

Journal of System Simulation ›› 2026, Vol. 38 ›› Issue (3): 758-775.doi: 10.16182/j.issn1004731x.joss.25-0298
• Papers • Previous Articles Next Articles
Liu Dayong1,2, Dong Zhiming1, Guo Qisheng1, Gao Ang3, Qiu Xuehuan1
Received:2025-04-12
Revised:2025-06-04
Online:2026-03-18
Published:2026-03-27
Contact:
Dong Zhiming
CLC Number:
Liu Dayong, Dong Zhiming, Guo Qisheng, Gao Ang, Qiu Xuehuan. Construction Approach of LLM-empowered Tactical Wargame Decision-making Agents[J]. Journal of System Simulation, 2026, 38(3): 758-775.
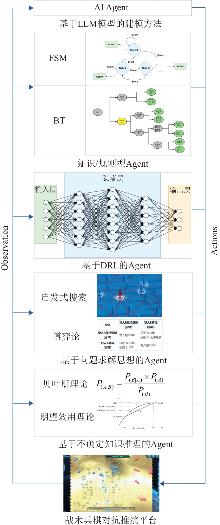
Fig. 1
Five typical decision-making agents
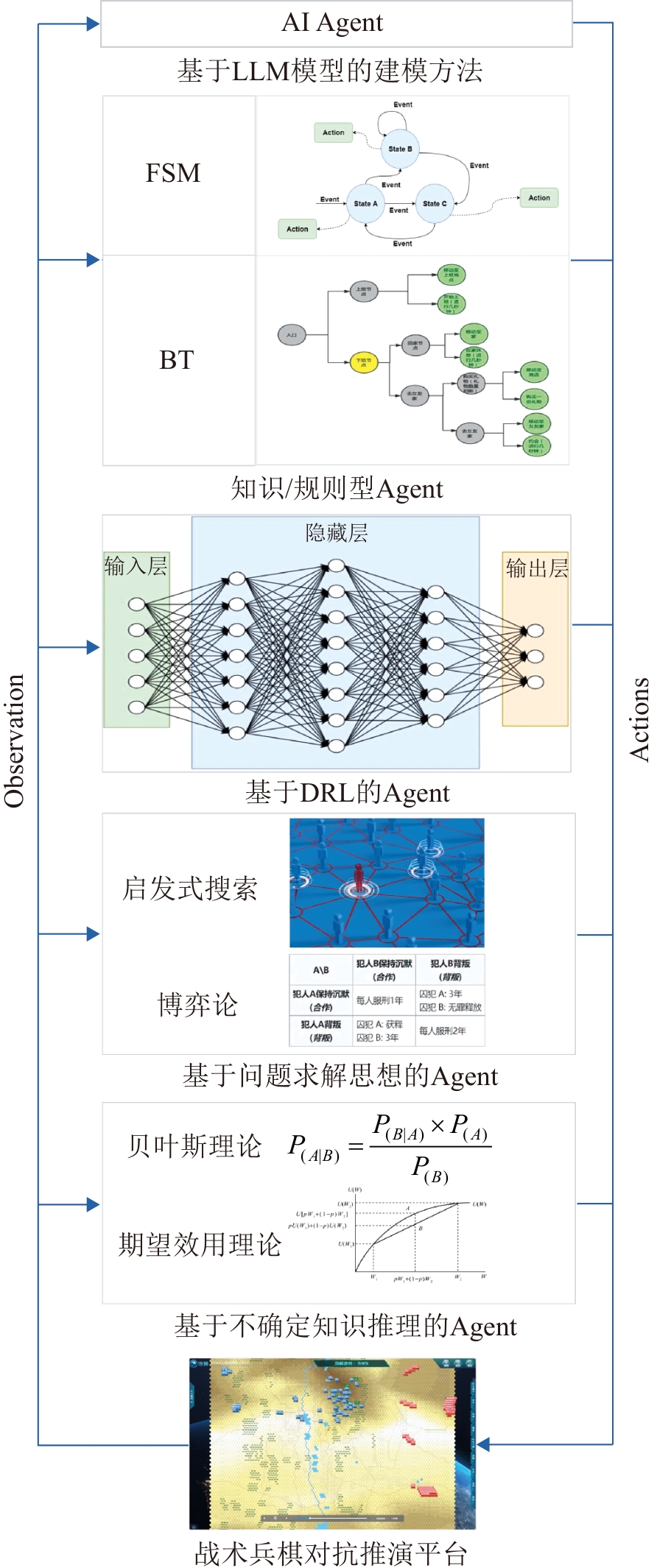
Fig. 2
Construction approach of decision-making agents based on LLM
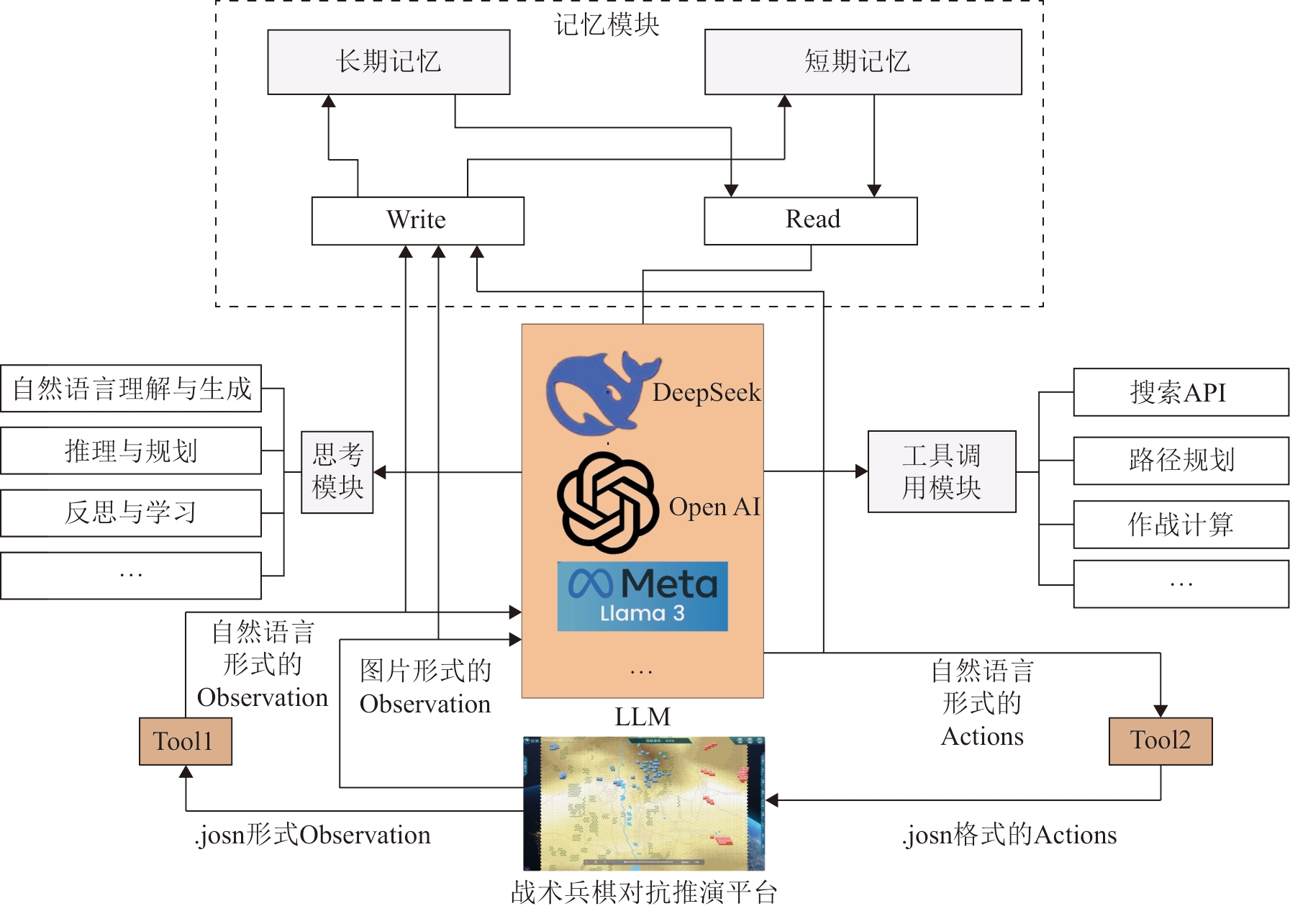
Table 1
Comparison of advantages and disadvantages of typical decision-making agent construction approaches
| 构建方法 | 优点 | 缺点 | 常用模型 | |
|---|---|---|---|---|
| 基于知识/规则 | 可解释性强、推理速度快 | 规则库构建工作量大,难以动态调整,智能水平上限难以突破 | FSM、BT | |
| 基于DRL的建模方法 | 基于单智能体DRL的方法 | 探索能力强,易找到最优策略 | 泛化能力弱;对于奖励稀疏问题、状态空间和搜索空间较大的问题很难收敛 | PPO、TRPO、 |
| 基于多智能体DRL的方法 | 智能体协作能力强、策略多样性好 | 模型收敛困难,目前仅在兵力数量较少的对抗场景中有应用;泛化能力弱 | MAPPO、MADDPG、 MASAC | |
| 基于问题求解思想的建模方法 | 启发式搜索 | 具有全局搜索能力 | 需要有明确的规则和状态空间,主要运用在组合优化、路径规划;占用算力较大 | GA、SA、ABC |
| 博弈决策 | 支持多方理性博弈分析,适用于对抗性场景 | 计算复杂度高,依赖完全信息假设,难以处理不完全信息 | Nash均衡求解器、 博弈树Game EA | |
| 基于不确定知识推理的建模方法 | 基于贝叶斯推理的建模 | 支持不确定性推理,动态更新概率分布 | 先验概率依赖专家经验,高维状态空间下计算效率低 | 贝叶斯网络、 MCMC采样 |
| 基于期望效用理论的建模 | 量化决策偏好,支持风险敏感性分析 | 效用函数设计主观性强,难以刻画复杂多目标冲突 | 期望效用最大化模型 | |
