

系统仿真学报 ›› 2025, Vol. 37 ›› Issue (5): 1142-1157.doi: 10.16182/j.issn1004731x.joss.24-0045
谷学强, 罗俊仁, 周棪忠, 张万鹏
收稿日期:2024-01-12
修回日期:2024-05-30
出版日期:2025-05-20
发布日期:2025-05-23
通讯作者:
罗俊仁
第一作者简介:谷学强(1983-),男,副研究员,博士,研究方向为智能规划与决策,边缘智能。
基金资助:Gu Xueqiang, Luo Junren, Zhou Yanzhong, Zhang Wanpeng
Received:2024-01-12
Revised:2024-05-30
Online:2025-05-20
Published:2025-05-23
Contact:
Luo Junren
摘要:
人工智能技术的发展极大推动了智能博弈决策问题求解范式的变革,从最优解、均衡解到适变解,如何构建基于生成式大模型的智能博弈自适应决策智能体充满挑战。博弈强对抗环境中兵力分配和多实体协同是研究排兵布阵和作战协同的核心课题。基于技能、排序和偏好元博弈模型构建的策略强化学习、策略博弈树搜索与策略偏好投票选择方法,设计了满足生成时规划的大模型智能体架构。该架构可对齐指挥员意图,具有可行性、适用性、扩展性,可为自适应决策过程提供可解释性策略推荐。从基座模型构建、目标引导博弈强化学习和开放式元博弈策略学习分析了关键技术需求。期望为强化学习类模型、博弈学习类模型与生成式大语言模型结合的交叉研究提供参考。
中图分类号:
谷学强,罗俊仁,周棪忠等 . 智能博弈决策大模型智能体技术综述[J]. 系统仿真学报, 2025, 37(5): 1142-1157.
Gu Xueqiang,Luo Junren,Zhou Yanzhong,et al . Survey on Large Language Agent Technologies for Intelligent Game Theoretic Decision-making[J]. Journal of System Simulation, 2025, 37(5): 1142-1157.

图1
智能博弈训练方法分类

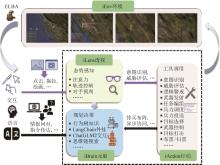
图2
智能博弈自适应决策智能体架构
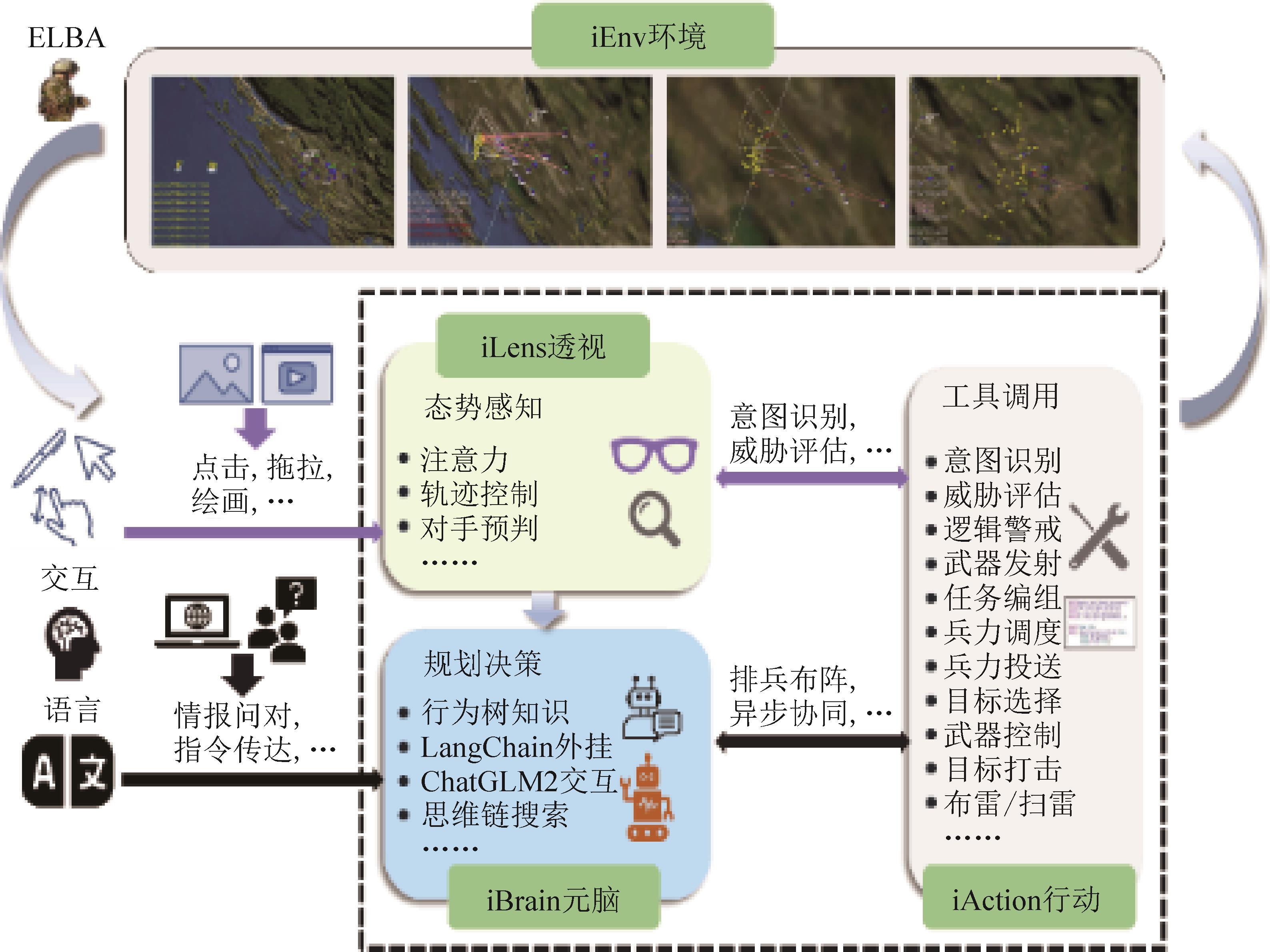
图3
智能体认知框架
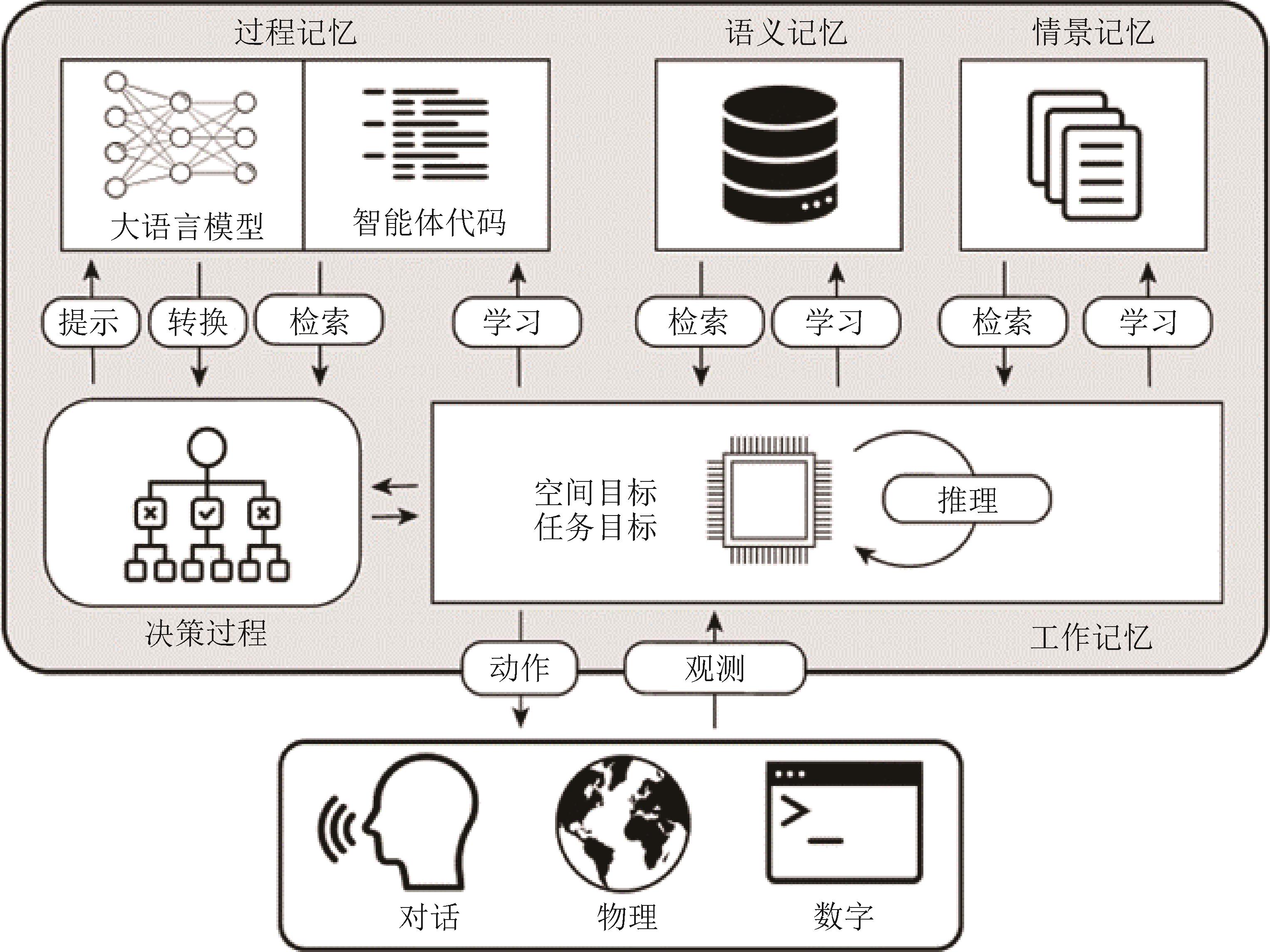
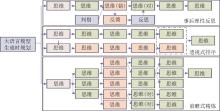
图4
大语言模型生成时规划
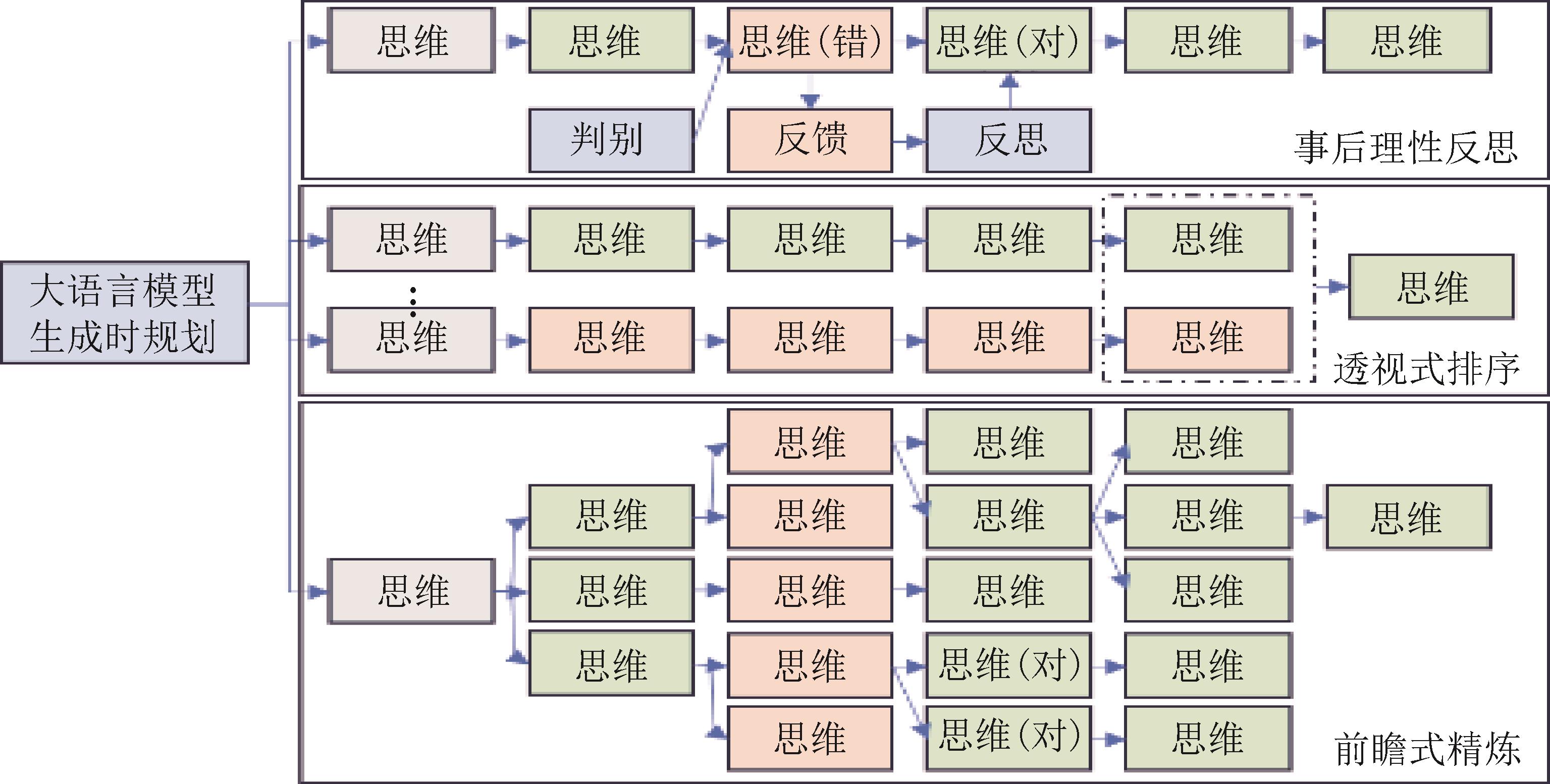
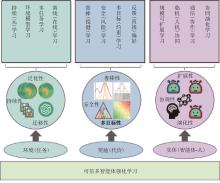
图5
可信多智能体强化学习
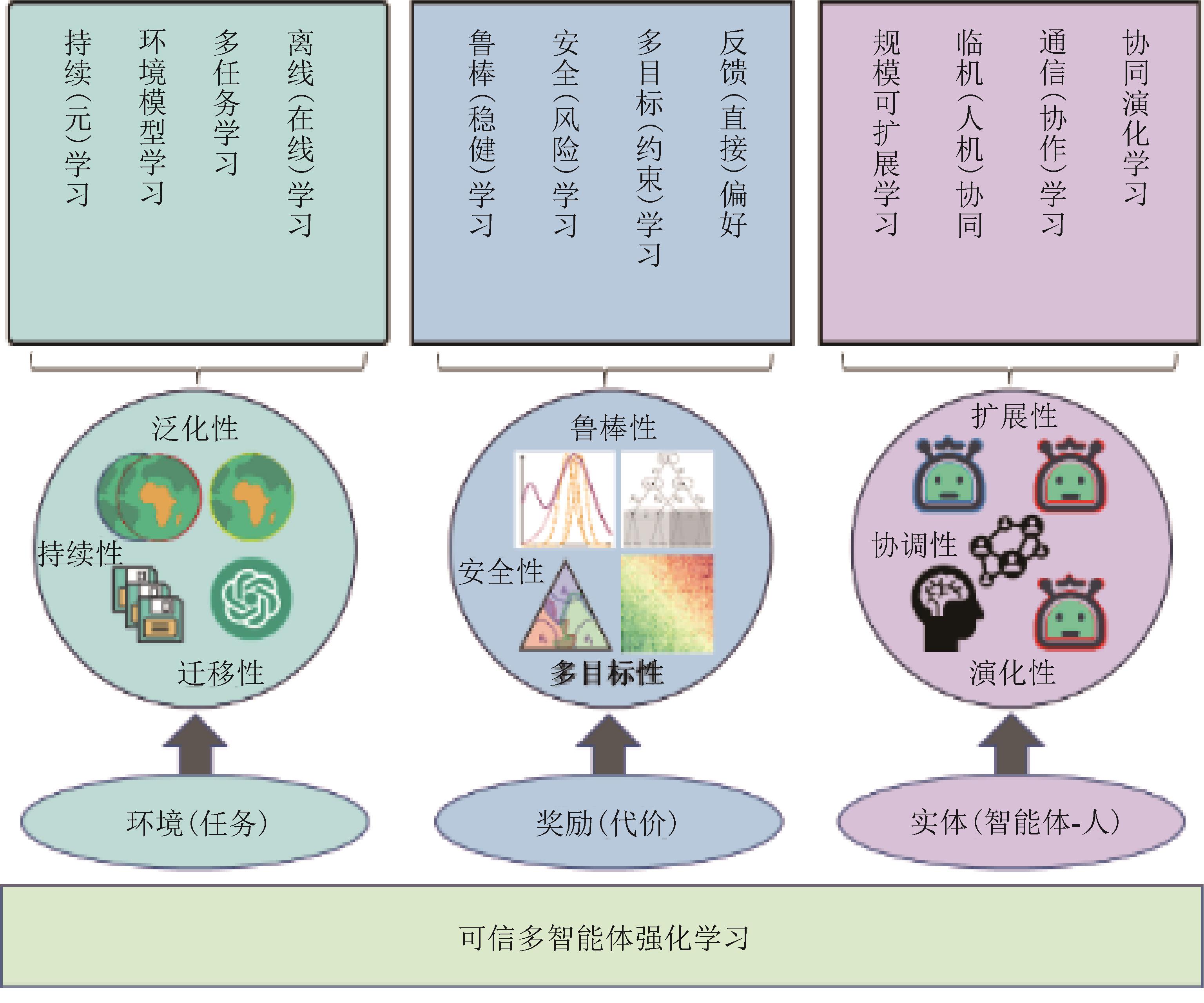
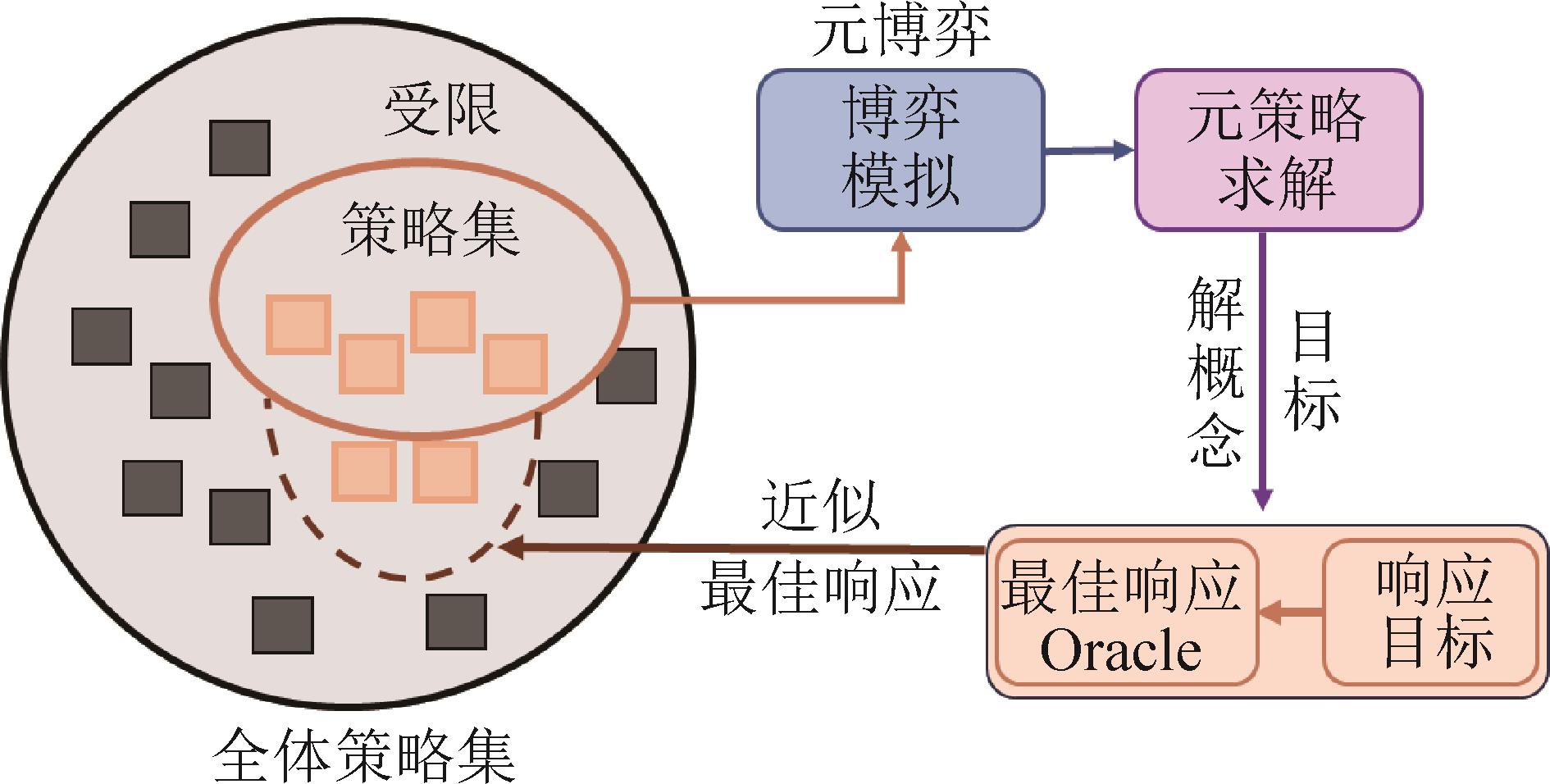
图6
策略空间响应预言机构架
| 1 | Grana J, Lamb J, O'Donoughue N A. Findings on Mosaic Warfare from a Colonel Blotto Game[EB/OL]. (2021-01-05) [2023-12-11]. . |
| 2 | 罗俊仁, 邹明我, 陈少飞, 等. 布洛托上校博弈模型及求解方法研究进展[J]. 计算机科学, 2024, 51(1): 84-98. |
| Luo Junren, Zou Mingwo, Chen Shaofei, et al. Research Progress on Colonel Blotto Game Models and Solving Methods[J]. Computer Science, 2024, 51(1): 84-98. | |
| 3 | Anthony T, Eccles T, Tacchetti A, et al. Learning to Play No-press Diplomacy with Best Response Policy Iteration[C]//Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 1510. |
| 4 | Defense Brief Editorial. DARPA Will Try Ruining Video Games to Improve Pentagon's War Games[EB/OL]. (2020-05-14) [2023-12-11]. . |
| 5 | Priebe M, Ligor D C, McClintock B, et al. Multiple Dilemmas: Challenges and Options for All-domain Command and Control[EB/OL]. (2020-12-03) [2023-12-11]. . |
| 6 | Cerri T, Laster N, Hernandez A, et al. Using AI to Assist Commanders with Complex Decision-making[J]. Interservice, 2018: 1-11. |
| 7 | Stilman B, Yakhnis V. LG Strategist: Your Personal Chief of Staff[C]//Enabling Technology for Simulation Science V. Bellingham: SPIE, 2001: 441-453. |
| 8 | Serge S R, Stevens J A, Eifert L. Make It Usable: Highlighting the Importance of Improving the Intuitiveness and Usability of a Computer-based Training Simulation[C]//2015 Winter Simulation Conference (WSC). Piscataway: IEEE, 2015: 1056-1067. |
