

系统仿真学报 ›› 2025, Vol. 37 ›› Issue (2): 345-361.doi: 10.16182/j.issn1004731x.joss.23-1180
苏炯铭, 罗俊仁, 陈少飞
收稿日期:2023-09-22
修回日期:2023-11-29
出版日期:2025-02-14
发布日期:2025-02-10
第一作者简介:苏炯铭(1984-),男,副研究员,博士,研究方向为智能博弈。
基金资助:Su Jiongming, Luo Junren, Chen Shaofei
Received:2023-09-22
Revised:2023-11-29
Online:2025-02-14
Published:2025-02-10
摘要:
随着人工智能技术的发展,特别是大型预训练模型理论的推动,智能博弈决策策略求解的一些新视角逐渐受到广泛关注和探讨。结合人工智能技术的发展与智能博弈决策策略求解范式的转变,以国际象棋(两人零和完美信息博弈)、强权外交(多人一般和不完美信息博弈)两款桌面游戏,星际争霸(多智能体马尔可夫博弈)为序贯决策实证分析研究对象,依循人工智能发展的新视角分析策略求解新范式、新方式,从决策大模型范式、生成式人工智能模型、大模型智能体关键技术共3个方面探析智能博弈决策大模型关键技术,为新技术体制下智能博弈决策问题的研究提供借鉴。
中图分类号:
苏炯铭,罗俊仁,陈少飞 . 智能博弈决策策略求解新视角实证分析[J]. 系统仿真学报, 2025, 37(2): 345-361.
Su Jiongming,Luo Junren,Chen Shaofei . An Empirical Analysis of New Perspectives for Strategy Solving in Intelligent Game-theoretic Decision-making[J]. Journal of System Simulation, 2025, 37(2): 345-361.
表1
面向兵棋推演的典型人工智能项目
| 项目名称 | 项目概览 | 研究目的 | 研究机制 | 关键发现 |
|---|---|---|---|---|
打破游戏规则 Gamebreaker | 利用视频游戏研究如何在兵棋推演中使用AI | 为了理解如何使用AI来解决模拟游戏中的多种问题,包括评估游戏平衡、识别新战术,以及测试电子游戏中最不稳定的行动。目标是使用AI创造不平衡的兵棋 | 9个团队的任务是破解两款商业电子游戏,操纵游戏以识别游戏中的意外状态(游戏动态未按预期运行),其目的是设计一种可以扩展到兵棋推演场景的方法。Blue Waves团队试图使用自主对抗、可解释人工智能和人工神经网络来预测结果,并确定某些对抗的输赢原因;Northrop Grumman团队计划建模并攻克“指挥:现代作战”模拟环境 | 可以借鉴商业游戏行业的成功经验,而不是从零开始开发国防应用。高度量化的方法可能适用于战术游戏或带有预先确定规则手册的游戏。不清楚这是否适用于具有高度不确定性的兵棋对抗 |
头脑风暴 BrainSTORM | 研究战役级多域作战模型 | 评估人工智能是否可以增强行动分析,以及人工智能辅助的非专家玩家是否可以在兵棋推演中击败专家团队 | 头脑风暴由三种不同的工具组成:“兵棋云”旨在促进高层次的战略开发;“作战行动序列(course of action,COA)比较”有助于将这些战略转化成为详细的COA计划;“SpeedSTORM”人工智能指令推荐所依托的访问环境 | 早期的实验结果表明,用户更喜欢依靠自己来解释人工智能的建议,而不是全盘接受 |
阴影 SHADE | 利用人工智能改善外交战略决策,特别是谈判过程 | 调查人工智能在多大程度上可以模仿人类的外交行为,包括“欺骗、共谋、画像”和“复杂的多方互动”。希望提高人们对谈判中涉及复杂沟通问题的理解 | 采用开源的“外交”游戏引擎来训练和评估人工智能体,方便人类与“外交”智能体对抗。目前已有团队创建了基准智能体来帮助训练 | 研究人员正在努力了解人工智能程序如何在更具战略意义的视角处理人类的担忧,例如,欺骗性的人类行为。当前的一些探索示例是开发一个原型AI |
作战 COMBAT | 开发模拟红队行为的人工智能程序,在兵棋推演中对抗蓝队 | 为红队制定多个可行的行动方案。利用这些基于人工智能的COA来确定蓝队的最佳反应。目标是使用人工智能来帮助、激发新的蓝队行为 | DARPA选择了一些公司的方案来开发人工智能应用。这些公司的任务是根据“俄罗斯战争方式:俄罗斯地面部队的力量结构、战术和现代化”来制定初始战术 | 目前不清楚该项目是否表明人工智能红队的成功,缺乏该种人工智能方法取得成功结果的公开信息 |
