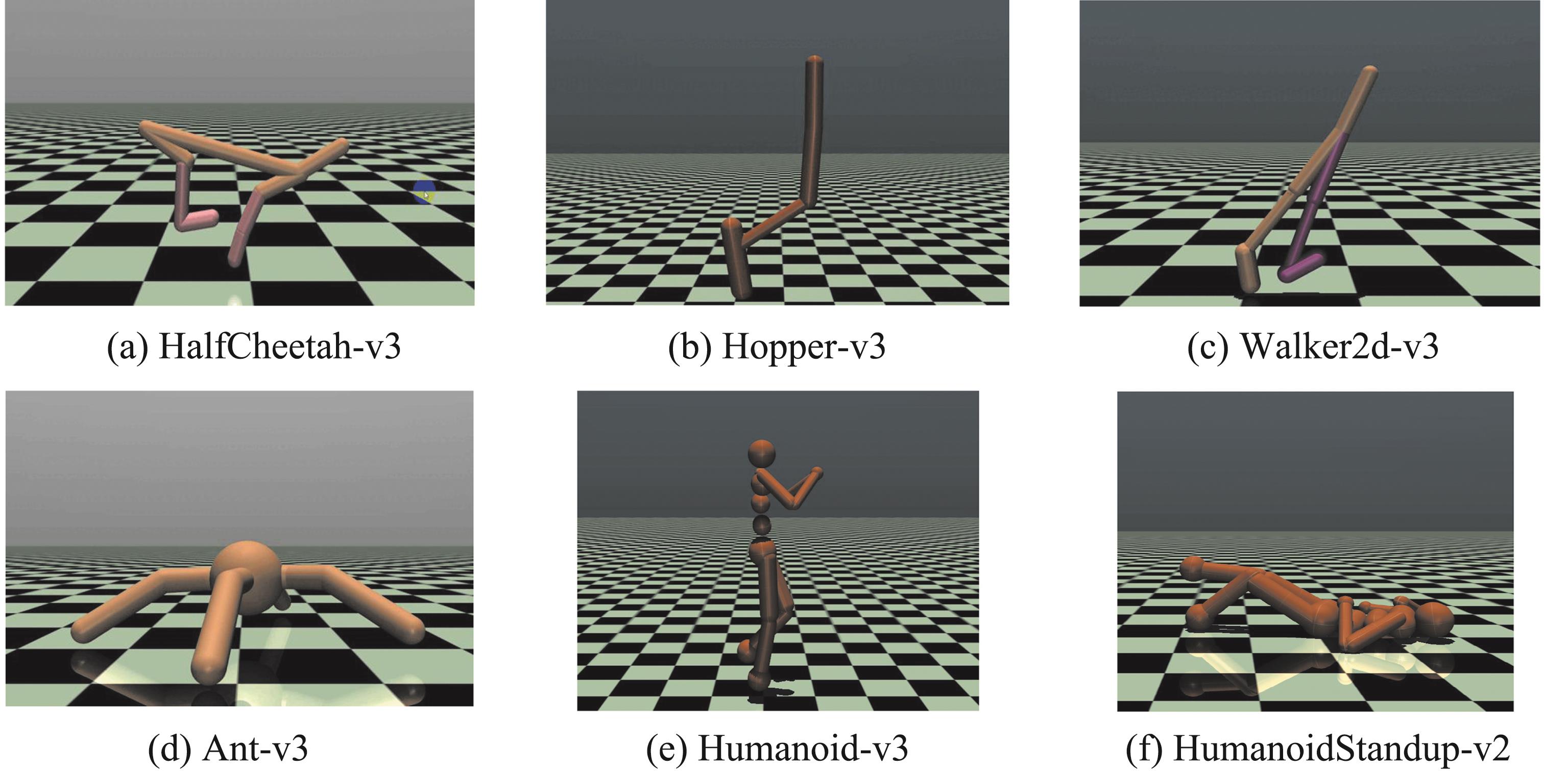
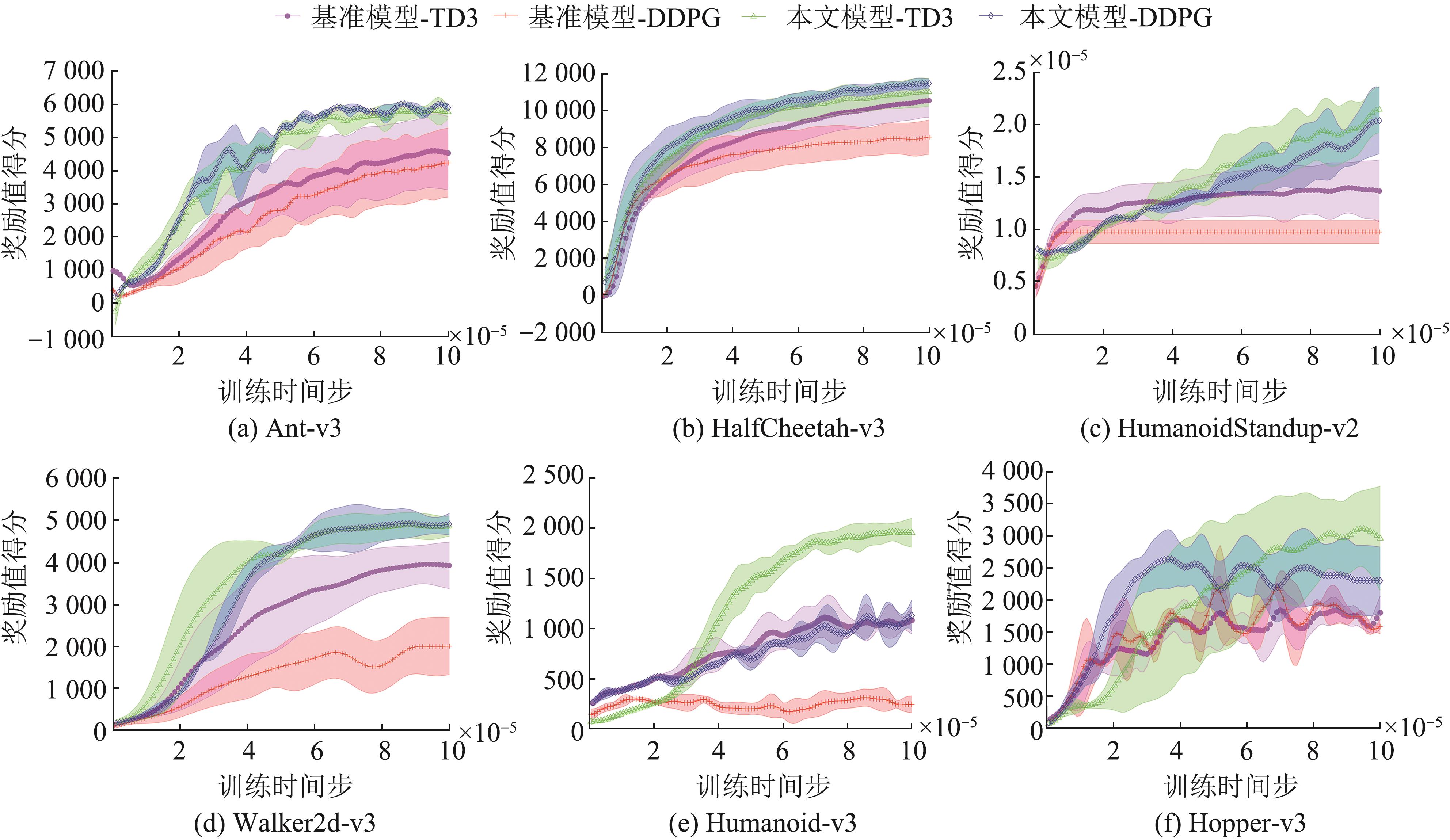
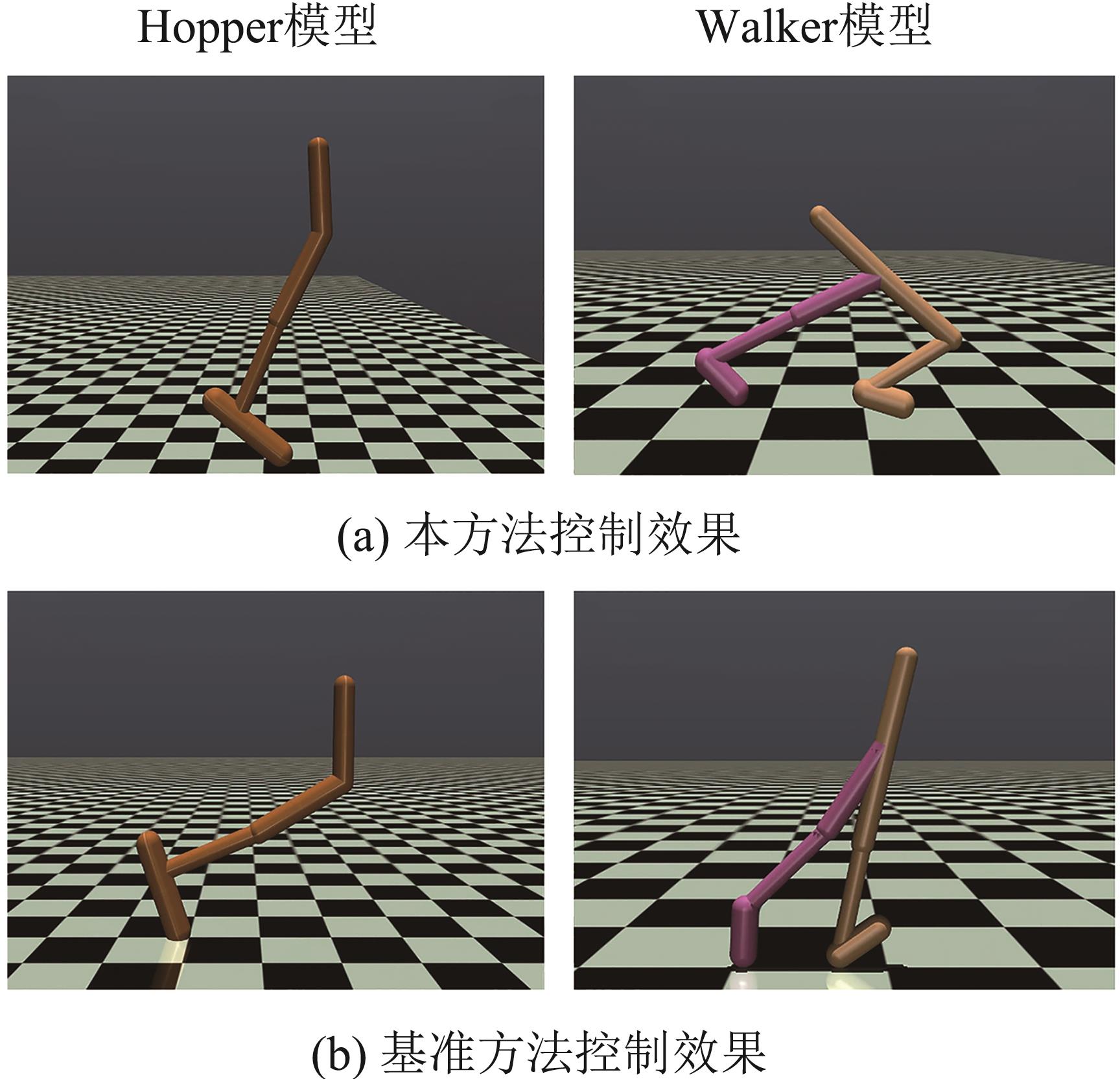
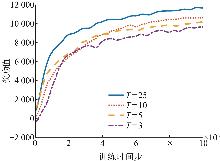
| [1] |
陈鼎, 黄杨茹, 彭佩玺, 等. 脉冲强化学习算法研究综述[J]. 计算机学报, 2023, 46(10): 2132-2160.
|
|
Chen Ding, Huang Yangru, Peng Peixi, et al. Research on Spiking Reinforcement Learning Algorithms: A Survey[J]. Chinese Journal of Computers, 2023, 46(10): 2132-2160.