| 基于LLM的构建方法 | 泛化能力强,支持多模态态势理解,可生成多样化策略 | 推理速度慢,只能用于欠实时推演;微观决策能力弱 | GPT-4、DeepSeek-R1、 DeepSeek-V3 | |
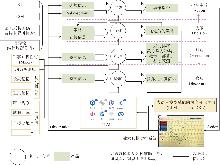
Fig. 3
Fusion decision-making framework of tactical wargame driven by large and small models
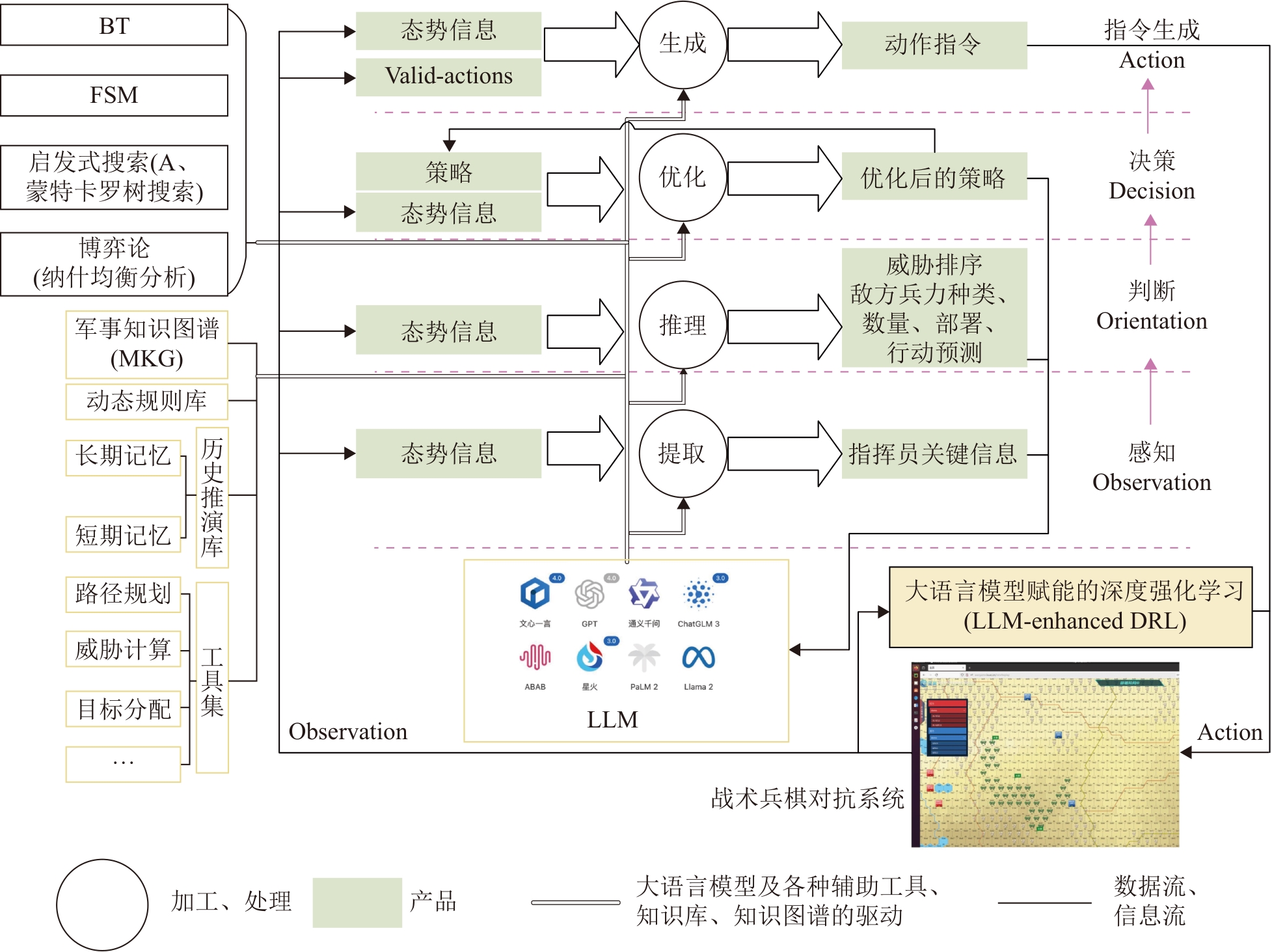

Fig. 4
Key decision-making information extraction
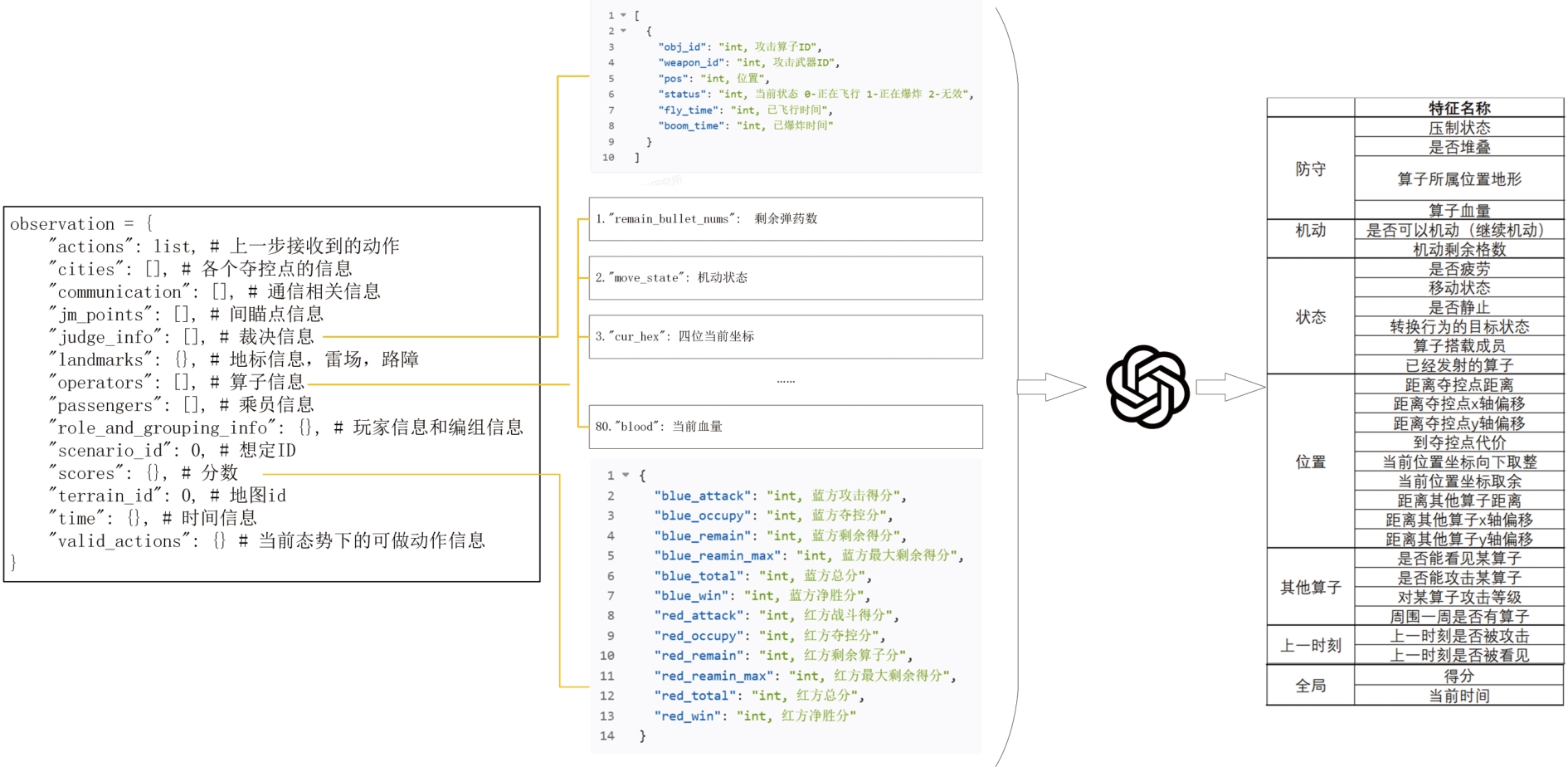
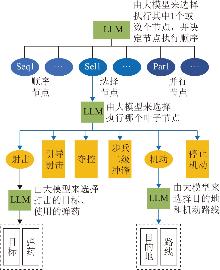
Fig. 5
Construction approach of agents fused with LLM and LLM with BT
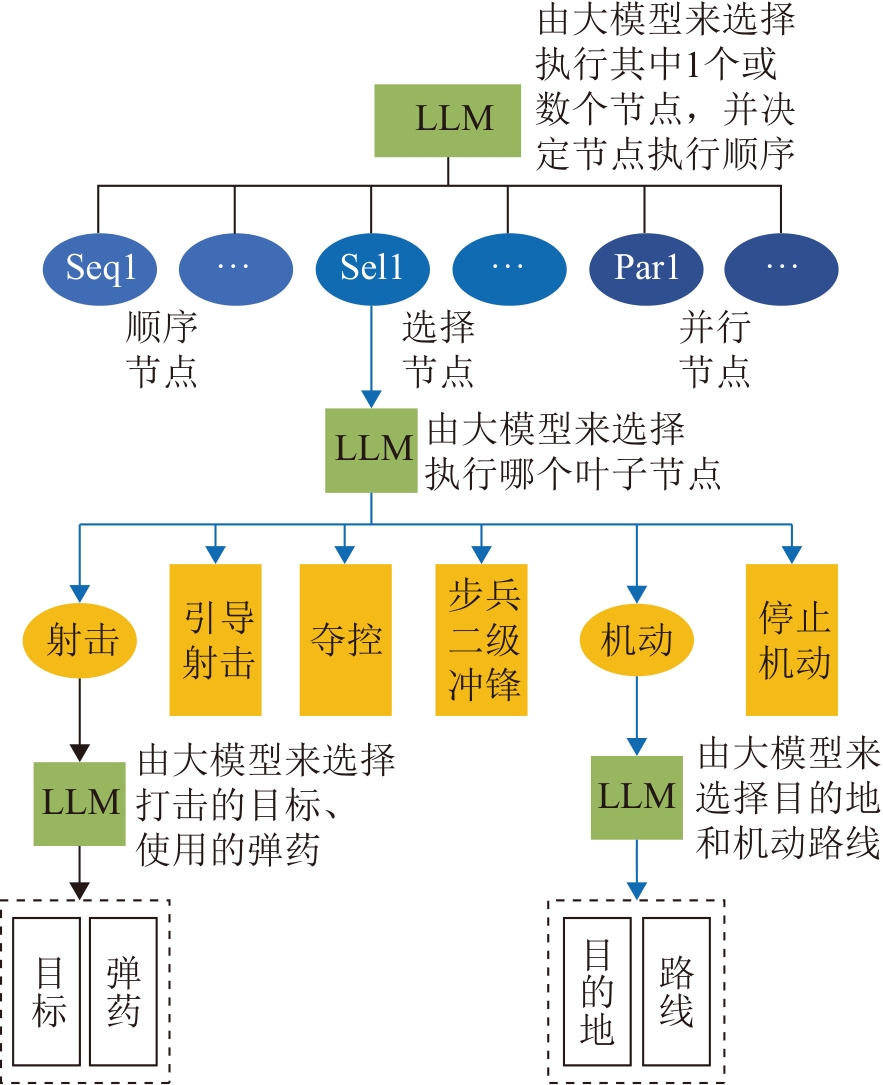
Table 2
Advantages of integrating LLM and BT
| 优势 | 解释 | 价值 |
|---|---|---|
增强战术 多样性 | LLM利用其生成能力,可以生成多样化策略,如“迂回包抄”“佯攻诱导”等,进而建立策略库,提升系统应对复杂场景的能力,避免策略僵化 | 提升系统应对复杂场景的能力,避免依赖单一策略导致的僵化 |
提升动态 适应性 | LLM实时解析战场威胁变化,如敌方火力转移,动态生成新的策略,注入BT新分支 | 增强系统对突发事件的响应能力,避免因环境变化导致策略失效 |
强化可解 释性 | LLM生成的策略经知识图谱验证后,映射为BT可读节点,如“东侧威胁密度低→选择侧翼”,满足策略的可解释需求 | 提供透明决策链条,满足军事推演的高风险场景下可解释、可验证的需求 |
保障 实时性 | BT底层以较高频率执行原子动作(移动、开火),而LLM仅在战术决策节点介入,通过异步流水线与缓存机制规避延迟瓶颈 | 通过分层调度与异步处理,确保高频动作与低频策略的协同优化 |
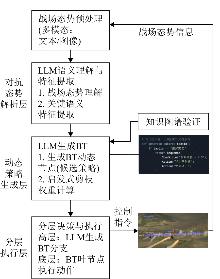
Fig. 6
Integrated architecture of LLM and BT
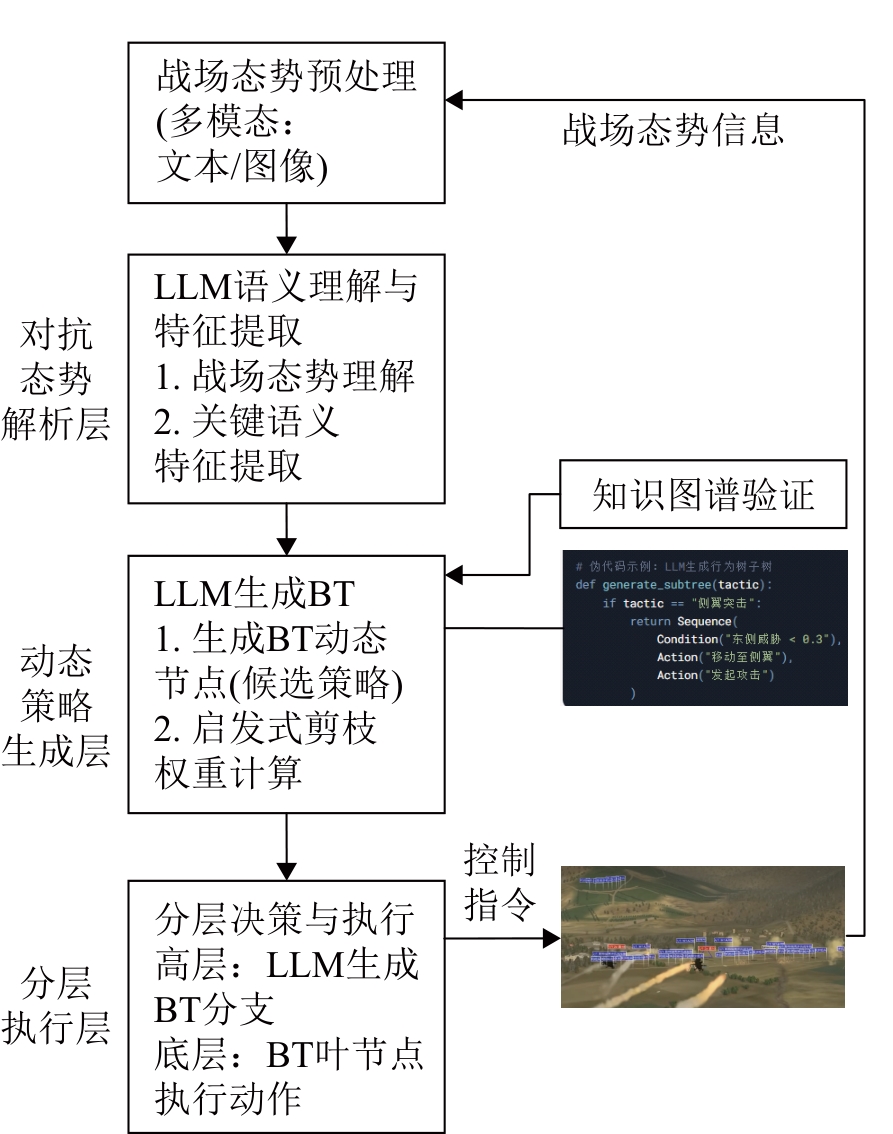
Table 3
Unmanned aerial vehicle operator's state transition function
| 当前状态 | 事件 | 下一状态 |
|---|---|---|
| 悬停 | 没有受到干扰,且收到飞行指令 | 机动 |
| 机动 | 收到停止指令且到达网格中心;到达终点 | 悬停 |
| … |

Fig. 7
FSM generation assisted by LLM

Table 4
LLM enhanced RL and RL enhanced LLM
| 维度 | LLM-enhanced RL | RL-enhanced LLM |
|---|---|---|
| 内涵 | 利用LLM的能力,提升RL的训练效率和策略性能 | 通过RL方法优化LLM的行为输出 |