权杖 SCEPTER | 旨在使用自动化和人工智能技术来探索和开发新的COA方案 | 旨在研究是否可以通过先进的自动化来提高COA方案的生成速度,以及这些COA是否可以战胜人类的方案 | 为机器生成COA方案的策略将在可信的模拟环境中进行测试,并由人类对其进行评估 | 该项目处于早期阶段,需要进一步跟踪其发展 |
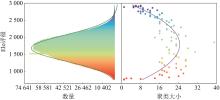
图1
国际象棋非传递性度量
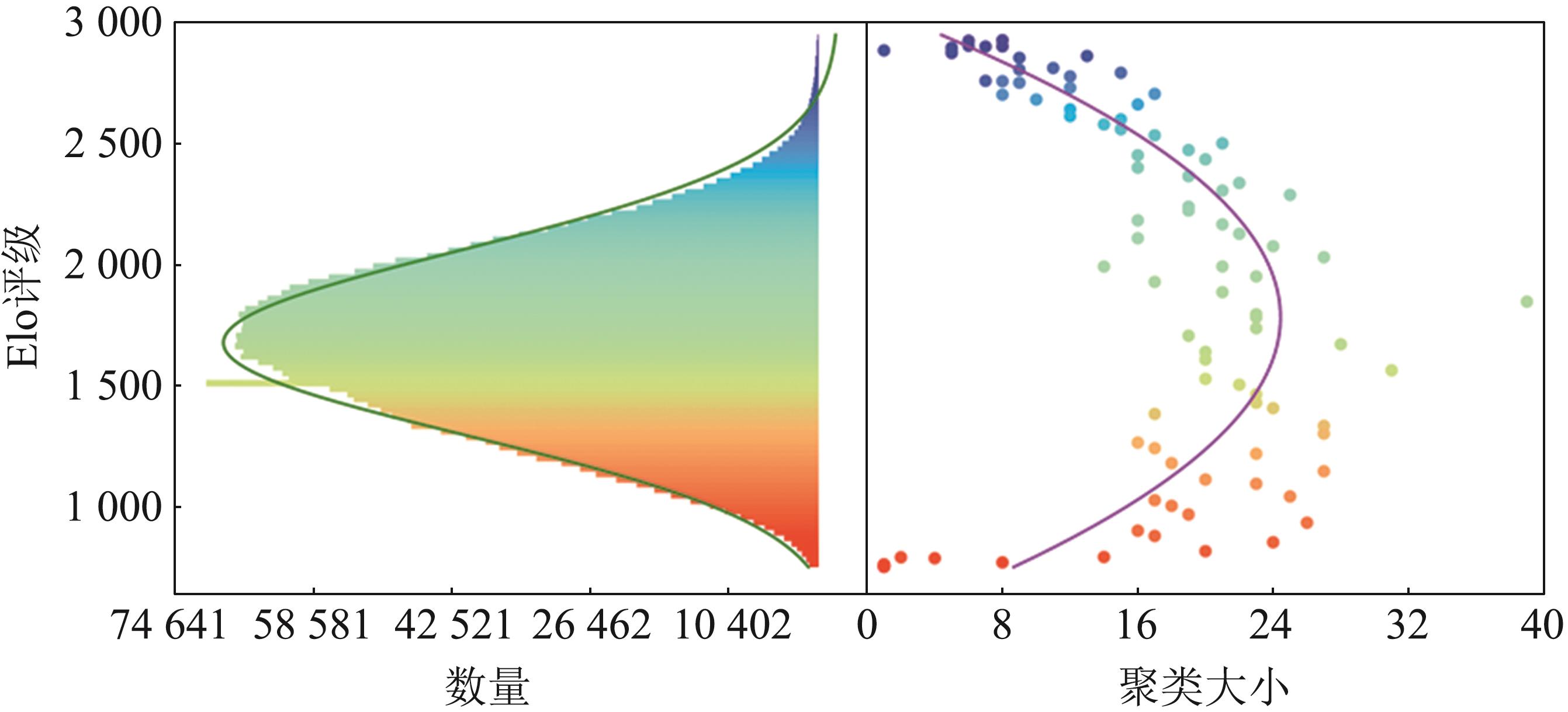
图2
对抗性策略环
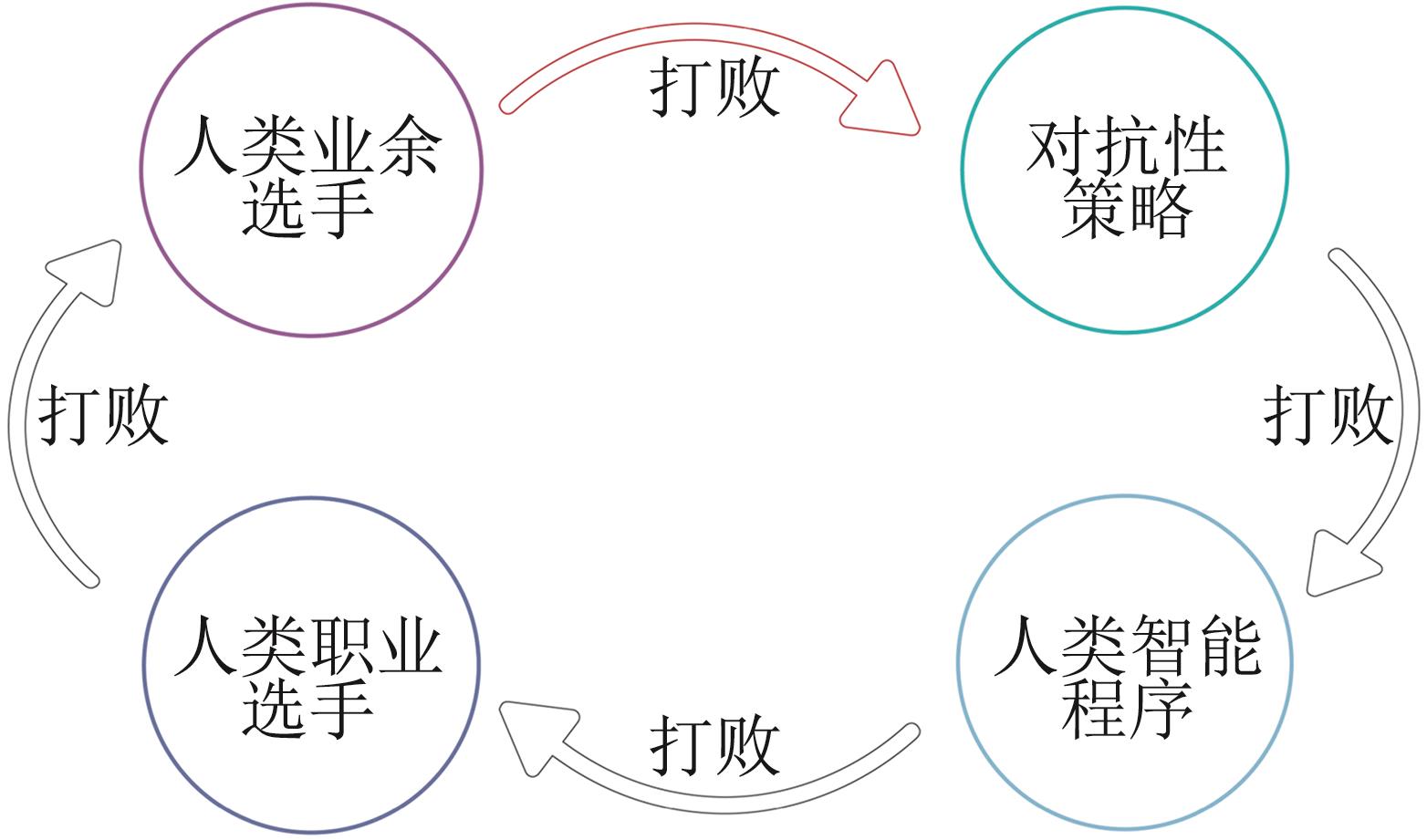

图3
国际象棋Transformer
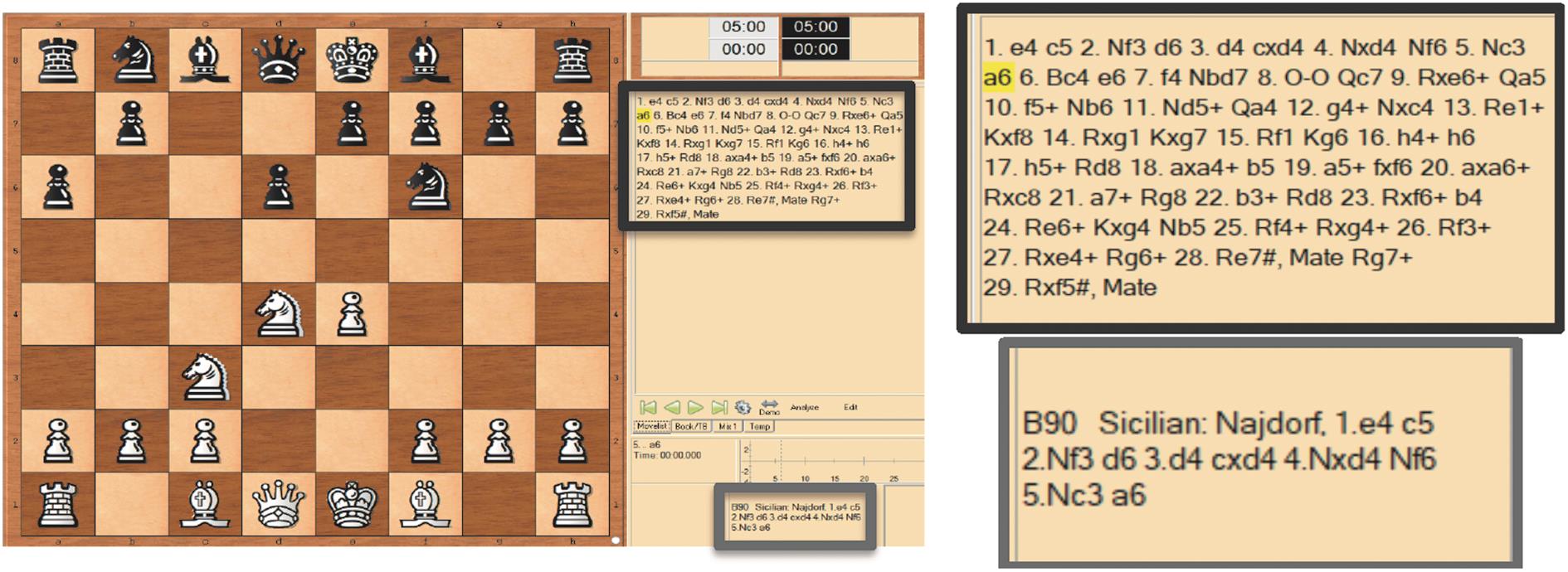
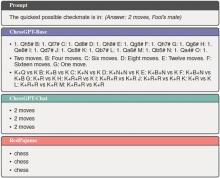
图4
国际象棋最快“将军”问题
图5
类人正则化策略
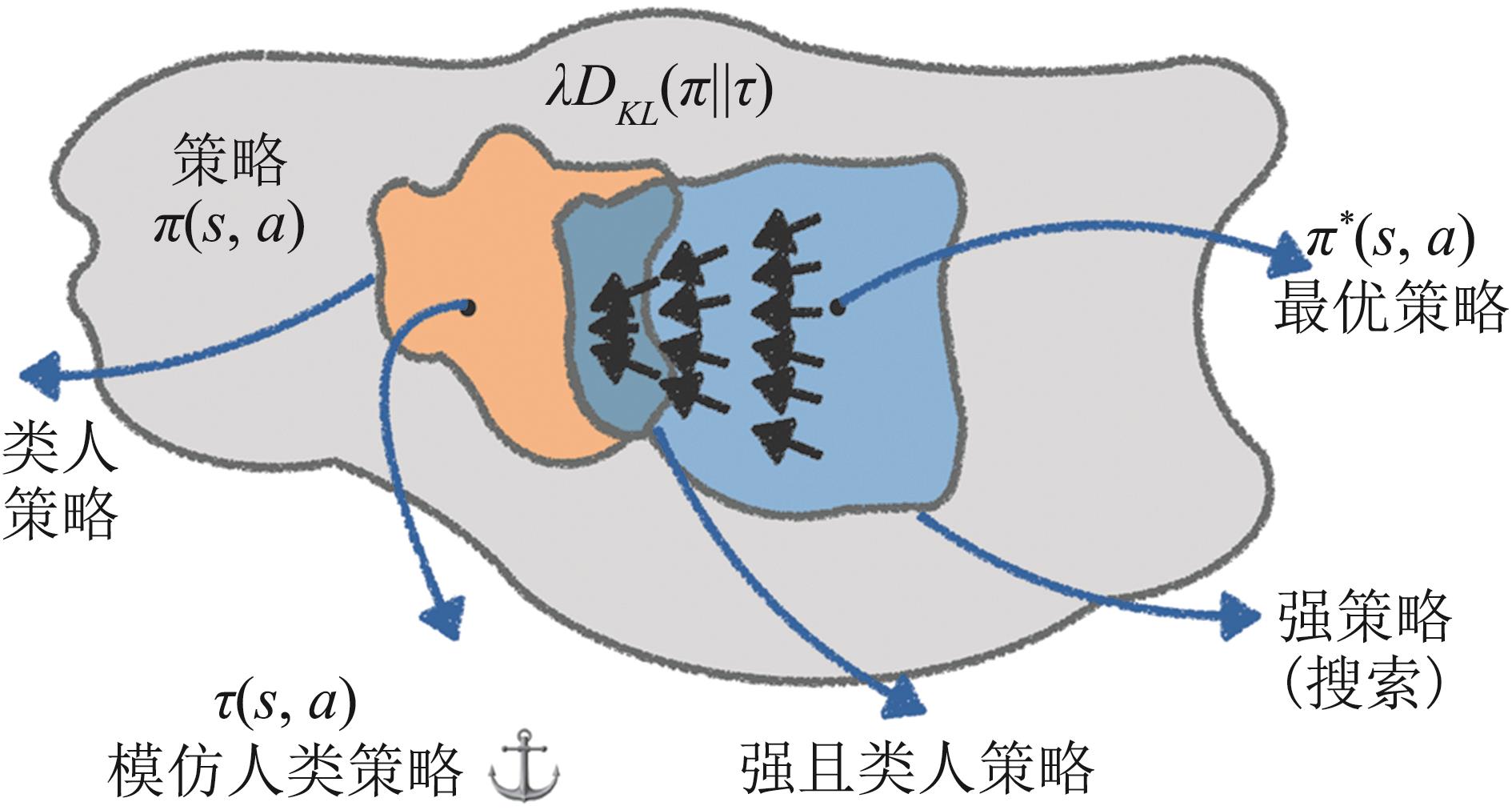
图6
分布式KL正则化策略[32]
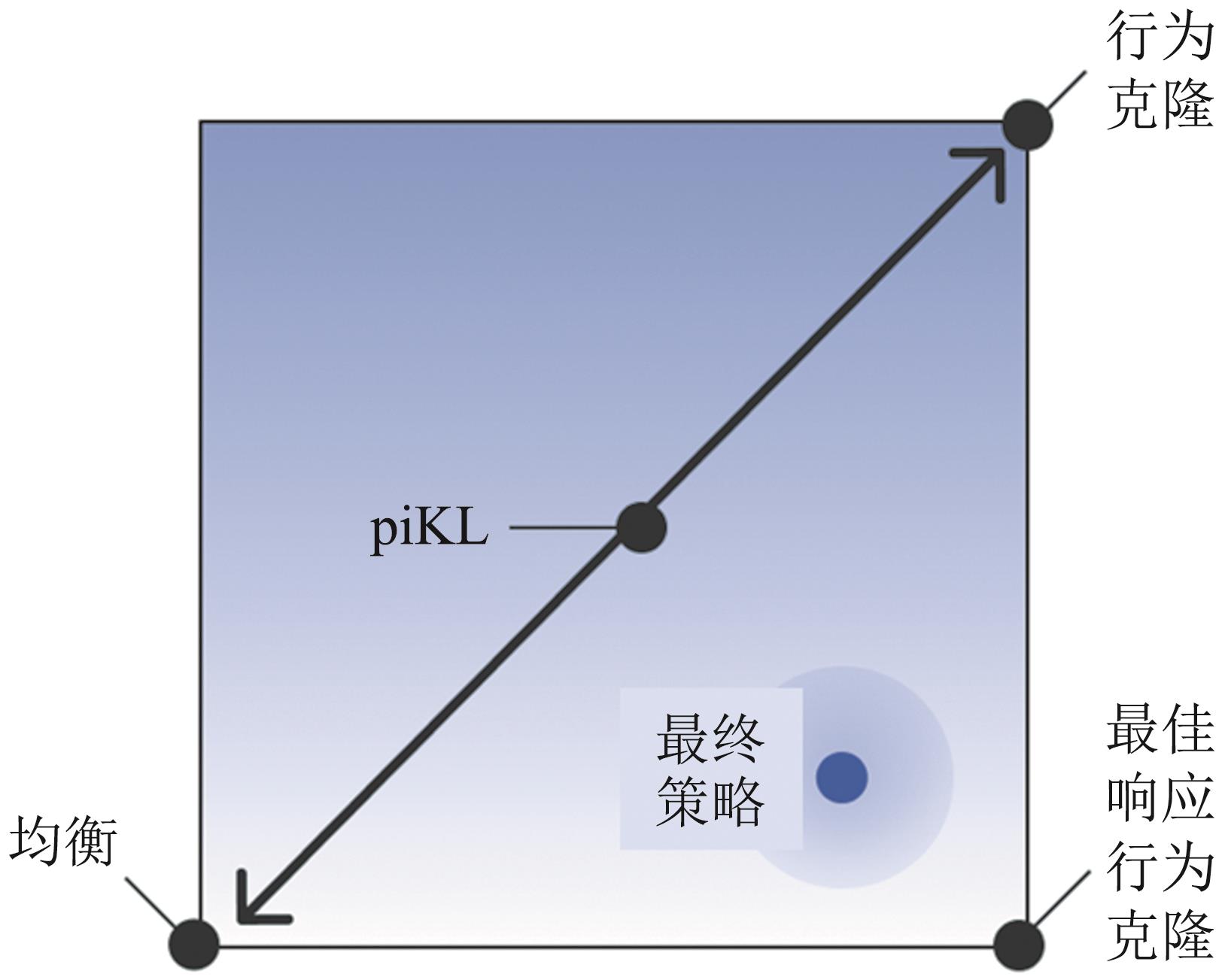
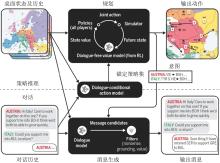
图7
策略推理与对话架构[33]
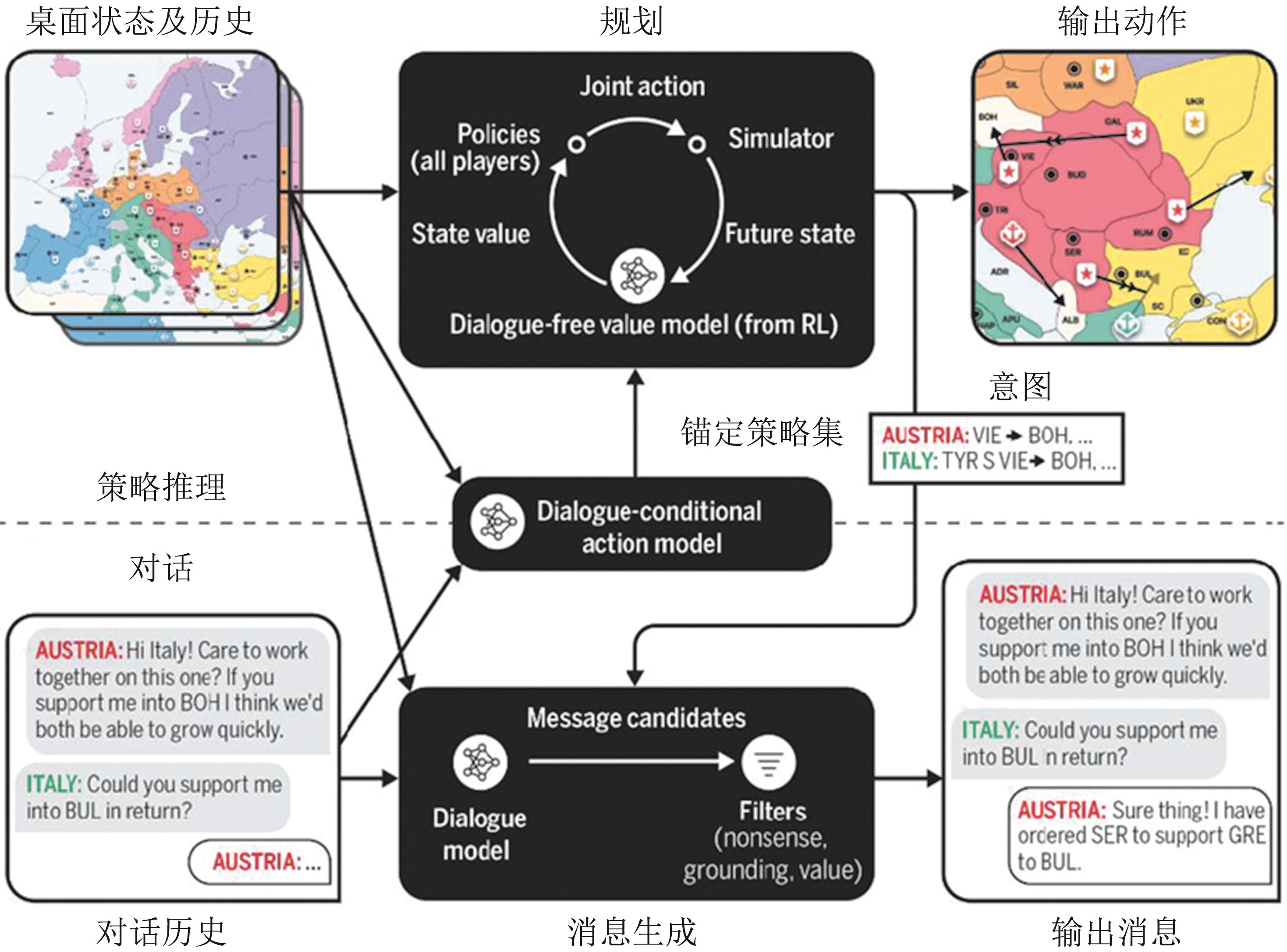
图8
多智能体势分解过程
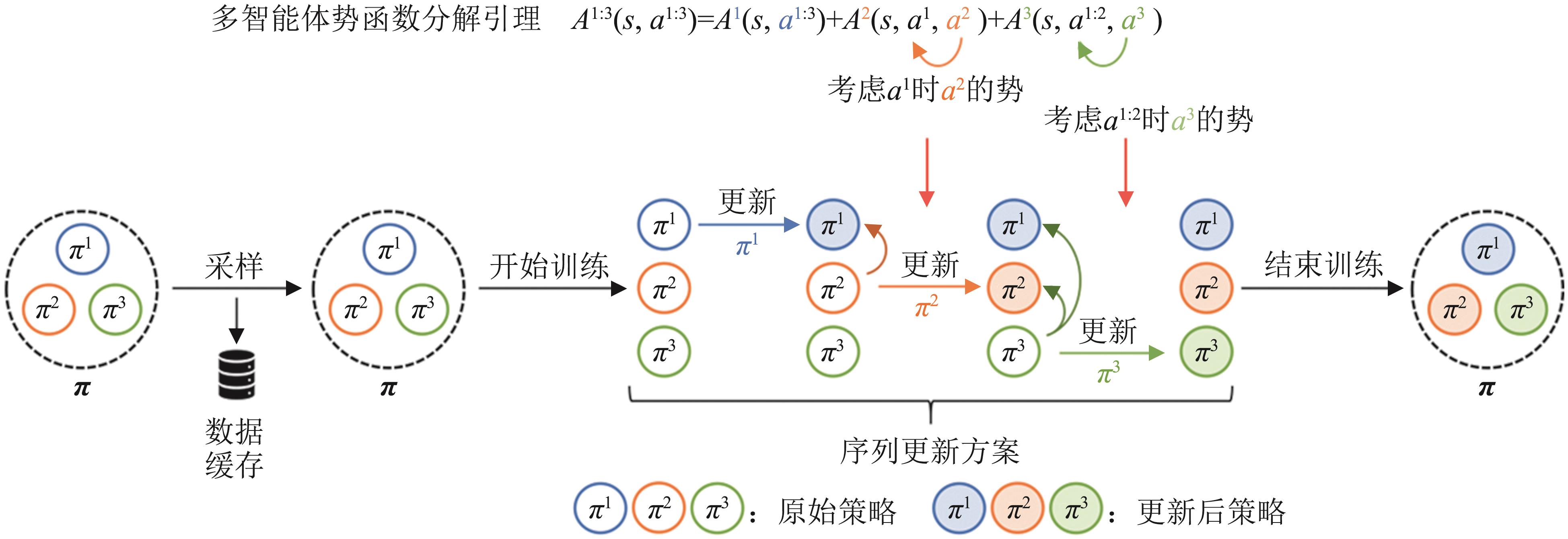
图9
多任务离线预训练与在线微调
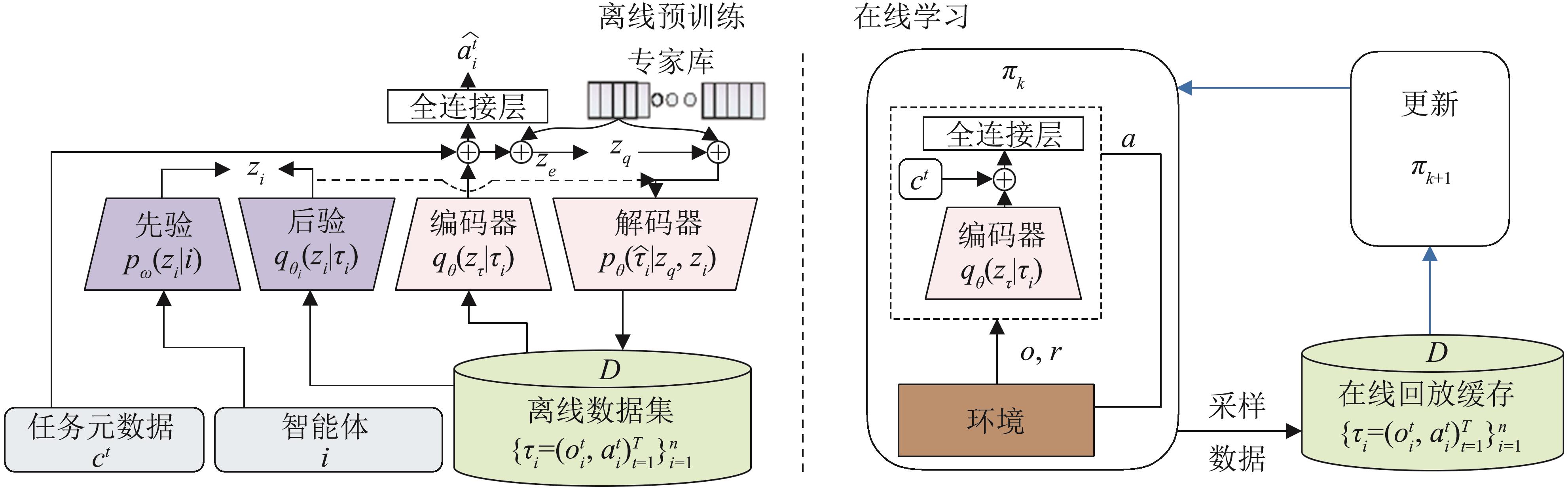
图10
开放式不完备信息多方动态博弈
图11
世界范围概念与多智能体学习
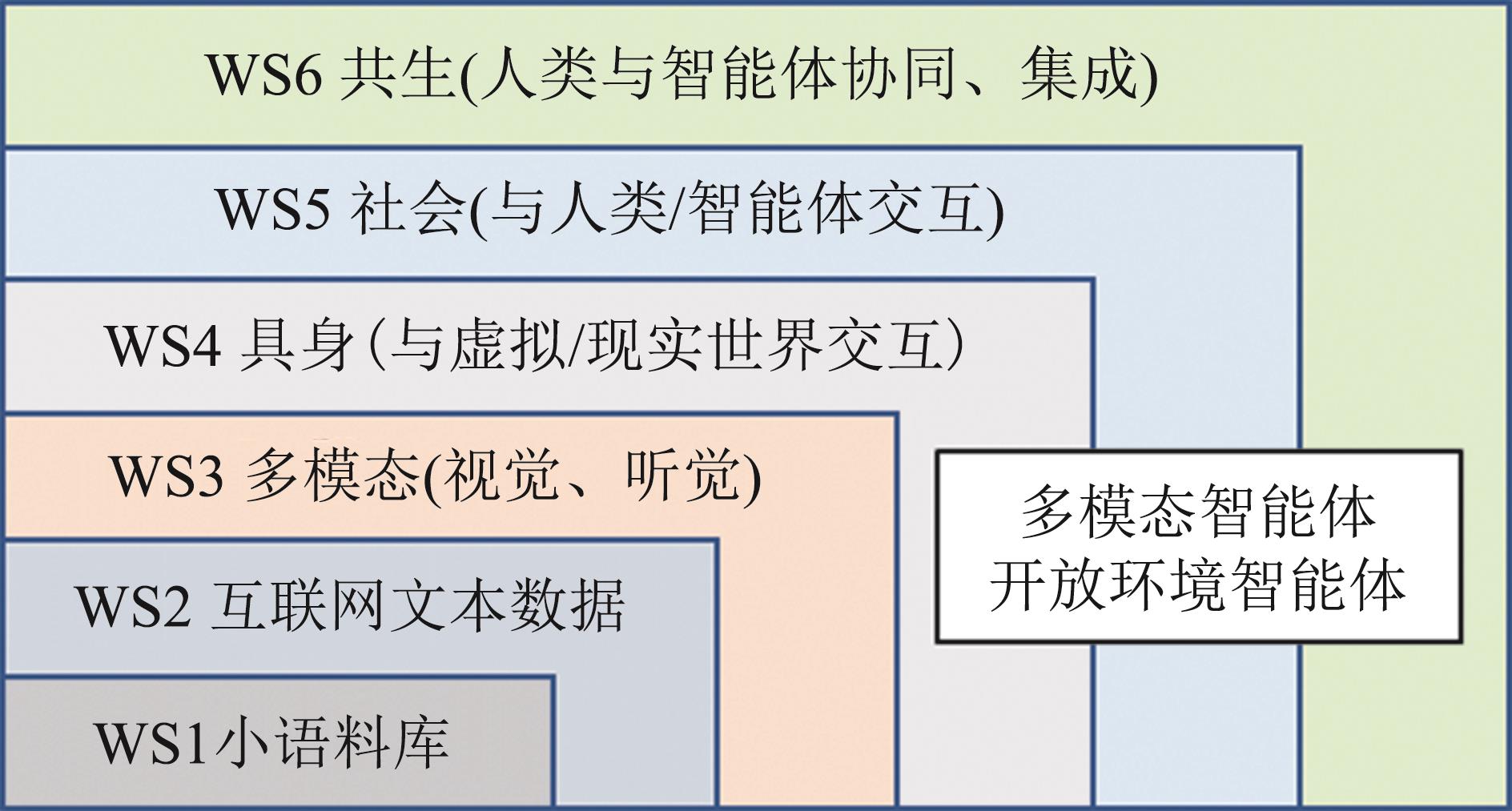

图12
决策智能体模型
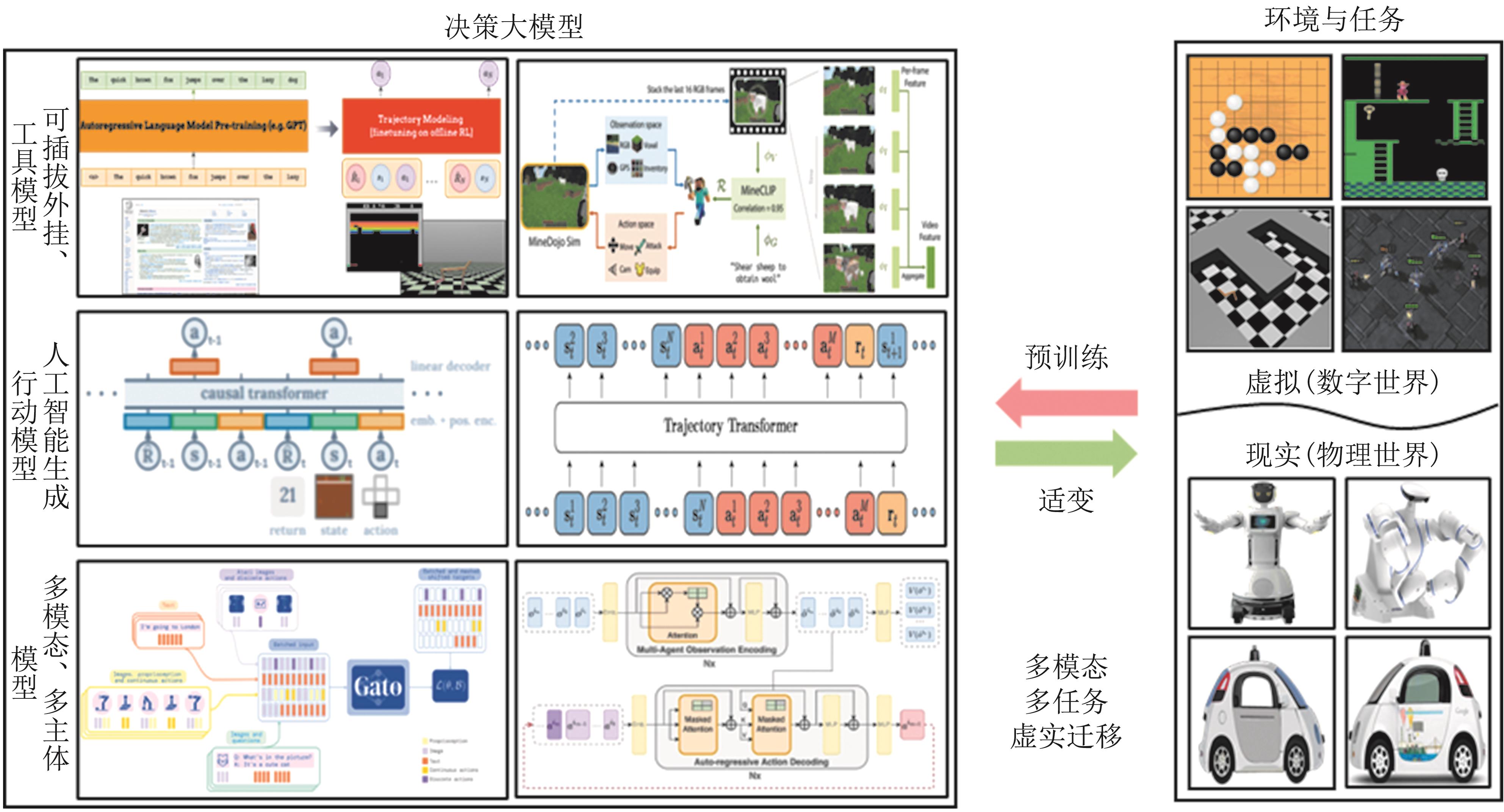
图13
生成式人工智能关键技术
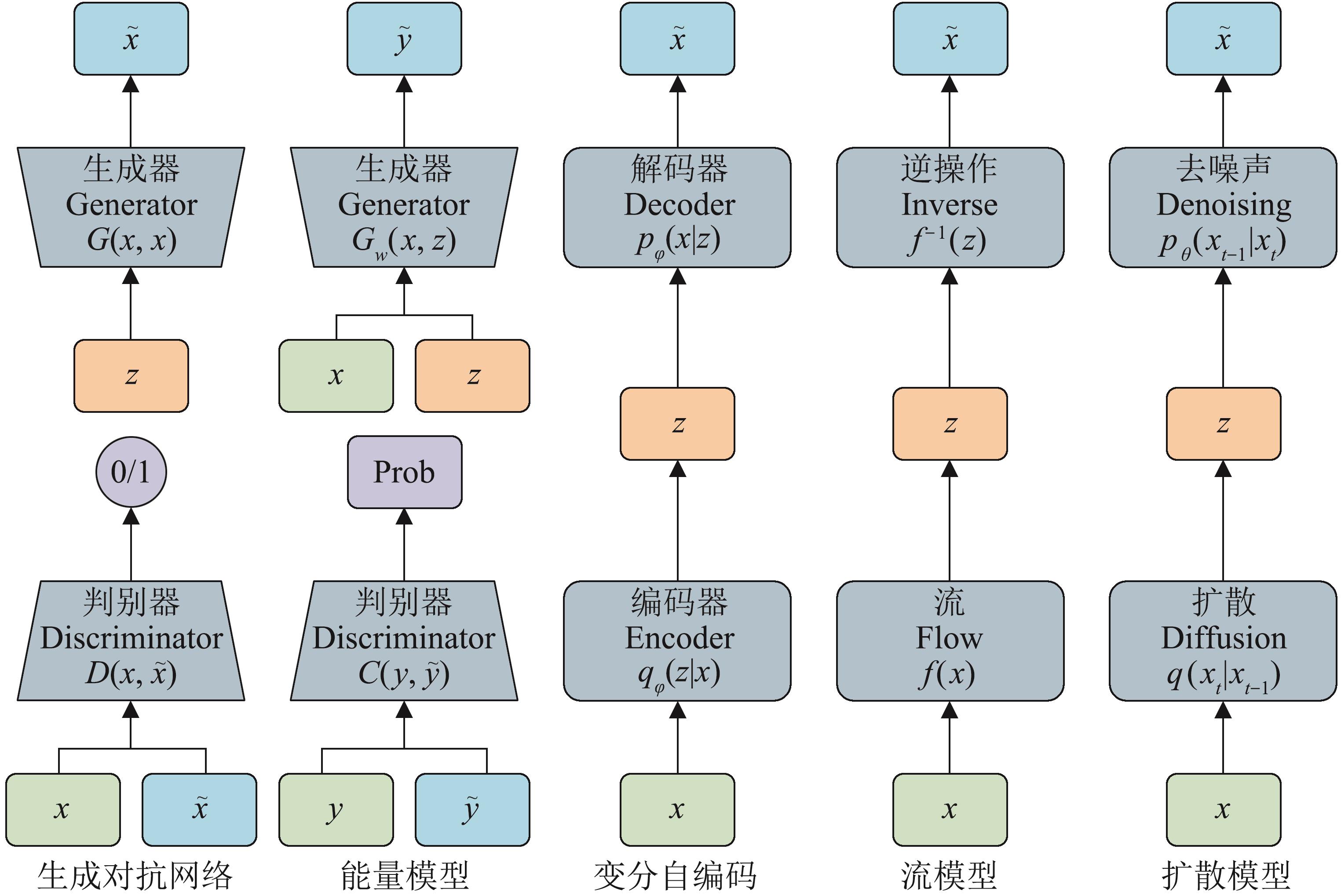
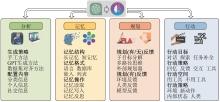
图14
大模型智能体设计框架[69]
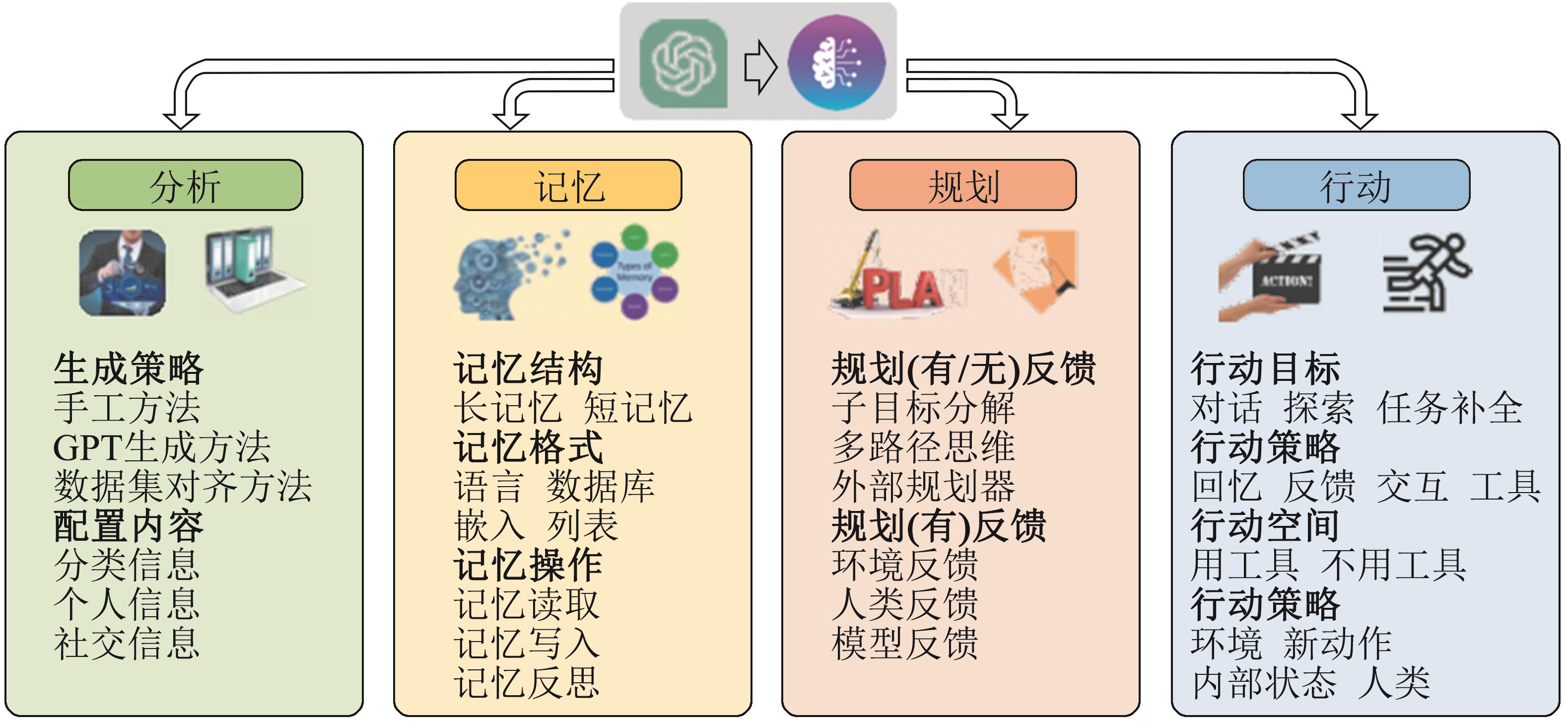
图15
基于大语言模型的多模态智能体[71]
| 1 | 罗俊仁, 张万鹏, 苏炯铭, 等. 多智能体博弈学习研究进展[J]. 系统工程与电子技术, 2024, 46(5): 1628-1655. |
| Luo Junren, Zhang Wanpeng, Su Jiongming, et al. Research Progress of Multi-agent Learning in Games[J]. Systems Engineering and Electronics, 2024, 46(5): 1628-1655. | |
| 2 | Edelkamp Stefan. Algorithmic Intelligence Towards an Algorithmic Foundation for Artificial Intelligence[M]. Cham: Springer International Publishing, 2023. |
| 3 | 胡晓峰, 齐大伟. 智能决策问题探讨——从游戏博弈到作战指挥, 距离还有多远[J]. 指挥与控制学报, 2020, 6(4): 356-363. |
| Hu Xiaofeng, Qi Dawei. On Problems of Intelligent Decision-making-how Far is It from Game-playing to Operational Command[J]. Journal of Command and Control, 2020, 6(4): 356-363. | |
| 4 | Clark B, Walton T A. Taking Back the Seas: Transforming the U.S. Surface Fleet for Decision-centric Warfare[EB/OL]. (2019-12-31) [2023-08-25]. . |
