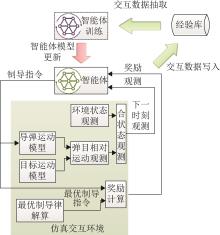
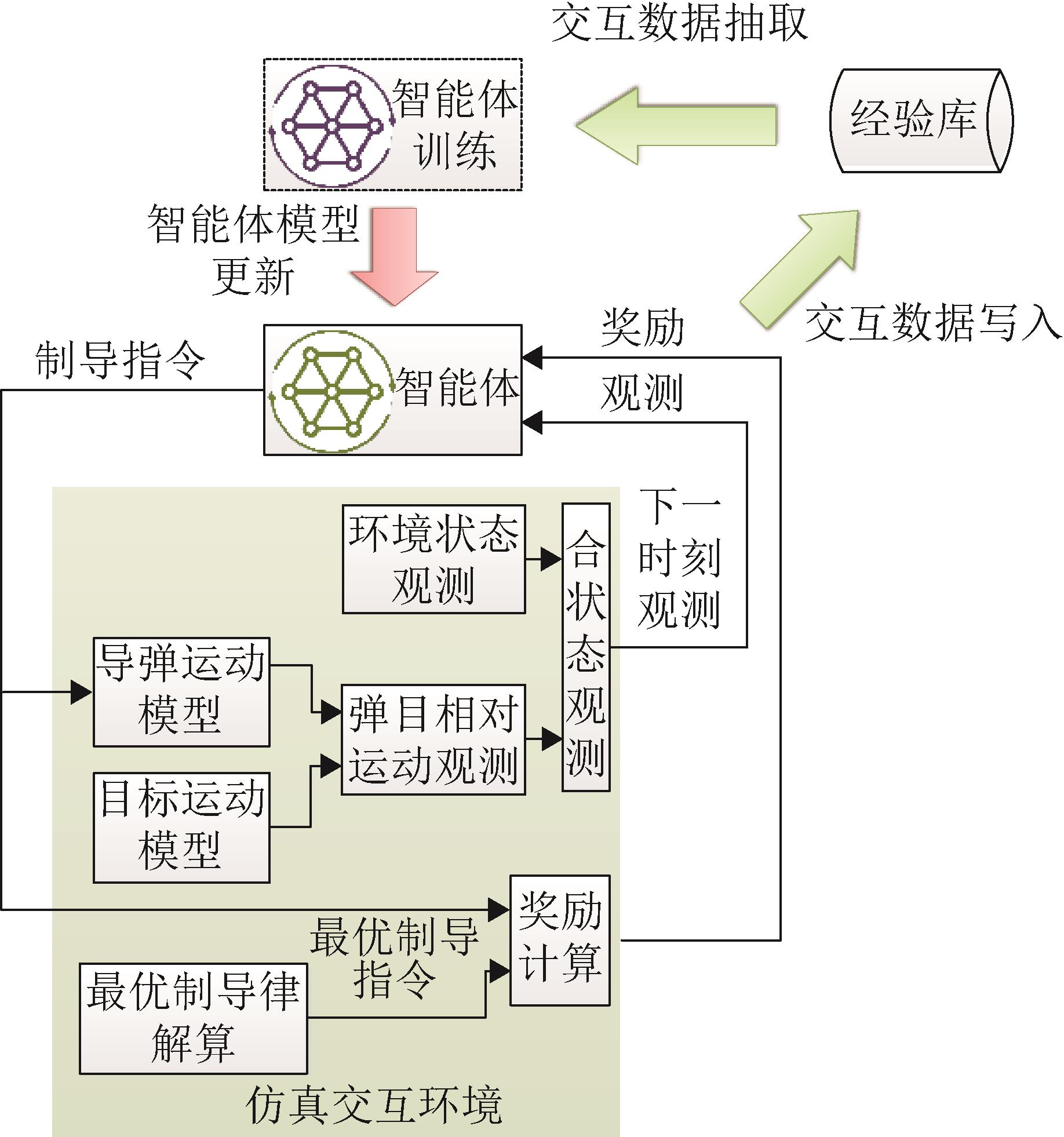
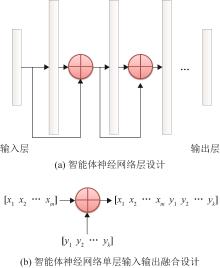
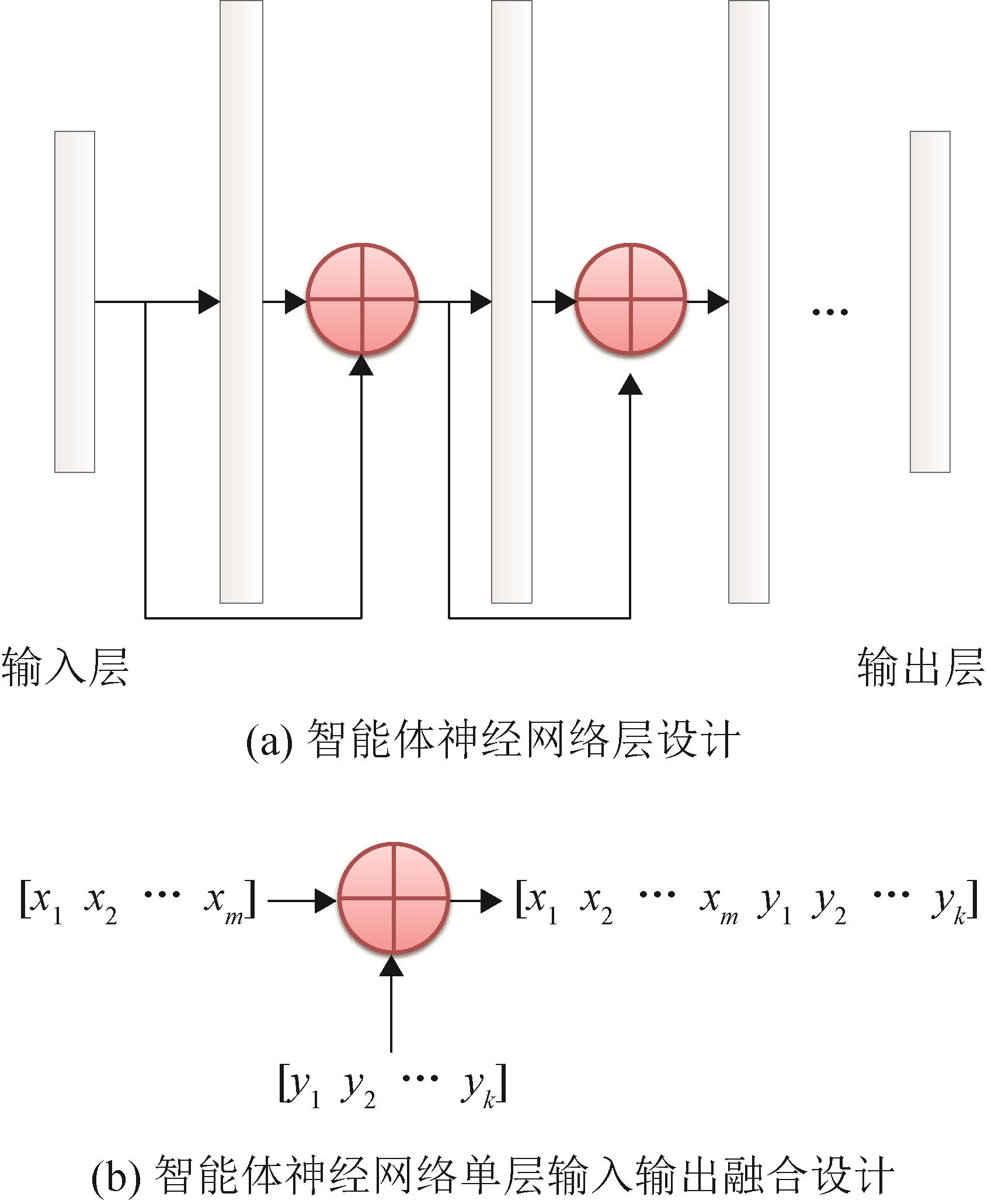
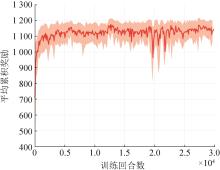
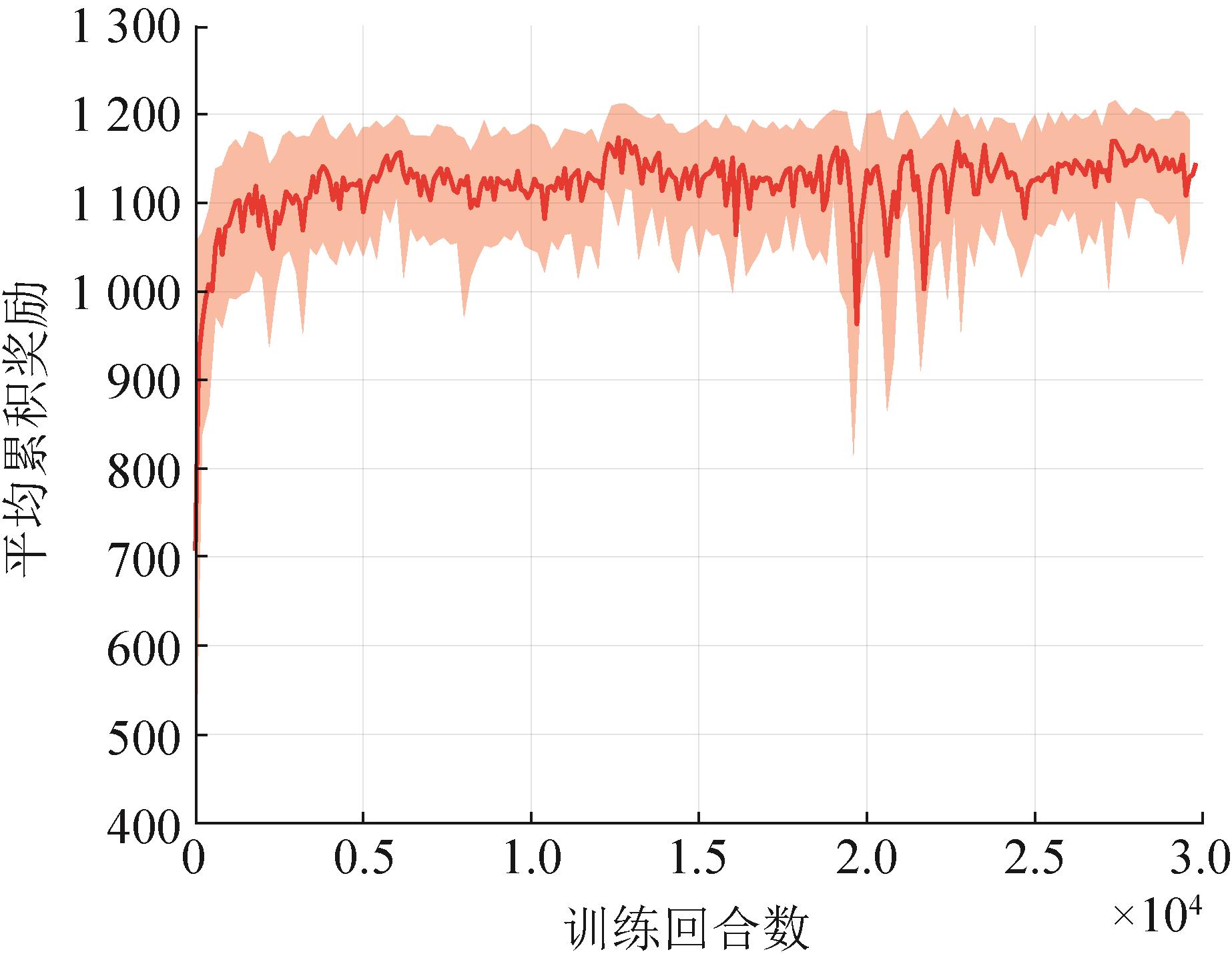
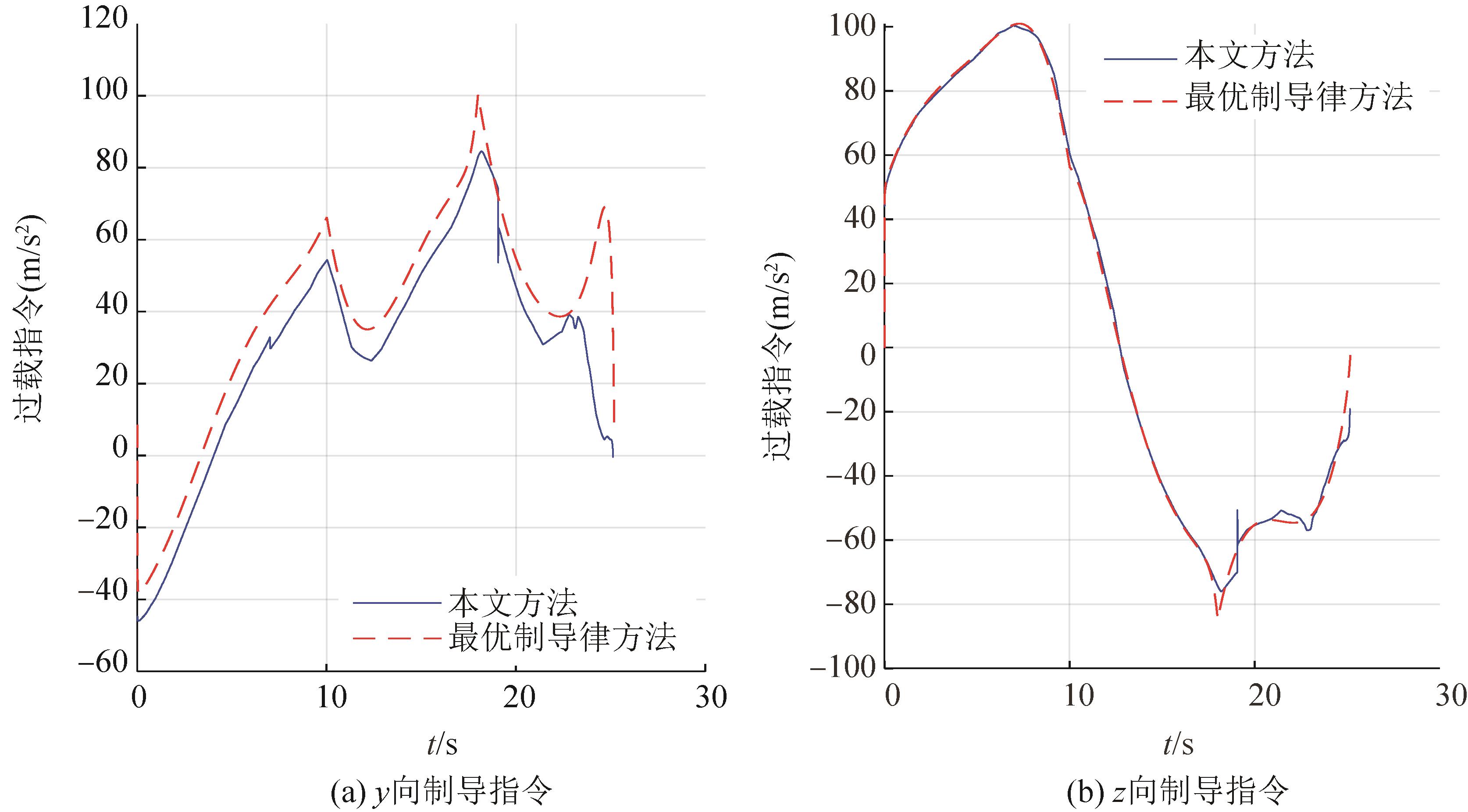
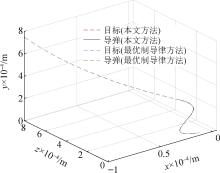
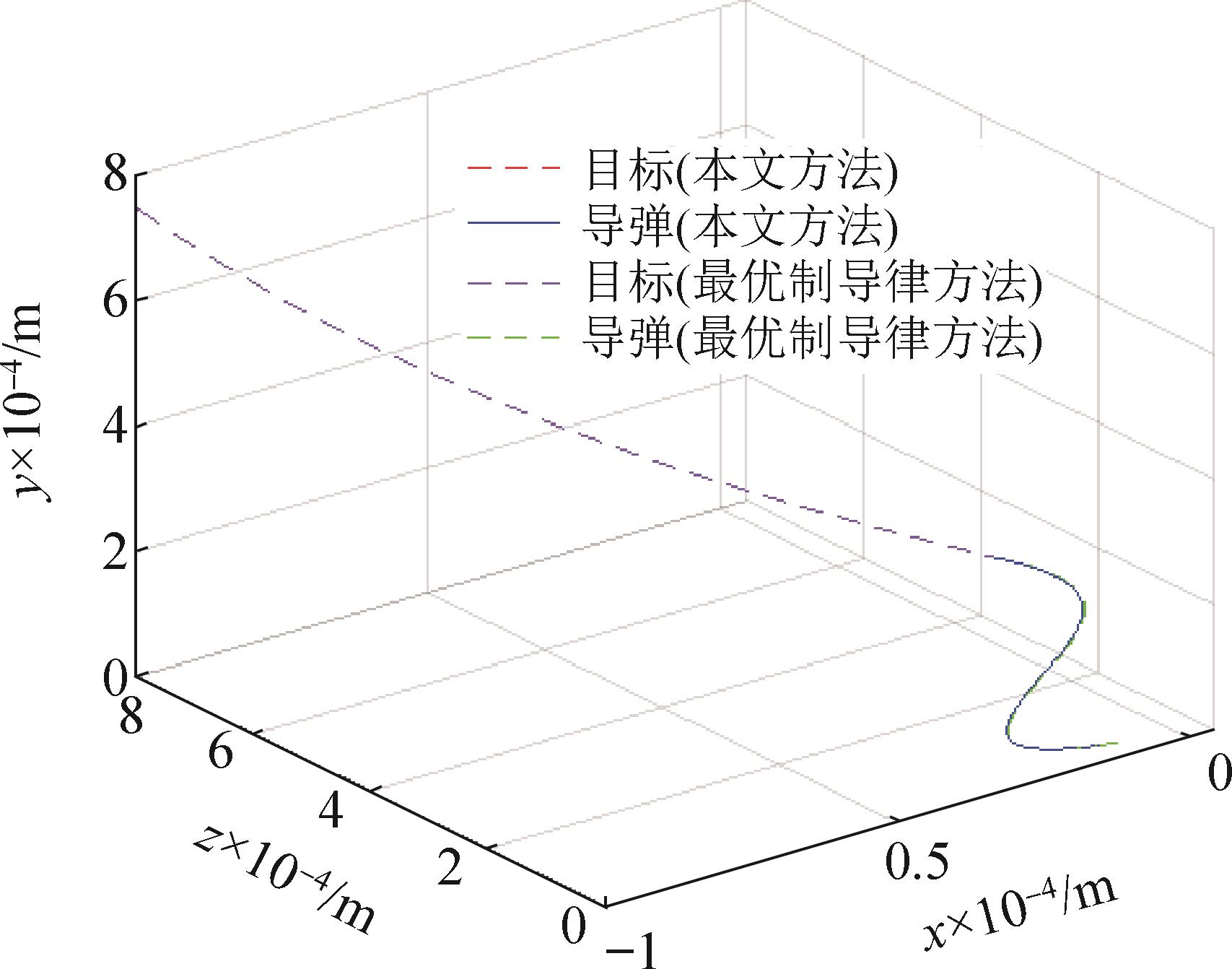
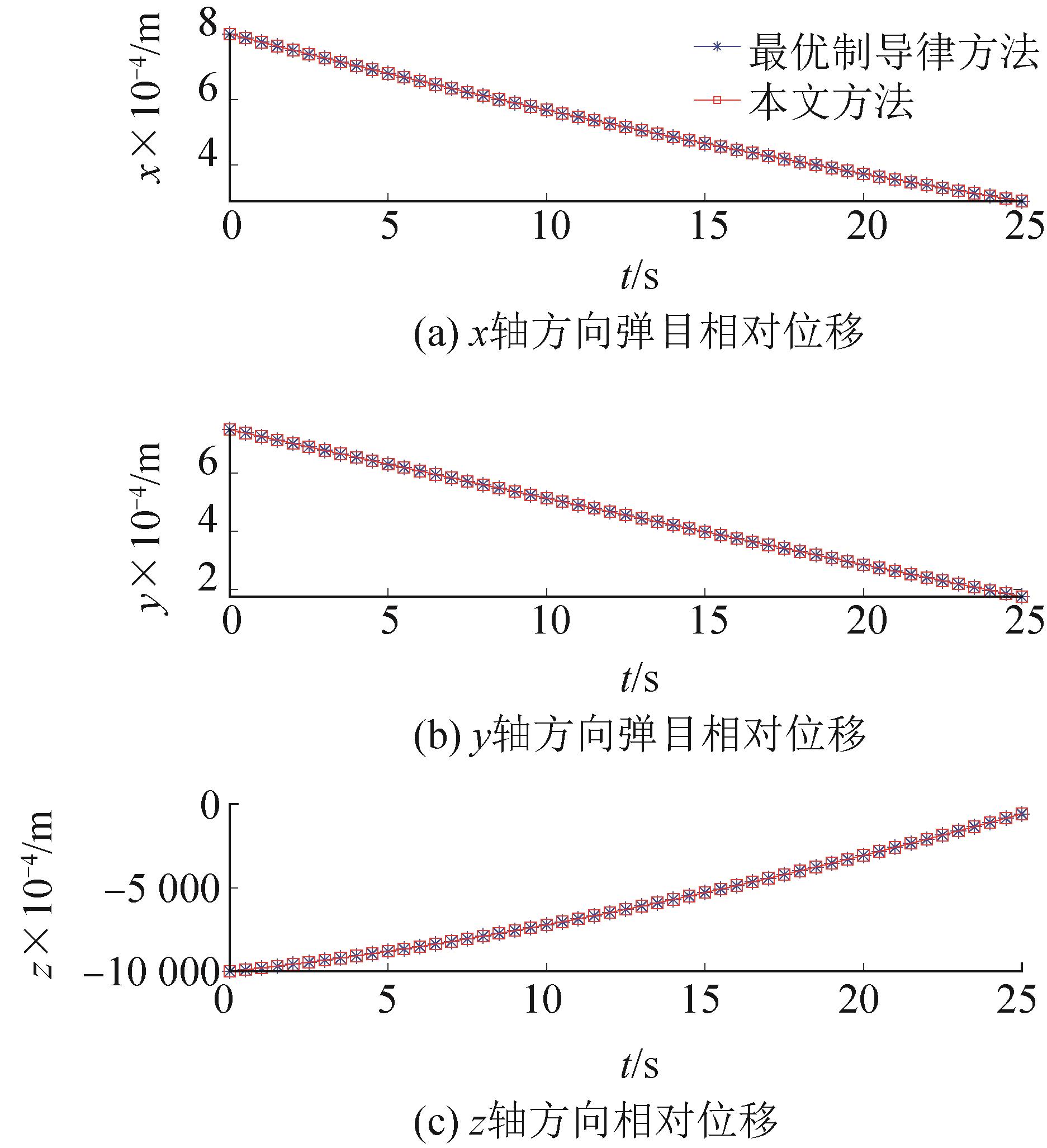