| 技术目标 | 解决传统RL的样本效率低、状态表征弱、探索能力差等问题 | 提升LLM在开放场景中的决策能力、安全性和可控性 |
| 主体 | RL算法 | LLM |
| 优化目标 | 提升策略的样本效率和任务性能 | 提升模型输出的安全性、有用性和可控性 |
| 技术焦点 | 状态表征、奖励设计、探索优化 | 输出对齐、偏好学习、安全约束 |
| 数据依赖 | 依赖环境交互数据(状态‒动作‒奖励三元组) | 依赖人类反馈数据 |
| 典型应用 | 机器人控制、战略游戏、自动驾驶 | 对话系统、内容生成、合规审查 |
Table 5
Four approaches of LLM-empowered DRL
| 技术路线 | 原理 | 典型案例 |
|---|---|---|
| 状态表征生成 | 利用LLM的语义理解能力,将原始观测转化为结构化向量 | 在兵棋推演中,LLM解析作战报告生成包含“补给线完整性”“威胁热力图”等维度的状态编码 |
| 奖励函数设计 | 通过自然语言指令定义奖励,替代人工设计的奖励函数 | DeepMind的CICERO模型,将“保持外交关系”的文本目标转化为多国好感度奖励信号 |
| 策略生成 | 用LLM生成候选动作序列,缩小策略搜索空间 | Google的PEARL框架中,LLM生成战术动作,指导智能体在3D战场中的机动路径 |
| 世界模型构建 | LLM作为环境模拟器,预测状态转移和奖励信号 | 在《星际争霸2》中,基于GPT-4的世界模型将单位位置预测误差从15.2 px降至6.7 px。 |
Table 6
Necessity analysis of feature extraction in wargame DRL
| 场景 | 端到端学习的不足 | 特征提取的优势 |
|---|---|---|
| 高维数据 | 模型难以聚焦关键信息 | 降维后输入提升学习效率 |
| 复杂战术规则 | 隐含模式学习成本高 | 显式编码领域知识加速收敛 |
| 训练资源限制 | 需要大量样本与计算资源 | 合成特征缓解数据稀缺 |
| 可解释性 | 可解释性较差 | 提高决策可解释性 |
| 实时性要求 | 原始数据处理延迟高 | 预处理特征减少推理时间 |
Table 7
Analysis of the advantages and disadvantages of expert manual and LLM automatic feature extraction
| 项目 | 专家 | LLM |
|---|---|---|
| 优势 | 领域知识精准:专家基于战术规则和经验设计特征,如集结点范围、地形遮挡,确保特征符合军事逻辑 可解释性强:手工特征可直接关联战术决策,便于调试与验证 | 特征提取效果好:自动发现敌方协同、地形时变效应等专家难以识别的特征 动态适应性:实时调整关键区域权重,优于静态规则 增效减负:将专家从繁复的特征设计中解放,聚焦于规则验证与战术创新 |
| 劣势 | 主观盲区:利用专家经验编制的特征提取函数容易遗漏重要信息 信息压缩失真:人难以捕捉战场态势中的微观行为特征 规则僵化:预设逻辑难以适应战场态势突变 | 军事推演数据稀缺且敏感 LLM推理速度较慢,如果在推演中动态进行特征提取,其实时性无法满足兵棋推演实时性要求 |
Fig. 8
Two modes of LLM-empowered feature extraction