| 9 | Anon. COMBAT[EB/OL]. (2021-12-14) [2023-12-01]. . |
| 10 | Vincent B. How Marine Corps University Is Experimenting with Generative AI in Simulations and Wargaming[EB/OL]. (2023-06-28) [2023-12-01]. . |
| 11 | Hinton P. Generative AI and Wargaming: What Is It Good for?[J]. The RUSI Journal, 2023, 168(7): 34-41. |
| 12 | 许霄, 李东, 郭圣明, 等. 面向联合作战兵棋推演的智能决策建模框架[J]. 指挥与控制学报, 2023, 9(4): 449-456. |
| Xu Xiao, Li Dong, Guo Shengming, et al. An Intelligent Decision-making Modeling Architecture for Joint Operation-oriented Wargaming[J]. Journal of Command and Control, 2023, 9(4): 449-456. | |
| 13 | 苏炯铭, 罗俊仁, 陈少飞. 智能博弈决策策略求解新视角实证分析[J]. 系统仿真学报, 2025, 37(2): 345-361. |
| Su Jiongming, Luo Junren, Chen Shaofei. An Empirical Analysis of New Perspectives for Strategy Solving in Intelligent Game-theoretic Decision-making[J]. Journal of System Simulation, 2025, 37(2): 345-361. | |
| 14 | 陈超, 姜鑫, 黄金才, 等. 军事对抗决策分析与建模[M]. 长沙: 国防科技大学出版社, 2018. |
| 15 | 李璟. 战斗力对抗[M]. 北京: 国防大学出版社, 2019. |
| 16 | 王珞. 升维: 不确定时代的决策博弈[M]. 北京: 机械工业出版社, 2022. |
| Wang Luo. Ascending: Dimension Decision Game in Uncertain Times[M]. Beijing: China Machine Press, 2022. | |
| 17 | Kelly A. Decision Making Using Game Theory: An Introduction for Managers[M]. Cambridge: Cambridge University Press, 2003. |
| 18 | 桑吉特·达米. 风险、不确定性与模糊性下的行为[M]. 李井奎, 译. 上海: 格致出版社, 2022.Sanjit Dhami. Behavioral Economics of Risk, Uncertainty, and Ambiguity[M]. Translated by Li Jingkui. Shanghai: Truth & Wisdom Press, 2022. |
| 19 | George I S. FIRESTORM AI System Prepares for Joint Role [EB/OL]. [2023-12-11]. . |
| 20 | Clark B, Patt D, Schramm H. Mosaic Warfare: Exploiting Artificial Intelligence and Autonomous Systems to Implement Decision-centric Operations[EB/OL]. (2020-02-11) [2023-12-11]. . |
| 21 | Clark B, Patt D, Walton T A. Advancing Decision-centric Warfare: Gaining Advantage Through Force Design and Mission Integration[EB/OL]. (2021-07-04) [2022-10-20]. . |
| 22 | 于淼. 枢纽态势论—信息时代的工程化作战筹划方法理论[M]. 北京: 军事科学出版社, 2013. |
| 23 | 贺筱媛, 郭圣明, 吴琳, 等. 面向智能化兵棋的认知行为建模方法研究[J]. 系统仿真学报, 2021, 33(9): 2037-2047. |
| He Xiaoyuan, Guo Shengming, Wu Lin, et al. Modeling Research of Cognition Behavior for Intelligent Wargaming[J]. Journal of System Simulation, 2021, 33(9): 2037-2047. | |
| 24 | 李宝德. “ 情景-应对 ” 模式下海运通道突发事件应急响应决策研究[D]. 大连: 大连海事大学, 2023. |
| Li Baode. Research on Emergency Response Decision-making for Emergency Events in Sea Lanes Based on "Scenario-response" Mode[D]. Dalian: Dalian Maritime University, 2023. | |
| 25 | Xie Sm, Raghunathan A, Liang P, et al. An Explanation of In-context Learning as Implicit Bayesian Inference[C]//International Conference on Learning Representations. New York: ICLR, 2021: 6893. |