| 5 | Defense Science Board. Final Report of the Defense Science Board (DSB) Task Force on Gaming, Exercising, Modeling, and Simulation[EB/OL]. [2023-08-25]. |
| 6 | Nilchiani R R, Verma D, Antón P S. Joint All-domain Command and Control (JADC2) Opportunities on the Horizon[EB/OL]. [2023-08-25]. |
| 7 | Knack A, Powell R. Artificial Intelligence in Wargaming: An Evidence-based Assessment of AI Applications[EB/OL]. [2023-08-25]. . |
| 8 | Johnson B W, Green J M, Kendall W, et al. Game Theory and Prescriptive Analytics for Naval Wargaming Battle Management Aids[EB/OL]. [2023-08-25]. . |
| 9 | 杜正军, 陈超, 姜鑫. 基于影响网络与序贯博弈的作战行动序列模型与求解[J]. 系统工程理论与实践, 2013, 33(1): 215-222. |
| Du Zhengjun, Chen Chao, Jiang Xin. Modeling and Solution of Course of Action Based on Influence Net and Sequential Game[J]. Systems Engineering-theory & Practice, 2013, 33(1): 215-222. | |
| 10 | Shannon C E. Programming a Computer for Playing Chess[C]//First Presented at the National IRE Convention, March 9, 1949 , and Also in Claude Elwood Shannon Collected Papers. Piscataway: IEEE, 1993: 637-656. |
| 11 | Ensmenger N. Is Chess the Drosophila of Artificial Intelligence? A Social History of an Algorithm[J]. Social Studies of Science, 2012, 42(1): 5-30. |
| 12 | Campbell M, Hoane A J, Hsu F H. Deep Blue[J]. Artificial Intelligence, 2002, 134(1): 57-83. |
| 13 | Czarnecki W M, Gidel G, Tracey B, et al. Real World Games Look Like Spinning Tops[C]//Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 1463. |
| 14 | Sanjaya R, Wang Jun, Yang Yaodong. Measuring the Non-transitivity in Chess[J]. Algorithms, 2022, 15(5): 152. |
| 15 | Silver D, Hubert T, Schrittwieser J, et al. A General Reinforcement Learning Algorithm That Masters Chess, Shogi, and Go Through Self-play[J]. Science, 2018, 362(6419): 1140-1144. |
| 16 | Mcgrath T, Kapishnikov A, Tomašev N, et al. Acquisition of Chess Knowledge in AlphaZero[J]. Proceedings of the National Academy of Sciences of the United States of America, 2022, 119(47): e2206625119. |