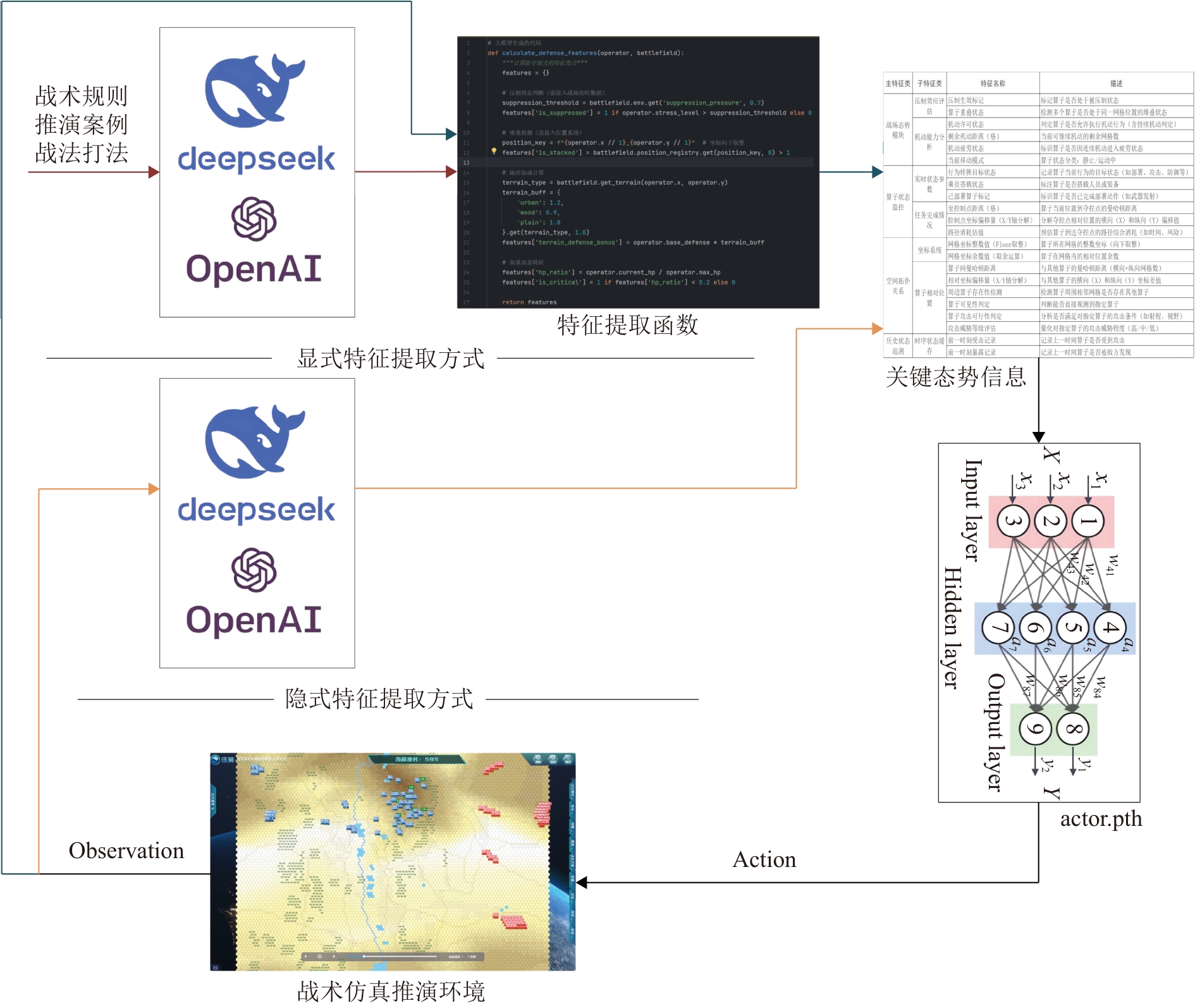
Table 8
Impact of reward function design on DRL performance
| 影响方面 | 奖励函数设计良好 | 奖励函数设计不佳 |
|---|---|---|
| 收敛性 | 策略稳定收敛至全局最优 | 无法收敛或陷入局部最优 |
| 收敛速度 | 快速学习有效战术 | 训练场次足够仍不收敛 |
| 模型性能 | 高胜率、适应复杂战场变化 | 策略僵化,易被敌方针对性击败 |
Table 9
Requirements for reward function design
| 要求 | 针对问题 | 重要性 | 实现方法 |
|---|---|---|---|
| 解决稀疏奖励问题 | 长期战术任务中关键事件信号极少 | 避免战术策略缺乏明确优化方向 | 侦察进度奖励、阶段性任务分解、战场态势熵激励 |
| 平衡多目标冲突 | 需协调火力压制、机动速度、隐蔽性等多战术目标 | 防止过度追求一个而忽视另一个 | 动态权重分配、多目标Pareto优化、硬约束 |
| 探索与利用平衡 | 平衡战术创新尝试与已验证有效战术 | 避免陷入固定战术模式被敌方预判 | 战术动作熵增奖励、未知地形探索加成、基于历史交战记录的UCT决策树 |
| 避免奖励欺骗 | Agent利用规则漏洞获取假优势 | 确保战术行为符合真实作战价值 | 因果链验证、战术意图判别器 |
| 可解释性 | 奖励逻辑需符合指挥条令且可被参谋人员审核 | 满足军事行动可追溯性要求 | 战术规则符号化编码、战场热图标注奖励来源 |
| 适应性 | 应对敌方战术变化 | 保持战术决策的动态优势 | 在线逆强化学习、基于OODA环的奖励函数在线更新 |
| 计算效率 | 满足战术级实时决策需求 | 避免延误战场时间敏感性行动 | 战术动作奖励预计算、轻量化模型 |

Fig. 9
General process steps of reward function design
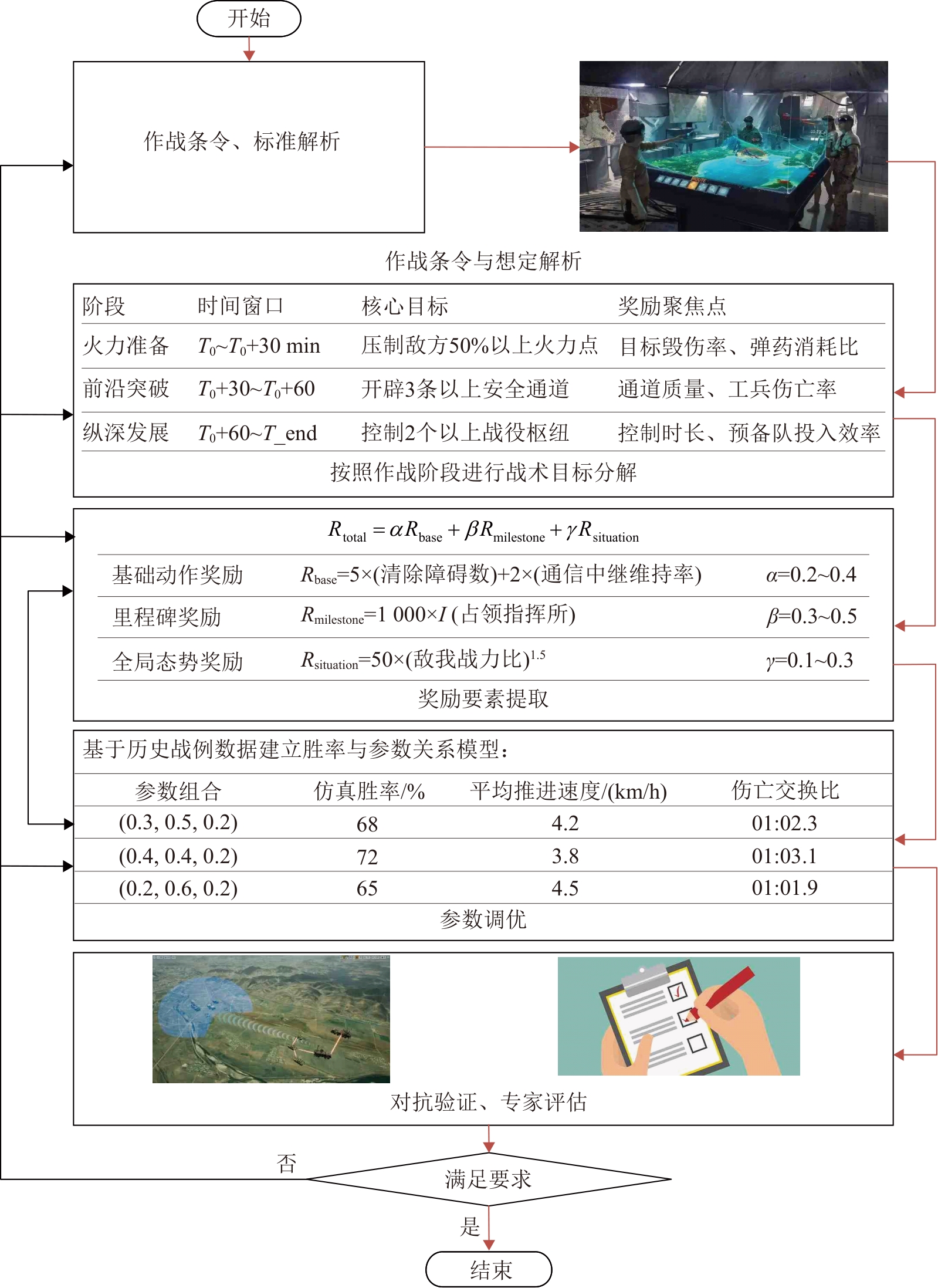
Table 10
Comparison of two modes for designing reward functions empowered by LLM
| 维度 | LLM作为奖励函数 | LLM生成奖励函数代码 |
|---|---|---|
| 工作原理 | 实时输入战场状态,输出即时奖励值 | 生成可部署的奖励计算代码(Python类/数学公式) |
| 实时性 | 低(300~2 000 ms/次) | 高(生成后代码运行≤10 ms) |
| 可解释性 | 黑箱决策,需SHAP等工具解释 | 白箱逻辑,可直接审查代码 |
| 动态适应性 | 在线微调适应新战术 | 需重新生成代码 |
| [1] | 刘大勇, 董志明, 刘倬立, 等. 大模型在陆战兵棋推演中的应用研究[C]//首届全国大模型与决策智能大会论文集. 北京: 中国指挥与控制学会, 2024: 43-53. |
| Liu Dayong, Dong Zhiming, Liu Zhuoli, et al. Research on the Application of Large Models in Army Tactical Chess Simulation[C]//Proceedings of the First National Conference on Large Models and Decision Intelligence. Beijing: Chinese Institute of Command and Control, 2024: 43-53. | |
