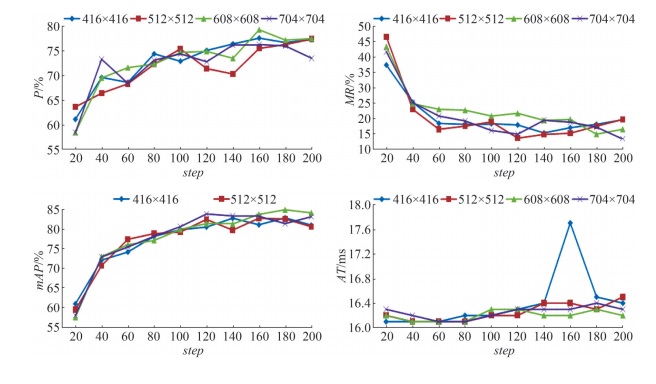
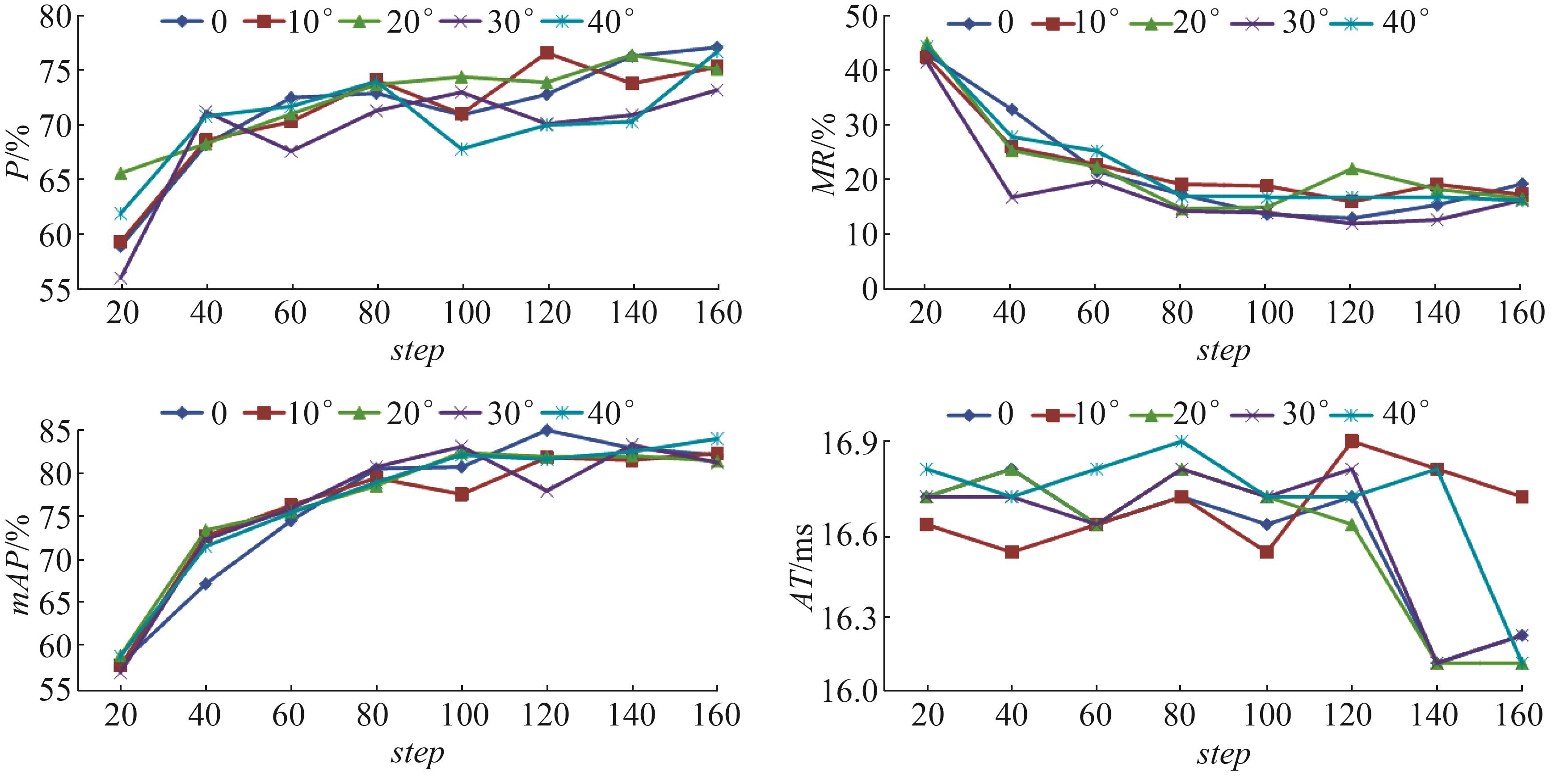
| 1 |
Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. Los Alamitos: IEEE, 2016: 779-788.