| 26 | Hao Rui, Liu Dianbo, Hu Linmei. Enhancing Human Capabilities Through Symbiotic Artificial Intelligence with Shared Sensory Experiences[EB/OL]. (2023-05-26) [2023-08-25]. . |
| 27 | 温颖, 万梓煜, 张劭, 等. 多模态环境中的多智能体强化学习: 预训练大模型视角[J]. 中国计算机学会通讯, 2023, 19(8): 41-49. |
| 28 | 胡晓峰, 齐大伟. 智能决策问题探讨-从游戏博弈到作战指挥,距离还有多远[J]. 指挥与控制学报, 2020, 6(4): 356-363. |
| Hu Xiaofeng, Qi Dawei. On Problems of Intelligent Decision-making-how Far Is It from Game-playing to Operational Command[J]. Journal of Command and Control, 2020, 6(4): 356-363. | |
| 29 | 阳东升, 李强, 刘玉超, 等. 宏观尺度C2过程机理: PREA环理论模型修订及应用[J]. 指挥与控制学报, 2022, 8(4): 389-401. |
| Yang Dongsheng, Li Qiang, Liu Yuchao, et al. Macro-scale C2 Process Mechanism: Revision and Application of Theory Model of PREA Loop[J]. Journal of Command and Control, 2022, 8(4): 389-401. | |
| 30 | 吉祥, 蒋锴, 成海东. 全域作战指挥信息系统总体架构及核心支柱[J]. 指挥与控制学报, 2023, 9(2): 225-232. |
| Ji Xiang, Jiang Kai, Cheng Haidong. Architecture and Core Pillars of All-domain Operation Command Information System[J]. Journal of Command and Control, 2023, 9(2): 225-232. | |
| 31 | Reed J O, Gelpi P, Wineman B, et al. Evolution of Warfare: Canonizing Science to Evolve the Game[D]. [S.l. : USMC Command and Staff College Marine Corps University, 2020. |
| 32 | McCarthy S M. Hierarchical Planning in Security Games: A Game Theoretic Approach to Strategic, Tactical and Operational Decision Making[D]. Los Angeles: University of Southern California, 2018. |
| 33 | Minguela-Castro Gerardo, Heradio Ruben, Cerrada Carlos. Automated Support for Battle Operational-strategic Decision-making[J]. Mathematics, 2021, 9(13): 1534. |
| 34 | 刘曰胜, 高凯. 自适应作战的演进逻辑[N]. 解放军报, 2023-07-20(7). |
| 35 | 柴天佑, 岳恒. 自适应控制[M]. 北京: 清华大学出版社, 2016. |
| 36 | Levy D. Advancing Optimization for Modern Machine Learning[D]. Stanford: Stanford University, 2021. |
| 37 | 杨卓群, 金芝. 基于验证的自适应系统决策: 一种模型驱动的方法[J]. 软件学报, 2017, 28(7): 1676-1697. |
| Yang Zhuoqun, Jin Zhi. Verification Based Decision-making for Self-adaptive Systems: A Model-driven Approach[J]. Journal of Software, 2017, 28(7): 1676-1697. | |
| 38 | Kamath U, Liu J, Whitaker J. Transfer Learning: Domain Adaptation[M]//Kamath U, Liu J, Whitaker J. Deep Learning for NLP and Speech Recognition. Cham: Springer International Publishing, 2019: 495-535. |
| 39 | Kong Yajing, Liu Liu, Wang Jun, et al. Adaptive Curriculum Learning[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2021: 5047-5056. |
| 40 | Ajay A, Gupta A, Ghosh D, et al. Distributionally Adaptive Meta Reinforcement Learning[C]//Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 25856-25869. |
| 41 | Bauer J, Baumli K, Behbahani F, et al. Human-timescale Adaptation in an Open-ended Task Space[C]//Proceedings of the 40th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2023: 1887-1935. |
