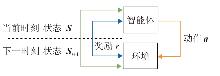
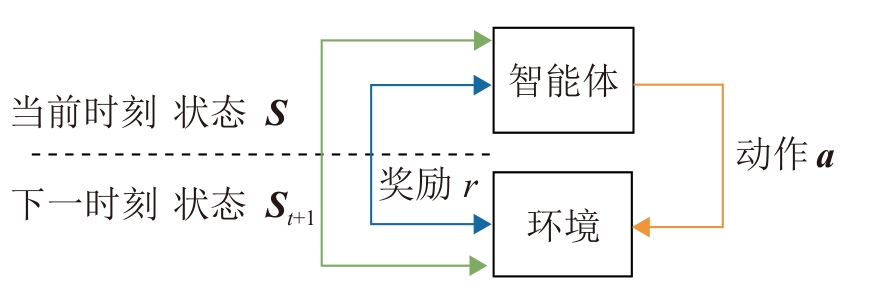
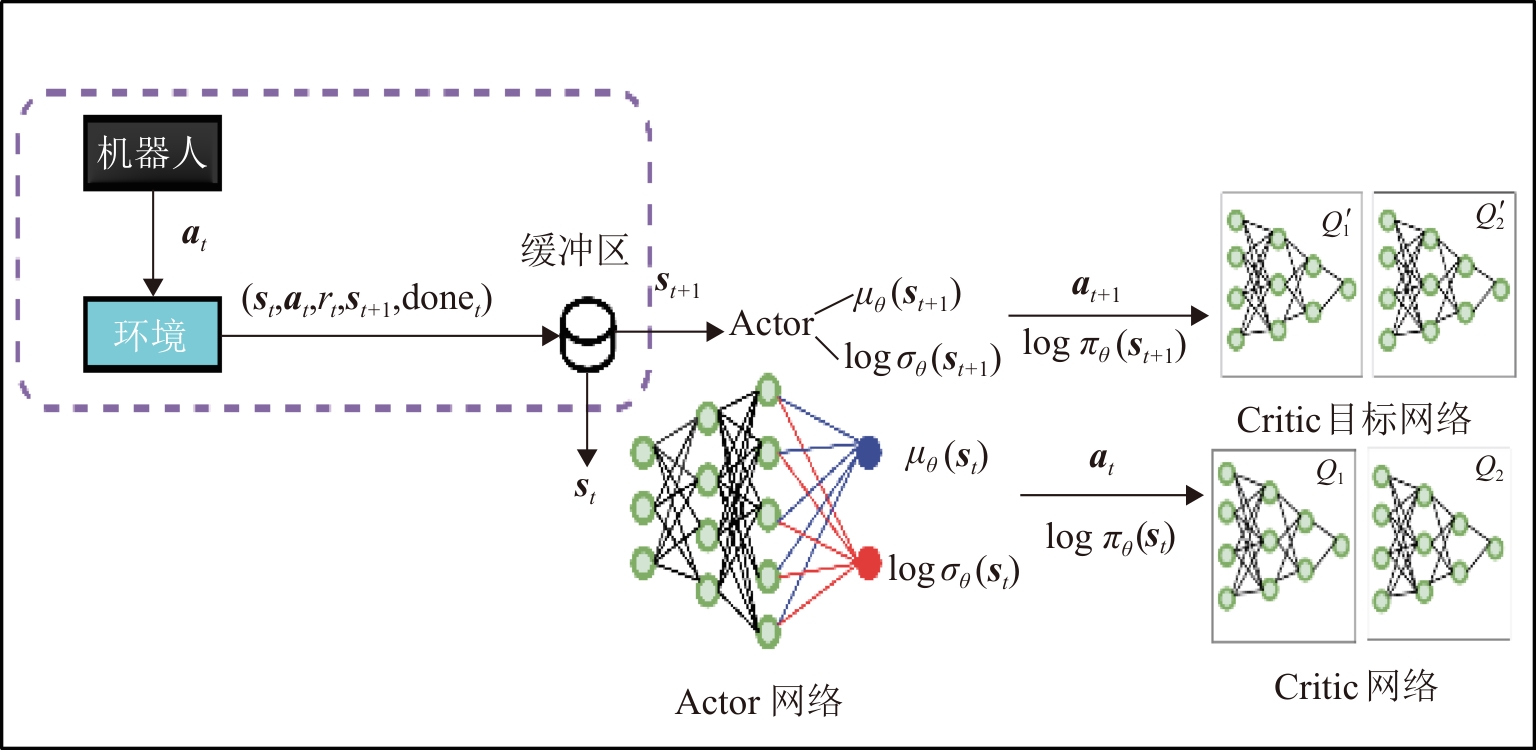
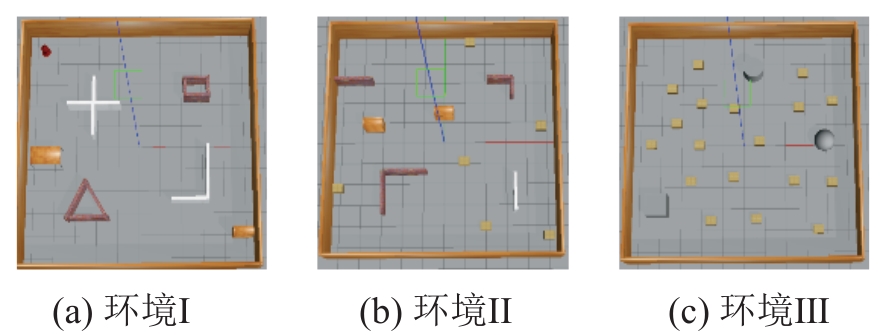
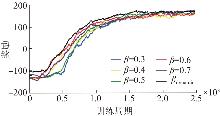
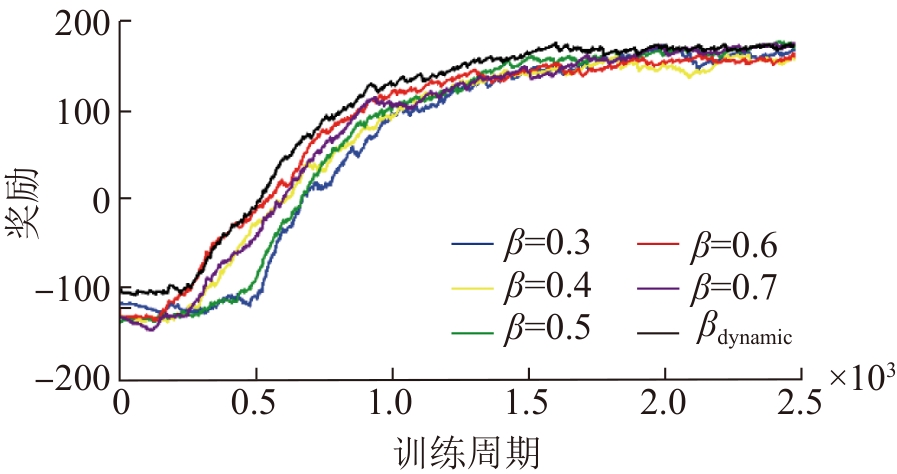
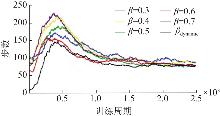
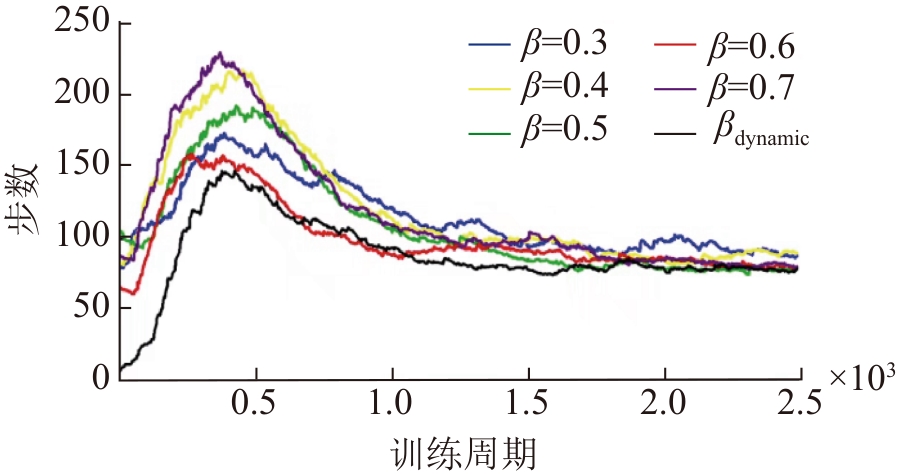
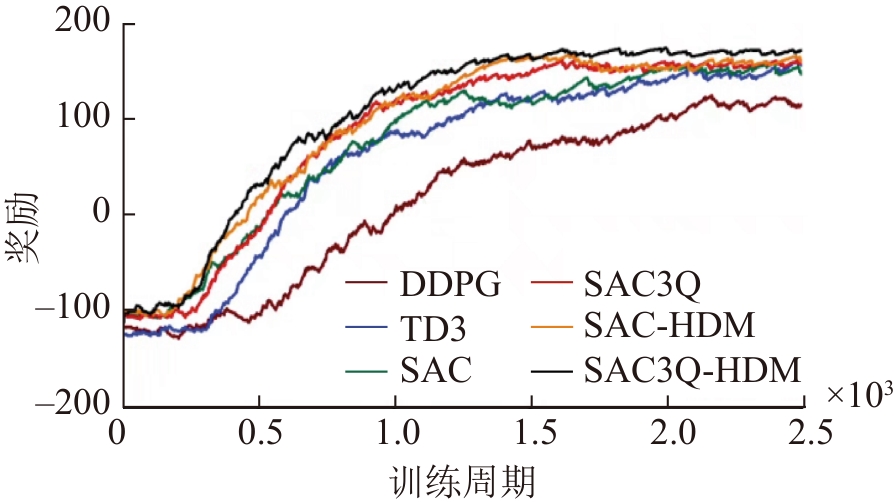
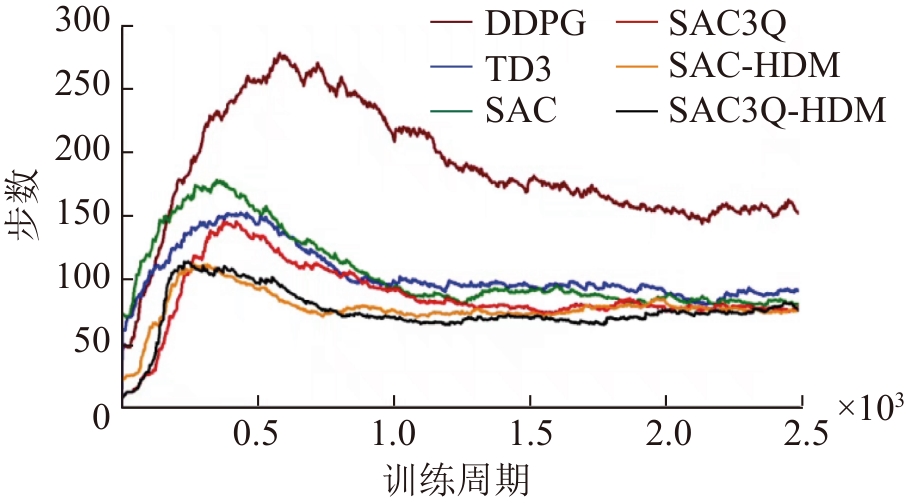