| 17 | Wang T T, Gleave A, Belrose N, et al. Adversarial Policies Beat Professional-level Go AIs [EB/OL]. (2023-07-13) [2023-08-25]. . |
| 18 | Czech Johannes, Blüml Jannis, Kersting Kristian. Representation Matters: The Game of Chess Poses a Challenge to Vision Transformers[EB/OL]. (2023-04-28) [2023-08-25]. . |
| 19 | Stöckl Andreas. Watching a Language Model Learning Chess[C]//Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2021). Stroudsburg: ACL, 2021: 1369-1379. |
| 20 | Toshniwal S, Wiseman S, Livescu K, et al. Chess as a Testbed for Language Model State Tracking[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 11385-11393. |
| 21 | Noever D, Ciolino M, Kalin J. The Chess Transformer: Mastering Play Using Generative Language Models [EB/OL]. (2020-08-02) [2023-08-25]. . |
| 22 | Feng Xidong, Luo Yicheng, Wang Ziyan, et al. ChessGPT: Bridging Policy Learning and Language Modeling[EB/OL]. [2023-08-25]. . |
| 23 | Johansson Stefan J, Håård Fredrik. Tactical Coordination in No-press Diplomacy[C]//Proceedings of the Fourth International Joint Conference on Autonomous Agents and Multiagent Systems. New York: Association for Computing Machinery, 2005: 423-430. |
| 24 | Stormont D P, Allan V H. A Comparison of Diplomacy Gameboard Graph Search Algorithms[C]//Proceedings of the 4th International Conference on Agents and Artificial Intelligence. Setúbal: SciTePress, 2012: 371-374. |
| 25 | Kemmerling Markus, Ackermann Niels, Preuss Mike. Nested Look-ahead Evolutionary Algorithm Based Planning for a Believable Diplomacy Bot[C]//Applications of Evolutionary Computation. Berlin: Springer Berlin Heidelberg, 2011: 83-92. |
| 26 | Dave de Jonge, Sierra Carles. D-brane: A Diplomacy Playing Agent for Automated Negotiations Research[J]. Applied Intelligence, 2017, 47(1): 158-177. |
| 27 | Marinheiro João. A Generic Agent Architecture for Cooperative Multi-agent Games[D]. Porto: University of Porto, 2016. |