| 42 | Xue Wanqi, Cai Qingpeng, Xue Zhenghai, et al. PrefRec: Recommender Systems with Human Preferences for Reinforcing Long-term User Engagement[C]//Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. New York: ACM, 2023: 2874-2884. |
| 43 | Reis Simão, Luís Paulo Reis, Lau Nuno. Game Adaptation by Using Reinforcement Learning Over Meta Games[J]. Group Decision and Negotiation, 2021, 30(2): 321-340. |
| 44 | Świechowski Maciej, Mańdziuk Jacek. Self-adaptation of Playing Strategies in General Game Playing[J]. IEEE Transactions on Computational Intelligence and AI in Games, 2014, 6(4): 367-381. |
| 45 | Fiegel Côme, Ménard Pierre, Kozuno Tadashi, et al. Adapting to Game Trees in Zero-sum Imperfect Information Games[C]//Proceedings of the 40th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2023: 10093-10135. |
| 46 | 黄美根, 王维平, 王涛, 等. 基于EC2的无人化作战体系云流化指控架构设计方法[J]. 系统工程与电子技术, 2022, 44(11): 3413-3422. |
| Huang Meigen, Wang Weiping, Wang Tao, et al. EC2-based Architecture Design Method of Cloud-flow C2 for Unmanned Combat SoS[J]. Systems Engineering and Electronics, 2022, 44(11): 3413-3422. | |
| 47 | Fogli M, Kudla T, Pingen G, et al. A Coalition Perspective on Federated and Adaptive Clouds for Disadvantaged Tactical Networks[C]// International Conference on Military Communications and Information Systems (ICMCIS). [S.l. : s.n.], 2023: 1001377. |
| 48 | Lawrence C. Adapting Cross-domain Kill-webs (ACK): A Framework for Decentralized Control of Multi-domain Mosaic Warfare[EB/OL]. [2023-12-11]. |
| 49 | 尹奇跃, 赵美静, 倪晚成, 等. 兵棋推演的智能决策技术与挑战[J]. 自动化学报, 2023, 49(5): 913-928. |
| Yin Qiyue, Zhao Meijing, Ni Wancheng, et al. Intelligent Decision Making Technology and Challenge of Wargame[J]. Acta Automatica Sinica, 2023, 49(5): 913-928. | |
| 50 | Adam Lukáš, Horčík Rostislav, Kasl Tomáš, et al. Double Oracle Algorithm for Computing Equilibria in Continuous Games[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 5070-5077. |
| 51 | Behnezhad S, Dehghani S, Derakhshan M, et al. Faster and Simpler Algorithm for Optimal Strategies of Blotto Game[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2017: 369-375. |
| 52 | Dong Quan Vu, Loiseau Patrick, Silva Alonso. Approximate Equilibria in Non-constant-sum Colonel Blotto and Lottery Blotto Games with Large Numbers of Battlefields[EB/OL]. (2019-10-15) [2023-12-01]. . |
| 53 | Li Xinmi, Zheng Jie. Pure Strategy Nash Equilibrium in 2-contestant Generalized Lottery Colonel Blotto Games[J]. Journal of Mathematical Economics, 2022, 103: 102771. |
| 54 | Dong Quan Vu, Loiseau Patrick. Colonel Blotto Games with Favoritism: Competitions with Pre-allocations and Asymmetric Effectiveness[C]//Proceedings of the 22nd ACM Conference on Economics and Computation. New York: ACM, 2021: 862-863. |
