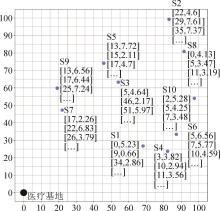
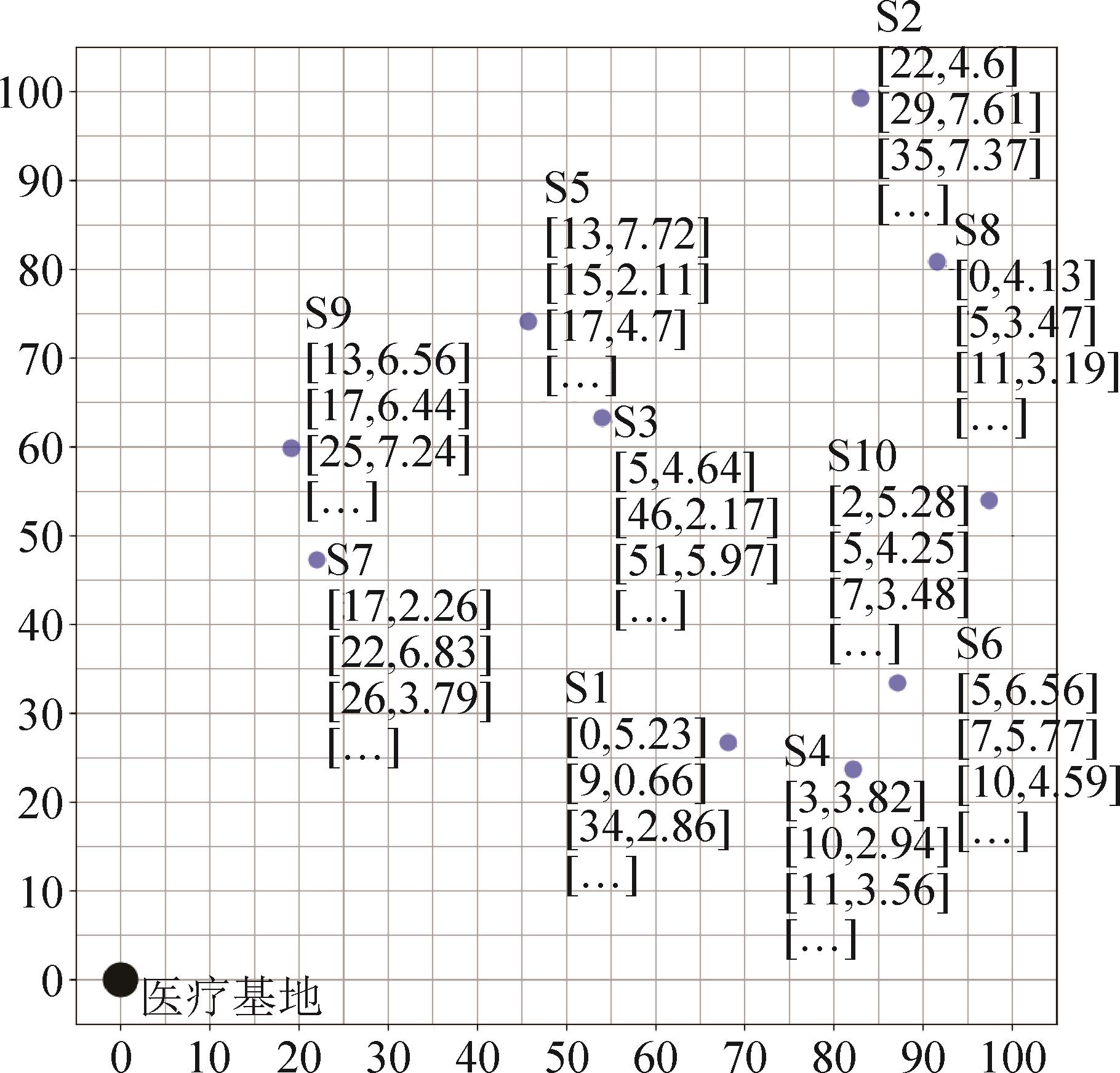
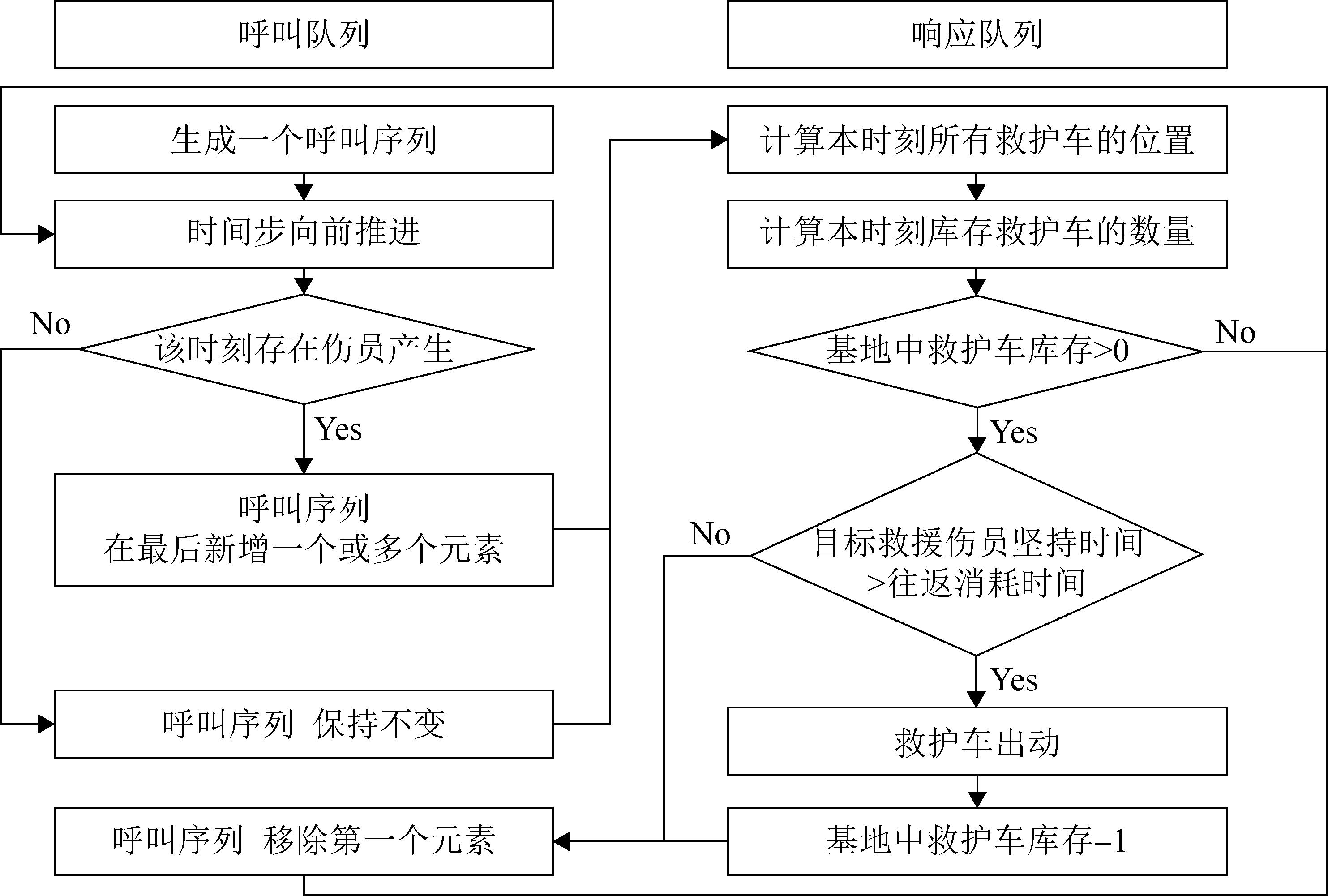
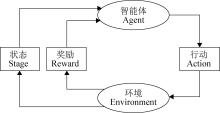
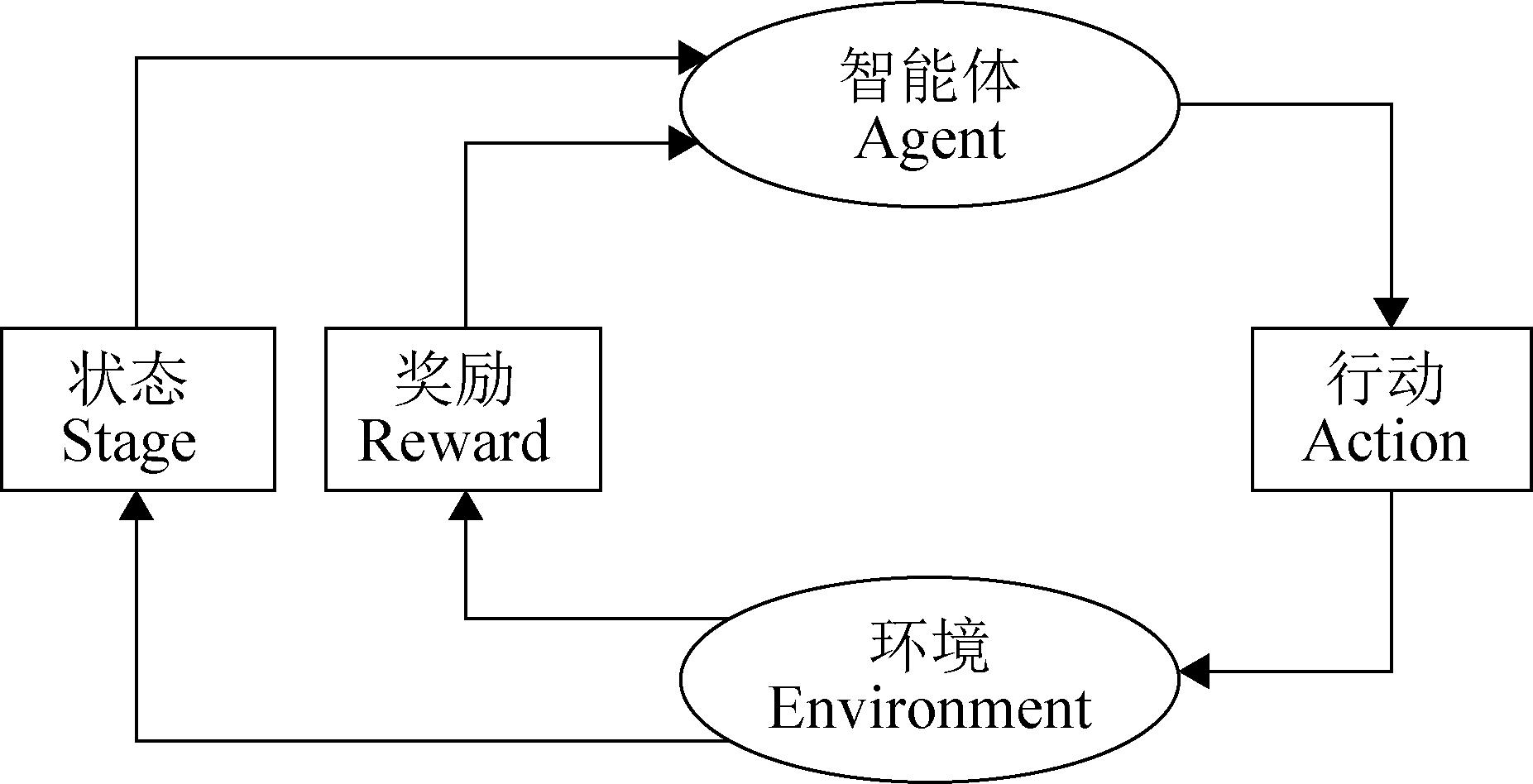
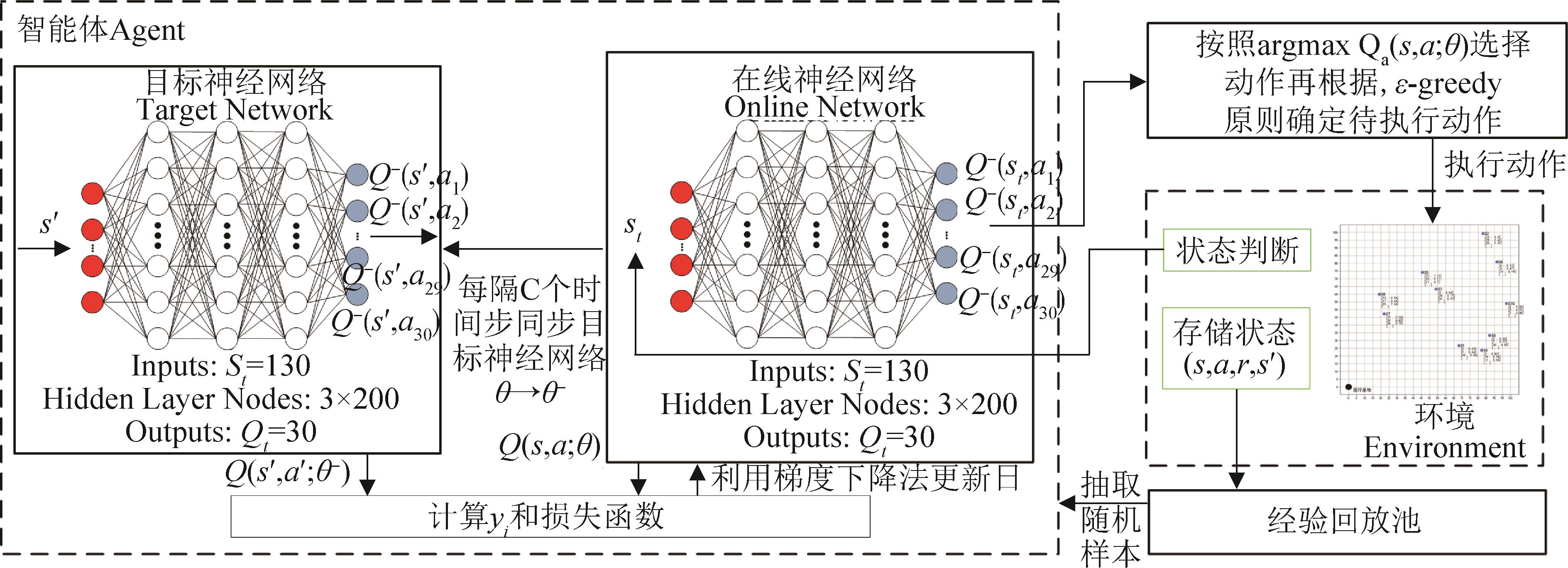
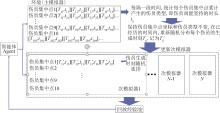