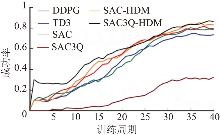
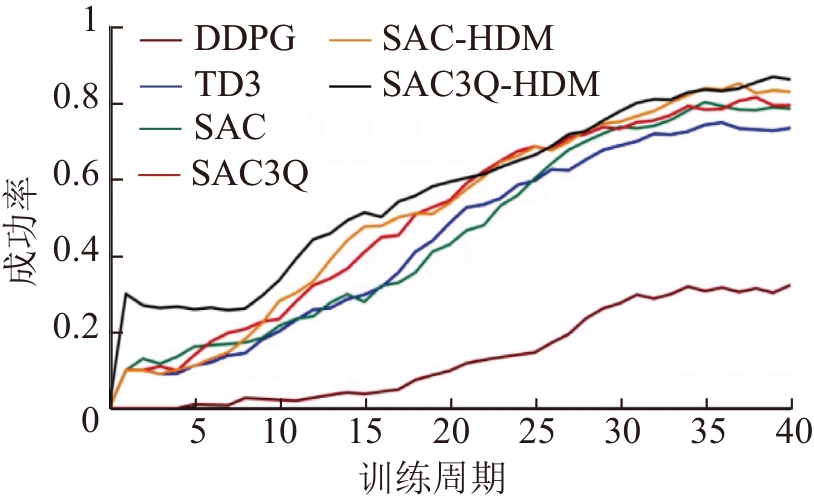
| [1] |
崔炜, 朱发证. 机器人导航的路径规划算法研究综述[J]. 计算机工程与应用, 2023, 59(19): 10-20.
|
|
Cui Wei, Zhu Fazheng. Review of Path Planning Algorithms for Robot Navigation[J]. Computer Engineering and Applications, 2023, 59(19): 10-20.
|
| [2] |
姚得鑫, 伞红军, 王雅如, 等. 移动机器人路径规划中A*算法的改进研究[J]. 系统仿真学报, 2024, 36(11): 2684-2698.
|
|
Yao Dexin, Hongjun San, Wang Yaru, et al. Improvement of A* Algorithm in Path Planning of Mobile Robot[J]. Journal of System Simulation, 2024, 36(11): 2684-2698.
|
| [3] |
巩慧, 倪翠, 王朋, 等. 基于Dijkstra算法的平滑路径规划方法[J]. 北京航空航天大学学报, 2024, 50(2): 535-541.
|
|
Gong Hui, Ni Cui, Wang Peng, et al. A Smooth Path Planning Method Based on Dijkstra Algorithm[J]. Journal of Beijing University of Aeronautics and Astronautics, 2024, 50(2): 535-541.
