

系统仿真学报 ›› 2026, Vol. 38 ›› Issue (1): 136-157.doi: 10.16182/j.issn1004731x.joss.25-0832
蒋滨泽1, 宋文凤1, 侯霞1, 李帅2,3
收稿日期:2025-09-02
修回日期:2025-10-11
出版日期:2026-01-18
发布日期:2026-01-28
通讯作者:
宋文凤
第一作者简介:蒋滨泽(2001-),男,硕士生,研究方为计算机视觉,条件驱动人体运动生成。
基金资助:Jiang Binze1, Song Wenfeng1, Hou Xia1, Li Shuai2,3
Received:2025-09-02
Revised:2025-10-11
Online:2026-01-18
Published:2026-01-28
Contact:
Song Wenfeng
摘要:
为提升文本驱动动作生成的精确性、可控性与真实感,提出了一种融合细粒度文本语义信息与空间控制信号的人体动作生成 方法 。在扩散模型框架下,引入全局文本标记与身体部位级别的局部标记,通过CLIP编码后得到对应的特征,输入到动作扩散模型,实现对不同身体部位的精细控制。利用空间指导在扩散去噪过程中动态调整关节位置,使生成动作满足空间约束;结合真实性指导,有效改善未受控关节的自然性与整体协调性。基于HumanML3D数据集进行实验,使用ChatGPT-4o对44 970条文本进行细粒度重写,提升文本与动作的语义对齐度。结果表明:所提方法在动作语义一致性、空间控制精度和生成质量等方面均优于现有方法,能够生成在语义一致性与动作质量上均符合用户预期的人体运动。
中图分类号:
蒋滨泽,宋文凤,侯霞等 . 结合细粒度文本与空间控制信号的人体动作扩散模型[J]. 系统仿真学报, 2026, 38(1): 136-157.
Jiang Binze,Song Wenfeng,Hou Xia,et al . Diffusion Model for Human Motion Generation with Fine-grained Text and Spatial Control Signals[J]. Journal of System Simulation, 2026, 38(1): 136-157.
图1
基于细粒度文本与空间控制信号的扩散模型
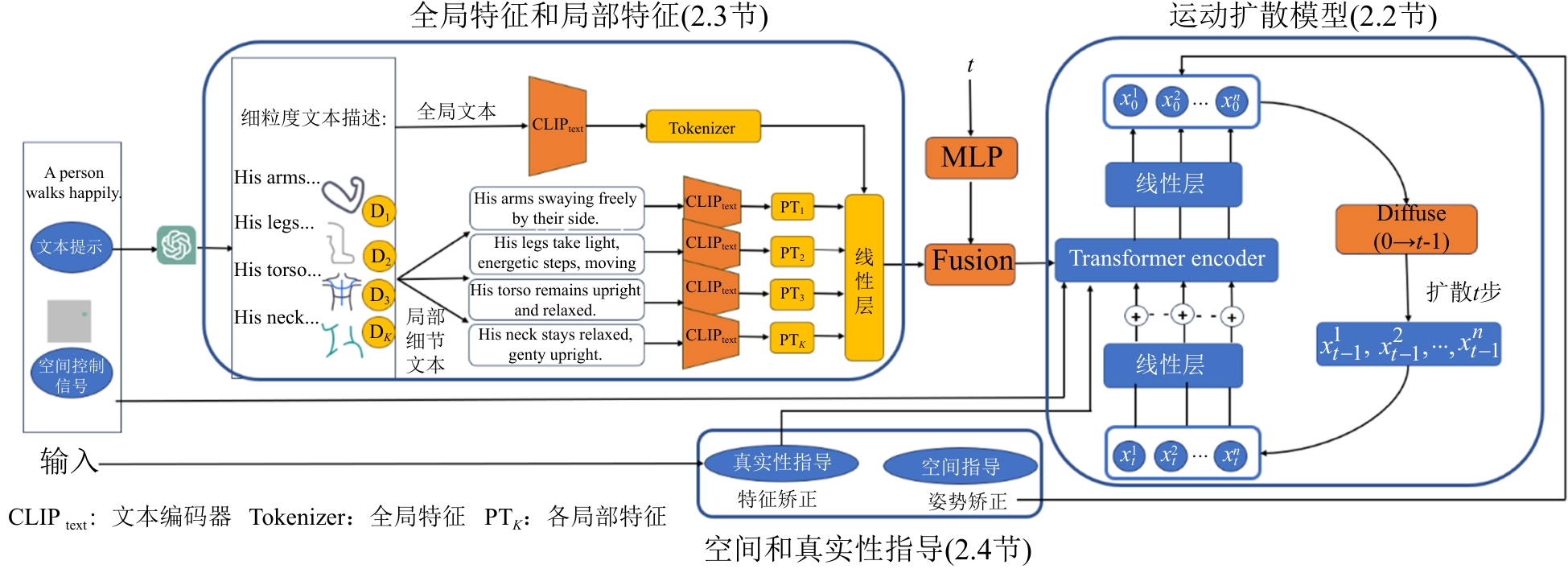
图2
扩散步数对动作质量影响的关键帧可视化
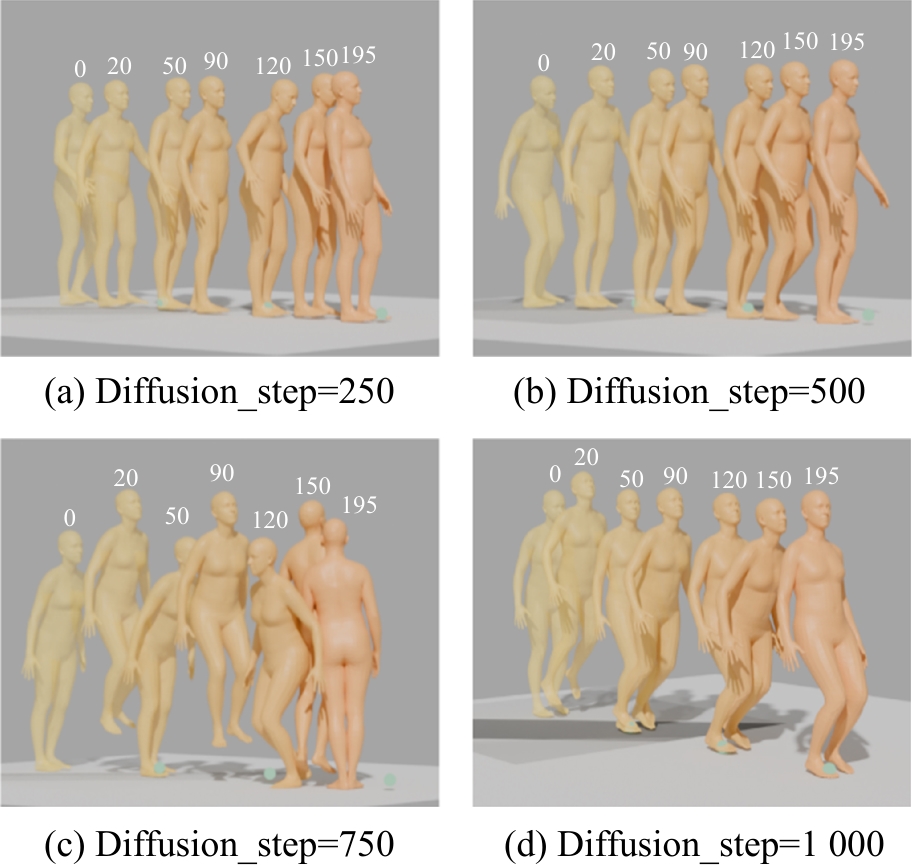

图3
空间指导结构图
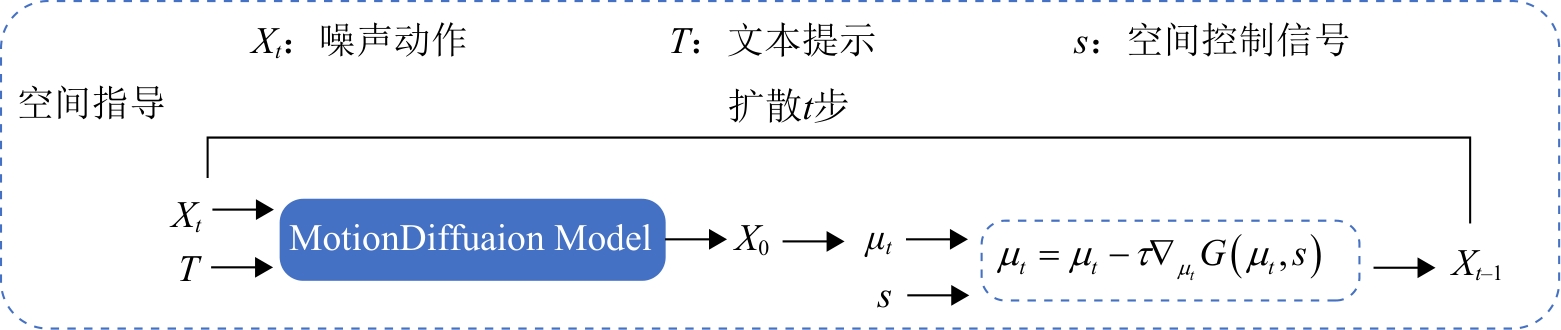
图4
真实性指导结构图
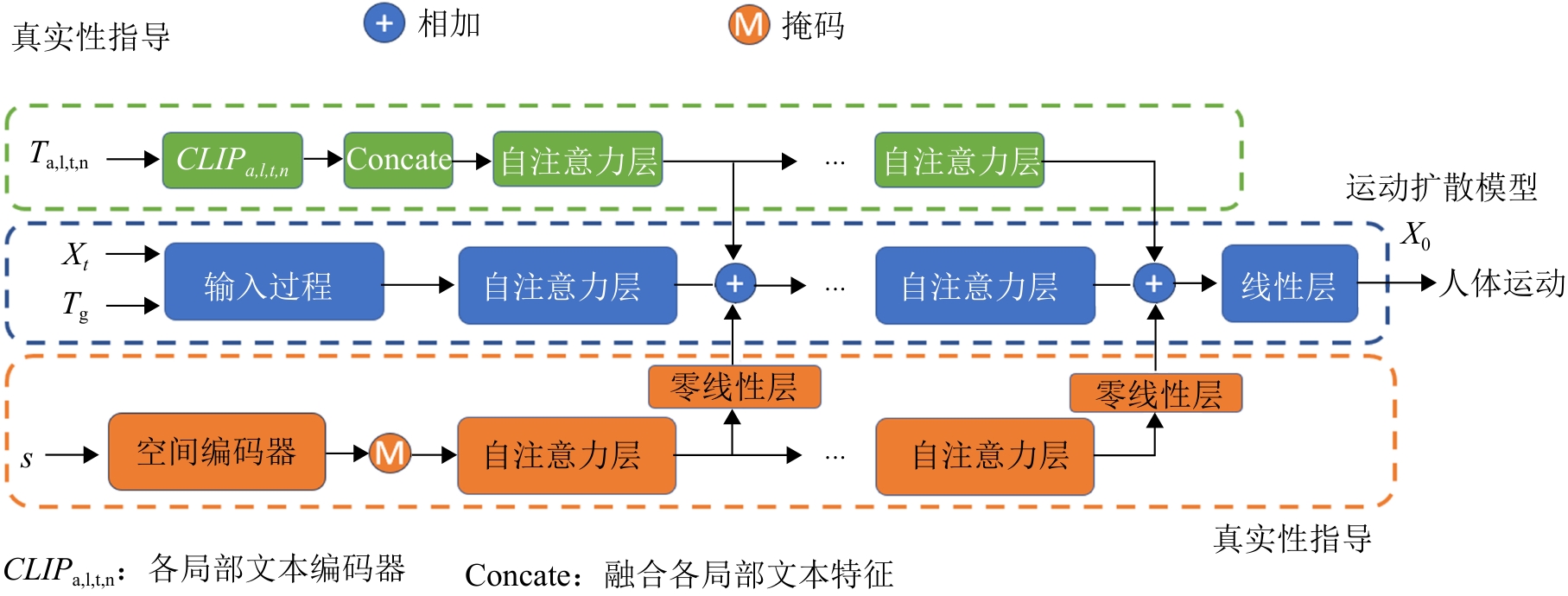
表1
实验环境
| 环境 | 参数 |
|---|---|
| 操作系统 | Ubuntu20.04 |
| 深度学习框架 | Pytorch 1.18 |
| CUDA版本 | CUDA 11.7 |
| 开发软件 | VS Code |
| 显卡 | 单张3090 |

图5
可视化实验对比(控制骨盆)
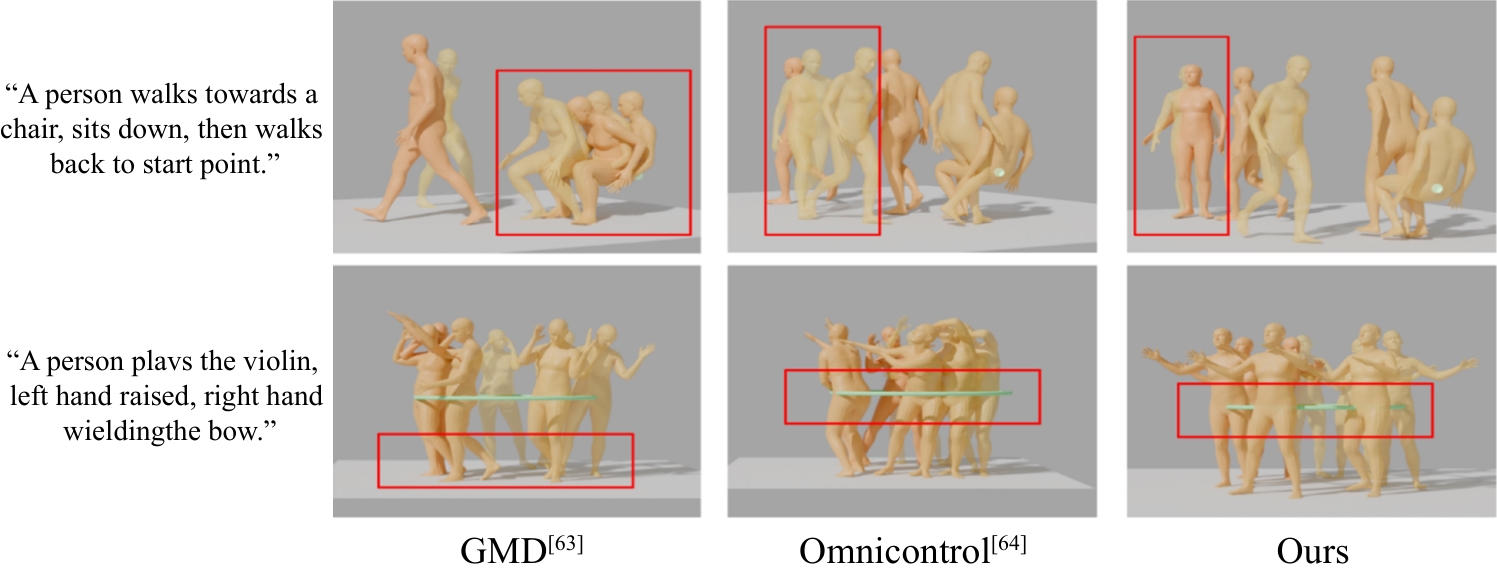
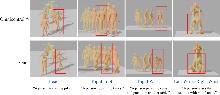
图6
可视化实验对比(控制其他身体部位)
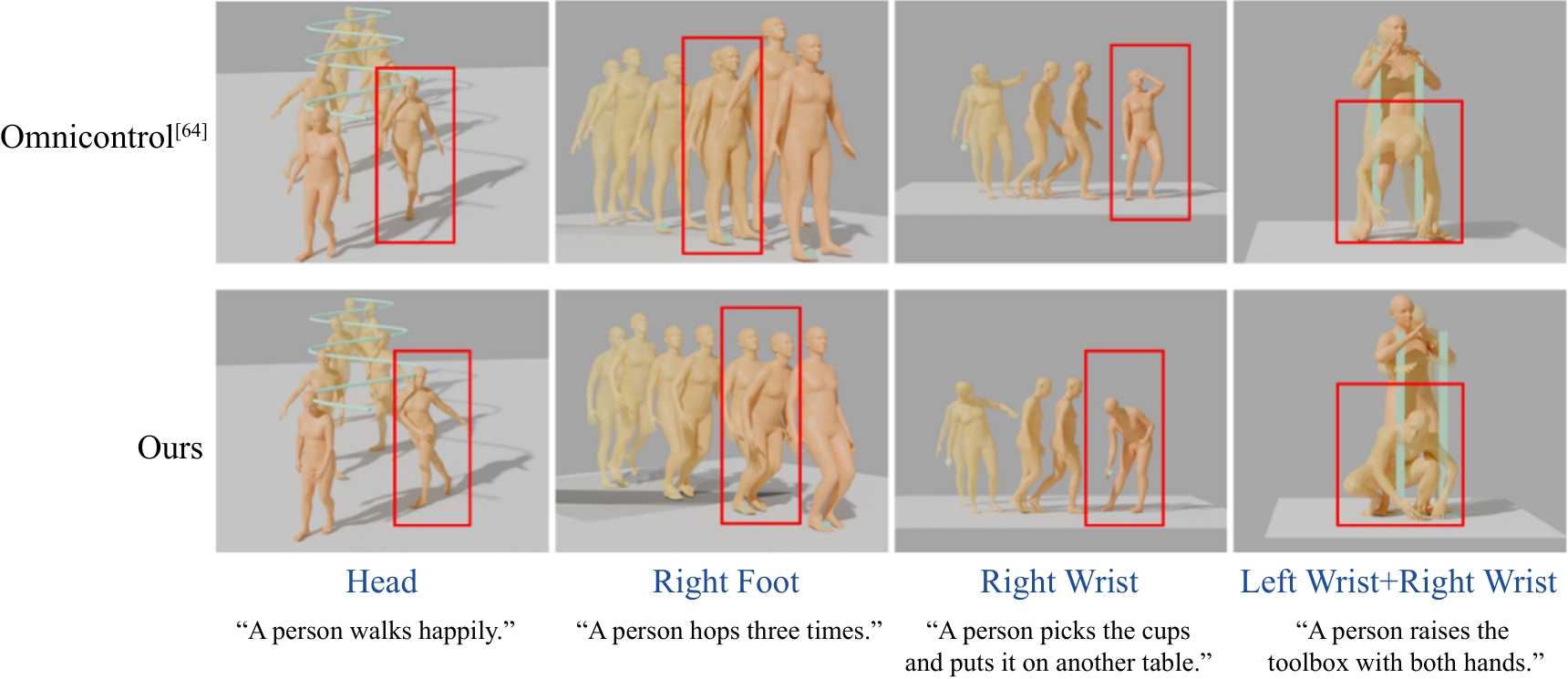
表2
量化实验结果对比结果(控制骨盆)
| Method | R-precision↑ | FID↓ | Diversity(9.503)→ | Foot skating ratio↓ | Traj. err. (50 cm)↓ | Loc. err. (50 cm)↓ | Avg. err. ↓ |
|---|---|---|---|---|---|---|---|
| real | 0.797 | 0.002 | 9.503 | — | 0 | 0 | 0 |
| MDM | 0.602 | 0.698 | 9.197 | 0.101 9 | 0.402 2 | 0.307 6 | 0.595 9 |
| PriorMDM | 0.583 | 0.475 | 9.156 | 0.089 7 | 0.345 7 | 0.213 2 | 0.441 7 |
| GMD | 0.665 | 0.576 | 9.206 | 0.100 9 | 0.093 1 | 0.032 1 | 0.143 9 |
| OmniControl | 0.687 | 0.218 | 9.422 | 0.054 7 | 0.038 7 | 0.009 6 | 0.033 8 |
| Ours | 0.708 | 0.173 | 9.806 | 0.047 1 | 0.030 6 | 0.007 9 | 0.028 4 |
表3
量化实验结果对比结果(控制所有关节)
| Method | Joint | R-precision↑ | FID↓ | Diversity(9.503)→ | Foot skating ratio↓ | Traj. err.(50 cm)↓ | Loc. err. (50 cm)↓ | Avg. err. ↓ |
|---|---|---|---|---|---|---|---|---|
| OmniControl | Pelvis | 0.691 | 0.322 | 9.545 | 0.057 1 | 0.040 4 | 0.008 5 | 0.036 7 |
| Ours | 0.708 | 0.197 | 9.803 | 0.042 3 | 0.035 5 | 0.007 3 | 0.032 7 | |