| [2] | 贾晨星, 明月伟, 葛承垄. 基于思维模拟的虚拟指挥员作战决策模型[J]. 指挥控制与仿真, 2025, 47(1): 44-52. |
| Jia Chenxing, Ming Yuewei, Ge Chenglong. Virtual Commander's Operational Decision-making Model Based on Thinking Simulation[J]. Command Control & Simulation, 2025, 47(1): 44-52. | |
| [3] | Ji Shaoxiong, Pan Shirui, Cambria Erik, et al. A Survey on Knowledge Graphs: Representation, Acquisition, and Applications[J]. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(2): 494-514. |
| [4] | Wang Zhen, Zhang Jianwen, Feng Jianlin, et al. Knowledge Graph Embedding by Translating on Hyperplanes[C]//Proceedings of the Twenty-eighth AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2014: 1112-1119. |
| [5] | 王保魁, 吴琳, 胡晓峰, 等. 基于时序图的作战指挥行为知识表示学习方法[J]. 系统工程与电子技术, 2020, 42(11): 2520-2528. |
| Wang Baokui, Wu Lin, Hu Xiaofeng, et al. Operations Command Behavior Knowledge Representation Learning Method Based on Sequential Graph[J]. Systems Engineering and Electronics, 2020, 42(11): 2520-2528. | |
| [6] | Vinyals O, Babuschkin I, Czarnecki W M, et al. Grandmaster Level in StarCraft II Using Multi-agent Reinforcement Learning[J]. Nature, 2019, 575(7782): 350-354. |
| [7] | 刘玮, 张永亮, 程旭. 基于深度强化学习的人机智能对抗综述[J]. 指挥信息系统与技术, 2023, 14(2): 28-37. |
| Liu Wei, Zhang Yongliang, Cheng Xu. Survey of Human-Computer Intelligence Gaming Based on Deep Reinforcement Learning[J]. Command Information System and Technology, 2023, 14(2): 28-37. | |
