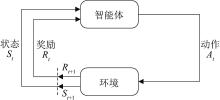
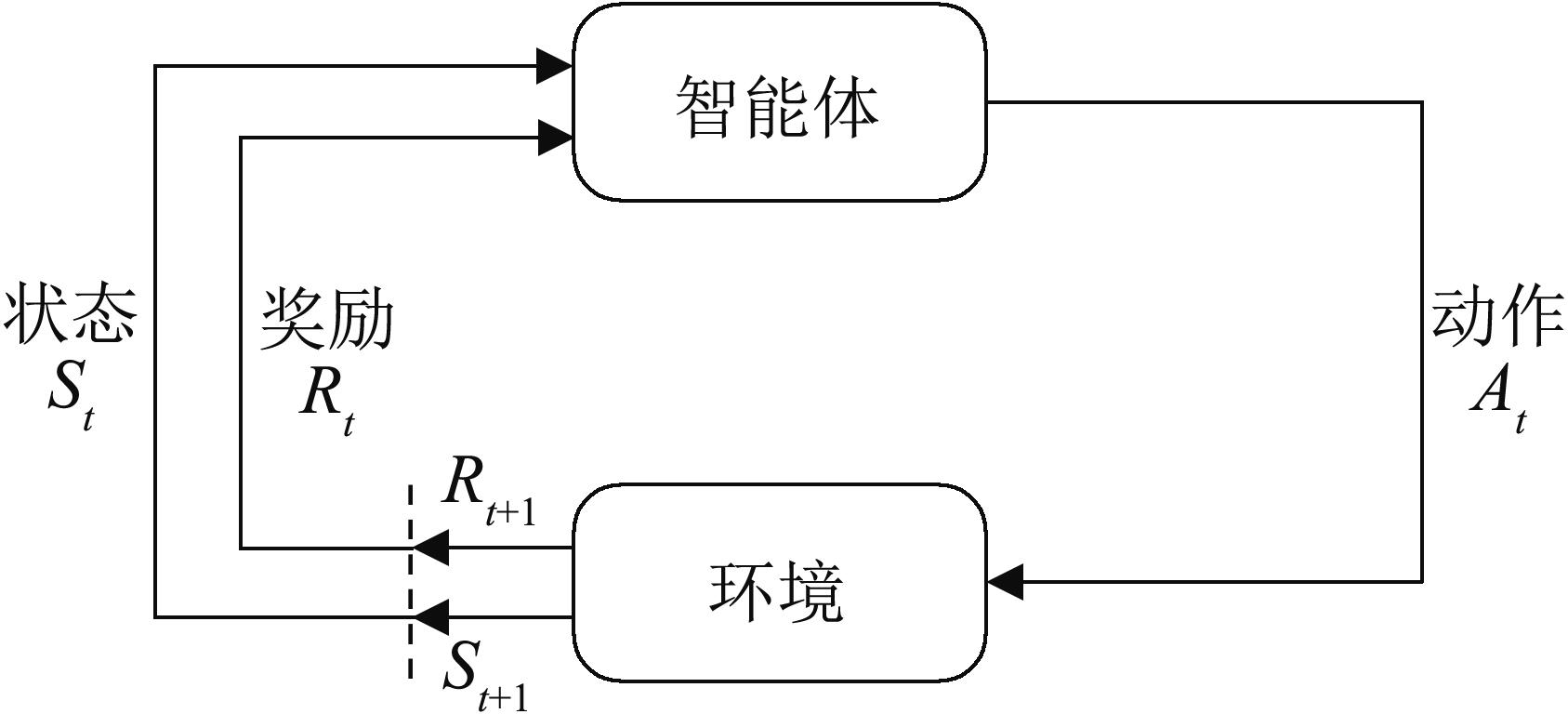
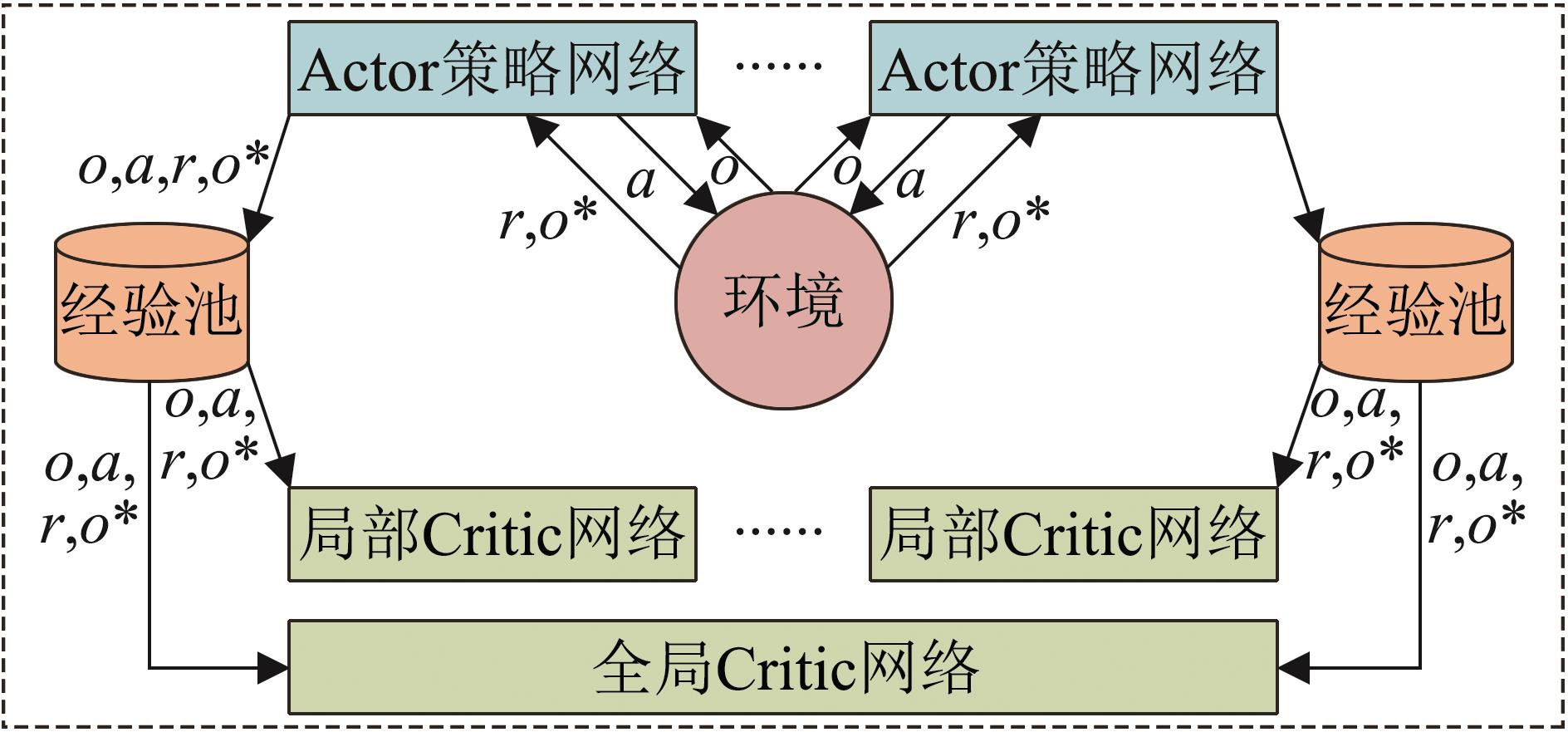
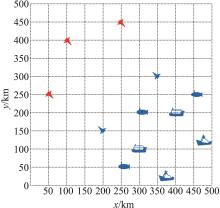
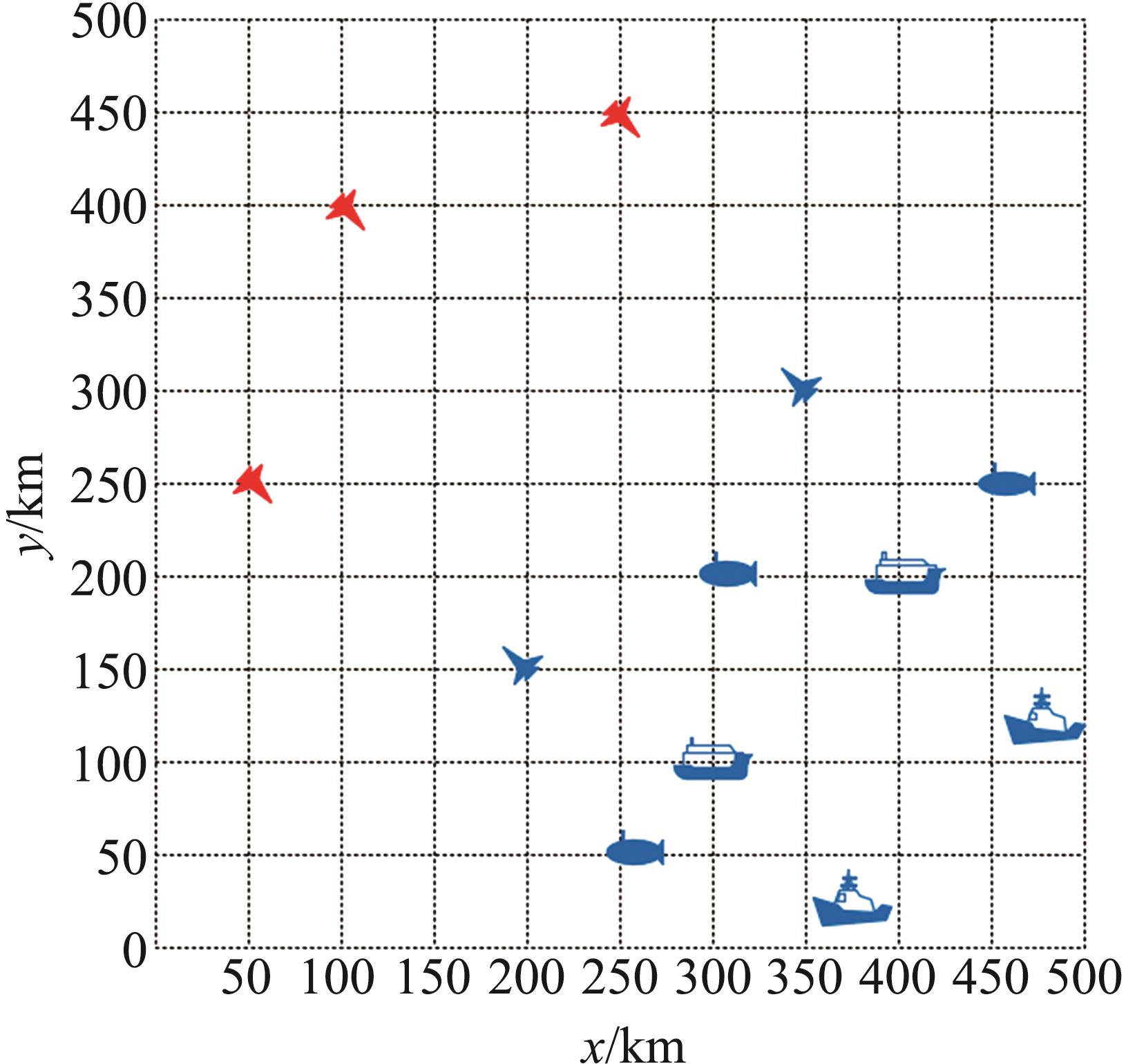