| OmniControl | Left Foot | 0.696 | 0.280 | 9.553 | 0.069 2 | 0.059 4 | 0.009 4 | 0.031 4 |
| Ours | 0.702 | 0.189 | 9.758 | 0.041 2 | 0.060 8 | 0.007 5 | 0.030 8 | |
| OmniControl | Right Foot | 0.701 | 0.319 | 9.481 | 0.066 8 | 0.066 6 | 0.012 0 | 0.033 4 |
| Ours | 0.704 | 0.217 | 9.747 | 0.042 5 | 0.065 3 | 0.014 1 | 0.033 4 | |
| OmniControl | Head | 0.696 | 0.335 | 9.480 | 0.055 6 | 0.042 2 | 0.007 9 | 0.034 9 |
| Ours | 0.711 | 0.232 | 9.738 | 0.042 1 | 0.038 3 | 0.006 9 | 0.031 8 | |
| OmniControl | Left Wrist | 0.680 | 0.304 | 9.436 | 0.056 2 | 0.080 1 | 0.013 4 | 0.052 9 |
| Ours | 0.707 | 0.199 | 9.569 | 0.039 4 | 0.061 3 | 0.008 5 | 0.040 6 | |
| OmniControl | Right Wrist | 0.692 | 0.299 | 9.519 | 0.060 1 | 0.081 3 | 0.012 7 | 0.051 9 |
| Ours | 0.706 | 0.220 | 9.705 | 0.043 4 | 0.065 2 | 0.012 3 | 0.042 1 | |
| OmniControl | Average | 0.693 | 0.310 | 9.502 | 0.060 8 | 0.061 7 | 0.010 7 | 0.040 4 |
| Ours | 0.706 | 0.209 | 9.720 | 0.041 7 | 0.041 0 | 0.009 4 | 0.035 2 |
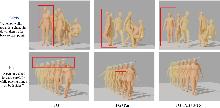
图7
消融实验
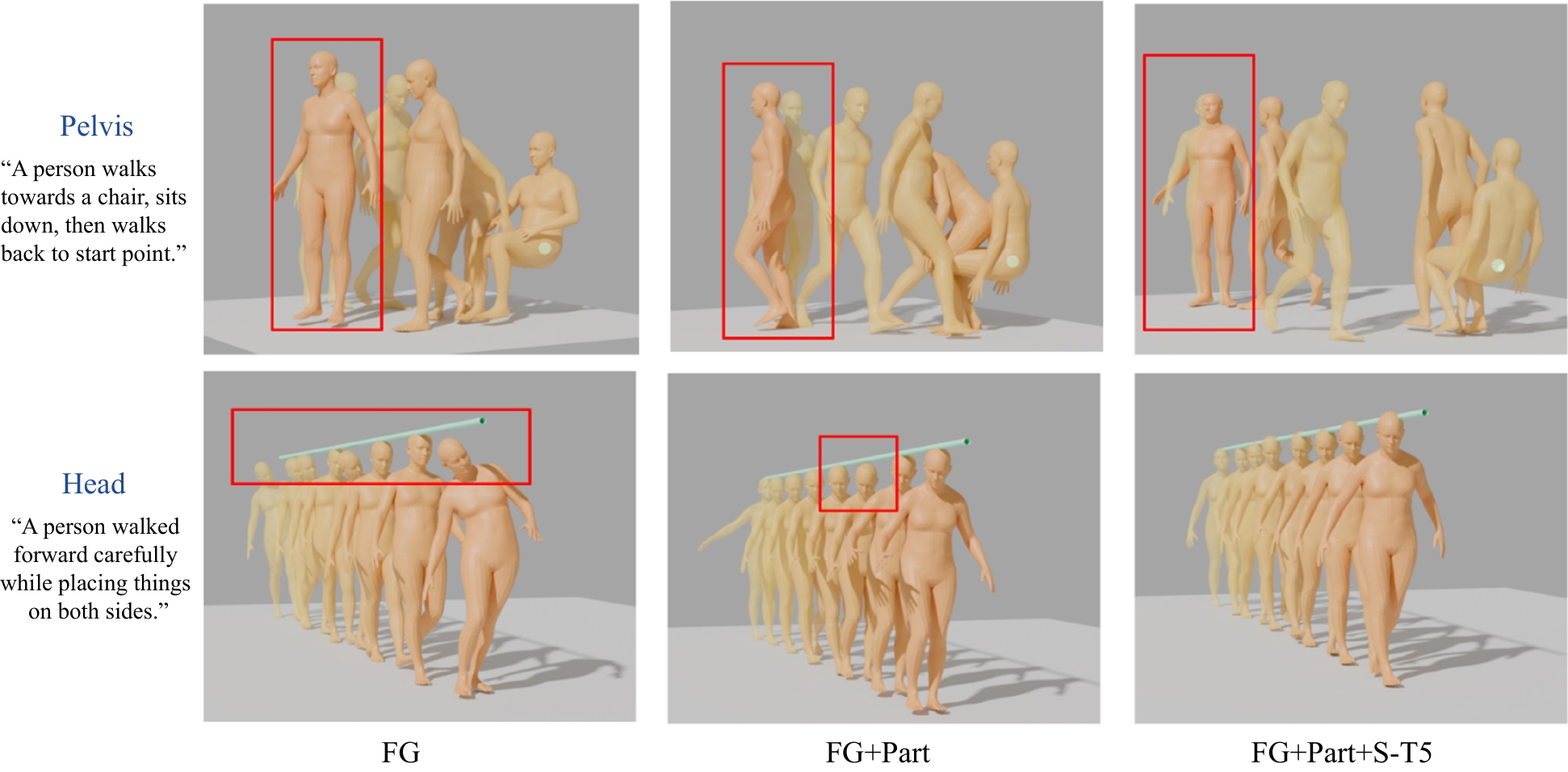
表4
消融实验
| FG | Part | S-T5 | R-precision↑ | FID↓ | Diversity(9.503)→ | Foot skating ratio↓ | Traj. err. (50 cm)↓ | Loc. err. (50 cm)↓ | Avg. err. ↓ |
|---|---|---|---|---|---|---|---|---|---|
| 0.693 | 0.310 | 9.502 | 0.060 8 | 0.061 7 | 0.010 7 | 0.040 4 | |||
| √ | 0.691 | 0.279 | 9.504 | 0.059 2 | 0.058 9 | 0.010 9 | 0.040 2 | ||
| √ | √ | 0.698 | 0.240 | 9.681 | 0.045 1 | 0.042 1 | 0.010 2 | 0.035 8 | |
| √ | √ | √ | 0.706 | 0.209 | 9.720 | 0.041 7 | 0.041 0 | 0.009 4 | 0.035 2 |
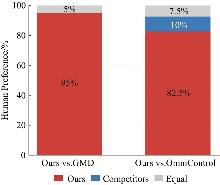
图8
用户实验结果
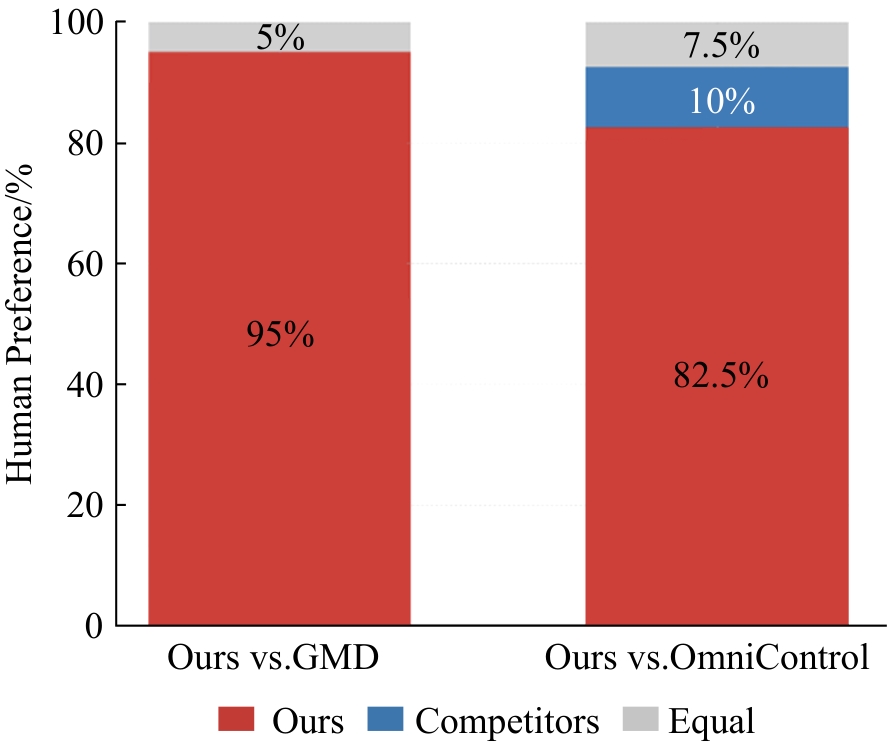
图9
泛化性评估
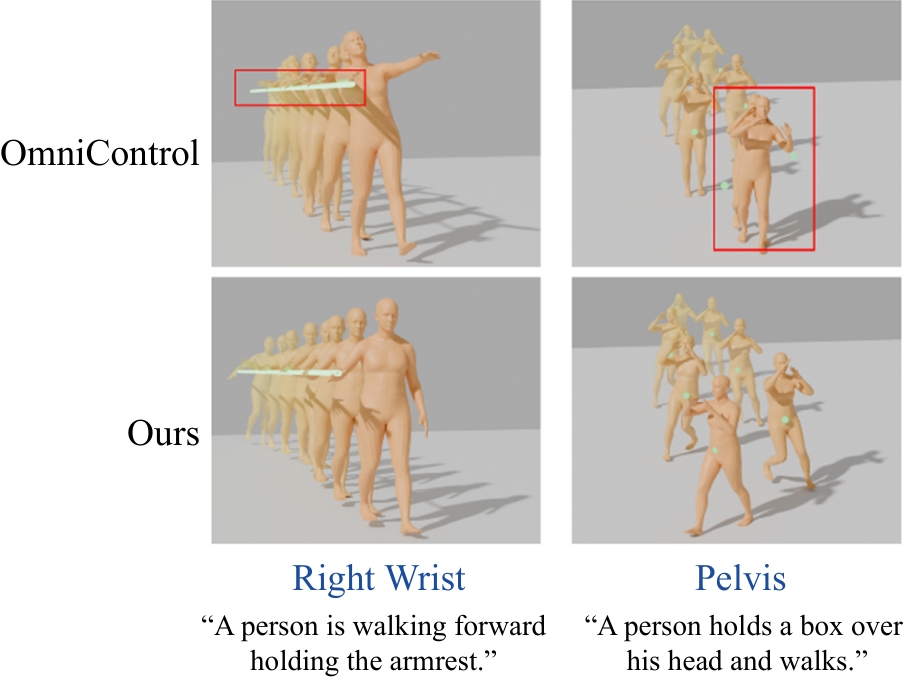
表5
不同方法在RTX 3090上的运行时间对比
| 方法 | 平均运行时间/(s/帧) ↓ |
|---|---|
| MDM | 0.192 |
| GMD | 0.567 |
| OmniControl | 0.606 |
| Ours | 0.548 |
| [1] | Xu Liang, Song Ziyang, Wang Dongliang, et al. ActFormer: A GAN-based Transformer Towards General Action-conditioned 3D Human Motion Generation[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 2228-2238. |
| [2] | Guo Chuan, Zou Shihao, Zuo Xinxin, et al. Generating Diverse and Natural 3D Human Motions from Text[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2022: 5142-5151. |
| [3] | Tevet G, Raab S, Gordon B, et al. Human Motion Diffusion Model[EB/OL]. (2022-10-03) [2025-08-12]. . |
| [4] | 赵宝全, 付一愉, 苏卓, 等. 多模态信息引导的三维数字人运动生成综述[J]. 中国图象图形学报, 2024, 29(9): 2541-2565. |
| Zhao Baoquan, Fu Yiyu, Su Zhuo, et al. A Survey on Multimodal Information-guided 3D Human Motion Generation[J]. Journal of Image and Graphics, 2024, 29(9): 2541-2565. | |