| [8] | Shah Dhruv, Michael Robert Equi, Osiński Błażej, et al. Navigation with Large Language Models: Semantic Guesswork as a Heuristic for Planning[C]//Proceedings of The 7th Conference on Robot Learning. Atlanta: PMLR, 2023: 2683-2699. |
| [9] | Carta Thomas, Romac Clément, Wolf Thomas, et al. Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning[C]//Proceedings of the 40th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2023: 3676-3713. |
| [10] | 陈新宇, 王卫斌, 陆光辉. 基于AI agent的6G内生智能技术框架及其应用[J]. 移动通信, 2024, 48(7): 28-32. |
| Chen Xinyu, Wang Weibin, Lu Guanghui. 6G Native Intelligent Technology Framework and its Application Based on AI Agent[J]. Mobile Communications, 2024, 48(7): 28-32. | |
| [11] | 孙宇祥, 赵俊杰, 解宇轩, 等. 自生成兵棋AI: 基于大语言模型的双层Agent任务规划[J]. 控制与决策, 2024, 39(12): 3927-3936. |
| Sun Yuxiang, Zhao Junjie, Xie Yuxuan, et al. Self Generated Wargame AI:Double Layer Agent Task Planning Based on Large Language Model[J]. Control and Decision, 2024, 39(12): 3927-3936. | |
| [12] | Weng Lilian. LLM Powered Autonomous Agents[EB/OL]. (2023-06-23) [2025-04-12]. . |
| [13] | 张奇, 桂韬, 郑锐, 等. 大规模语言模型: 从理论到实践[M]. 北京: 电子工业出版社, 2024. |
| Zhang Qi, Gui Tao, Zheng Rui, et al. Large scale Language Models: From Theory to Practice[M]. Beijing: Electronic Industry Press, 2024. | |
| [14] | 高昂, 段莉, 张国辉, 等. 计算机生成兵力行为建模发展现状[J]. 计算机工程与应用, 2019, 55(19): 43-51. |
