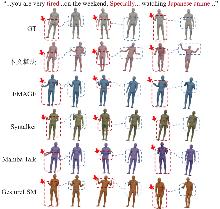
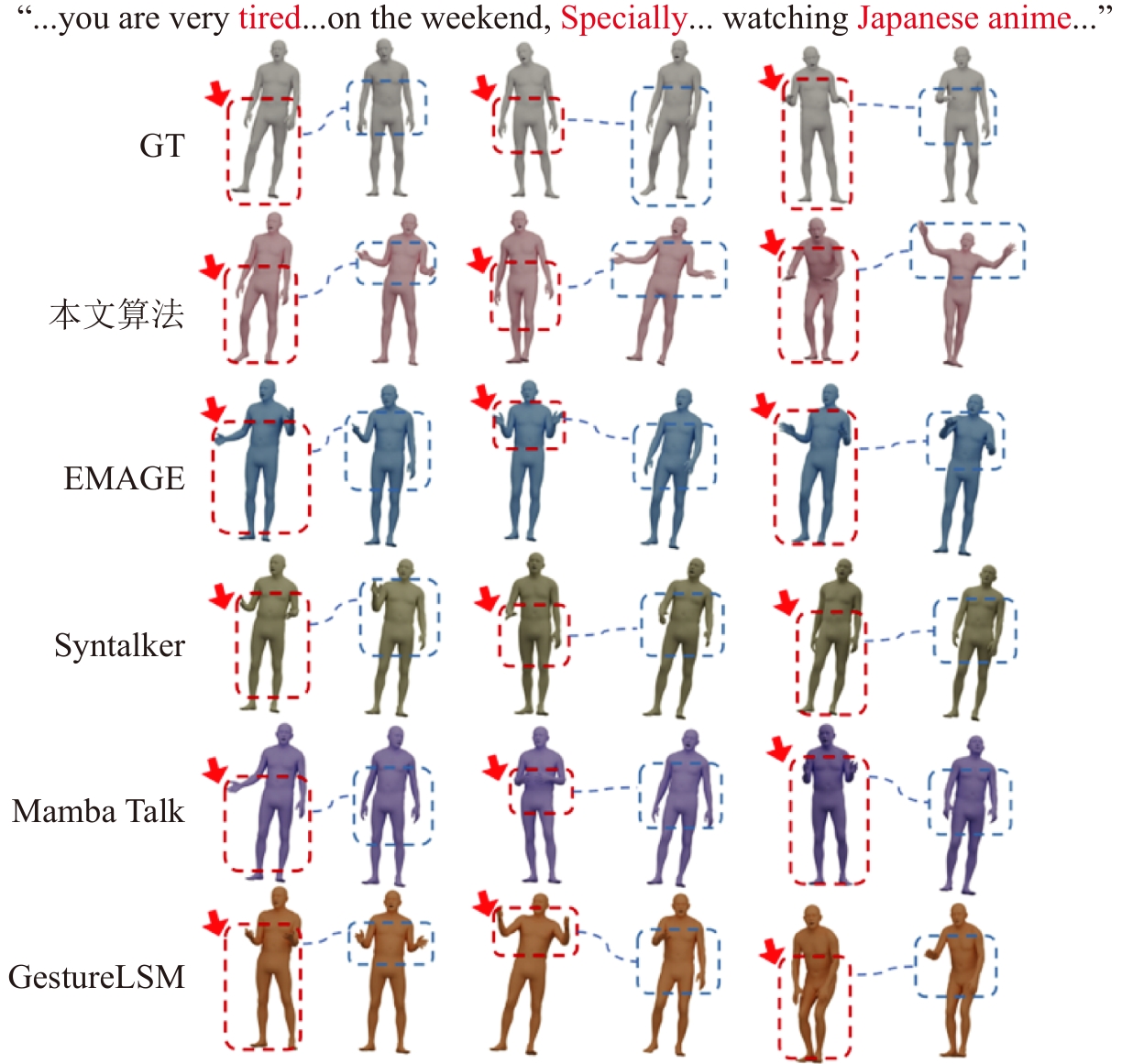
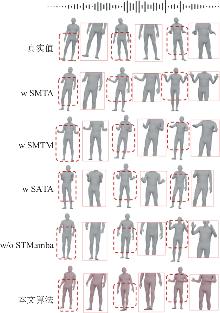
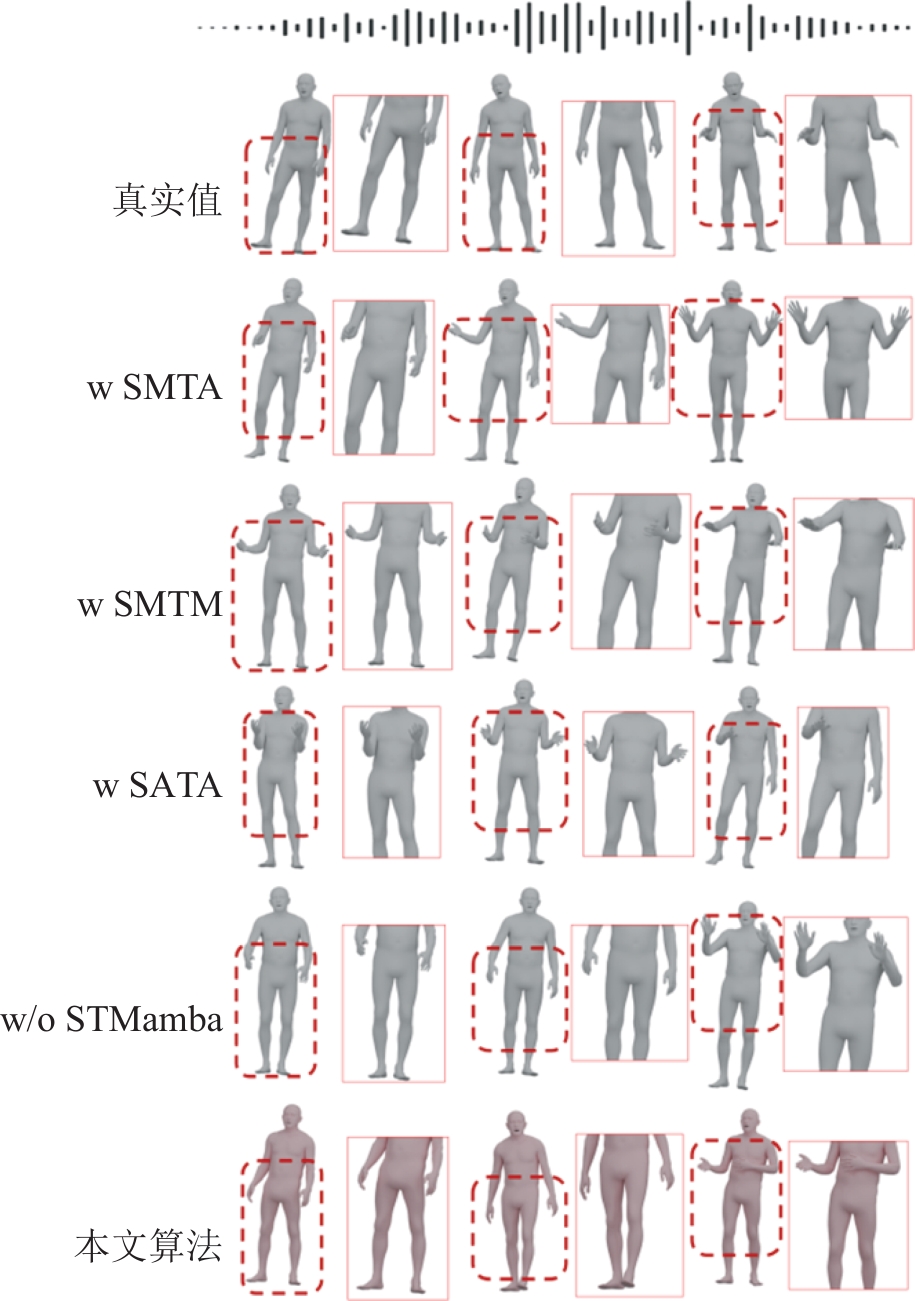
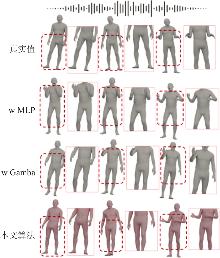
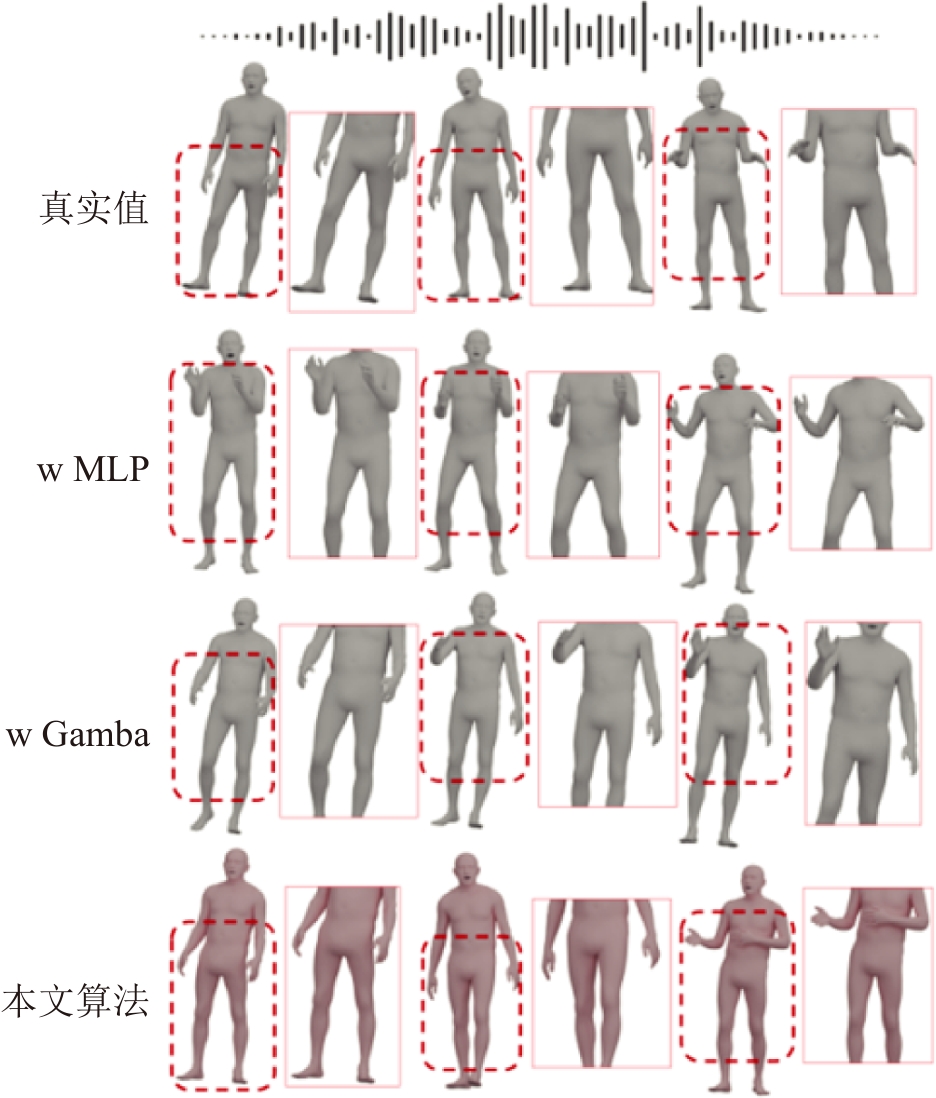
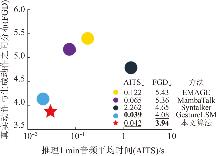
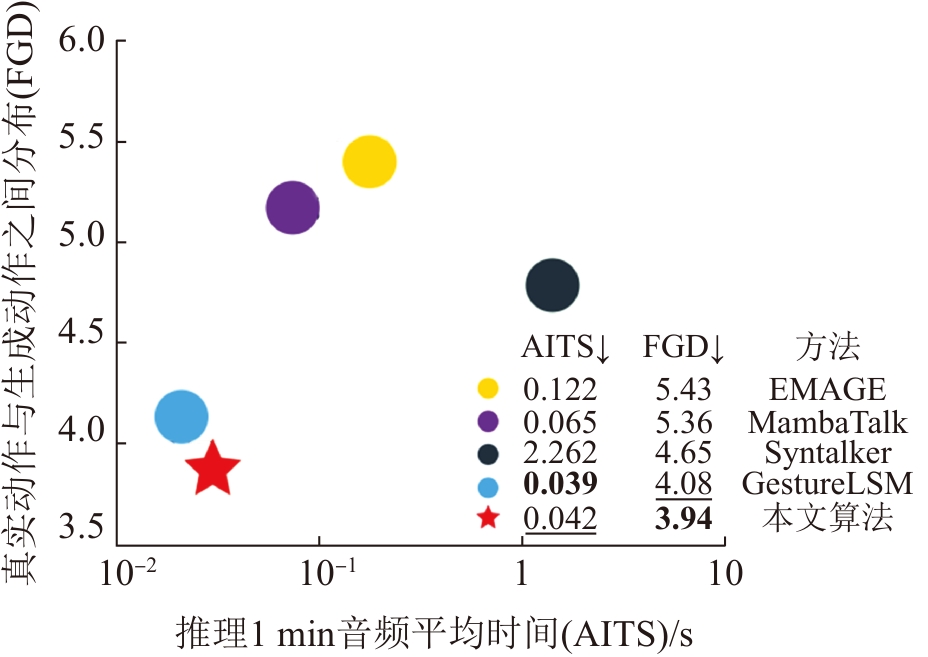
| [1] |
Liu Haiyang, Zhu Zihao, Iwamoto Naoya, et al. BEAT: A Large-scale Semantic and Emotional Multi-modal Dataset for Conversational Gestures Synthesis[C]//Computer Vision – ECCV 2022. Cham: Springer Nature Switzerland, 2022: 612-630.
|
| [2] |