| [5] | Guo Chuan, Zuo Xinxin, Wang Sen, et al. Action2Motion: Conditioned Generation of 3D Human Motions[C]//Proceedings of the 28th ACM International Conference on Multimedia. New York: Association for Computing Machinery, 2020: 2021-2029. |
| [6] | Hoang N M, Gong Kehong, Guo Chuan, et al. MotionMix: Weakly-Supervised Diffusion for Controllable Motion Generation[C]//Proceedings of the Thirty-eighth AAAI Conference on Artificial Intelligence and Thirty-sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence. Palo Alto: AAAI Press, 2024: 2157-2165. |
| [7] | Petrovich M, Black M J, Varol G. Action-conditioned 3D Human Motion Synthesis with Transformer VAE[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2021: 10965-10975. |
| [8] | Guo Chuan, Mu Yuxuan, Javed M G, et al. MoMask: Generative Masked Modeling of 3D Human Motions[C]//2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2024: 1900-1910. |
| [9] | Chen Xin, Jiang Biao, Liu Wen, et al. Executing Your Commands via Motion Diffusion in Latent Space[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2023: 18000-18010. |
| [10] | Bae J, Hwang I, Lee Y Y, et al. Less is More: Improving Motion Diffusion Models with Sparse Keyframes[EB/OL]. (2025-05-12) [2025-08-12]. . |
| [11] | Guo Chuan, Zuo Xinxin, Wang Sen, et al. TM2T: Stochastic and Tokenized Modeling for the Reciprocal Generation of 3D Human Motions and Texts[C]//Computer Vision – ECCV 2022. Cham: Springer Nature Switzerland, 2022: 580-597. |
| [12] | Guo Chuan, Hwang I, Wang Jian, et al. SnapMoGen: Human Motion Generation from Expressive Texts[EB/OL]. (2025-10-23) [2025-08-12]. . |
| [13] | Lin Junfan, Chang Jianlong, Liu Lingbo, et al. Being Comes from Not-Being: Open-vocabulary Text-to-motion Generation with Wordless Training[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2023: 23222-23231. |
| [14] | Petrovich M, Black M J, Varol G. TEMOS: Generating Diverse Human Motions from Textual Descriptions[C]//Computer Vision – ECCV 2022. Cham: Springer Nature Switzerland, 2022: 480-497. |
| [15] | Petrovich M, Litany O, Iqbal U, et al. Multi-Track Timeline Control for Text-driven 3D Human Motion Generation[EB/OL]. (2024-05-24) [2025-08-12]. . |
| [16] | Yuan Ye, Song Jiaming, Iqbal U, et al. PhysDiff: Physics-Guided Human Motion Diffusion Model[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 15964-15975. |