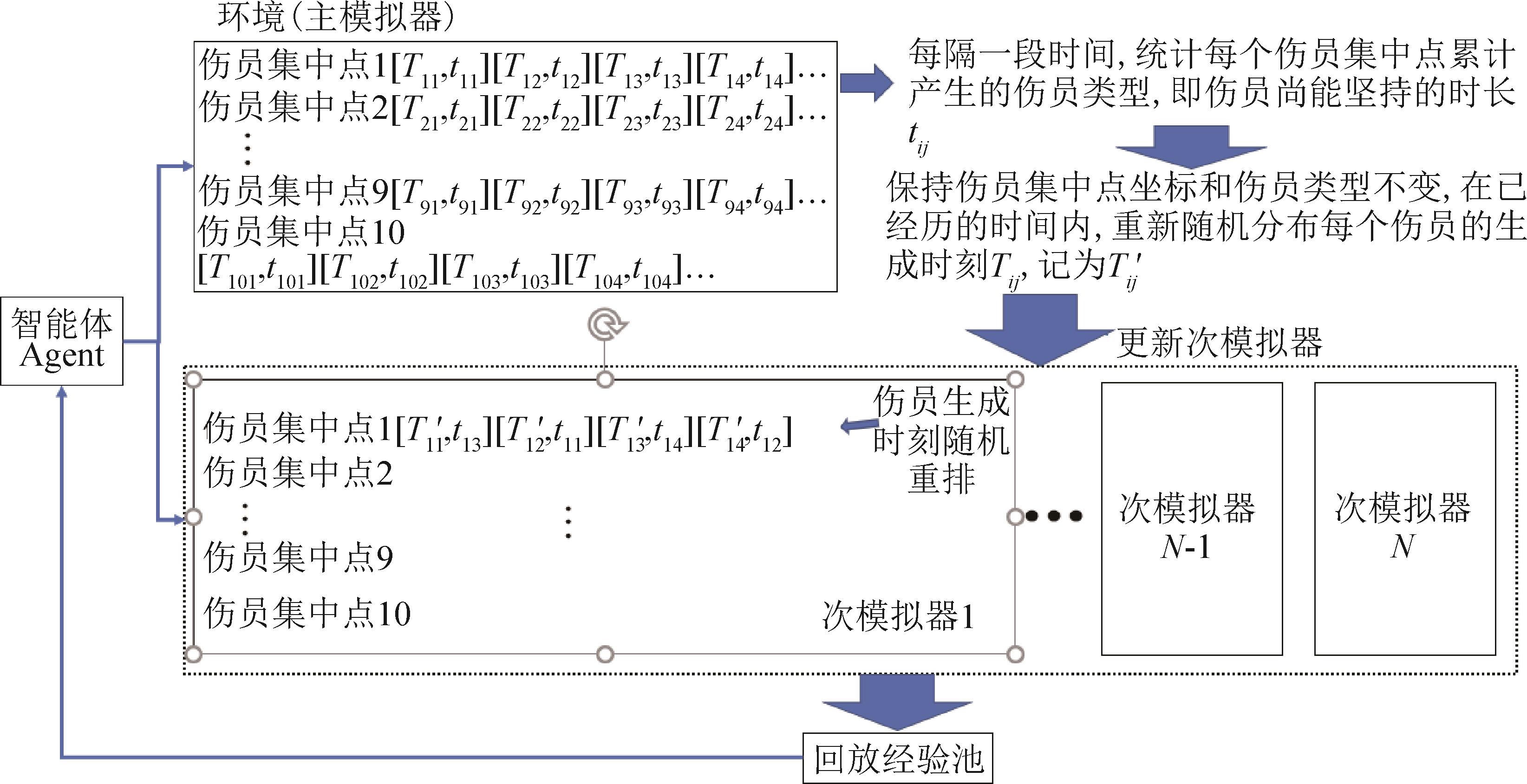
| 1 |
吴瑶. 城市突发公共事件伤员救治出救点选择与车辆路径集成优化研究[D]. 成都: 西南交通大学, 2011.
|
|
Wu Yao. Integrated Optimization of Depot Selection and Vehicle Routing for Treatment of the Wounded in Urban Public Emergencies[D]. Chengdu: Southwest Jiaotong University, 2011.
|
| 2 |
刘旭. 抗震救灾医疗后送系统实证与建模研究[D]. 上海: 第二军医大学, 2012.
|
|
Liu Xu. Empirical Study and Modeling of Medical Evacuation System following a Major Earthquake[D]. Shanghai: The Second Military Medical University, 2012.
|
| 3 |
范文璟. 城市突发公共事件应急资源调配中出救点选择与救援车辆路径的集成优化研究[D]. 成都: 西南交通大学, 2011.
|
|
Fan Wenjing. Integrated Optimization of Depot Selection and Vehicle Routing for Relief Resource Distribution in Urban Public Emergencies[D]. Chengdu: Southwest Jiaotong University, 2011.
|
| 4 |
马祖军, 胡萍. 实时/时变路网环境下城市出救点选择与救援车辆路径的集成动态优化[J]. 管理工程学报, 2014, 28(4): 165-172.
|
|
Ma Zujun, Hu Ping. Dynamic Optimization of Combined Emergency Response Facility Selection and Vehicle Routing Problem in Real-time and Time-dependent Road Networks in Urban Environments[J]. Journal of Industrial Engineering and Engineering Management, 2014, 28(4): 165-172.