|
| [2] |
苏善伟, 朱波, 向锦武, 等. 非线性非最小相位系统的控制研究综述[J]. 自动化学报, 2015, 41(1): 9-21.
|
|
Su Shanwei, Zhu Bo, Xiang Jinwu, et al. A Survey on the Control of Nonlinear Non-minimum Phase Systems[J]. Acta Automatica Sinica, 2015, 41(1): 9-21.
|
| [3] |
Nubert J, Köhler J, Berenz V, et al. Safe and Fast Tracking on a Robot Manipulator: Robust MPC and Neural Network Control[J]. IEEE Robotics and Automation Letters, 2020, 5(2): 3050-3057.
|
| [4] |
Tang Guangzhi, Kumar N, Yoo R, et al. Deep Reinforcement Learning with Population-coded Spiking Neural Network for Continuous Control[C]//Proceedings of the 2020 Conference on Robot Learning. Chia Laguna Resort: PMLR, 2021: 2016-2029.
|
| [5] |
Bing Zhenshan, Meschede Claus, Röhrbein Florian, et al. A Survey of Robotics Control Based on Learning-inspired Spiking Neural Networks[J]. Frontiers in Neurorobotics, 2018, 12: 35.
|
| [6] |
吴晓光, 刘绍维, 杨磊, 等. 基于深度强化学习的双足机器人斜坡步态控制方法[J]. 自动化学报, 2021, 47(8): 1976-1987.
|
|
Wu Xiaoguang, Liu Shaowei, Yang Lei, et al. A Gait Control Method for Biped Robot on Slope Based on Deep Reinforcement Learning[J]. Acta Automatica Sinica, 2021, 47(8): 1976-1987.
|
| [7] |
潘海南, 陈柏良, 黄开宏, 等. 基于深度强化学习的履带机器人摆臂控制方法[J]. 系统仿真学报, 2024, 36(2): 405-414.
|
|
Pan Hainan, Chen Bailiang, Huang Kaihong, et al. Flipper Control Method for Tracked Robot Based on Deep Reinforcement Learning[J]. Journal of System Simulation, 2024, 36(2): 405-414.
|
| [8] |
Tang Guangzhi, Shah A, Michmizos K P. Spiking Neural Network on Neuromorphic Hardware for Energy-efficient Unidimensional SLAM[C]//2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway: IEEE, 2019: 4176-4181.
|
| [9] |
Cao Zhiqiang, Cheng Long, Zhou Chao, et al. Spiking Neural Network-based Target Tracking Control for Autonomous Mobile Robots[J]. Neural Computing and Applications, 2015, 26(8): 1839-1847.
|
| [10] |
胡一凡, 李国齐, 吴郁杰, 等. 脉冲神经网络研究进展综述[J]. 控制与决策, 2021, 36(1): 1-26.
|
|
Hu Yifan, Li Guoqi, Wu Yujie, et al. Spiking Neural Networks a Survey on Recent Advances and New Directions[J]. Control and Decision, 2021, 36(1): 1-26.
|
| [11] |
Tang Guangzhi, Kumar N, Michmizos K P. Reinforcement Co-learning of Deep and Spiking Neural Networks for Energy-efficient Mapless Navigation with Neuromorphic Hardware[C]//2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway: IEEE, 2020: 6090-6097.
|
| [12] |
Patel D, Hazan H, Saunders D J, et al. Improved Robustness of Reinforcement Learning Policies Upon Conversion to Spiking Neuronal Network Platforms Applied to Atari Breakout Game[J]. Neural Networks, 2019, 120: 108-115.
|
| [13] |
Spüler Martin, Nagel Sebastian, Rosenstiel Wolfgang. A Spiking Neuronal Model Learning a Motor Control Task by Reinforcement Learning and Structural Synaptic Plasticity[C]//2015 International Joint Conference on Neural Networks (IJCNN). Piscataway: IEEE, 2015: 1-8.