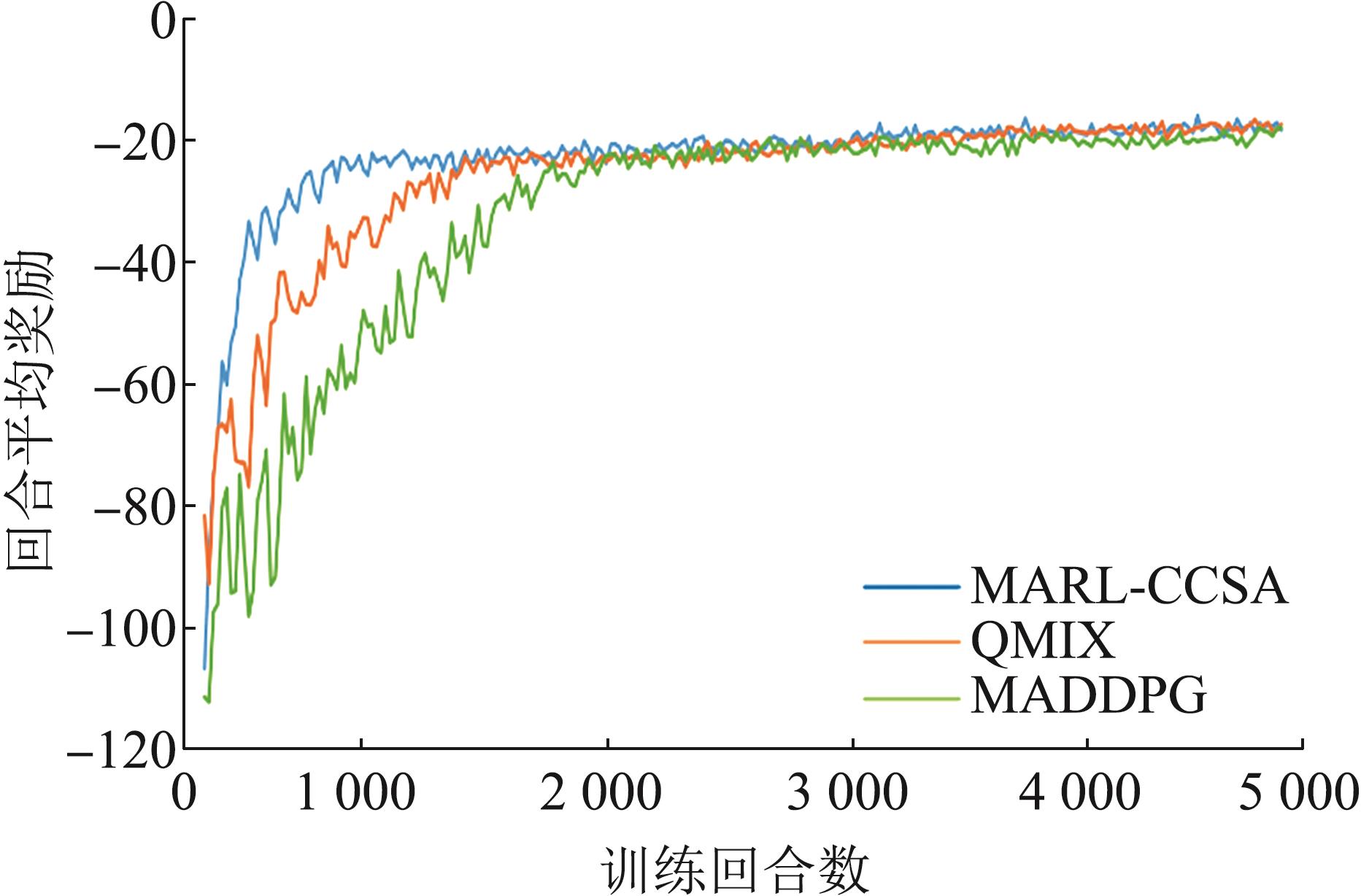
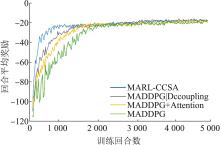
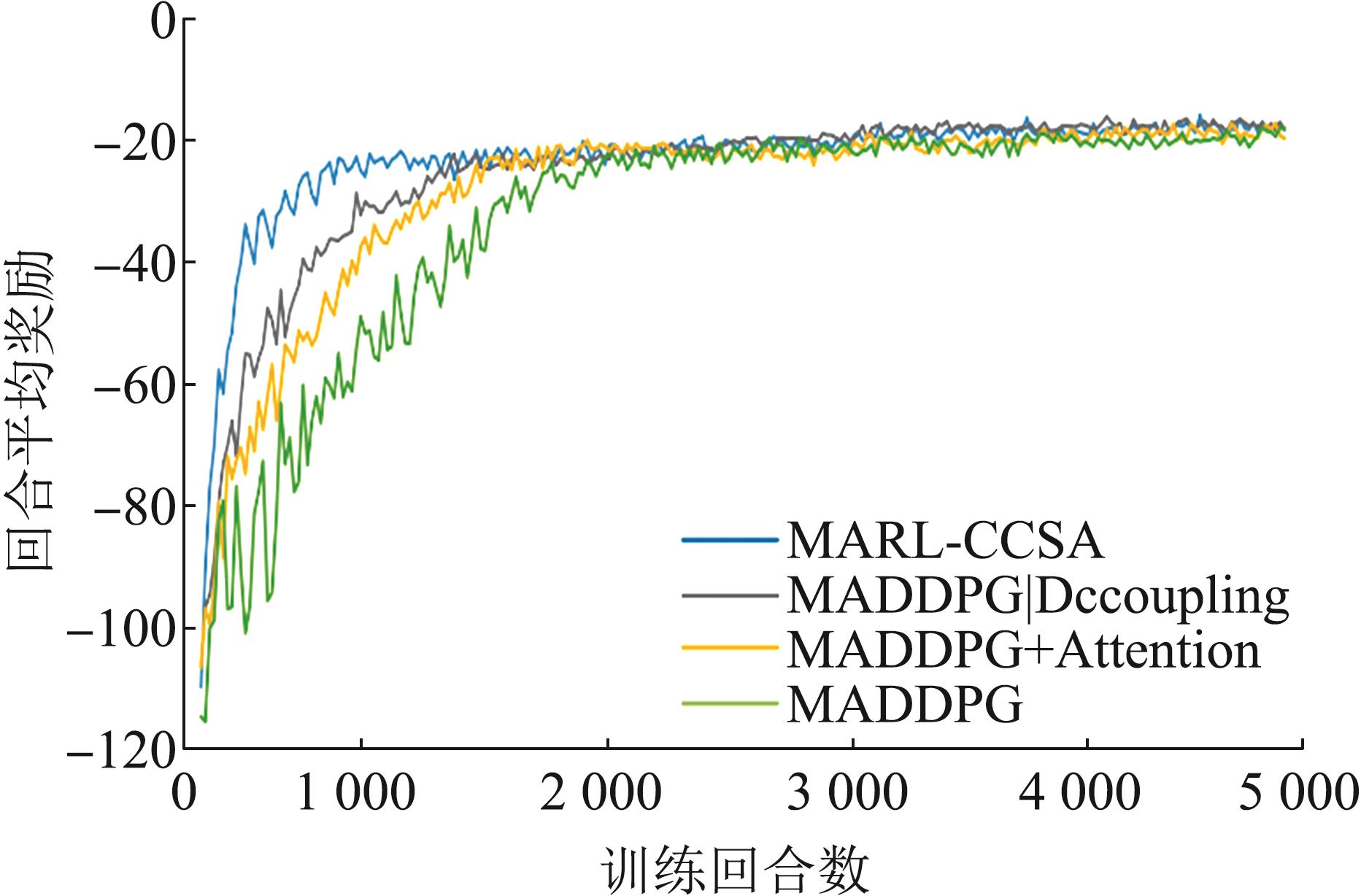
| 1 |
Lowe R, Wu Y I, Tamar A, et al. Multi-agent Actor-critic for Mixed Cooperative-Competitive Environments[C]//Advances in Neural Information Processing Systems. San Francisco: Margan Kaufmann, 2017.
|
| 2 |
Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous Control with Deep Reinforcement Learning[C/OL]. International Conference on Learning Representations. 2016. [2022-06-11]. .
|
| 3 |
Rashid T, Samvelyan M, Schroeder C, et al. QMIX: Monotonic Value Function Factorisation for Deep Multi-agent Reinforcement Learning[C]//International Conference on Machine Learning. New York: PMLR, 2018: 4295-4304.
