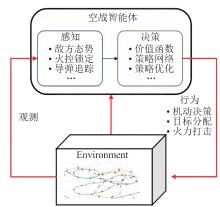
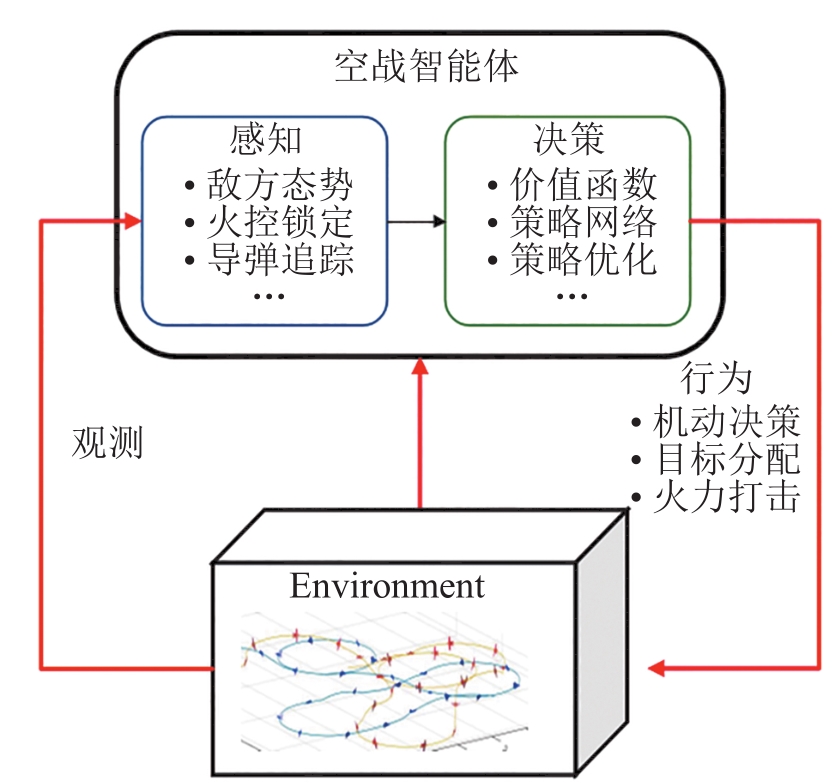
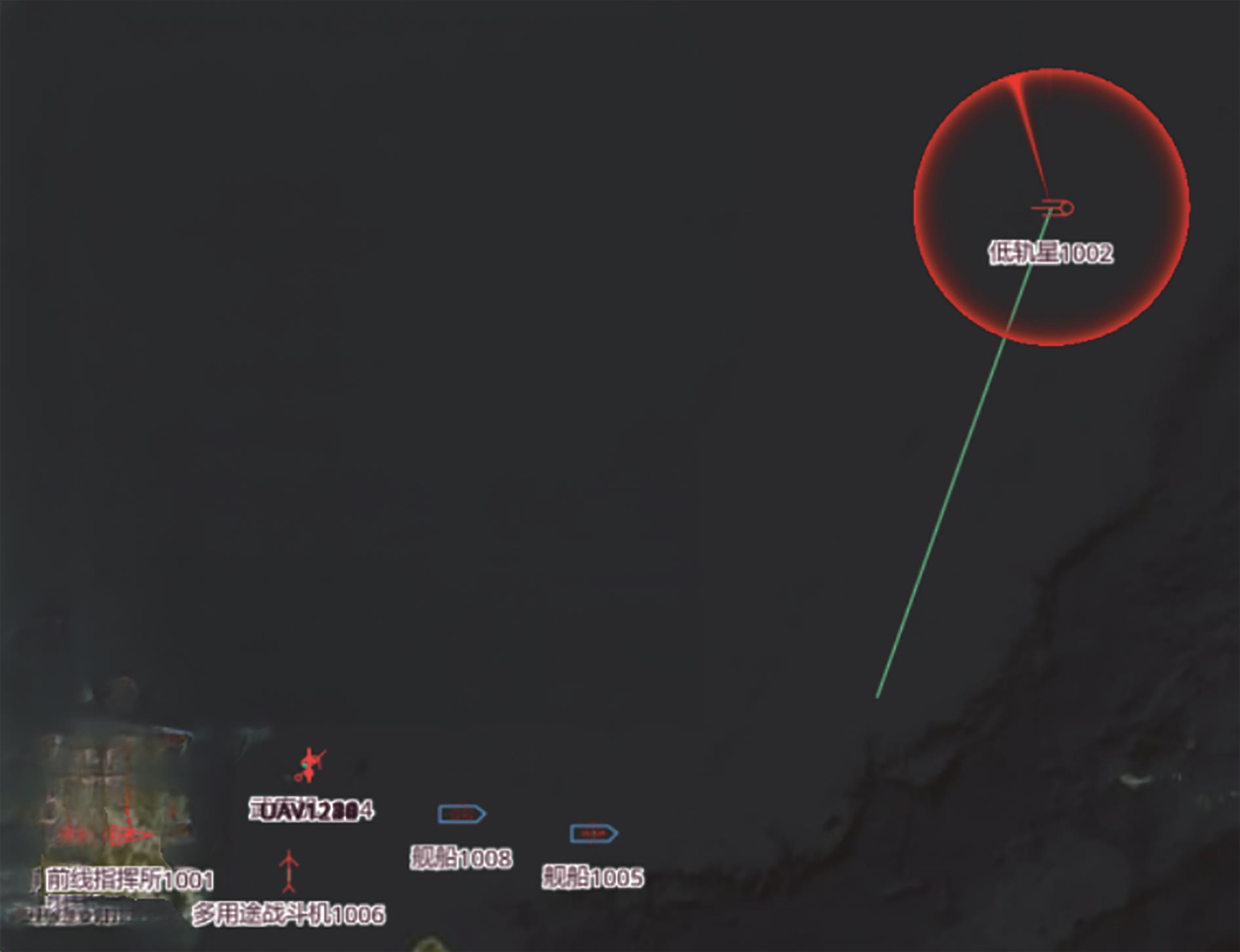
| 1 |
Holcomb S D, Porter W K, Ault S V, et al. Overview on DeepMind and Its AlphaGo Zero AI[C]//Proceedings of the 2018 International Conference on Big Data and Education. New York, NY, USA: Association for Computing Machinery, 2018: 67-71.
|
| 2 |
Arulkumaran K, Cully A, Togelius J. AlphaStar: an Evolutionary Computation Perspective[C]//Proceedings of the Genetic and Evolutionary Computation Conference Companion. New York, NY, USA: Association for Computing Machinery, 2019: 314-315.
|
| 3 |
Berner C, Brockman G, Chan B, et al. Dota 2 With Large Scale Deep Reinforcement Learning[EB/OL]. (2019-12-13) [2023-05-10]. .
|
| 4 |
杨惟轶, 白辰甲, 蔡超, 等. 深度强化学习中稀疏奖励问题研究综述[J]. 计算机科学, 2020, 47(3): 182-191.
|
|
Yang Weiyi, Bai Chenjia, Cai Chao, et al. Survey on Sparse Reward in Deep Reinforcement Learning[J]. Computer Science, 2020, 47(3): 182-191.
|
| 5 |
Chen G. A New Framework for Multi-agent Reinforcement Learning-centralized Training and Exploration With Decentralized Execution via Policy Distillation[EB/OL]. (2019-10-21) [2022-11-02]. .
|
| 6 |
Lowe R, Wu Yi, Tamar A, et al. Multi-agent Actor-critic for Mixed Cooperative-competitive Environments[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2017: 6382-6393.
|
| 7 |
Marthi B. Automatic Shaping and Decomposition of Reward Functions[C]//Proceedings of the 24th International Conference on Machine learning. New York, NY, USA: Association for Computing Machinery, 2007: 601-608.