| 28 | Kraus S, Lehmann D. Diplomat, an Agent in a Multi Agent Environment: An Overview[C]//Seventh Annual International Phoenix Conference on Computers an Communications. Piscataway: IEEE, 1988: 434-438. |
| 29 | Paquette P, Lu Y, Bocco S, et al. No Press Diplomacy: Modeling Multi-agent Gameplay[C]//Advances in Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 4474-4485. |
| 30 | Anthony T, Eccles T, Tacchetti A, et al. Learning to Play No-press Diplomacy with Best Response Policy Iteration[C]//Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 17987-18003. |
| 31 | Bakhtin A, Wu D, Lerer A, et al. No-press Diplomacy from Scratch[C]//Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 18063-18074. |
| 32 | Bakhtin A, Wu D J, Lerer A, et al. Mastering the Game of No-press Diplomacy via Human-regularized Reinforcement Learning and Planning[EB/OL]. (2022-10-11) [2023-08-25]. . |
| 33 | Meta Fundamental AI Research Diplomacy Team (FAIR), Bakhtin A, Brown N, et al. Human-level Play in the Game of Diplomacy by Combining Language Models with Strategic Reasoning[J]. Science, 2022, 378(6624): 1067-1074. |
| 34 | Gemp I, Savani R, Lanctot M, et al. Sample-based Approximation of Nash in Large Many-player Games via Gradient Descent[C]//Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems. Richland: International Foundation for Autonomous Agents and Multiagent Systems, 2022: 507-515. |
| 35 | Sokota S, D'orazio R, Kolter J Z, et al. A Unified Approach to Reinforcement Learning, Quantal Response Equilibria, and Two-player Zero-sum Games[EB/OL]. (2022-06-03) [2023-08-25]. |
| 36 | Zhang H, Lerer A, Brown N. Equilibrium Finding in Normal-form Games via Greedy Regret Minimization[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 9484-9492. |
| 37 | Gray J, Lerer A, Bakhtin A, et al. Human-level Performance in No-press Diplomacy via Equilibrium Search[EB/OL]. (2021-05-03) [2023-08-25]. . |