|
| 2 |
Dalal N, Triggs B. Histograms of Oriented Gradients for Human Detection[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05). Los Alamitos: IEEE, 2005: 886-893.
|
| 3 |
Everingham M, Eslami S, Gool L V, et al. The Pascal Visual Object Classes Challenge: A Retrospective[J]. International Journal of Computer Vision(S0920-5691), 2015, 111(1): 98-136.
|
| 4 |
Papageorgiou C P, Oren M, Poggio T. A General Framework for Object Detection[C]//Sixth International Conference on Computer Vision (IEEE cat. No. 98CH36271). Los Alamitos: IEEE, 1998: 555-562.
|
| 5 |
Viola P, Jones M J, Snow D. Detecting Pedestrians Using Patterns of Motion and Appearance[J]. International Journal of Computer Vision(S0920-5691), 2005, 63(2): 153-161.
|
| 6 |
Leibe B, Seemann E, Schiele B. Pedestrian Detection in Crowded Scenes[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05). Los Alamitos: IEEE, 2005: 878-885.
|
| 7 |
Girshick R, Donahue J, Darrell T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos: IEEE, 2014: 580-587.
|
| 8 |
Girshick R. Fast R-CNN[C]//IEEE International Conference on Computer Vision. Los Alamitos: IEEE, 2015: 1440-1448.
|
| 9 |
Ren S, He K, Girshick R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence(S0162-8828), 2017, 39(6): 1137-1149.
|
| 10 |
Zhang S, Yang J, Schiele B. Occluded Pedestrian Detection Through Guided Attention in CNNs[C]//IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos: IEEE, 2018: 6995-7003.
|
| 11 |
He K, Gkioxari G, Dollár P, et al. Mask R-CNN[C]//IEEE International Conference on Computer Vision. Los Alamitos: IEEE, 2017: 2961-2969.
|
| 12 |
Redmon J, Farhadi A. YOLO9000: Better, Faster, Stronger[C]//IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos: IEEE, 2017: 7263-7271.
|
| 13 |
Redmon J, Farhadi A. YOLOv3: An Incremental Improvement[J/OL]. ArXiv preprint (2018-04-08)[2021-07-20]. .
|
| 14 |
Bochkovskiy A, Wang C Y, Liao H Y M. YOLOv4: Optimal Speed and Accuracy of Object Detection[J/OL]. ArXiv(2020-04-23)[2021-08-29]. .
|
| 15 |
Wang C Y, Liao H, Wu Y H, et al. CSPNet: A New Backbone that can Enhance Learning Capability of CNN[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops(CVPRW). Los Alamitos: IEEE, 2020: 390-391.
|
| 16 |
Hu J, Shen L, Sun G. Squeeze-and-Excitation Networks[C]//IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos: IEEE, 2018: 7132-7141.
|
| 17 |
He K, Zhang X, Ren S, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence(S0162-8828), 2014, 37(9): 1904-1916.