| [17] | Zhang Jianrong, Zhang Yangsong, Xiaodong Cun, et al. Generating Human Motion from Textual Descriptions with Discrete Representations[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2023: 14730-14740. |
| [18] | Zhang Mingyuan, Cai Zhongang, Pan Liang, et al. MotionDiffuse: Text-driven Human Motion Generation with Diffusion Model[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(6): 4115-4128. |
| [19] | Alexanderson S, Nagy R, Beskow J, et al. Listen, Denoise, Action! Audio-driven Motion Synthesis with Diffusion Models[J]. ACM Transactions on Graphics, 2023, 42(4): 44. |
| [20] | Gong Kehong, Lian Dongze, Chang Heng, et al. TM2D: Bimodality Driven 3D Dance Generation via Music-text Integration[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 9908-9918. |
| [21] | Lee H Y, Yang Xiaodong, Liu Mingyu, et al. Dancing to Music[C]//Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 3586-3596. |
| [22] | Li Ruilong, Yang Shan, Ross D A, et al. AI Choreographer: Music Conditioned 3D Dance Generation with AIST++[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2021: 13381-13392. |
| [23] | Qi Qiaosong, Zhuo Le, Zhang Aixi, et al. DiffDance: Cascaded Human Motion Diffusion Model for Dance Generation[C]//Proceedings of the 31st ACM International Conference on Multimedia. New York: Association for Computing Machinery, 2023: 1374-1382. |
| [24] | Li Siyao, Yu Weijiang, Gu Tianpei, et al. Bailando: 3D Dance Generation by Actor-critic GPT with Choreographic Memory[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2022: 11040-11049. |
| [25] | Tseng J, Castellon R, Liu C K. EDGE: Editable Dance Generation from Music[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2023: 448-458. |
| [26] | 王家松,周雷,张博.基于扩散模型加速和感知优化的高效姿态驱动人体动作生成技术[J/OL].计算机应用研究,1-8[2025-10-10].. |
| [27] | 刘颖,李济廷,柴瑞坤,等.语音驱动说话数字人视频生成方法综述[J].电子科技大学学报,2024,53(06):911-921. |
| [28] | Bae J, Won J, Lim D, et al. PMP: Learning to Physically Interact with Environments using Part-wise Motion Priors[C]//ACM SIGGRAPH 2023 Conference Proceedings. New York: Association for Computing Machinery, 2023: 64. |
| [29] | Bhatnagar B L, Xie Xianghui, Petrov I A, et al. BEHAVE: Dataset and Method for Tracking Human Object Interactions[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2022: 15914-15925. |
| [30] | Ghosh A, Dabral R, Golyanik V, et al. IMoS: Intent-Driven Full-body Motion Synthesis for Human-object Interactions[J]. Computer Graphics Forum, 2023, 42(2): 1-12. |
| [31] | Kulkarni N, Rempe D, Genova K, et al. NIFTY: Neural Object Interaction Fields for Guided Human Motion Synthesis[C]//2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2024: 947-957. |