| 55 | Dong Quan Vu, Loiseau Patrick, Silva Alonso, et al. Path Planning Problems with Side Observations-when Colonels Play Hide-and-seek[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 2252-2259. |
| 56 | Shi Guanya, Hönig Wolfgang, Yue Yisong, et al. Neural-swarm: Decentralized Close-proximity Multirotor Control Using Learned Interactions[C]//Proceedings of 2020 IEEE International Conference on Robotics and Automation (ICRA). Piscataway: IEEE, 2020: 3241-3247. |
| 57 | Iqbal S, Christian A Schroeder De Witt, Peng Bei, et al. Randomized Entity-wise Factorization for Multi-agent Reinforcement Learning[C]//Proceedings of the 38th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2021: 4596-4606. |
| 58 | Ryu Heechang, Shin Hayong, Park Jinkyoo. Multi-agent Actor-critic with Hierarchical Graph Attention Network[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 7236-7243. |
| 59 | Yang Yaodong, Luo Rui, Li Minne, et al. Mean Field Multi-agent Reinforcement Learning[C]//Proceedings of the 35th International Conference on Machine Learning. Laguna Resort: PMLR, 2018: 5571-5580. |
| 60 | Hao Jianye, Hao Xiaotian, Mao Hangyu, et al. Boosting Multiagent Reinforcement Learning via Permutation Invariant and Permutation Equivariant Networks[C]//The Eleventh International Conference on Learning Representations. New York: ICLR, 2023: 11697. |
| 61 | Kuba J G, Feng Xidong, Ding Shiyao, et al. Heterogeneous-Agent Mirror Learning: A Continuum of Solutions to Cooperative MARL[EB/OL]. (2022-08-02) [2023-10-16]. . |
| 62 | Song Yan, Jiang He, Tian Zheng, et al. An Empirical Study on Google Research Football Multi-agent Scenarios[J]. Machine Intelligence Research, 2024, 21(3): 549-570. |
| 63 | Pan Xuehai, Liu M, Zhong Fangwei, et al. MATE: Benchmarking Multi-agent Reinforcement Learning in Distributed Target Coverage Control[C]//Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 27862-27879. |
| 64 | 包战, 张驭龙, 朱松岩, 等. 智能临机规划技术要点研究[J]. 国防科技, 2023, 44(1): 112-118. |
| Bao Zhan, Zhang Yulong, Zhu Songyan, et al. Research on Key Points of Intelligent Contingency Planning Technology[J]. National Defense Technology, 2023, 44(1): 112-118. | |
| 65 | Team A A, Bauer J, Baumli K, et al. Human-timescale adaptation in an open-ended task space [J]. arXiv preprint, 2023, arXiv:. |
| 66 | Balduzzi D, Tuyls K, Perolat J, et al. Re-evaluating Evaluation[C]//Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 3272-3283. |
| 67 | Lanctot M, Larson K, Bachrach Y, et al. Evaluating Agents Using Social Choice Theory[EB/OL]. (2025-01-20)[2023-12-11]. . |
| 68 | Yang Fengjun, Mehr N, Schwager M. Decentralized Role Assignment in Multi-agent Teams via Empirical Game-theoretic Analysis[EB/OL]. (2021-09-29) [2022-10-20]. . |
| 69 | Marinier B, Van L M, Jones R. Applying Appraisal Theories to Goal Directed Autonomy[C]//Workshop on Goal-Directed Autonomy. Atlanta, GA: s.n.], 2010. |
