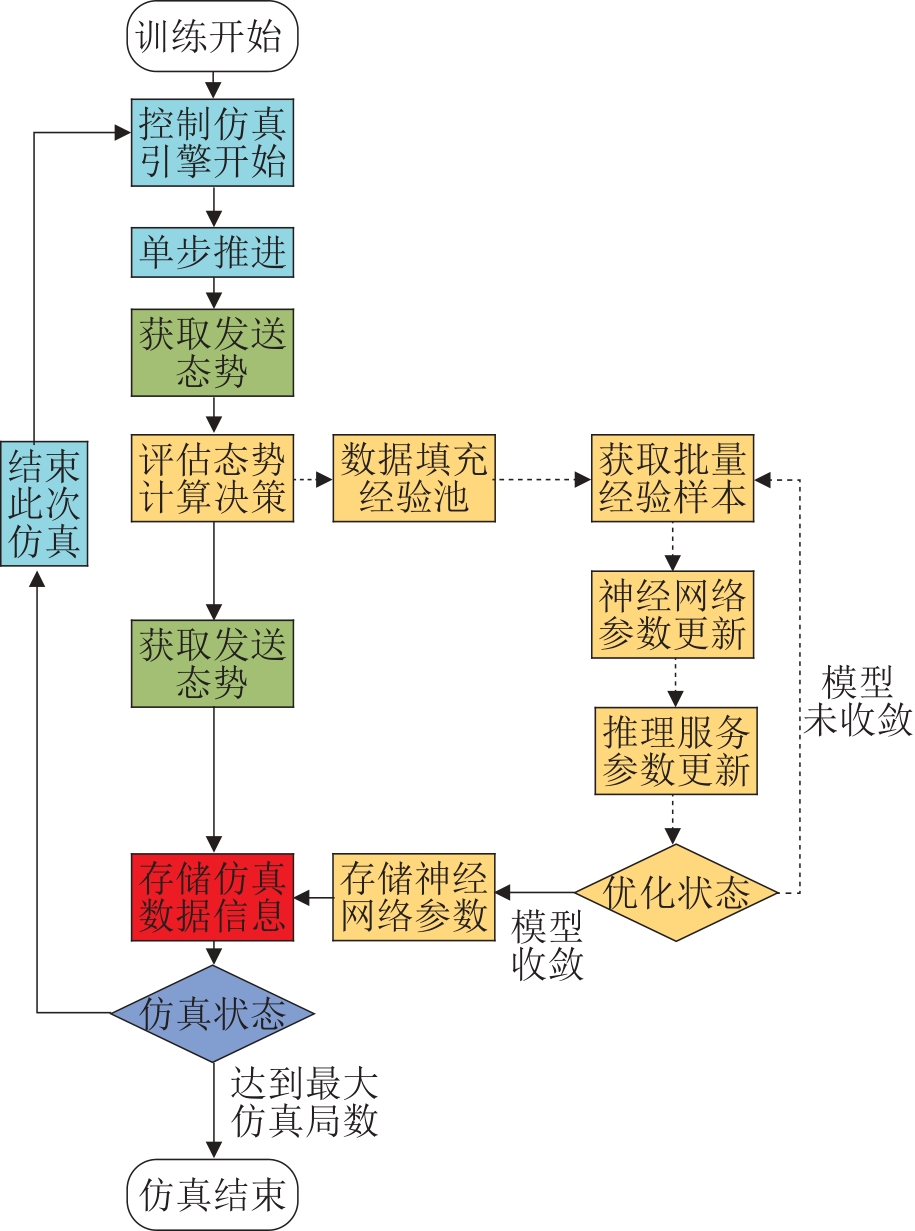
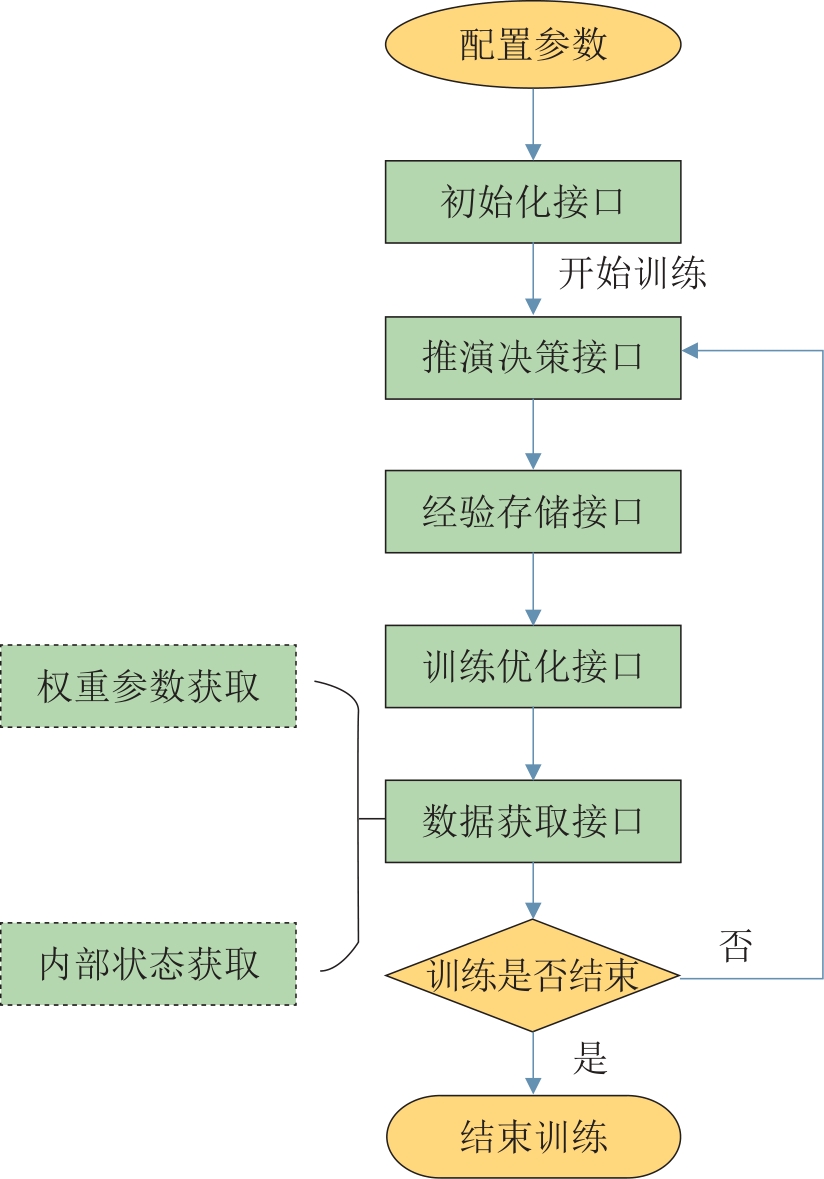
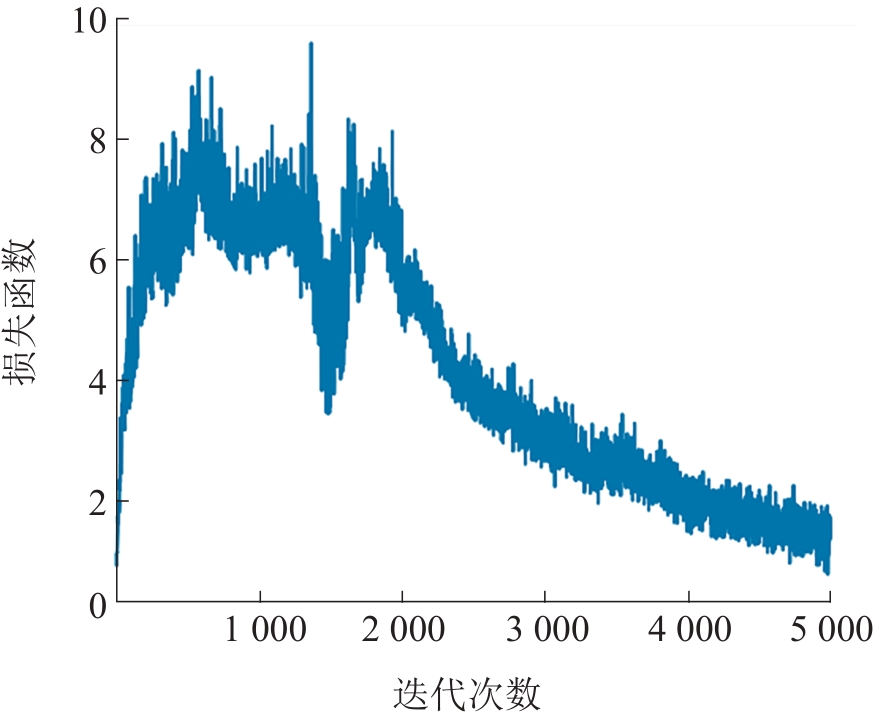
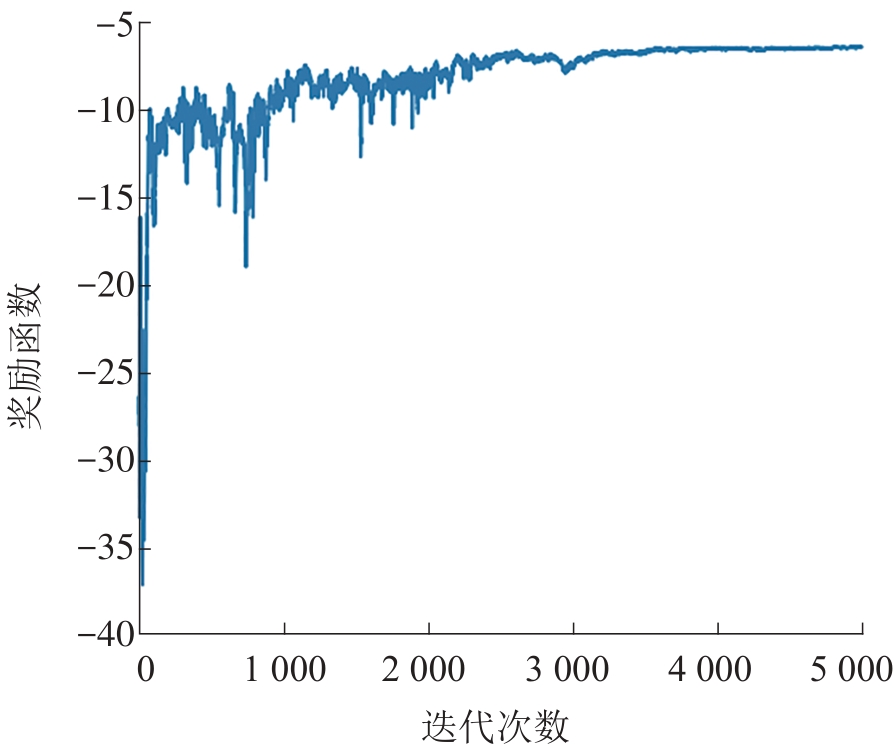
| 1 |
邹启杰, 蒋亚军, 高兵, 等. 协作多智能体深度强化学习研究综述[J]. 航空兵器, 2022, 29(6): 78-88.
|
|
Zou Qijie, Jiang Yajun, Gao Bing, et al. An Overview of Cooperative Multi-agent Deep Reinforcement Learning[J]. Aero Weaponry, 2022, 29(6): 78-88.
|
| 2 |
Christiano P F, Leike J, Brown T W, et al. Deep Reinforcement Learning from Human Preferences[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2017: 4302-4310.
|
| 3 |
Brockman G, Cheung V, Pettersson L, et al. OpenAI Gym[EB/OL]. (2016-06-05) [2023-05-21]. .
|
| 4 |
Alibaba. Gym StarCraft[EB/OL]. [2023-05-16]. .
|
| 5 |