|
| 4 |
Watkins C J C H. Learning from Delayed Rewards[D]. London: King's College, 1989.
|
| 5 |
Rummery G A, Niranjan M. On-line Q-learning Using Connectionist Systems[M]. Cambridge, England: University of Cambridge, Department of Engineering, 1994.
|
| 6 |
Sutton R S, McAllester D A, Singh S P, et al. Policy Gradient Methods for Reinforcement Learning with Function Approximation[C]//Advances in Neural Information Processing Systems. San Francisco: Margan Kaufmann, 2000: 1057-1063.
|
| 7 |
Mnih V, Kavukcuoglu K, Silver D, et al. Playing Atari with Deep Reinforcement Learning[J/OL]. [2022-06-11]. .
|
| 8 |
Barto A G, Sutton R S, Anderson C W. Neuronlike Adaptive Elements That Can Solve Difficult Learning Control Problems[J]. IEEE Transactions on Systems, Man, and Cybernetics(S0018-9472), 1983, 27(5): 834-846.
|
| 9 |
Hernandez-Leal P, Kartal B, Taylor M E. Is multiagent Deep Reinforcement Learning the Answer or the Question? A Brief Survey[J/OL]. [2022-06-11]. .
|
| 10 |
Tampuu A, Matiisen T, Kodelja D, et al. Multiagent Cooperation and Competition with Deep Reinforcement Learning[J]. Plos One(S1932-6203), 2017, 12(4): e0172395.
|
| 11 |
Gupta J K, Egorov M, Kochenderfer M. Cooperative Multi-agent Control Using Deep Reinforcement Learning[C]//International Conference on Autonomous Agents and Multiagent Systems. Cham: Springer, 2017: 66-83.
|
| 12 |
Foerster J N, Assael Y M, De Freitas N, et al. Learning to Communicate with Deep Multi-agent Reinforcement Learning[J]. [2022-06-11]. .
|
| 13 |
Sukhbaatar S, Fergus R. Learning Multi-agent Communication with Backpropagation[J]. Advances in Neural Information Processing Systems(S1049-5258), 2016, 29: 2244-2252.
|
| 14 |
Sunehag P, Lever G, Gruslys A, et al. Value-decomposition Networks for Cooperative Multi-agent Learning[J]. [2022-06-11] .
|
| 15 |
Foerster J, Nardelli N, Farquhar G, et al. Stabilising Experience Replay for Deep Multi-agent Reinforcement Learning[C]//International Conference on Machine learning. New York: PMLR, 2017: 1146-1155.
|
| 16 |
符小卫, 王辉, 徐哲. 基于DE-MADDPG的多无人机协同追捕策略研究[J]. 航空学报, 2022, 43(5): 325311.
|
|
Fu Xiaowei, Wang Hui, Xu Zhe. Cooperative Pursuit Strategy for Multi-UAVs Based on DE-MADDPG Algorithm[J]. Acta Aeronauticaet Astronautica Sinica, 2022, 43(5): 325311.
|
| 17 |
Schaul T, Quan J, Antonoglou I, et al. Prioritized Experience Replay[J]. [2022-06-11]. .
|
| 18 |
Vaswani A, Shazeer N, Parmar N, et al. Attention is All You Need[C]//Advances in Neural Information Processing Systems. San Francisco: Margan Kaufmann, 2017: 5998-6008.
|
| 19 |
Hu J, Shen L, Sun G. Squeeze-and-Excitation Networks[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141.
|
| 20 |
Iqbal S, Sha F. Actor-Attention-Critic for Multi-agent Reinforcement Learning[C]//International Conference on Machine Learning. New York: PMLR, 2019: 2961-2970.
|
| 21 |
Oh J, Chockalingam V, Lee H. Control of Memory, Active Perception, and Action in Minecraft[C]//International Conference on Machine Learning. New York: PMLR, 2016: 2790-2799.
|
 ), 燕雪峰, 宫丽娜, 张静宣, 关东海, 魏明强(
), 燕雪峰, 宫丽娜, 张静宣, 关东海, 魏明强(