Liu Haiyang, Zhu Zihao, Becherini Giorgio, et al. EMAGE: Towards Unified Holistic Co-speech Gesture Generation via Expressive Masked Audio Gesture Modeling[C]//2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2024: 1144-1154.
|
| [3] |
Qi Xingqun, Pan Jiahao, Li Peng, et al. Weakly-supervised Emotion Transition Learning for Diverse 3D Co-speech Gesture Generation[C]//2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2024: 10424-10434.
|
| [4] |
Xu Zunnan, Lin Yukang, Han Haonan, et al. MambaTalk: Efficient Holistic Gesture Synthesis with Selective State Space Models[C]//Proceedings of the 38th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2024: 20055-20080.
|
| [5] |
Alexanderson Simon, Gustav Eje Henter, Kucherenko Taras, et al. Style-controllable Speech-driven Gesture Synthesis Using Normalising Flows[J]. Computer Graphics Forum, 2020, 39(2): 487-496.
|
| [6] |
Chen Bohong, Li Yumeng, Ding Yaoxiang, et al. Enabling Synergistic Full-body Control in Prompt-based Co-speech Motion Generation[C]//Proceedings of the 32nd ACM International Conference on Multimedia. New York: ACM, 2024: 6774-6783.
|
| [7] |
Yang Sicheng, Wu Zhiyong, Li Minglei, et al. DiffuseStyleGesture: Stylized Audio-driven Co-speech Gesture Generation with Diffusion Models[C]//Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence. California: IJCAI, 2023: 5860-5868.
|
| [8] |
Gu A, Dao T. Mamba: Linear-time Sequence Modeling with Selective State Spaces[EB/OL]. (2024-05-31) [2025-04-05]. .
|
| [9] |
Dao T, Gu A. Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality[C]//Proceedings of the 41st International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2024: 10041-10071.
|
| [10] |
Liu Pinxin, Song Luchuan, Huang Junhua, et al. GestureLSM: Latent Shortcut Based Co-speech Gesture Generation with Spatial-temporal Modeling[EB/OL]. (2025-01-31) [2025-04-05]. .
|
| [11] |
Zhang Mingyuan, Li Huirong, Cai Zhongang, et al. FineMoGen: Fine-grained Spatio-temporal Motion Generation and Editing[C]//Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 13981-13992.