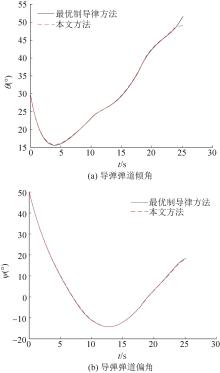
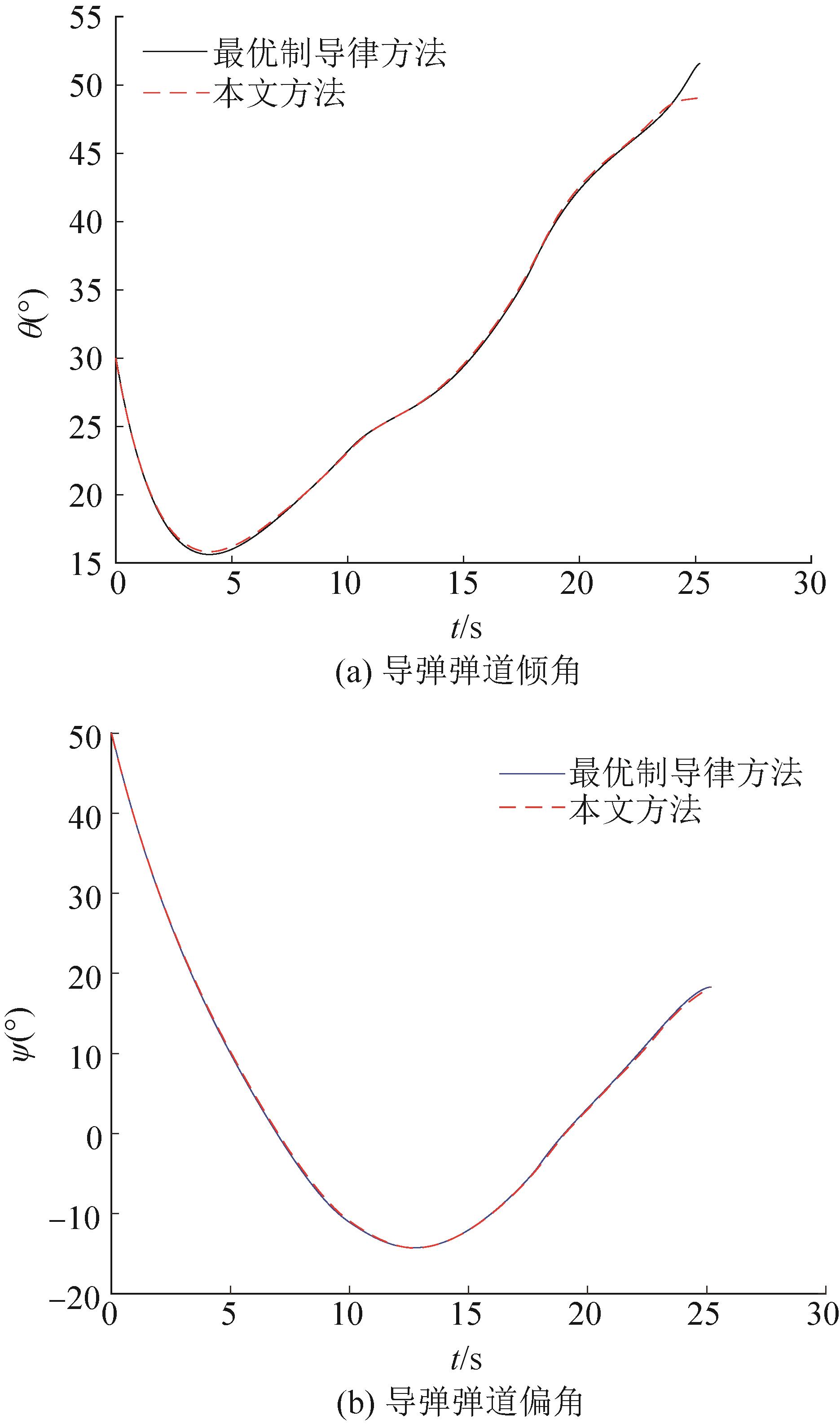
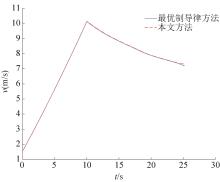
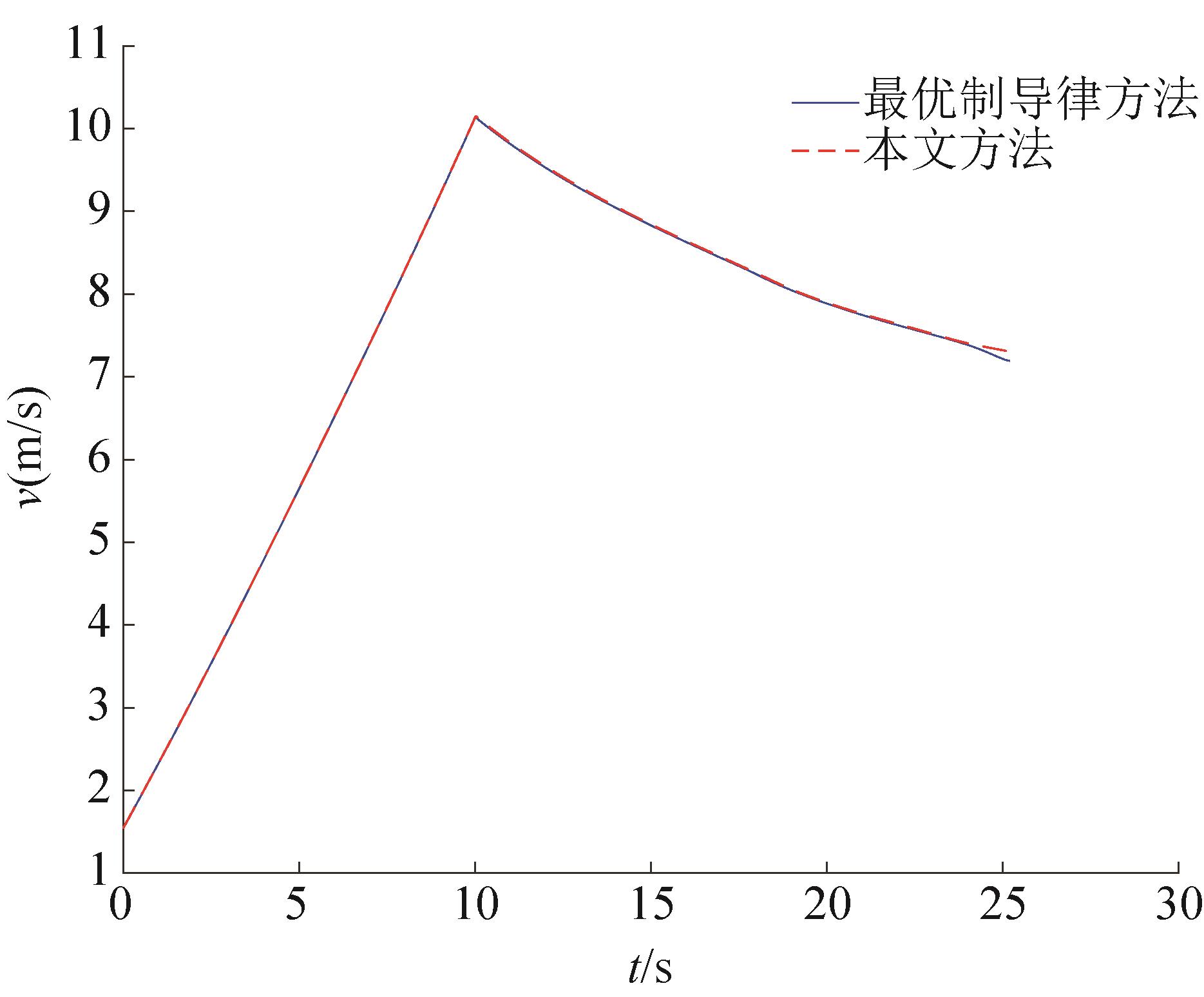
| 1 |
吴帅, 周晓华, 汪莉莉, 等. 基于实际采样的导弹弹道建模与仿真[J]. 系统仿真学报, 2019, 31(4): 811-817.
|
|
Wu Shuai, Zhou Xiaohua, Wang Lili, et al. Modeling and Simulation of Missile Trajectory Based on Practical Sampling[J]. Journal of System Simulation, 2019, 31(4): 811-817.