|
| 8 |
Chen Jiayu, Zhang Yuanxin, Xu Yuanfan, et al. Variational Automatic Curriculum Learning for Sparse-reward Cooperative Multi-agent Problems[C]//35th Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2021, 34: 9681-9693.
|
| 9 |
Hu Yujing, Wang Weixun, Jia Hangtian, et al. Learning to Utilize Shaping Rewards: A New Approach of Reward Shaping[C]//34th Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2020: 15931-15941.
|
| 10 |
Zhelo O, Zhang Jingwei, Tai Lei, et al. Curiosity-driven Exploration for Mapless Navigation With Deep Reinforcement Learning[EB/OL]. (2018-05-14) [2023-06-21]. .
|
| 11 |
Wang Xin, Chen Yudong, Zhu Wenwu. A Survey on Curriculum Learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(9): 4555-4576.
|
| 12 |
Hutsebaut-Buysse M, Mets K, Latré S. Hierarchical Reinforcement Learning: A Survey and Open Research Challenges[J]. Machine Learning & Knowledge Extraction, 2022, 4(1): 172-221.
|
| 13 |
周攀, 黄江涛, 章胜, 等. 基于深度强化学习的智能空战决策与仿真[J]. 航空学报, 2023, 44(4): 94-107.
|
|
Zhou Pan, Huang Jiangtao, Zhang Sheng, et al. Intelligent Air Combat Decision Making and Simulation Based on Deep Reinforcement Learning[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(4): 94-107.
|
| 14 |
李永丰, 史静平, 章卫国, 等. 深度强化学习的无人作战飞机空战机动决策[J]. 哈尔滨工业大学学报, 2021, 53(12): 33-41.
|
|
Li Yongfeng, Shi Jingping, Zhang Weiguo, et al. Maneuver Decision of UCAV in Air Combat Based on Deep Reinforcement Learning[J]. Journal of Harbin Institute of Technology, 2021, 53(12): 33-41.
|
| 15 |
Wang Zhuang, Li Hui, Wu Haolin, et al. Improving Maneuver Strategy in Air Combat by Alternate Freeze Games With a Deep Reinforcement Learning Algorithm[J]. Mathematical Problems in Engineering, 2020, 2020: 7180639.
|
| 16 |
章胜, 杜昕, 肖娟, 等. 基于深度强化学习的固定翼飞行器六自由度飞行智能控制[J]. 指挥与控制学报, 2022, 8(2): 179-188.
|
|
Zhang Sheng, Du Xin, Xiao Juan, et al. Fixed-wing Aircraft 6-DOF Flight Control Based on Deep Reinforcement Learning[J]. Journal of Command and Control, 2022, 8(2): 179-188.
|
| 17 |
孙智孝, 杨晟琦, 朴海音, 等. 未来智能空战发展综述[J]. 航空学报, 2021, 42(8): 28-42.
|
|
Sun Zhixiao, Yang Shengqi, Haiyin Piao, et al. A Survey of Air Combat Artificial Intelligence[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(8): 28-42.
|
| 18 |
Tashev B, Purcell M, McLaughlin B. Russia's Information Warfare: Exploring the Cognitive Dimension[J]. MCU Journal, 2019, 10(2): 129-147.
|
| 19 |
Hamfelt A, Karlsson M, Thierfelder T, et al. Beyond K-means: Clusters Identification for GIS[M]//Popovich V V, Claramunt C, Devogele T, et al. Information Fusion and Geographic Information Systems: Towards the Digital Ocean. Berlin, Heidelberg: Springer Berlin Heidelberg, 2011: 93-105.
|
| 20 |
Rashid T, Farquhar G, Peng Bei, et al. Weighted QMIX: Expanding Monotonic Value Function Factorisation for Deep Multi-agent Reinforcement Learning[C]//34th Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2020: 10199-10210.
|
 ), 王泽, 董力维, 李妮(
), 王泽, 董力维, 李妮(