|
| [12] |
Liu Xian, Wu Qianyi, Zhou Hang, et al. Learning Hierarchical Cross-modal Association for Co-speech Gesture Generation[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2022: 10452-10462.
|
| [13] |
Ao Tenglong, Gao Qingzhe, Lou Yuke, et al. Rhythmic Gesticulator: Rhythm-aware Co-speech Gesture Synthesis with Hierarchical Neural Embeddings[J]. ACM Transactions on Graphics, 2022, 41(6): 209.
|
| [14] |
Yi Hongwei, Liang Hualin, Liu Yifei, et al. Generating Holistic 3D Human Motion from Speech[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2023: 469-480.
|
| [15] |
Hamza Mughal M, Dabral Rishabh, C J Scholman Merel, et al. Retrieving Semantics from the Deep: An RAG Solution for Gesture Synthesis[C]//2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2025: 16578-16588.
|
| [16] |
Chen Changan, Zhang Juze, Lakshmikanth S K, et al. The Language of Motion: Unifying Verbal and Non-verbal Language of 3D Human Motion[EB/OL]. (2024-12-13) [2025-04-05]. .
|
| [17] |
Frans K, Hafner D, Levine S, et al. One Step Diffusion Via Shortcut Models[EB/OL]. (2024-10-16) [2025-08-12]. .
|
| [18] |
Lenz B, Lieber O, Arazi A, et al. Jamba: Hybrid Transformer-Mamba Language Models[C]//ICLR 2025 Conference. New York: ICLR, 2025: 1-26.
|
| [19] |
Wang Junxiong, Paliotta Daniele, May A, et al. The Mamba in the Llama: Distilling and Accelerating Hybrid Models[C]//Proceedings of the 38th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2024: 62432-62457.
|
| [20] |
Touvron H, Lavril T, Izacard G, et al. LLaMA: Open and Efficient Foundation Language Models[EB/OL]. (2023-02-27) [2025-04-05]. .
|
| [21] |
Zhu Lianghui, Liao Bencheng, Zhang Qian, et al. Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model[C]//Proceedings of the 41st International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2024: 62429-62442.
|
| [22] |
Liu Yue, Tian Yunjie, Zhao Yuzhong, et al. VMamba: Visual State Space Model[C]//Proceedings of the 38th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2024: 103031-103063.
|
| [23] |
Tao Hu Vincent, Stefan Andreas Baumann, Gui Ming, et al. ZigMa: A DiT-style Zigzag Mamba Diffusion Model[C]//Computer Vision – ECCV 2024. Cham: Springer Nature Switzerland, 2025: 148-166.
|
| [24] |
Peebles W, Xie Saining. Scalable Diffusion Models with Transformers[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 4172-4182.
|
| [25] |
Shen Qiuhong, Wu Zike, Yi Xuanyu, et al. Gamba: Marry Gaussian Splatting with Mamba for Single View 3D Reconstruction[EB/OL]. (2024-05-24) [2025-04-05]. .
|
| [26] |
Kerbl Bernhard, Kopanas Georgios, Leimkuehler Thomas, et al. 3D Gaussian Splatting for Real-time Radiance Field Rendering[J]. ACM Transactions on Graphics, 2023, 42(4): 139.
|
| [27] |
Zhang Zeyu, Liu Akide, Reid Ian, et al. Motion Mamba: Efficient and Long Sequence Motion Generation[C]//Computer Vision – ECCV 2024. Cham: Springer Nature Switzerland, 2025: 265-282.
|
| [28] |
Fu Chencan, Wang Yabiao, Zhang Jiangning, et al. MambaGesture: Enhancing Co-speech Gesture Generation with Mamba and Disentangled Multi-modality Fusion[C]//Proceedings of the 32nd ACM International Conference on Multimedia. New York: ACM, 2024: 10794-10803.
|
| [29] |
Rombach Robin, Blattmann Andreas, Lorenz Dominik, et al. High-resolution Image Synthesis with Latent Diffusion Models[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2022: 10674-10685.
|
| [30] |
Lee S, Hoover B, Strobelt H, et al. Diffusion Explainer: Visual Explanation for Text-to-image Stable Diffusion[C]//2024 IEEE Visualization and Visual Analytics (VIS). Piscataway: IEEE, 2024: 96-100.