|
| 2 |
顾文锦, 雷军委, 潘长鹏. 带落角限制的虚拟目标比例导引律设计[J]. 飞行力学, 2006, 24(2): 43-46.
|
|
Gu Wenjin, Lei Junwei, Pan Changpeng. Design of the Climbing Trajectory Using Virtual Target's Proportional Navigation Method with the Control of Terminal Azimuth of a Missile[J]. Flight Dynamics, 2006, 24(2): 43-46.
|
| 3 |
Lee C H, Kim T H, Tahk M J. Interception Angle Control Guidance Using Proportional Navigation with Error Feedback[J]. Journal of Guidance, Control, and Dynamics, 2013, 36(5): 1556-1561.
|
| 4 |
闫梁, 赵继广, 李辕. 带约束碰撞角的顺/逆轨制导律设计[J]. 北京航空航天大学学报, 2015, 41(5): 857-863.
|
|
Yan Liang, Zhao Jiguang, Li Yuan. Guidance Law with Angular Constraints for Head-pursuit or Head-on Engagement[J]. Journal of Beijing University of Aeronautics and Astronautics, 2015, 41(5): 857-863.
|
| 5 |
Li Yuan, Yan Liang, Zhao Jiguang, et al. Combined Proportional Navigation Law for Interception of High-speed Targets[J]. Defence Technology, 2014, 10(3): 298-303.
|
| 6 |
司玉洁, 熊华, 李喆. 拦截机动目标的三维自适应神经网络制导律[J]. 系统仿真学报, 2021, 33(2): 453-460.
|
|
Si Yujie, Xiong Hua, Li Zhe. Three-dimensional Adaptive Neural Network Guidance Law Against Maneuvering Targets[J]. Journal of System Simulation, 2021, 33(2): 453-460.
|
| 7 |
熊少锋, 魏明英, 赵明元, 等. 考虑导弹速度时变的角度约束最优中制导律[J]. 控制理论与应用, 2018, 35(2): 248-257.
|
|
Xiong Shaofeng, Wei Mingying, Zhao Mingyuan, et al. Impact Angle Constrained Optimal Midcourse Guidance Law for Missiles of Time-varying Speed[J]. Control Theory & Applications, 2018, 35(2): 248-257.
|
| 8 |
熊少锋, 魏明英, 赵明元, 等. 逆轨拦截机动目标的三维最优制导律[J]. 宇航学报, 2020, 41(1): 80-90.
|
|
Xiong Shaofeng, Wei Mingying, Zhao Mingyuan, et al. Three Dimensional Optimal Guidance Law Against Maneuvering Targets for Head-on Engagement[J]. Journal of Astronautics, 2020, 41(1): 80-90.
|
| 9 |
孟克子, 周荻. 多约束条件下的最优中制导律设计[J]. 系统工程与电子技术, 2016, 38(1): 116-122.
|
|
Meng Kezi, Zhou Di. Design of Optimal Midcourse Guidance Law with Multiple Constraints[J]. Systems Engineering and Electronics, 2016, 38(1): 116-122.