| [32] | Li Jiaman, Clegg A, Mottaghi R, et al. Controllable Human - object Interaction Synthesis[C]//Computer Vision-ECCV 2024. Cham: Springer Nature Switzerland, 2025: 54-72. |
| [33] | Li Jiaman, Wu Jiajun, Liu C K. Object Motion Guided Human Motion Synthesis[J]. ACM Transactions on Graphics, 2023, 42(6): 197. |
| [34] | Taheri O, Ghorbani N, Black M J, et al. GRAB: A Dataset of Whole-body Human Grasping of Objects[C]//Computer Vision - ECCV 2020. Cham: Springer International Publishing, 2020: 581-600. |
| [35] | Xu Sirui, Li Zhengyuan, Wang Yuxiong, et al. InterDiff: Generating 3D Human-object Interactions with Physics-informed Diffusion[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 14882-14894. |
| [36] | Zhao Kaifeng, Wang Shaofei, Zhang Yan, et al. Compositional Human-scene Interaction Synthesis with Semantic Control[C]//Computer Vision – ECCV 2022. Cham: Springer Nature Switzerland, 2022: 311-327. |
| [37] | Cen Zhi, Pi Huaijin, Peng Sida, et al. Generating Human Motion in 3D Scenes from Text Descriptions[C]//2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2024: 1855-1866. |
| [38] | Huang Siyuan, Zan Wang, Li Puhao, et al. Diffusion-based Generation, Optimization, and Planning in 3D Scenes[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2023: 16750-16761. |
| [39] | Hwang I, Bae J, Lim D, et al. Goal-driven Human Motion Synthesis in Diverse Tasks[C]//2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Piscataway: IEEE, 2025: 2911-2921. |
| [40] | Jiang Nan, He Zimo, Wang Zi, et al. Autonomous Character-scene Interaction Synthesis from Text Instruction[C]//SIGGRAPH Asia 2024 Conference Papers. New York: Association for Computing Machinery, 2024: 33. |
| [41] | Jiang Nan, Zhang Zhiyuan, Li Hongjie, et al. Scaling Up Dynamic Human-scene Interaction Modeling[C]//2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2024: 1737-1747. |
| [42] | Lee J, Joo H. Locomotion-Action-Manipulation: Synthesizing Human-scene Interactions in Complex 3D Environments[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 9629-9640. |
| [43] | Lim D, Jeong C, Kim Y M. MAMMOS: MApping Multiple Human Motion with Scene Understanding and Natural Interactions[C]//2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW). Piscataway: IEEE, 2023: 4280-4289. |
| [44] | Sui Kewei, Ghosh A, Hwang I, et al. A Survey on Human Interaction Motion Generation[EB/OL]. (2025-04-07) [2025-08-12]. . |
