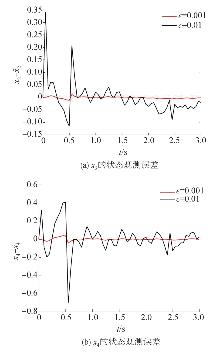
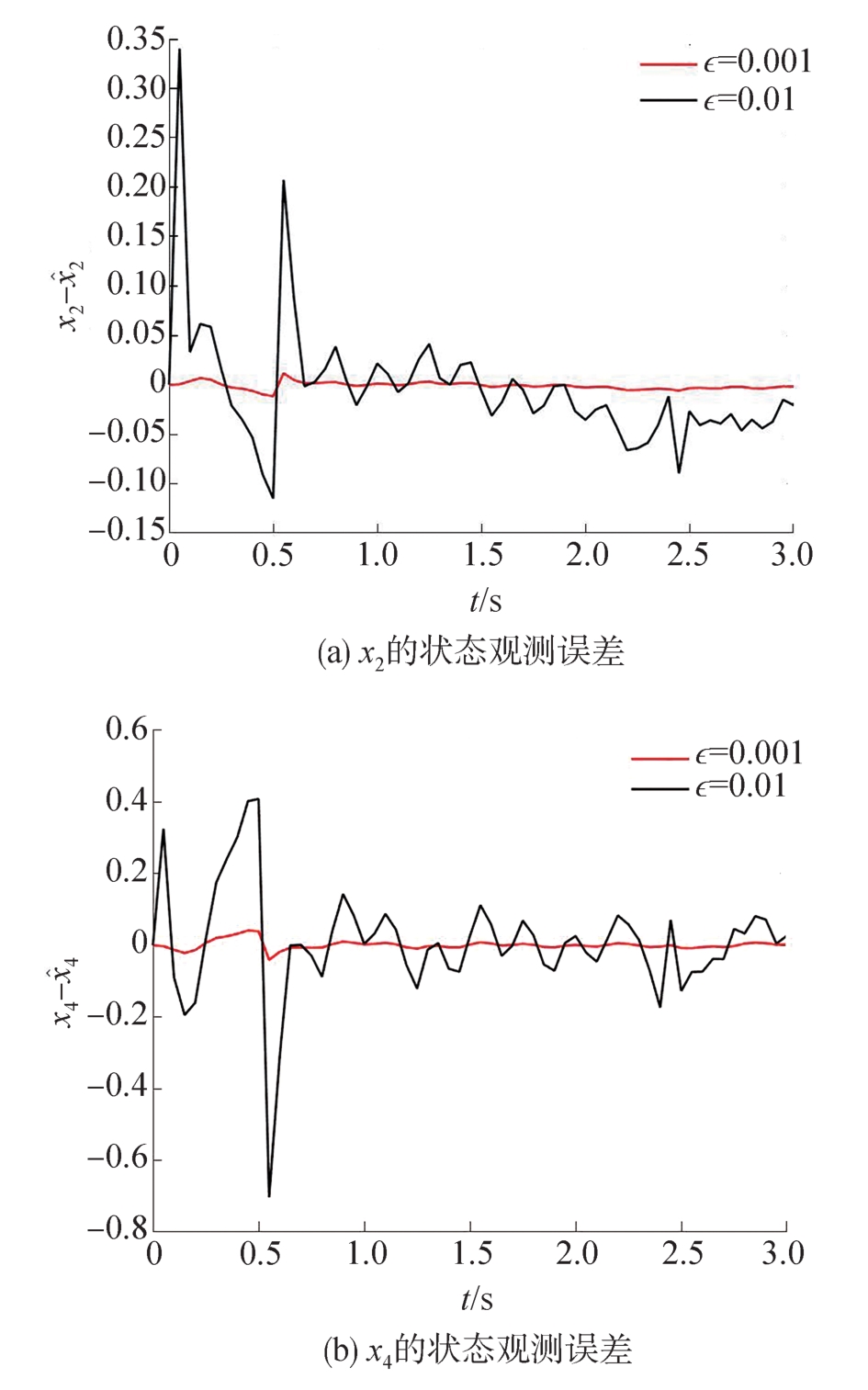
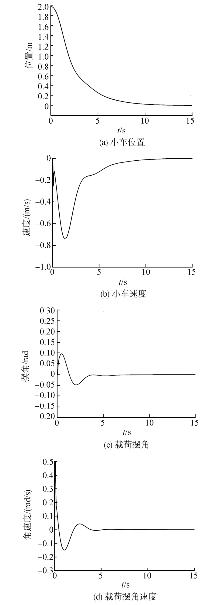