|
| 18 |
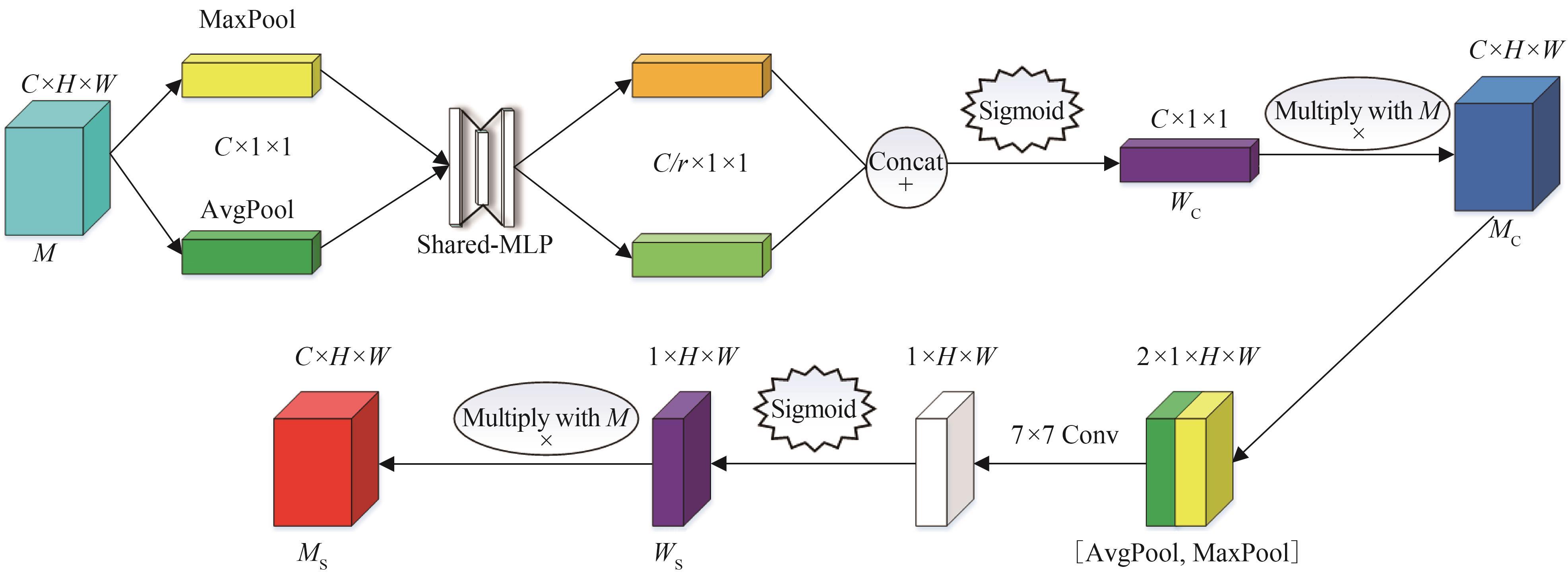
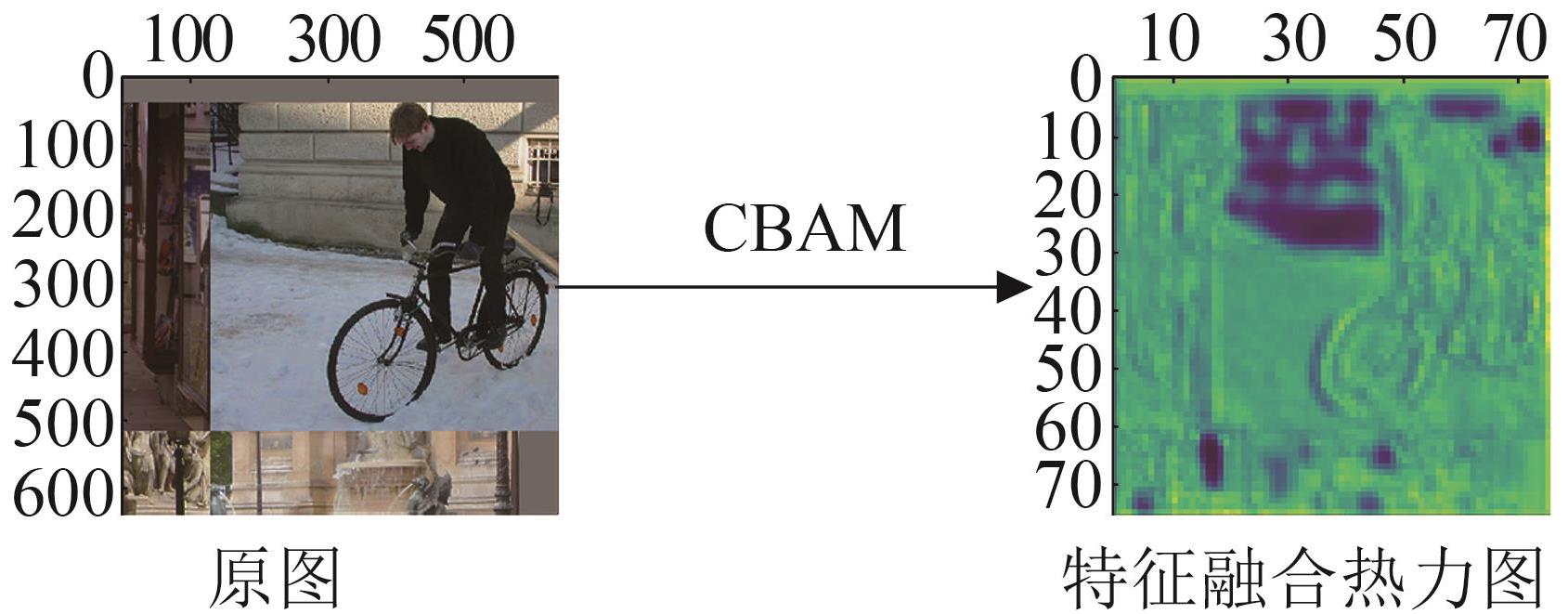
Woo S, Park J, Lee J Y, et al. CBAM: Convolutional Block Attention Module[C]//European Conference on Computer Vision(ECCV). Berlin: Springer, 2018: 3-19.