| [45] | Wang Zan, Chen Yixin, Liu Tengyu, et al. Humanise: Language-Conditioned Human Motion Generation in 3D Scenes[C]//Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 14959-14971. |
| [46] | Wang Zan, Chen Yixin, Jia Baoxiong, et al. Move as You Say, Interact as You Can: Language-guided Human Motion Generation with Scene Affordance[C]//2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2024: 433-444. |
| [47] | Yi Hongwei, Thies J, Black M J, et al. Generating Human Interaction Motions in Scenes with Text Control[C]//Computer Vision – ECCV 2024. Cham: Springer Nature Switzerland, 2024: 246-263. |
| [48] | Zhao Kaifeng, Zhang Yan, Wang Shaofei, et al. Synthesizing Diverse Human Motions in 3D Indoor Scenes[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 14692-14703. |
| [49] | Ahuja C, Morency L P. Language2Pose: Natural Language Grounded Pose Forecasting[C]//2019 International Conference on 3D Vision (3DV). Piscataway: IEEE, 2019: 719-728. |
| [50] | Ghosh A, Cheema N, Oguz C, et al. Synthesis of Compositional Animations from Textual Descriptions[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2021: 1376-1386. |
| [51] | Tevet G, Gordon B, Hertz A, et al. MotionCLIP: Exposing Human Motion Generation to CLIP Space[C]//Computer Vision – ECCV 2022: 17th European Conference. Berlin: Springer-Verlag, 2022: 358-374. |
| [52] | Radford A, Kim J K, Hallacy C, et al.Learning Transferable Visual Models from Natural Language Supervision [C]//Proceedings of the 38th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2021: 8748-8763. |
| [53] | Zhong Chongyang, Hu Lei, Zhang Zihao, et al. AttT2M: Text-Driven Human Motion Generation with Multi-perspective Attention Mechanism[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 509-519. |
| [54] | 李健, 杨钧, 王丽燕, 等. 融入变分自编码网络的文本生成三维运动人体[J]. 中国图象图形学报, 2024, 29(5): 1434-1446. |
| LI Jian, YANG Jun, WANG Liyan, et al. Incorporating Variational Auto-encoder Networks for Text-driven Generation of 3D Motion Human Body[J]. Journal of Image and Graphics, 2024, 29(5): 1434-1446. | |
| [55] | Zhang Mingyuan, Cai Zhongang, Pan Liang, et al. MotionDiffuse: Text-driven Human Motion Generation with Diffusion Model[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(6): 4115-4128. |
| [56] | Kim J, Kim J, Choi S. FLAME: Free-Form Language-Based Motion synthesis & Editing[C]//Proceedings of the Thirty-seventh AAAI Conference on Artificial Intelligence and Thirty-fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence. Palo Alto: AAAI Press, 2023: 8255-8263. |