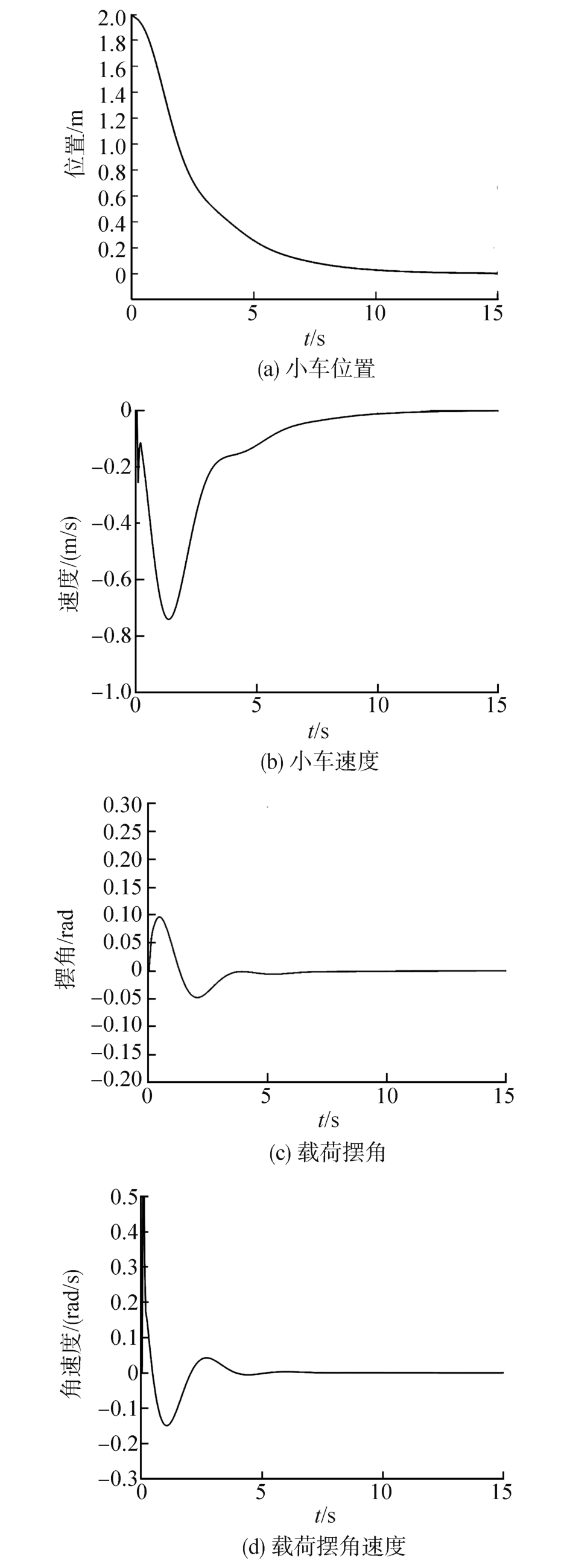
| [1] |
邵雪卷, 李瑶, 张井岗, 等. 桥式起重机轨迹规划的方法研究[J]. 系统仿真学报, 2019, 31(5): 971-977.