|
| [14] |
Bing Zhenshan, Meschede Claus, Huang Kai, et al. End to End Learning of Spiking Neural Network Based on R-STDP for a Lane Keeping Vehicle[C]//2018 IEEE International Conference on Robotics and Automation (ICRA). Piscataway: IEEE, 2018: 4725-4732.
|
| [15] |
Mahadevuni A, Li Peng. Navigating Mobile Robots to Target in Near Shortest Time Using Reinforcement Learning with Spiking Neural Networks[C]//2017 International Joint Conference on Neural Networks (IJCNN). Piscataway: IEEE, 2017: 2243-2250.
|
| [16] |
Bing Zhenshan, Jiang Zhuangyi, Cheng Long, et al. End to End Learning of a Multi-layered Snn Based on R-stdp for a Target Tracking Snake-like Robot[C]//2019 International Conference on Robotics and Automation (ICRA). Piscataway: IEEE, 2019: 9645-9651.
|
| [17] |
Liu Junxiu, Lu Hao, Luo Yuling, et al. Spiking Neural Network-based Multi-task Autonomous Learning for Mobile Robots[J]. Engineering Applications of Artificial Intelligence, 2021, 104: 104362.
|
| [18] |
Guo Yufei, Chen Yuanpei, Zhang Liwen, et al. IM-loss: Information Maximization Loss for Spiking Neural Networks[C]//Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 156-166.
|
| [19] |
Averbeck B B, Latham P E, Pouget A. Neural Correlations, Population Coding and Computation[J]. Nature Reviews Neuroscience, 2006, 7(5): 358-366.
|
| [20] |
Tkačik Gašper, Prentice J S, Balasubramanian V, et al. Optimal Population Coding by Noisy Spiking Neurons[J]. Proceedings of the National Academy of Sciences, 2010, 107(32): 14419-14424.
|
| [21] |
Pan Zihan, Wu Jibin, Zhang Malu, et al. Neural Population Coding for Effective Temporal Classification[C]//2019 International Joint Conference on Neural Networks (IJCNN). Piscataway: IEEE, 2019: 1-8.
|
| [22] |
Dayan P, Abbott L. Computational Neuroscience: Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems[M]. Cambridge: MIT Press, 2001: 162-166.
|
| [23] |
Wu Yujie, Deng Lei, Li Guoqi, et al. Spatio-temporal Backpropagation for Training High-performance Spiking Neural Networks[J]. Frontiers in Neuroscience, 2018, 12: 331.
|
| [24] |
Brockman G, Cheung V, Pettersson L, et al. OpenAI Gym[EB/OL]. (2016-06-05) [2024-04-11]. .
|
| [25] |
Todorov E, Erez T, Tassa Y. MuJoCo: A Physics Engine for Model-based Control[C]//2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2012: 5026-5033.
|
| [26] |
Raffin Antonin, Hill Ashley, Gleave Adam, et al. Stable-Baselines3: Reliable Reinforcement Learning Implementations[J]. Journal of Machine Learning Research, 2021, 22: 1-8.
|
| [27] |
董豪, 杨静, 李少波, 等. 基于深度强化学习的机器人运动控制研究进展[J]. 控制与决策, 2022, 37(2): 278-292.
|
|
Dong Hao, Yang Jing, Li Shaobo, et al. Research Progress of Robot Motion Control Based on Deep Reinforcement Learning[J]. Control and Decision, 2022, 37(2): 278-292.
|
| [28] |
Dankwa S, Zheng Wenfeng. Twin-delayed DDPG: A Deep Reinforcement Learning Technique to Model a Continuous Movement of an Intelligent Robot Agent[C]//Proceedings of the 3rd International Conference on Vision, Image and Signal Processing. New York: ACM, 2020: 1-5.
|
| [29] |
Fujimoto S, Hoof H, Meger D. Addressing Function Approximation Error in Actor-critic Methods[C]//Proceedings of the 35th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2018: 1587-1596.
|
| [30] |
Guo Yufei, Tong Xinyi, Chen Yuanpei, et al. RecDis-SNN: Rectifying Membrane Potential Distribution for Directly Training Spiking Neural Networks[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2022: 326-335.
|