| [57] | Zhang Mingyuan, Guo Xinying, Pan Liang, et al. ReMoDiffuse: Retrieval-augmented Motion Diffusion Model[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 364-373. |
| [58] | 石旭, 孙运莲, 骆岩林, 等. 基于时序感知潜在扩散模型的人体交互动作生成[J]. 计算机学报, 2025, 48(9): 2226-2240. |
| Shi Xu, Sun Yunlian, Luo Yanlin, et al. Human Interaction Generation Based on Temporal-aware Latent Diffusion Model[J]. Chinese Journal of Computers, 2025, 48(9): 2226-2240. | |
| [59] | Devlin J, Chang Mingwei, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2019: 4171-4186. |
| [60] | Achiam J, Adler S, Agarwal S, et al. GPT-4 Technical Report[EB/OL]. (2024-03-04) [2025-08-12]. . |
| [61] | Raffel C, Shazeer N, Roberts A, et al. Exploring the Limits of Transfer Learning with a Unified Text-to-text Transformer[J]. The Journal of Machine Learning Research, 2020, 21(1): 140. |
| [62] | Gilardi F, Alizadeh M, Kubli M. ChatGPT Outperforms Crowd Workers for Text-annotation Tasks[J]. Proceedings of the National Academy of Sciences of the United States of America, 2023, 120(30): e2305016120. |
| [63] | Kalakonda S S, Maheshwari S, Sarvadevabhatla R K. Action-GPT: Leveraging Large-scale Language Models for Improved and Generalized Action Generation[C]//2023 IEEE International Conference on Multimedia and Expo (ICME). Piscataway: IEEE, 2023: 31-36. |
| [64] | Athanasiou N, Petrovich M, Black M J, et al. SINC: Spatial Composition of 3D Human Motions for Simultaneous Action Generation[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 9950-9961. |
| [65] | Zhang Mingyuan, Li Huirong, Cai Zhongang, et al. FineMoGen: Fine-grained Spatio-temporal Motion Generation and Editing[C]//Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 13981-13992. |
| [66] | Jiang Biao, Chen Xin, Liu Wen, et al. MotionGPT: Human Motion as a Foreign Language[C]//Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 20067-20079. |
| [67] | Shafir Y, Tevet G, Kapon R, et al. Human Motion Diffusion as a Generative Prior[EB/OL]. (2023-08-30) [2025-08-12]. . |
| [68] | Karunratanakul K, Preechakul K, Suwajanakorn S, et al. Guided Motion Diffusion for Controllable Human Motion Synthesis[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 2151-2162. |
| [69] | Xie Yiming, Jampani V, Zhong Lei, et al. OmniControl: Control Any Joint at Any Time for Human Motion Generation[EB/OL]. (2024-04-14) [2025-08-12]. . |
| [70] | Zhang Lümin, Rao Anyi, Agrawala M. Adding Conditional Control to Text-to-image Diffusion Models[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 3813-3824. |