| Gao Ang, Duan Li, Zhang Guohui, et al. Development Status of Computer Generated Force Behavior Modeling[J]. Computer Engineering and Applications, 2019, 55(19): 43-51. | |
| [15] | OpenAI. GPT-4 Technical Report[EB/OL]. (2023-03-15) [2025-03-30]. . |
| [16] | DeepSeek-R 1多版本性能深度实测[EB/OL]. (2025-09-23) [2026-02-06]. . |
| DeepSeek-R1 Multi Version Performance Deep Testing[EB/OL]. (2025-09-23) [2026-02-06] . | |
| [17] | 王文君, 刘波, 王勇. 美军指挥员关键信息需求研究及启示[C]//第十二届中国指挥控制大会论文集(上册). 北京: 中国指挥与控制学会, 2024: 69-72. |
| Wang Wenjun, Liu Bo, Wang Yong. Research and Enlightenment on Critical Information Requirements for U.S. Military Commanders[C]//Proceedings of the 12th China Command and Control Conference (Vol 1). Beijing: Chinese Institute of Command and Control, 2024: 69-72. | |
| [18] | 杨杰. 面向计算机生成兵力的行为树决策模型生成方法研究[D]. 长沙: 国防科技大学, 2021. |
| Yang Jie. Research on Generation Method of Behavior Tree Decision Model for Computer Generated Forces[D]. Changsha: National University of Defense Technology, 2021. | |
| [19] | 刘小玲, 潘巨辉. FSM在海军作战仿真CGF中的应用[J]. 计算机仿真, 2007, 24(8): 24-27. |
| Liu Xiaoling, Pan Juhui. Finite State Machine and Its application to CGF of Naval Combat Simulation[J]. Computer Simulation, 2007, 24(8): 24-27. | |
| [20] | Cao Yuji, Zhao Huan, Cheng Yuheng, et al. Survey on Large Language Model-enhanced Reinforcement Learning: Concept, Taxonomy, and Methods[EB/OL]. (2024-10-30) [2025-05-23]. . |
| [1] | Xu Risheng, Yang Linyao, Qin Yuanqi, Wang Xiao, Sun Changyin. Knowledge-enhanced LLM-based Method for Regional Traffic Signal Control [J]. Journal of System Simulation, 2026, 38(2): 518-531. |