|
|
Shao Xuejuan, Li Yao, Zhang Jinggang, et al. Trajectory Planning Method of Overhead Crane[J]. Journal of System Simulation, 2019, 31(5): 971-977.
|
| [2] |
Liu Diantong, Yi Jianqiang, Zhao Dongbin, et al. Adaptive Sliding Mode Fuzzy Control for a Two-dimensional Overhead Crane[J]. Mechatronics, 2005, 15(5): 505-522.
|
| [3] |
Almutairi Naif B, Zribi Mohamed. Sliding Mode Control of a Three-dimensional Overhead Crane[J]. Journal of Vibration and Control, 2009, 15(11): 1679-1730.
|
| [4] |
Yoshida Yasuo. Feedback Control and Time-optimal Control About Overhead Crane by Visual Servo and These Combination Control[M]. London: IntechOpen, 2011.
|
| [5] |
Paiewonsky B. Optimal Control: A Review of Theory and Practice[J]. AIAA Journal, 1965, 3(11): 1985-2006.
|
| [6] |
Trélat E. Optimal Control and Applications to Aerospace: Some Results and Challenges[J]. Journal of Optimization Theory and Applications, 2012, 154(3): 713-758.
|
| [7] |
Dempster Rowan, Al-Sharman Mohammad, Rayside Derek, et al. Real-time Unified Trajectory Planning and Optimal Control for Urban Autonomous Driving Under Static and Dynamic Obstacle Constraints[C]//2023 IEEE International Conference on Robotics and Automation (ICRA). Piscataway: IEEE, 2023: 10139-10145.
|
| [8] |
Li Yongqiang, Hou Zhongsheng, Feng Yuanjing, et al. Data-driven Approximate Value Iteration with Optimality Error Bound Analysis[J]. Automatica, 2017, 78: 79-87.
|
| [9] |
Guo Lei, Zhao Han. Online Adaptive Optimal Control Algorithm Based on Synchronous Integral Reinforcement Learning with Explorations[J]. Neurocomputing, 2023, 520: 250-261.
|
| [10] |
Song Ruizhuo, Zhu Liao. Stable Value Iteration for Two-player Zero-sum Game of Discrete-time Nonlinear Systems Based on Adaptive Dynamic Programming[J]. Neurocomputing, 2019, 340: 180-195.
|
| [11] |
Su Hanguang, Zhang Huaguang, Zhang Kun, et al. Online Reinforcement Learning for a Class of Partially Unknown Continuous-time Nonlinear Systems via Value Iteration[J]. Optimal Control Applications & Methods, 2018, 39(2): 1011-1028.
|
| [12] |
Wang Chenglong, Fang Haiyang, He Shuping. Adaptive Optimal Controller Design for a Class of LDI-based Neural Network Systems with Input Time-delays[J]. Neurocomputing, 2020, 385: 292-299.
|
| [13] |
Bertsekas D P. Value and Policy Iterations in Optimal Control and Adaptive Dynamic Programming[J]. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(3): 500-509.
|
| [14] |
Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous Control with Deep Reinforcement Learning[EB/OL]. (2019-07-05) [2025-06-01]. .
|
| [15] |
Langford J. Approximately Optimal Approximate Reinforcement Learning[EB/OL]. [2025-06-15]. .
|
| [16] |
Vrabie D, Pastravanu O, Abu-Khalaf M, et al. Adaptive Optimal Control for Continuous-time Linear Systems Based on Policy Iteration[J]. Automatica, 2009, 45(2): 477-484.
|
| [17] |
Jiang Yu, Jiang Zhongping. Computational Adaptive Optimal Control for Continuous-time Linear Systems with Completely Unknown Dynamics[J]. Automatica, 2012, 48(10): 2699-2704.
|
| [18] |
Bian Tao, Jiang Zhongping. Value Iteration and Adaptive Dynamic Programming for Data-driven Adaptive Optimal Control Design[J]. Automatica, 2016, 71: 348-360.