| [71] | Dai Wenxun, Chen Linghao, Wang Jingbo, et al. MotionLCM: Real-time Controllable Motion Generation via Latent Consistency Model[C]//Computer Vision – ECCV 2024. Cham: Springer Nature Switzerland, 2025: 390-408. |
| [72] | Wan Weilin, Dou Zhiyang, Komura T, et al. TLControl: Trajectory and Language Control for Human Motion Synthesis[C]//Computer Vision – ECCV 2024. Cham: Springer Nature Switzerland, 2025: 37-54. |
| [73] | Pinyoanuntapong E, Saleem M U, Karunratanakul K, et al. MaskControl: Spatio-temporal Control for Masked Motion Synthesis[EB/OL]. (2025-10-18) [2025-10-22]. . |
| [74] | Karunratanakul K, Preechakul K, Aksan E, et al. Optimizing Diffusion Noise Can Serve as Universal Motion Priors[C]//2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2024: 1334-1345. |
| [75] | Studer J, Agrawal D, Borer D, et al. Factorized Motion Diffusion for Precise and Character-agnostic Motion Inbetweening[C]//Proceedings of the 17th ACM SIGGRAPH Conference on Motion, Interaction, and Games. New York: Association for Computing Machinery, 2024: 11. |
| [76] | Sohl-Dickstein J, Weiss E A, Maheswaranathan N, et al. Deep Unsupervised Learning Using Nonequilibrium Thermodynamics[C]//Proceedings of the 32nd International Conference on International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2015: 2256-2265. |
| [77] | Ho J, Jain A, Abbeel P. Denoising Diffusion Probabilistic Models[C]//Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 6840-6851. |
| [78] | Ramesh A, Dhariwal P, Nichol A, et al. Hierarchical Text-Conditional Image Generation with CLIP Latents[EB/OL]. (2022-04-13) [2025-08-12]. . |
| [79] | Dhariwal P, Nichol A. Diffusion Models Beat GANs on Image Synthesis[C]//Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 8780-8794. |
| [80] | Mahmood N, Ghorbani N, Troje N F, et al. AMASS: Archive of Motion Capture as Surface Shapes[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2019: 5441-5450. |
| [1] | 张硕喆, 宋文凤, 侯霞, 李帅. 基于时空增强生成模型的协同音频人体全身动作生成[J]. 系统仿真学报, 2026, 38(1): 211-224. |
| [2] | 廖国琼, 黄龙杰, 李清新, 张家俊, 陈柯帆. DEHPR:基于扩散模型的端到端手部姿态重建网络[J]. 系统仿真学报, 2026, 38(1): 174-188. |
| [3] | 李想, 桑海峰. 基于Transformer网络多模态融合的密集视频描述方法[J]. 系统仿真学报, 2024, 36(5): 1061-1071. |
| [4] | 刘顺华, 方民. 基于复杂地形的化学仿真环境建模研究[J]. 系统仿真学报, 2021, 33(6): 1258-1267. |
| [5] | 王志文, 张子豪, 贾玉祥, 魏毅, 沈燕飞. 基于语音识别控制的人体运动仿真[J]. 系统仿真学报, 2018, 30(11): 4203-4209. |
| [6] | 吴正雄, 郭刚, 段红. 新的有偏扩散模型LMC仿真算法的精度[J]. 系统仿真学报, 2017, 29(10): 2247-2253. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