| 70 | Ritter F E, Tehranchi F, Oury J D. ACT-R: A Cognitive Architecture for Modeling Cognition[J]. Wiley Interdisciplinary Reviews. Cognitive Science, 2019, 10(3): e1488. |
| 71 | Sumers T R, Yao Shunyu, Narasimhan K, et al. Cognitive Architectures for Language Agents[EB/OL]. (2024-03-15) [2024-03-17]. . |
| 72 | Molineaux M, Klenk M, Aha D W. Goal-driven Autonomy in a Navy Strategy Simulation[C]//Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2010: 1548-1554. |
| 73 | Microsoft. Prompt Flow[EB/OL]. [2023-12-11]. . |
| 74 | 蒋旭丰. 类ChatGPT大语言模型背景下计算机兵棋面临的机遇、挑战及未来展望[J]. 军事文摘, 2023(21): 57-60. |
| 75 | Chu Zheng, Chen Jingchang, Chen Qianglong, et al. A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future[EB/OL]. (2023-09-27) [2023-12-01]. . |
| 76 | Reed S, Zolna K, Parisotto E, et al. A Generalist Agent[EB/OL]. (2022-11-11) [2023-12-11]. . |
| 77 | 厦门渊亭信息科技有限公司. 天机: 军事大模型[EB/OL]. (2023-04-07) [2023-12-11]. . |
| 78 | Tadross D, Harris K. Donovan-AI Powered Decision Making for Defense[EB/OL]. (2023-06-29) [2023-10-18]. . |
| 79 | PALANTIR. AIP: Artificial Intelligence for Defense[EB/OL]. (2023-04-07) [2023-10-18]. . |
| 80 | Huang Jie, Chang Chenchuan. Towards Reasoning in Large Language Models: A Survey[C]//Findings of the Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 1049-1065. |
| 81 | Wang Song, Zhu Yaochen, Liu Haochen, et al. Knowledge Editing for Large Language Models: A Survey[J]. ACM Computing Surveys, 2024, 57(3): 59. |
| 82 | Yao Yunzhi, Wang Peng, Tian Bozhong, et al. Editing Large Language Models: Problems, Methods, and Opportunities[C]//Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA, USA: ACL, 2023: 1022210240. |
| 83 | Pan Liangming, Saxon M, Xu Wenda, et al. Automatically Correcting Large Language Models: Surveying the Landscape of Diverse Automated Correction Strategies[C]//Transactions of the Association for Computational Linguistics. Stroudsburg, PA, USA: ACL, 2024: 484-506. |
| 84 | Ma Chengdong, Yang Ziran, Gao Minquan, et al. Red Teaming Game: A Game-Theoretic Framework for Red Teaming Language Models[EB/OL]. (2023-09-30) [2023-12-11]. . |
| 85 | Zhang Ceyao, Yang Kaijie, Hu Siyi, et al. ProAgent: Building Proactive Cooperative Agents with Large Language Models[C]//Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence. Palo Alto, CA, USA: AAAI Press, 2024: 17591-17599. |
| 86 | Wu Yue, Tang Xuan, Mitchell T M, et al. SmartPlay: A Benchmark for LLMs as Intelligent Agents[EB/OL]. (2023-10-02) 2023-12-11]. . |
| 87 | Xu Lin, Hu Zhiyuan, Zhou Daquan, et al. MAgIC: Investigation of Large Language Model Powered Multi-agent in Cognition, Adaptability, Rationality and Collaboration[C]//Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA, USA: ACL, 2024: 7315-7332. |