|
| 19 |
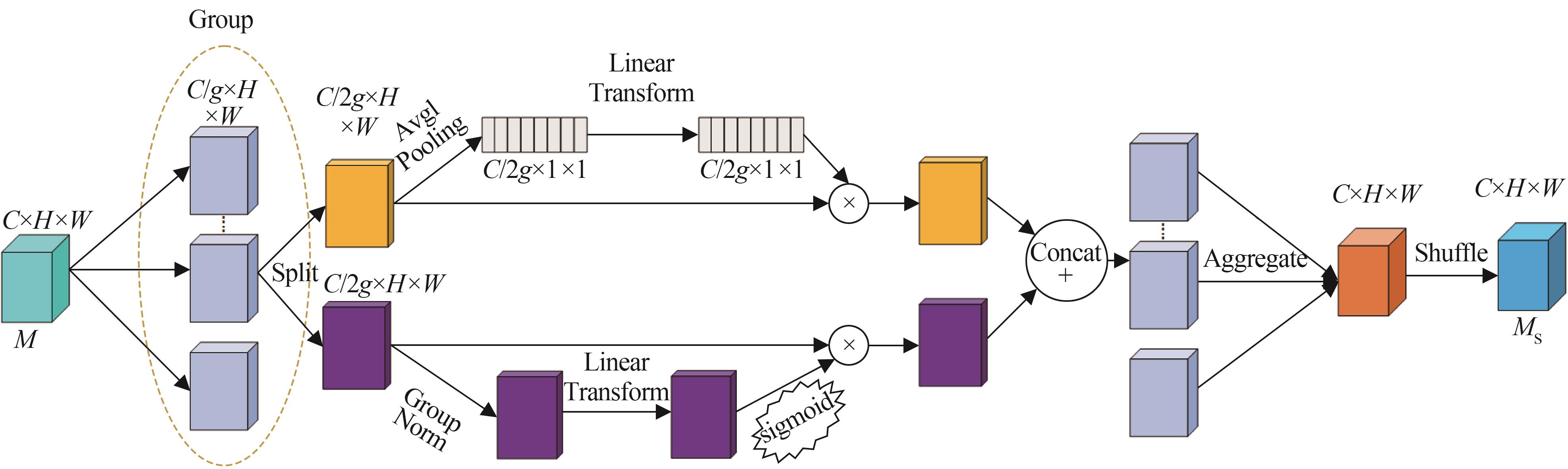
Zhang Q L, Yang Y B. Sa-net: Shuffle Attention for Deep Convolutional Neural Networks[C]//IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP). Toronto: IEEE, 2021: 2235-2239.
|
| 20 |
Liu Z, Sun M, Zhou T, et al. Rethinking the Value of Network Pruning[J/OL]. ArXiv preprint(2018-10-11)[2021-07-22]. .
|
| 21 |
Han S, Pool J, Tran J, et al. Learning both Weights and Connections for Efficient Neural Networks[J/OL]. ArXiv preprint(2015-06-08)[2021-07-25]. .
|
| 22 |
Yu J, Jiang Y, Wang Z, et al. Unitbox: An Advanced Object Detection Network[C]//24th ACM International Conference on Multimedia. New York: ACM, 2016: 516-520.
|
| 23 |
Rezatofighi H, Tsoi N, Gwak J Y, et al. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. Los Alamitos: IEEE, 2019: 658-666.
|
 ), Lu Wang, Chongliu Jia, Yuemou Jian, Xiaoxia Ma
), Lu Wang, Chongliu Jia, Yuemou Jian, Xiaoxia Ma