周亮, 王震, 王冠. 远程过程调用技术在分布式软件系统中的应用[J]. 航空电子技术, 2020, 51(4): 47-52.
|
|
Zhou Liang, Wang Zhen, Wang Guan. Application of Remote Procedure Calling Technology in Distributed Software System[J]. Avionics Technology, 2020, 51(4): 47-52.
|
| 6 |
张红杰. 深度强化学习训练与推理的性能优化[D]. 合肥: 中国科学技术大学, 2021.
|
|
Zhang Hongjie. Performance Optimization of Training and Inference of Deep Reinforcement Learning[D]. Hefei: University of Science and Technology of China, 2021.
|
| 7 |
Abadi Martín, Agarwal A, Barham P, et al. TensorFlow: Large-scale Machine Learning on Heterogeneous Distributed Systems[EB/OL]. (2016-03-16) [2023-04-23]. .
|
| 8 |
Lowe R, Wu Yi, Tamar A, et al. Multi-agent Actor-critic for Mixed Cooperative-competitive Environments[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2017, 30: 6382-6393.
|
| 9 |
Konda V R, Tsitsiklis J N. Actor-critic Algorithms[C]//Advances in Neural Information Processing Systems. Cambridge: MIT Press, 2000: 1008-1014.
|
| 10 |
Terry J, Black B, Grammel N, et al. PettingZoo: Gym for Multi-agent Reinforcement Learning[C]//Advances in Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates, Inc., 2021: 15032-15043.
|
| 11 |
王壮, 艾毅, 文旭光, 等. 航空器智能引导机动决策奖励重塑方法[J]. 科学技术与工程, 2023, 23(8): 3535-3543.
|
|
Wang Zhuang, Ai Yi, Wen Xuguang, et al. Reward Shaping for Intelligent Maneuver Decision Generation in Aircraft Guidance[J]. Science Technology and Engineering, 2023, 23(8): 3535-3543.
|
 ), 陈智杰1, 郭子铭2, 李妮1(
), 陈智杰1, 郭子铭2, 李妮1(