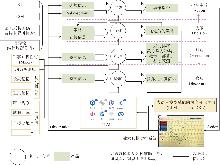
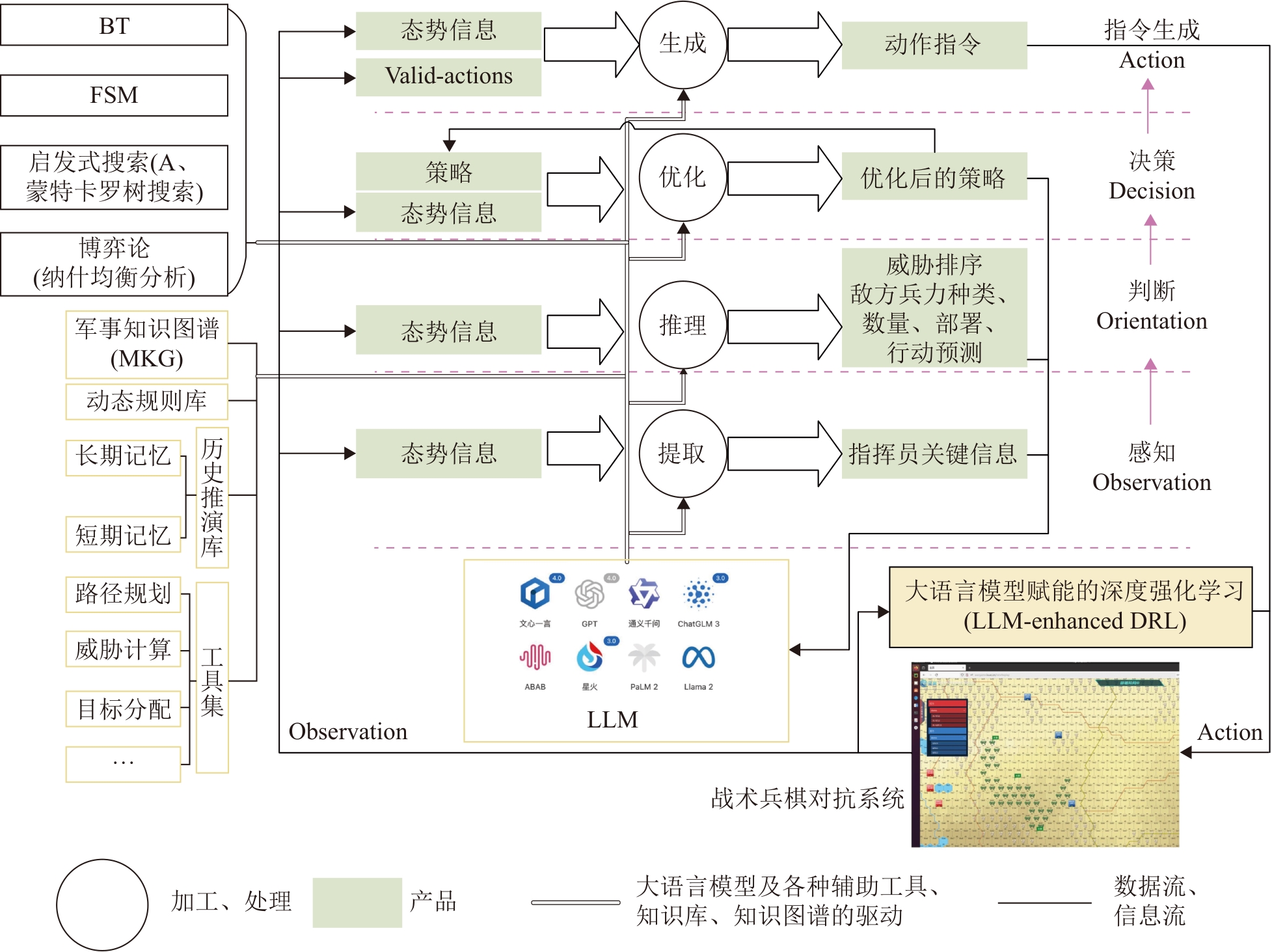
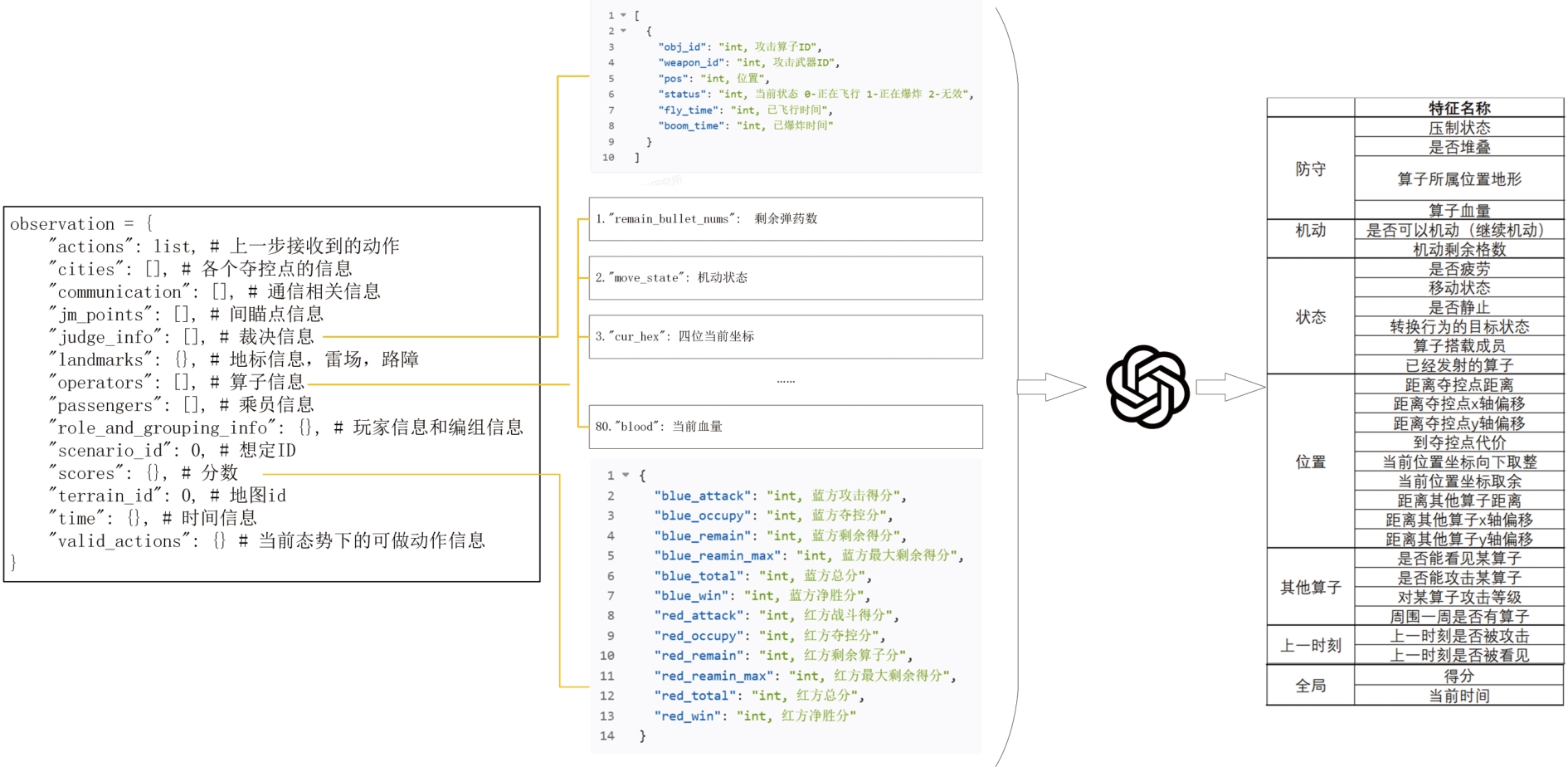
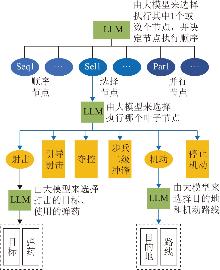
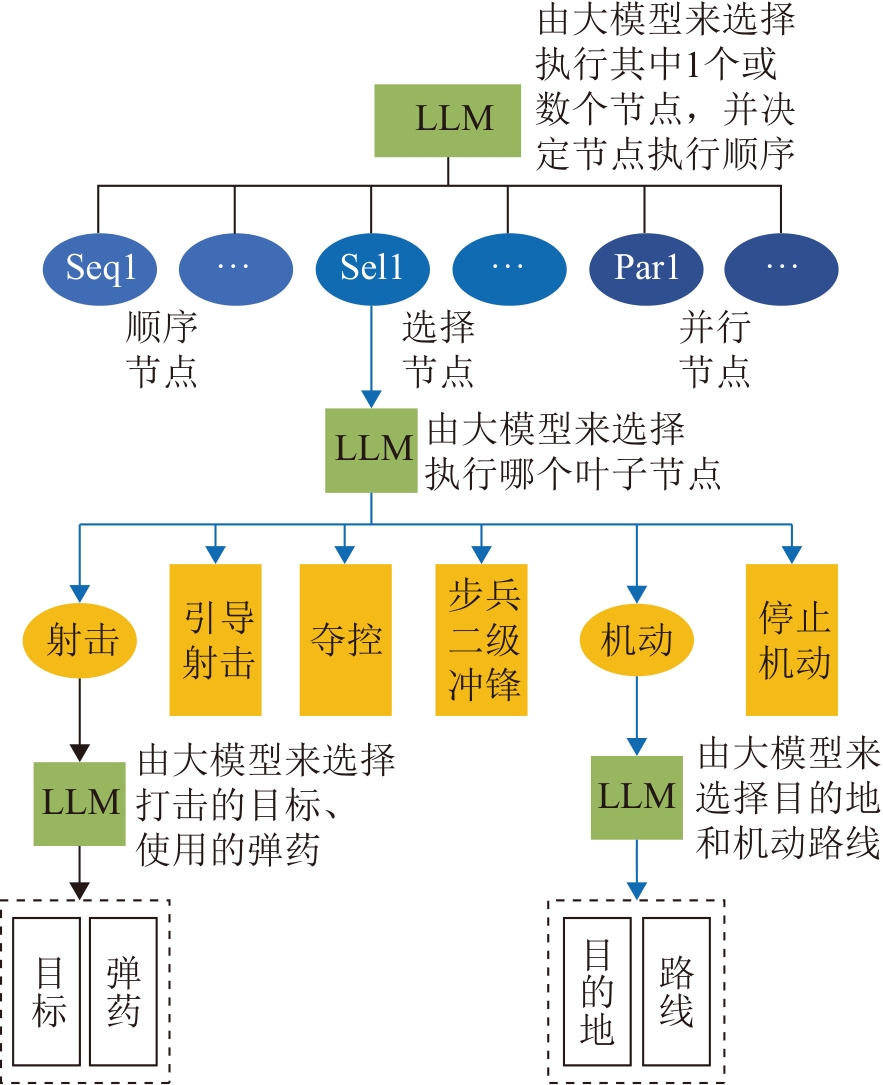
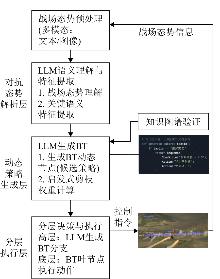
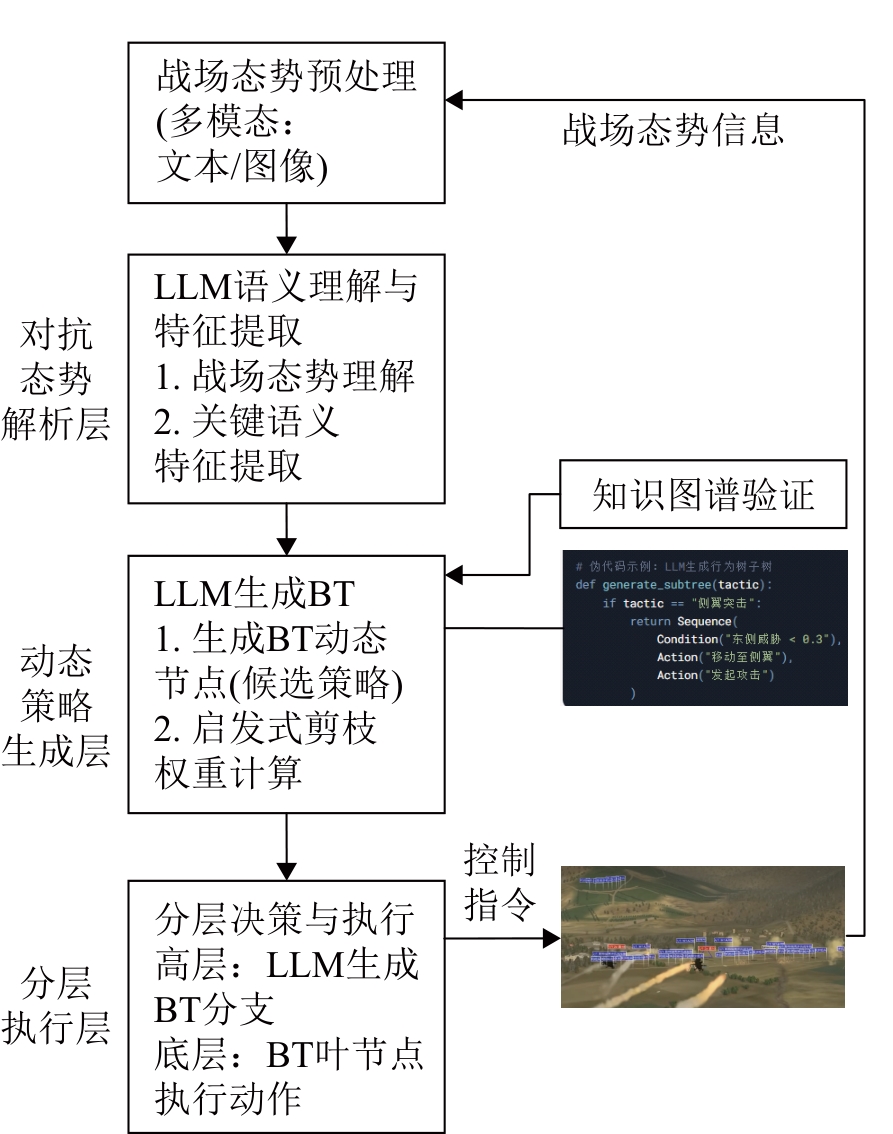
| [1] |
刘大勇, 董志明, 刘倬立, 等. 大模型在陆战兵棋推演中的应用研究[C]//首届全国大模型与决策智能大会论文集. 北京: 中国指挥与控制学会, 2024: 43-53.
|
|
Liu Dayong, Dong Zhiming, Liu Zhuoli, et al. Research on the Application of Large Models