| [2] | Wang Yifan, Yang Bin, Wang Congjun. Simulation Method for Multi-crew Construction Processes Based on Large Language Model-powered Agent [J]. Journal of System Simulation, 2026, 38(2): 488-500. |
| [3] | Liu Yiqing, Zhang Qiuyang, Liu Chunyu, Xue Yao, Wei Zhiwei, Feng Yan. A Semantic Knowledge-enhanced Assessment Method for Spectrum Effectiveness of Low Earth Orbit Constellations [J]. Journal of System Simulation, 2026, 38(2): 460-475. |
| [4] | Zhang Mingxin, Wu Jinxuan, Zhu Rui, Wang Yunlong, Meng Wenjuan, Liu Zhe, Li Xu, Chen Xiaolei, Liang Yuxuan, Zheng Yi, Xue Xiangyang. Social Cognition Simulation with Large Language Model-driven Agents [J]. Journal of System Simulation, 2026, 38(2): 261-277. |
| [5] | Wang Xiang, Tan Guozhen. Research on Decision-making of Autonomous Driving in Highway Environment Based on Knowledge and Large Language Model [J]. Journal of System Simulation, 2025, 37(5): 1246-1255. |
| [6] | Teng Li, Peipei Ding, Jinfang Liu. Multi-Stage Multi-AGV Path Planning with Walk under Shelves for Robotic Mobile Fulfillment Systems [J]. Journal of System Simulation, 2022, 34(7): 1512-1523. |
| [7] | Niu Zhiqiang, Li Chaoyang, Dong Hongyu, Zhang Feng, Meng Lingyun, Tong Lu, Wu Shengnan. Analyzing dispatching wave policies for e-commerce logistics based on the multi-agent-based simulation [J]. Journal of System Simulation, 2020, 32(12): 2415-2425. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