| 38 | Jacob A P, Wu D J, Farina G, et al. Modeling Strong and Human-like Gameplay with KL-regularized Search[C]//Proceedings of the 39th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2022: 9695-9728. |
| 39 | Dafoe A, Bachrach Y, Hadfield G, et al. Cooperative AI: Machines Must Learn to Find Common Ground[J]. Nature, 2021, 593(7857): 33-36. |
| 40 | Kramár János, Eccles T, Gemp I, et al. Negotiation and Honesty in Artificial Intelligence Methods for the Board Game of Diplomacy[J]. Nature Communications, 2022, 13(1): 7214. |
| 41 | Peskov D, Cheng B, Elgohary A, et al. It Takes Two to Lie: One to Lie, and One to Listen[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 3811-3854. |
| 42 | Shi Weiyan, Dinan E, Renduchintala A, et al. AutoReply: Detecting Nonsense in Dialogue Introspectively with Discriminative Replies[EB/OL]. (2022-11-22) [2023-08-25]. . |
| 43 | Ahuja Hansin, Lynnette Hui Xian Ng, Jaidka Kokil. Using Graph-aware Reinforcement Learning to Identify Winning Strategies in Diplomacy Games (Student Abstract)[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 12899-12900. |
| 44 | Mukobi G, Erlebach H, Lauffer N, et al. Welfare Diplomacy: Benchmarking Language Model Cooperation [EB/OL]. (2023-10-13) [2023-10-18]. . |
| 45 | Samvelyan M, Rashid T, Schroeder De Witt C, et al. The StarCraft Multi-agent Challenge[C]//Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems. 2019: 2186-2188. |
| 46 | Vinyals O, Babuschkin I, Czarnecki W M, et al. Grandmaster Level in StarCraft II Using Multi-agent Reinforcement Learning[J]. Nature, 2019, 575(7782): 350-354. |
| 47 | Wang Xiangjun, Song Junxiao, Qi Penghui, et al. SCC: An Efficient Deep Reinforcement Learning Agent Mastering the Game of StarCraft II[C]//Proceedings of the 38th International Conference on Machine Learning. Chia Laguna Resort: PMLR, 2021: 10905-10915. |