|
| [4] |
徐强, 徐坚磊, 胡燕海, 等. 基于改进模拟退火遗传算法的机械臂轨迹优化[J]. 系统仿真学报, 2025, 37(2): 404-412.
|
|
Xu Qiang, Xu Jianlei, Hu Yanhai, et al. Trajectory Optimization of Robotic Arm Based on Improved Simulated Annealing Genetic Algorithm[J]. Journal of System Simulation, 2025, 37(2): 404-412.
|
| [5] |
鲍惠芳, 方杰, 张进思, 等. 基于改进蚁群算法的低碳冷链配送路径优化[J]. 系统仿真学报, 2024, 36(1): 183-194.
|
|
Bao Huifang, Fang Jie, Zhang Jinsi, et al. Optimization on Cold Chain Distribution Routes Considering Carbon Emissions Based on Improved Ant Colony Algorithm[J]. Journal of System Simulation, 2024, 36(1): 183-194.
|
| [6] |
Gao Kaizhou, Gao Minglong, Zhou Mengchu, et al. Artificial Intelligence Algorithms in Unmanned Surface Vessel Task Assignment and Path Planning: A Survey[J]. Swarm and Evolutionary Computation, 2024, 86: 101505.
|
| [7] |
Wu Jingda, Huang Chao, Huang Hailong, et al. Recent Advances in Reinforcement Learning-based Autonomous Driving Behavior Planning: A Survey[J]. Transportation Research Part C: Emerging Technologies, 2024, 164: 104654.
|
| [8] |
Quinones-Ramirez Miguel, Rios-Martinez Jorge, Uc-Cetina Victor. Robot Path Planning Using Deep Reinforcement Learning[EB/OL]. (2023-03-06) [2025-03-18]. .
|
| [9] |
Zhou Qian, Lian Yang, Wu Jiayang, et al. An Optimized Q-learning Algorithm for Mobile Robot Local Path Planning[J]. Knowledge-Based Systems, 2024, 286: 111400.
|
| [10] |
Demelash Abiye Deguale, Yu Lingli, Melikamu Liyih Sinishaw, et al. Enhancing Stability and Performance in Mobile Robot Path Planning with PMR-Dueling DQN Algorithm[J]. Sensors, 2024, 24(5): 1523.
|
| [11] |
Lillicrap Timothy P, Hunt Jonathan J, Pritzel Alexander, et al. Continuous Control with Deep Reinforcement Learning[EB/OL]. (2019-07-05) [2025-03-18]. .
|
| [12] |
Fujimoto Scott, Hoof Herke, Meger David. Addressing Function Approximation Error in Actor-Critic Methods[C]//Proceedings of the 35th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2018: 1587-1596.
|
| [13] |
Zhang Yinmin, Liu Jie, Li Chuming, et al. A Perspective of Q-value Estimation on Offline-to-online Reinforcement Learning[C]//Proceedings of the Thirty-eighth AAAI Conference on Artificial Intelligence and Thirty-sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence. Palo Alto: AAAI Press, 2024: 16908-16916.
|
| [14] |
Ly Adrian, Dazeley Richard, Vamplew Peter, et al. Elastic Step DQN: A Novel Multi-step Algorithm to Alleviate Overestimation in Deep Q-Networks[J]. Neurocomputing, 2024, 576: 127170.
|
| [15] |
Wang Zhengjun, Gao Weifeng, Li Genghui, et al. Path Planning for Unmanned Aerial Vehicle via Off-policy Reinforcement Learning with Enhanced Exploration[J]. IEEE Transactions on Emerging Topics in Computational Intelligence, 2024, 8(3): 2625-2639.
|
| [16] |
Luo Xuqiong, Wang Qiyuan, Gong Hongfang, et al. UAV Path Planning Based on the Average TD3 Algorithm with Prioritized Experience Replay[J]. IEEE Access, 2024, 12: 38017-38029
|
| [17] |
Cimurs Reinis, Il Hong Suh, Jin Han Lee. Goal-driven Autonomous Exploration Through Deep Reinforcement Learning[J]. IEEE Robotics and Automation Letters, 2022, 7(2): 730-737.
|
| [18] |
Wang Jiaqi, Han Huiyan, Han Xie, et al. Reinforcement Learning Path Planning Method Incorporating Multi-step Hindsight Experience Replay for Lightweight Robots[J]. Displays, 2024, 84: 102796.
|
| [19] |
Khlif Nesrine, Nahla Khraief, Safya Belghith. Reinforcement Learning with Modified Exploration Strategy for Mobile Robot Path Planning[J]. Robotica, 2023, 41(9): 2688-2702.
|
| [20] |
Haarnoja Tuomas, Zhou Aurick, Hartikainen Kristian, et al. Soft Actor-Critic Algorithms and Applications[EB/OL]. (2019-01-29) [2025-03-18]. .
|