| 88 | Hua Wenyue, Fan Lizhou, Li Lingyao, et al. War and Peace (WarAgent): Large Language Model-based Multi-Agent Simulation of World Wars[EB/OL]. (2023-11-28) [2023-12-11]. . |
| 89 | 孙宇祥, 赵俊杰, 解宇轩, 等. 自生成兵棋AI: 基于大语言模型的双层Agent任务规划[J]. 控制与决策, 2024, 39(12): 3927-3936. |
| Sun Yuxiang, Zhao Junjie, Xie Yuxuan, et al. Self Generated Wargame AI: Double Layer Agent Task Planning Based on Large Language Model[J]. Control and Decision, 2024, 39(12): 3927-3936. | |
| 90 | Lanctot M, Zambaldi V, Gruslys Audrūnas, et al. A Unified Game-theoretic Approach to Multiagent Reinforcement Learning[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 4193-4206. |
| 91 | Marris L, Gemp I, Anthony T, et al. Turbocharging Solution Concepts: Solving NEs, CEs and CCEs with Neural Equilibrium Solvers[C]//Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 5586-5600. |
| 92 | Yao Jian, Liu Weiming, Fu Haobo, et al. Policy Space Diversity for Non-transitive Games[EB/OL]. (2023-06-29) [2023-10-10]. . |
| 93 | Slumbers O, Mguni D H, Blumberg S B, et al. A Game-theoretic Framework for Managing Risk in Multi-agent Systems[C]//Proceedings of the 40th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2023: 32059-32087. |
| 94 | Li Pengdeng, Li Shuxin, Yang Chang, et al. Self-adaptive PSRO: Towards an Automatic Population-based Game Solver[C]//Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence. California: IJCAI, 2024: 139-147. |
| 95 | Mcaleer S, Lanier J, Wang K A, et al. XDO: A Double Oracle Algorithm for Extensive-form Games[C]//35th Conference on Neural Information Processing Systems (NeurIPS 2021). [S.l. : s.n.], 2021: 1-12. |
| 96 | Tang Xiaohang, Le Cong Dinh, McAleer S M, et al. Regret-minimizing Double Oracle for Extensive-form Games[C]//Proceedings of the 40th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2023: 33599-33615. |
| 97 | Konicki C, Chakraborty M, Wellman M P. Exploiting Extensive-Form Structure in Empirical Game-Theoretic Analysis[C]//International Conference on Web and Internet Economics. Cham: Springer International Publishing, 2022: 132-149. |
| 98 | Wang Yongzhao, Wellman M P. Generalized Response Objectives for Strategy Exploration in Empirical Game-theoretic Analysis[C]//Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems. Richland: International Foundation for Autonomous Agents and Multiagent Systems, 2024: 1892-1900. |
| 99 | Black S, Darken C. Scaling Intelligent Agents in Combat Simulations for Wargaming[EB/OL]. (2024-02-08) [2024-03-11]. . |
| 100 | Li Wenhao, Qiao Dan, Wang Baoxiang, et al. Semantically Aligned Task Decomposition in Multi-agent Reinforcement Learning[EB/OL]. (2023-09-30) [2023-12-11]. . |