| 48 | Kim M, Oh J, Lee Y, et al. The StarCraft Multi-agent Challenges+ : Learning of Multi-stage Tasks and Environmental Factors Without Precise Reward Functions [EB/OL]. (2023-07-06) [2023-08-25]. . |
| 49 | Ellis B, Moalla S, Samvelyan M, et al. SMACv2: An Improved Benchmark for Cooperative Multi-agent Reinforcement Learning [EB/OL]. (2022-12-04) [2023-08-25]. . |
| 50 | Michalski A, Christianos F, Albrecht S V. SMAClite: A Lightweight Environment for Multi-agent Reinforcement Learning [EB/OL]. (2023-05-09) [2023-08-25]. . |
| 51 | Zhang B, Li L, Xu Z, et al. Inducing Stackelberg Equilibrium Through Spatio-temporal Sequential Decision-making in Multi-Agent Reinforcement Learning [EB/OL]. (2023-04-01) [2023-08-25]. . |
| 52 | Yu C, Yang X, Gao J, et al. Asynchronous Multi-agent Reinforcement Learning for Efficient Real-time Multi-robot Cooperative Exploration [EB/OL]. (2023-01-09) [2023-08-25]. . |
| 53 | Zang Yifan, He Jinmin, Li Kai, et al. Sequential Cooperative Multi-agent Reinforcement Learning[C]//Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems. Richland: International Foundation for Autonomous Agents and Multiagent Systems, 2023: 485-493. |
| 54 | Zhong Yifan, Kuba J G, Feng Xidong, et al. Heterogeneous-agent Reinforcement Learning[EB/OL]. [2023-08-25]. . |
| 55 | Mathieu M, Ozair S, Srinivasan S, et al. StarCraft II Unplugged: Large Scale Offline Reinforcement Learning[C]//Deep RL Workshop NeurIPS 2021. Seattle, WA, USA, 2021: 1-13. |
| 56 | Meng L, Wen M, Yang Y, et al. Offline Pre-trained Multi-agent Decision Transformer: One Big Sequence Model Tackles all SMACtasks [EB/OL]. (2021-12-06) [2023-08-25]. . |
| 57 | Meng Linghui, Wen Muning, Le Chenyang, et al. Offline Pre-trained Multi-agent Decision Transformer[J]. Machine Intelligence Research, 2023, 20(2): 233-248. |
| 58 | Meng Linghui, Ruan Jingqing, Xiong Xuantang, et al . M 3: Modularization for Multi-task and Multi-agent Offline Pre-training[C]//Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems. Richland: International Foundation for Autonomous Agents and Multiagent Systems, 2023: 1624-1633. |