|
| [19] |
Vamvoudakis K G, Lewis F L. Online Actor-Critic Algorithm to Solve the Continuous-time Infinite Horizon Optimal Control Problem[J]. Automatica, 2010, 46(5): 878-888.
|
| [20] |
Modares H, Lewis F L. Optimal Tracking Control of Nonlinear Partially-unknown Constrained-input Systems Using Integral Reinforcement Learning[J]. Automatica, 2014, 50(7): 1780-1792.
|
| [21] |
Rizvi S A A, Lin Zongli. Output Feedback Adaptive Dynamic Programming for Linear Differential Zero-sum Games[J]. Automatica, 2020, 122: 109272.
|
| [22] |
Xie Kedi, Zheng Yiwei, Jiang Yi, et al. Optimal Dynamic Output Feedback Control of Unknown Linear Continuous-time Systems by Adaptive Dynamic Programming[J]. Automatica, 2024, 163: 111601.
|
| [23] |
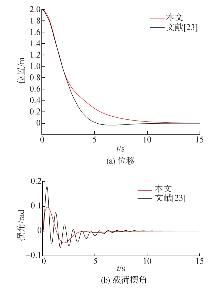
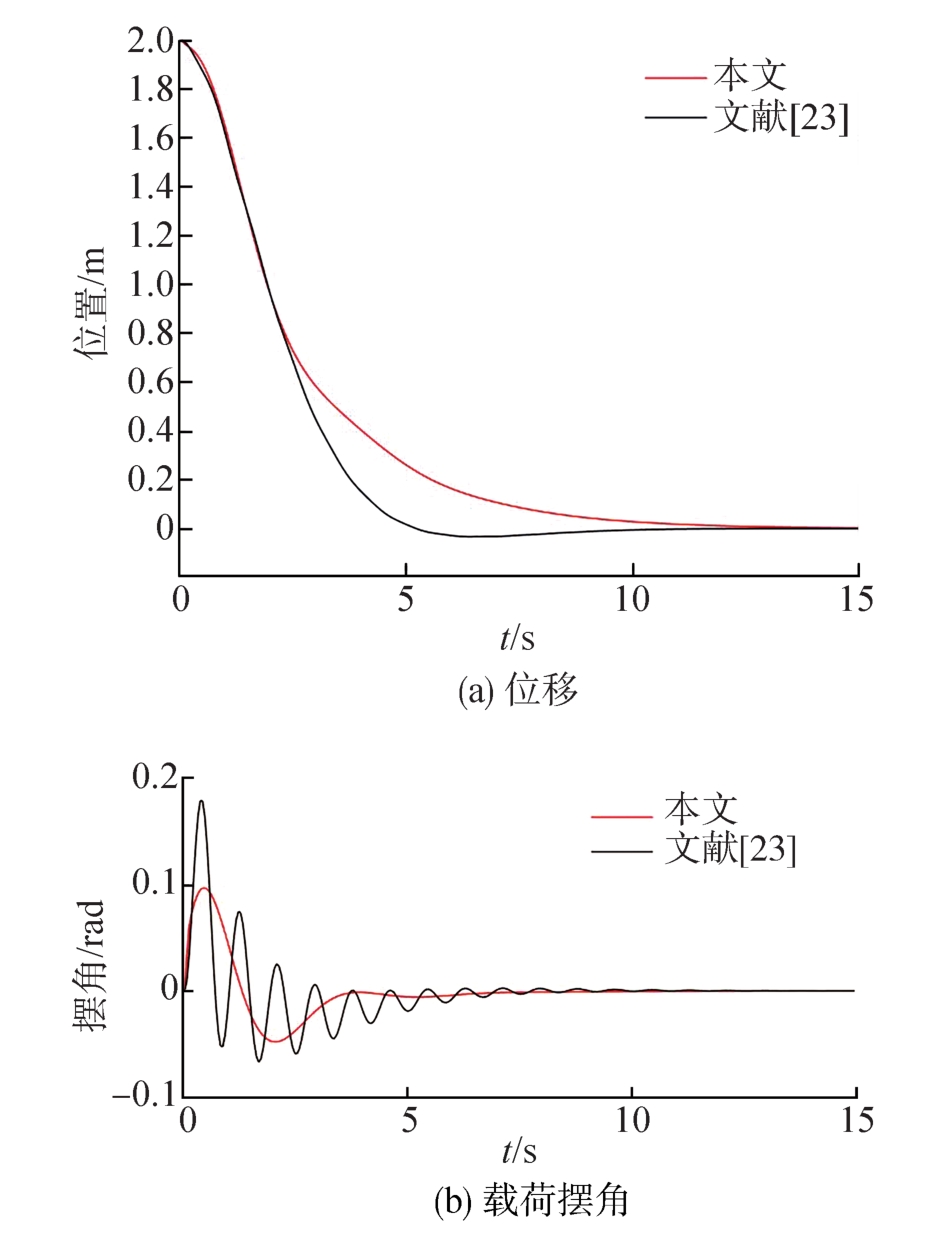
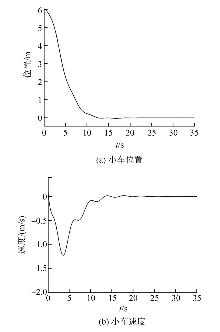
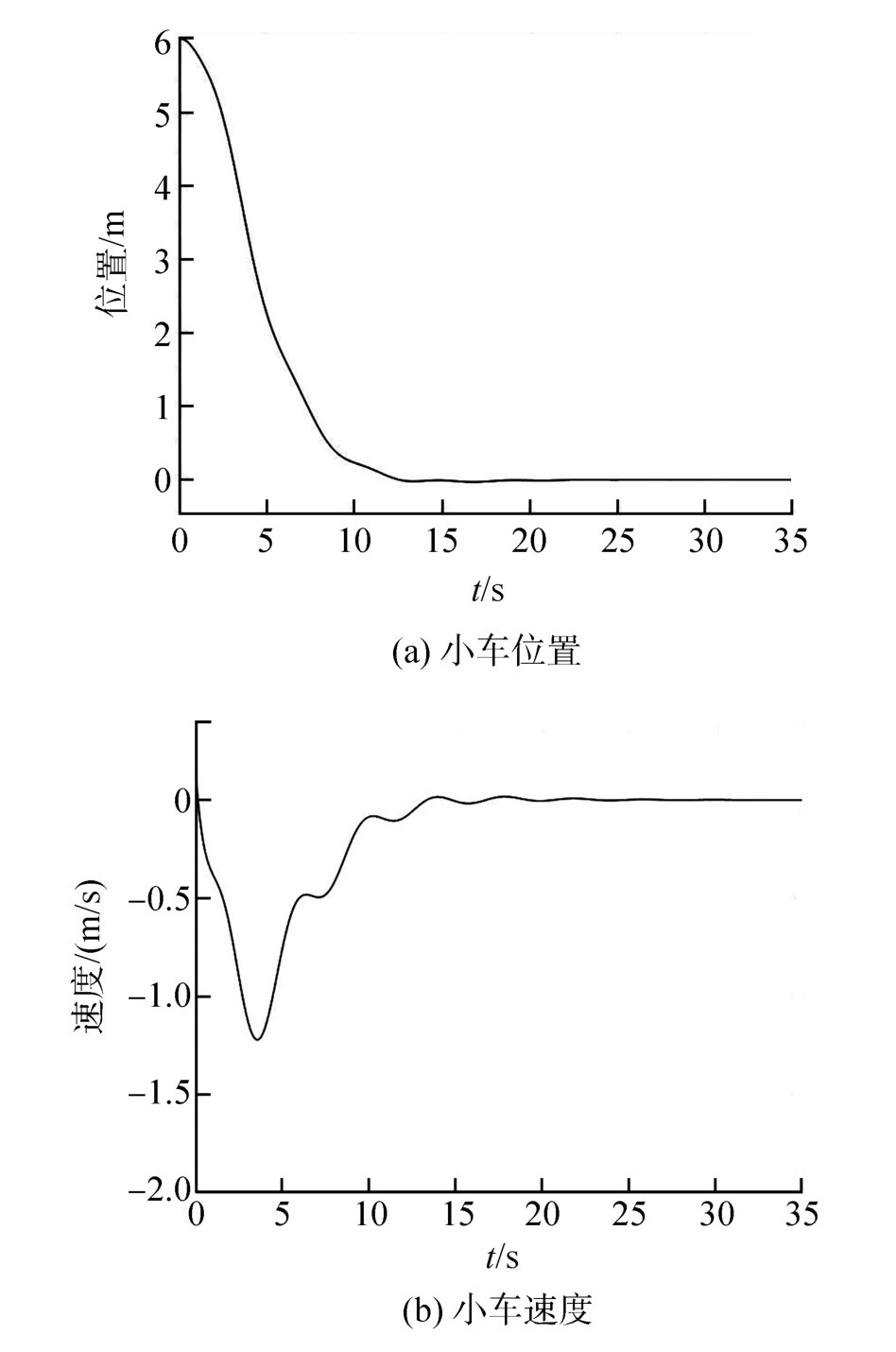
Wang Ding, He Haibo, Liu Derong. Intelligent Optimal Control with Critic Learning for a Nonlinear Overhead Crane System[J]. IEEE Transactions on Industrial Informatics, 2018, 14(7): 2932-2940.