|
| 5 |
Topcuoglu H, Hariri S, Wu Minyou. Performance-effective and Low-complexity Task Scheduling for Heterogeneous Computing[J]. IEEE Transactions on Parallel and Distributed Systems, 2002, 13(3): 260-274.
|
| 6 |
Pan Quanke, Mehmet Fatih Tasgetiren, Liang Y C. A Discrete Differential Evolution Algorithm for the Permutation Flowshop Scheduling Problem[J]. Computers & Industrial Engineering, 2008, 55(4): 795-816.
|
| 7 |
Lancaster J, Ozbayrak Mustafa. Evolutionary Algorithms Applied to Project Scheduling Problems-a Survey of the State-of-the-art[J]. International Journal of Production Research, 2007, 45(2): 425-450.
|
| 8 |
Gen Mitsuo, Lin Lin. Multiobjective Evolutionary Algorithm for Manufacturing Scheduling Problems: State-of-the-art Survey[J]. Journal of Intelligent Manufacturing, 2014, 25(5): 849-866.
|
| 9 |
Klanke Christian, Engell Sebastian. Scheduling and Batching with Evolutionary Algorithms in Simulation-optimization of an Industrial Formulation Plant[J]. Computers & Industrial Engineering, 2022, 174: 108760.
|
| 10 |
Luo Shu, Zhang Linxuan, Fan Yushun. Dynamic Multi-objective Scheduling for Flexible Job Shop by Deep Reinforcement Learning[J]. Computers & Industrial Engineering, 2021, 159: 107489.
|
| 11 |
Yang Shengluo, Wang Junyi, Xu Zhigang. Real-time Scheduling for Distributed Permutation Flowshops with Dynamic Job Arrivals Using Deep Reinforcement Learning[J]. Advanced Engineering Informatics, 2022, 54: 101776.
|
| 12 |
侯力玮. 面向玻璃基板卸片操作的机械臂在线学习控制研究[D]. 长沙: 中南大学, 2022.
|
|
Hou Liwei. Research on Online Learning Control of Manipulator for Peeling of Glass Substrate[D]. Changsha: Central South University, 2022.
|
| 13 |
高梦琦, 冯翔, 虞慧群, 等. 基于在线学习稀疏特征的大规模多目标进化算法[J]. 计算机科学, 2024, 51(3): 56-62.
|
|
Gao Mengqi, Feng Xiang, Yu Huiqun, et al. Large-scale Multi-objective Evolutionary Algorithm Based on Online Learning of Sparse Features[J]. Computer Science, 2024, 51(3): 56-62.
|
| 14 |
杨光. 基于稀疏表征的在线强化学习研究[D]. 南京: 南京邮电大学, 2020.
|
|
Yang Guang. Research on Online Reinforcement Learning Based on Sparse Representation[D]. Nanjing: Nanjing University of Posts and Telecommunications, 2020.
|
| 15 |
王海蛟. 基于强化学习的卫星规模化在线调度方法研究[D]. 北京: 中国科学院大学, 2018.
|
|
Wang Haijiao. Massive Scheduling Method Under Online Situation for Satellites Based on Reinforcement Learning[D]. Beijing: University of Chinese Academy of Sciences, 2018.
|
| 16 |
孙正伦, 乔鹏, 窦勇, 等. 面向执行-学习者的在线强化学习并行训练方法[J]. 计算机学报, 2023, 46(2): 229-243.
|
|
Sun Zhenglun, Qiao Peng, Dou Yong, et al. PALA: Parallel Actor-learner Architecture for Distributed Deep Reinforcement Learning[J]. Chinese Journal of Computers, 2023, 46(2): 229-243.
|
| 17 |
马佩鑫. 未知环境下基于深度强化学习的多机器人自主探索[D]. 杭州: 浙江理工大学, 2023.
|
|
Ma Peixin. Multi-robot Autonomous Exploration in Unknown Environment via Deep Reinforcement Learning[D]. Hangzhou: Zhejiang Sci-Tech University, 2023.
|
| 18 |
Li Haoran, Zhang Qichao, Zhao Dongbin. Deep Reinforcement Learning-based Automatic Exploration for Navigation in Unknown Environment[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(6): 2064-2076.
|