|
| 10 |
Taub I, Shima T. Intercept Angle Missile Guidance Under Time Varying Acceleration Bounds[J]. Journal of Guidance, Control, and Dynamics, 2013, 36(3): 686-699.
|
| 11 |
Bai Guoyu, Shen Huairong, Chen Jingpeng, et al. Novel Guidance Law for Interception for Maneuvering Target with High-speed[C]//Proceedings of 2016 3rd International Conference on Engineering Technology and Application. Lancaster, PA, USA: DEStech Publications, 2016: 735-742.
|
| 12 |
周慧波, 宋申民, 刘海坤. 具有攻击角约束的非奇异终端滑模导引律设计[J]. 中国惯性技术学报, 2014, 22(5): 606-611, 618.
|
|
Zhou Huibo, Song Shenmin, Liu Haikun. Nonsingular Terminal Sliding Mode Guidance Law with Impact Angle Constraint[J]. Journal of Chinese Inertial Technology, 2014, 22(5): 606-611, 618.
|
| 13 |
LeCun Y, Bengio Y, Hinton G. Deep Learning[J]. Nature, 2015, 521(7553): 436-444.
|
| 14 |
郭圣明, 贺筱媛, 吴琳, 等. 基于强制稀疏自编码神经网络的作战态势评估方法研究[J]. 系统仿真学报, 2018, 30(3): 772-784, 800.
|
|
Guo Shengming, He Xiaoyuan, Wu Lin, et al. Situation Assessment Approach for Air Defense Operation System Based on Force-sparsed Stacked-auto Encoding Neural Networks[J]. Journal of System Simulation, 2018, 30(3): 772-784, 800.
|
| 15 |
Mnih V, Kavukcuoglu K, Silver D, et al. Human-level Control Through Deep Reinforcement Learning[J]. Nature, 2015, 518(7540): 529-533.
|
| 16 |
Silver D, Huang A, Maddison C J, et al. Mastering the Game of Go with Deep Neural Networks and Tree Search[J]. Nature, 2016, 529(7587): 484-489.
|
| 17 |
Vinyals O, Babuschkin I, Czarnecki W M, et al. Grandmaster Level in StarCraft II Using Multi-agent Reinforcement Learning[J]. Nature, 2019, 575(7782): 350-354.
|
| 18 |
Furfaro R, Linares R. Waypoint-based Generalized ZEM/ZEV Feedback Guidance for Planetary Landing Via a Reinforcement Learning Approach[C]//3rd International Academy of Astronautics Conference on Dynamics and Control of Space Systems. Escondido, CA, USA: Univelt Inc., 2017: 401-416.
|
| 19 |
Liang Chen, Wang Weihong, Liu Zhenghua, et al. Learning to Guide: Guidance Law Based on Deep Meta-learning and Model Predictive Path Integral Control[J]. IEEE Access, 2019, 7: 47353-47365.
|
| 20 |
Gaudet B, Furfaro R. Missile Homing-phase Guidance Law Design Using Reinforcement Learning[C]//AIAA Guidance, Navigation, and Control Conference. Reston, VA, USA: AIAA, 2012: AIAA 2012-4470.
|
| 21 |
Chen Yadong, Wang Jianan, Wang Chunyan, et al. Three-dimensional Cooperative Homing Guidance Law with Field-of-view Constraint[J]. Journal of Guidance, Control, and Dynamics, 2020, 43(2): 389-397.
|
| 22 |
Hussein A, Gaber M M, Elyan E, et al. Imitation Learning: A Survey of Learning Methods[J]. ACM Computing Surveys, 2018, 50(2): 21.
|
| 23 |
Micheal B, Claude S. A Framework for Behavioural Cloning[M]. [S.l.]: [s.n.], 1995: 103-129.
|
| 24 |
Abbeel P, Ng A Y. Apprenticeship Learning Via Inverse Reinforcement Learning[C]//Proceedings of the Twenty-First International Conference on Machine Learning. New York, NY, USA: Association for Computing Machinery, 2004: 1.
|
| 25 |
Ng A Y, Russell S J. Algorithms for Inverse Reinforcement Learning[C]//Proceedings of the Seventeenth International Conference on Machine Learning. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 2000: 663-670.
|
| 26 |
Ross Stéphane, Gordon G J, Bagnell J A. A Reduction of Imitation Learning and Structured Prediction to No-regret Online Learning[C]//Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. Chia Laguna Resort, Sardinia, Italy: PMLR, 2011: 627-635.
|
| 27 |
Hämäläinen Perttu, Babadi A, Ma Xiaoxiao, et al. PPO-CMA: Proximal Policy Optimization with Covariance Matrix Adaptation[C]//2020 IEEE 30th International Workshop on Machine Learning for Signal Processing (MLSP). Piscataway, NJ, USA: IEEE, 2020: 1-6.
|
 ), 林廷宇1, 肖莹莹1, 施国强1, 王豪2, 曾贲2, 欧一鸣1, 赵芃芃1
), 林廷宇1, 肖莹莹1, 施国强1, 王豪2, 曾贲2, 欧一鸣1, 赵芃芃1