|
| [24] |
Zhang Haoran, Zhao Chunhui, Ding Jinliang. Online Reinforcement Learning with Passivity-based Stabilizing Term for Real Time Overhead Crane Control Without Knowledge of the System Model[J]. Control Engineering Practice, 2022, 127: 105302.
|
| [25] |
Sun Ning, Fang Yongchun. New Energy Analytical Results for the Regulation of Underactuated Overhead Cranes: An End-effector Motion-based Approach[J]. IEEE Transactions on Industrial Electronics, 2012, 59(12): 4723-4734.
|
| [26] |
Atassi A N, Khalil H K. A Separation Principle for the Stabilization of a Class of Nonlinear Systems[J]. IEEE Transactions on Automatic Control, 1999, 44(9): 1672-1687.
|
| [27] |
Vamvoudakis K G, Vrabie D, Lewis F L. Online Adaptive Algorithm for Optimal Control with Integral Reinforcement Learning[J]. International Journal of Robust and Nonlinear Control, 2014, 24(17): 2686-2710.
|
| [28] |
Williams Jesús López Yánez, Francisco das Chagas de Souza. On the Effect of Probing Noise in Optimal Control LQR via Q-learning Using Adaptive Filtering Algorithms[J]. European Journal of Control, 2022, 65: 100633.
|
| [29] |
Ge S S, Lee T H, Harris C J. Adaptive Neural Network Control of Robotic Manipulators[M]//World Scientific Series in Robotics and Intelligent Systems. Singapore: World Scientific Publishing Co Pte Ltd, 1998: 396.
|
| [30] |
Ioannou Petros, Fidan Bariş. Adaptive Control Tutorial[M]. Philadelphia: SIAM, 2006.
|
| [31] |
Vrabie D, Lewis F. Neural Network Approach to Continuous-time Direct Adaptive Optimal Control for Partially Unknown Nonlinear Systems[J]. Neural Networks, 2009, 22(3): 237-246.
|
| [32] |
Wang Ding, Mu Chaoxu. A Novel Neural Optimal Control Framework with Nonlinear Dynamics: Closed-loop Stability and Simulation Verification[J]. Neurocomputing, 2017, 266: 353-360.
|
| [33] |
Khalil. High-gain Observers in Nonlinear Feedback Control[M]. London: Springer, 1999.
|