| 101 | Grayson T, Lilliu S. Mosaic Warfare and Human-machine Symbiosis[J]. Scientific Video Protocols, 2021, 1(1): 1-12. |
| 102 | 郑少秋, 梁汝鹏, 吴浩, 等. 人机共生作战决策系统:发展愿景与关键技术[J]. 火力与指挥控制, 2022, 47(7): 1-6, 13. |
| Zheng Shaoqiu, Liang Rupeng, Wu Hao, et al. Human-machine Symbiosis Combat Decision-making System: Development Vision and Key Technologies[J]. Fire Control & Command Control, 2022, 47(7): 1-6, 13. | |
| 103 | Drake S A, Gatlin A K, Harrison B H, et al. USMC Vertical Takeoff and Landing Aircraft: Human-machine Teaming for Controlling Unmanned Aerial Systems[D]. Monterey: Naval Postgraduate School, 2022. |
| 104 | Nekoei H, Zhao Xutong, Rajendran J, et al. Towards Few-shot Coordination: Revisiting Ad-hoc Teamplay Challenge in the Game of Hanabi[C]//Proceedings of The 2nd Conference on Lifelong Learning Agents. Chia Laguna Resort: PMLR, 2023: 861-877. |
| 105 | Rothfuß S. Human-machine Cooperative Decision Making[M]. [S.l.] : KIT Scientific Publishing, 2022. |
| 106 | van Oijen Joost, Pieter de Marez Oyens. Empowering Military Decision Support through the Synergy of AI and Simulation[C]//The 2023 NATO NMSG Symposium: Simulation: Going Beyond the Limitations of the Real World. [S.l. : s.n.], 2023. |
| 107 | 单时卓, 裴天翼, 刘泽轩. 基于人机混合智能的协同作战研究[J]. 计算机测量与控制, 2024, 32(5): 296-301. |
| Shan Shizhuo, Pei Tianyi, Liu Zexuan. Research on Cooperative Combat Based on Man-machine Combination Intelligence[J]. Computer Measurement & Control, 2024, 32(5): 296-301. |
| [1] | 董志明, 胡忠奇, 戴浩然, 高建成. 基于大语言模型的作战仿真想定自动化生成方法[J]. 系统仿真学报, 2026, 38(5): 1129-1145. |
| [2] | 周子聪, 曾俊杰, 胡越, 朱正秋, 尹全军. 基于次优示例引导的兵棋推演多智能体强化学习方法[J]. 系统仿真学报, 2026, 38(5): 1277-1289. |
| [3] | 彭莱春阳, 叶飞, 郭晓明, 周靖林. X语言仿真大模型:体系架构、关键技术与典型应用[J]. 系统仿真学报, 2026, 38(4): 869-888. |
| [4] | 刘威, 陈德龙, 刘泽, 王锐, 李凯文, 张涛. 基于自适应混合进化的防空反导火力资源分配优化[J]. 系统仿真学报, 2026, 38(4): 959-973. |
| [5] | 刘沛津, 张闽心, 何林, 孙艺阁, 苏庭琪. 面向城市复杂环境视觉地点识别算法研究[J]. 系统仿真学报, 2026, 38(3): 818-828. |
| [6] | 李济廷, 孙毅, 王一戎, 蔺义芹, 贾珺, 丁纲松. 大模型驱动的社交网络多智能体仿真综述[J]. 系统仿真学报, 2026, 38(2): 235-260. |
| [7] | 张明新, 伍瑾轩, 朱睿, 王云龙, 孟文娟, 刘喆, 李煦, 陈小磊, 梁宇轩, 郑毅, 薛向阳. 基于大语言模型智能体的社会认知模拟[J]. 系统仿真学报, 2026, 38(2): 261-277. |
| [8] | 姬鸿远, 卿杜政. 基于模块化推理的态势认知思维链技术研究[J]. 系统仿真学报, 2026, 38(2): 278-293. |
| [9] | 朱玲, 李靖, 张朝辉. 基于改进REA*算法的机器人自适应路径规划[J]. 系统仿真学报, 2026, 38(2): 332-345. |
| [10] | 闫强, 张倩语, 魏娜. 基于演化博弈的生成式人工智能幻觉应对分析[J]. 系统仿真学报, 2026, 38(2): 399-415. |
| [11] | 刘沂青, 张秋阳, 刘春雨, 薛尧, 魏智伟, 冯岩. 语义知识增强的低轨星座频谱效能评估技术[J]. 系统仿真学报, 2026, 38(2): 460-475. |
| [12] | 王一凡, 杨彬, 汪丛军. 基于大模型智能体的多班组施工过程仿真方法[J]. 系统仿真学报, 2026, 38(2): 488-500. |
| [13] | 胥日升, 杨林瑶, 覃缘琪, 王晓, 孙长银. 知识增强大语言模型的区域交通信号控制方法[J]. 系统仿真学报, 2026, 38(2): 518-531. |
| [14] | 魏呈彪, 赵涛岩, 曹江涛, 李平. 深度模糊神经网络的设计和预测[J]. 系统仿真学报, 2025, 37(9): 2200-2210. |
| [15] | 刘子龙, 张磊. 自然环境下改进YOLOv5对小目标苹果的检测[J]. 系统仿真学报, 2025, 37(8): 2124-2138. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