in Army Tactical Chess Simulation[C]//Proceedings of the First National Conference on Large Models and Decision Intelligence. Beijing: Chinese Institute of Command and Control, 2024: 43-53.
|
| [2] |
贾晨星, 明月伟, 葛承垄. 基于思维模拟的虚拟指挥员作战决策模型[J]. 指挥控制与仿真, 2025, 47(1): 44-52.
|
|
Jia Chenxing, Ming Yuewei, Ge Chenglong. Virtual Commander's Operational Decision-making Model Based on Thinking Simulation[J]. Command Control & Simulation, 2025, 47(1): 44-52.
|
| [3] |
Ji Shaoxiong, Pan Shirui, Cambria Erik, et al. A Survey on Knowledge Graphs: Representation, Acquisition, and Applications[J]. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(2): 494-514.
|
| [4] |
Wang Zhen, Zhang Jianwen, Feng Jianlin, et al. Knowledge Graph Embedding by Translating on Hyperplanes[C]//Proceedings of the Twenty-eighth AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2014: 1112-1119.
|
| [5] |
王保魁, 吴琳, 胡晓峰, 等. 基于时序图的作战指挥行为知识表示学习方法[J]. 系统工程与电子技术, 2020, 42(11): 2520-2528.
|
|
Wang Baokui, Wu Lin, Hu Xiaofeng, et al. Operations Command Behavior Knowledge Representation Learning Method Based on Sequential Graph[J]. Systems Engineering and Electronics, 2020, 42(11): 2520-2528.
|
| [6] |
Vinyals O, Babuschkin I, Czarnecki W M, et al. Grandmaster Level in StarCraft II Using Multi-agent Reinforcement Learning[J]. Nature, 2019, 575(7782): 350-354.
|
| [7] |
刘玮, 张永亮, 程旭. 基于深度强化学习的人机智能对抗综述[J]. 指挥信息系统与技术, 2023, 14(2): 28-37.