|
| [31] |
林馨怡, 吴泓嘉, 袁稚庭, 等. 基于图像提取与修复的计算机辅助古画印章分析[J]. 计算机辅助设计与图形学学报, 2025, 37(2): 254-264.
|
|
Lin Xinyi, Wu Hongjia, Yuan Zhiting, et al. Computer Aided Analysis of Ancient Painting Seals Based on Image Extraction and Restoration[J]. Journal of Computer-Aided Design & Computer Graphics, 2025, 37(2): 254-264.
|
| [32] |
Kim Taehoon, Kang ChanHee, Park JaeHyuk, et al. Human Motion Aware Text-to-video Generation with Explicit Camera Control[C]//2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). Piscataway: IEEE, 2024: 5069-5078.
|
| [33] |
Tevet G, Raab S, Gordon B, et al. Human Motion Diffusion Model[C]//ICLR 2023 Conference. New York: ICLR, 2023: 1-16.
|
| [34] |
Chen Xin, Jiang Biao, Liu Wen, et al. Executing Your Commands via Motion Diffusion in Latent Space[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2023: 18000-18010.
|
| [35] |
Xie Yiming, Jampani V, Zhong Lei, et al. OmniControl: Control Any Joint at Any Time for Human Motion Generation[C]//ICLR 2024 Conference. New York: ICLR, 2024: 1-19.
|
| [36] |
Zhang Lümin, Rao Anyi, Agrawala M. Adding Conditional Control to Text-to-image Diffusion Models[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 3813-3824.
|
| [37] |
Zhou Yanqi, Lei Tao, Liu Hanxiao, et al. Mixture-of-experts with Expert Choice Routing[EB/OL]. (2022-10-14) [2025-04-05]. .
|
| [38] |
Tseng J, Castellon R, Liu C K. EDGE: Editable Dance Generation from Music[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2023: 448-458.
|
| [39] |
石敏, 孙碧莲, 朱登明, 等. KM 2D: 舞蹈动作基元符号和音乐语义驱动的舞蹈动画生成方法[J/OL]. 计算机辅助设计与图形学学报. (2025-03-15) [2025-08-12]. .
|
|
Shi Min, Sun Bilian, Zhu Dengming, et al. KM 2D: Method for Generating Dance Animation Driven by Dance Movement Primitives and Musical Semantics[J/OL]. Journal of Computer-aided Design & Computer Graphics. (2025-03-15) [2025-08-12]. .
|
| [40] |
李晨光, 温玉辉, 景宇宸, 等. 体型感知的音乐驱动舞蹈动作风格化生成[J/OL]. 计算机辅助设计与图形学学报. (2025-02-07) [2025-08-12]. .
|
|
Li Chenguang, Wen Yuhui, Jing Yuchen, et al. Shape-aware Stylized Dance Motion Generation Driven by Music[J/OL]. Journal of Computer-aided Design & Computer Graphics. (2025-02-07) [2025-08-12]. .
|
| [41] |
Ao Tenglong, Zhang Zeyi, Liu Libin. GestureDiffuCLIP: Gesture Diffusion Model with CLIP Latents[J]. ACM Transactions on Graphics, 2023, 42(4): 42.
|
| [42] |
Radford A, Kim J W, Hallacy C, et al. Learning Transferable Visual Models from Natural Language Supervision[C]//Proceedings of the 38th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2021: 8748-8763.
|
| [43] |
Chen Junming, Liu Yunfei, Wang Jianan, et al. DiffSHEG: A Diffusion-based Approach for Real-time Speech-driven Holistic 3D Expression and Gesture Generation[C]//2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2024: 7352-7361.
|
| [44] |
王愫, 刘月林, 孙利. 视觉感知数据驱动的产品造型智能生成设计方法[J/OL]. 计算机辅助设计与图形学学报. (2025-02-17) [2025-08-12]. .
|
|
Wang Su, Liu Yuelin, Sun Li. An Intelligent Generative Design Method for Product Styling Driven by Visual Perception Data[J/OL]. Journal of Computer-Aided Design & Computer Graphics. (2025-02-17) [2025-08-12]. .
|