|
|
Liu Wei, Zhang Yongliang, Cheng Xu. Survey of Human-Computer Intelligence Gaming Based on Deep Reinforcement Learning[J]. Command Information System and Technology, 2023, 14(2): 28-37.
|
| [8] |
Shah Dhruv, Michael Robert Equi, Osiński Błażej, et al. Navigation with Large Language Models: Semantic Guesswork as a Heuristic for Planning[C]//Proceedings of The 7th Conference on Robot Learning. Atlanta: PMLR, 2023: 2683-2699.
|
| [9] |
Carta Thomas, Romac Clément, Wolf Thomas, et al. Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning[C]//Proceedings of the 40th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2023: 3676-3713.
|
| [10] |
陈新宇, 王卫斌, 陆光辉. 基于AI agent的6G内生智能技术框架及其应用[J]. 移动通信, 2024, 48(7): 28-32.
|
|
Chen Xinyu, Wang Weibin, Lu Guanghui. 6G Native Intelligent Technology Framework and its Application Based on AI Agent[J]. Mobile Communications, 2024, 48(7): 28-32.
|
| [11] |
孙宇祥, 赵俊杰, 解宇轩, 等. 自生成兵棋AI: 基于大语言模型的双层Agent任务规划[J]. 控制与决策, 2024, 39(12): 3927-3936.
|
|
Sun Yuxiang, Zhao Junjie, Xie Yuxuan, et al. Self Generated Wargame AI:Double Layer Agent Task Planning Based on Large Language Model[J]. Control and Decision, 2024, 39(12): 3927-3936.
|
| [12] |
Weng Lilian. LLM Powered Autonomous Agents[EB/OL]. (2023-06-23) [2025-04-12]. .
|
| [13] |
张奇, 桂韬, 郑锐, 等. 大规模语言模型: 从理论到实践[M]. 北京: 电子工业出版社, 2024.
|
|
Zhang Qi, Gui Tao, Zheng Rui, et al. Large scale Language Models: From Theory to Practice[M]. Beijing: Electronic Industry Press, 2024.
|
| [14] |
高昂, 段莉, 张国辉, 等. 计算机生成兵力行为建模发展现状[J]. 计算机工程与应用, 2019, 55(19): 43-51.
|
|
Gao Ang, Duan Li, Zhang Guohui, et al. Development Status of Computer Generated Force Behavior Modeling[J]. Computer Engineering and Applications, 2019, 55(19): 43-51.
|
| [15] |
OpenAI. GPT-4 Technical Report[EB/OL]. (2023-03-15) [2025-03-30]. .
|
| [16] |
DeepSeek-R 1多版本性能深度实测[EB/OL]. (2025-09-23) [2026-02-06]. .
|
|
DeepSeek-R1 Multi Version Performance Deep Testing[EB/OL]. (2025-09-23) [2026-02-06] .
|
| [17] |
王文君, 刘波, 王勇. 美军指挥员关键信息需求研究及启示[C]//第十二届中国指挥控制大会论文集(上册). 北京: 中国指挥与控制学会, 2024: 69-72.
|
|
Wang Wenjun, Liu Bo, Wang Yong. Research and Enlightenment on Critical Information Requirements for U.S. Military Commanders[C]//Proceedings of the 12th China Command and Control Conference (Vol 1). Beijing: Chinese Institute of Command and Control, 2024: 69-72.
|
| [18] |
杨杰. 面向计算机生成兵力的行为树决策模型生成方法研究[D]. 长沙: 国防科技大学, 2021.
|
|
Yang Jie. Research on Generation Method of Behavior Tree Decision Model for Computer Generated Forces[D]. Changsha: National University of Defense Technology, 2021.
|
| [19] |
刘小玲, 潘巨辉. FSM在海军作战仿真CGF中的应用[J]. 计算机仿真, 2007, 24(8): 24-27.
|
|
Liu Xiaoling, Pan Juhui. Finite State Machine and Its application to CGF of Naval Combat Simulation[J]. Computer Simulation, 2007, 24(8): 24-27.
|
| [20] |
Cao Yuji, Zhao Huan, Cheng Yuheng, et al. Survey on Large Language Model-enhanced Reinforcement Learning: Concept, Taxonomy, and Methods[EB/OL]. (2024-10-30) [2025-05-23]. .
|