| 59 | Wei J, Tay Y, Bommasani R, et al. Emergent Abilities of Large Language Models[EB/OL]. (2022-10-26) [2023-08-25]. . |
| 60 | Bisk Y, Holtzman A, Thomason J, et al. Experience Grounds Language [EB/OL]. (2020-11-02) [2023-08-25]. . |
| 61 | Hao Rui, Liu Dianbo, Hu Linmei. Enhancing Human Capabilities Through Symbiotic Artificial Intelligence with Shared Sensory Experiences [EB/OL]. (2023-05-26) [2023-08-25]. . |
| 62 | 温颖, 万梓煜, 张劭, 等. 多模态环境中的多智能体强化学习: 预训练大模型视角[EB/OL]. (2023-03-10) [2023-08-25]. . |
| 63 | Tadross D, Harris K. Donovan-AI Powered Decision Making for Defense [EB/OL]. (2023-06-29). [2023-10-18]. . |
| 64 | Yang S, Nachum O, Du Yilun, et al. Foundation Models for Decision Making: Problems, Methods, and Opportunities [EB/OL]. (2023-03-07) [2023-08-25]. . |
| 65 | Xu Minrui, Du Hongyang, Niyato D, et al. Unleashing the Power of Edge-cloud Generative AI in Mobile Networks: A Survey of AIGC Services[EB/OL]. (2023-10-31) [2023-11-25]. . |
| 66 | Zhang Hongxin, Du Weihua, Shan Jiaming, et al. Building Cooperative Embodied Agents Modularly with Large Language Models[EB/OL]. (2023-07-05) [2023-08-25]. . |
| 67 | Hong Sirui, Zhuge Mingchen, Chen J, et al. MetaGPT: Meta Programming for A Multi-agent Collaborative Framework[EB/OL]. (2023-11-06) [2023-11-25]. . |
| 68 | Liu Zhiwei, Yao Weiran, Zhang Jianguo, et al. BOLAA: Benchmarking and Orchestrating LLM-augmented Autonomous Agents[EB/OL]. (2023-08-11) [2023-11-25]. . |
| 69 | Wang Lei, Ma Chen, Feng Xueyang, et al. A Survey on Large Language Model Based Autonomous Agents[EB/OL]. (2023-08-22) [2023-08-25]. . |
| 70 | Qin Yujia, Hu Shengding, Lin Yankai, et al. Tool Learning with Foundation Models[EB/OL]. (2023-06-15) [2023-08-25]. . |
| 71 | Yang Hui, Yue Sifu, He Yunzhong. Auto-GPT for Online Decision Making: Benchmarks and Additional Opinions[EB/OL]. (2023-06-04) [2023-08-25]. . |
| 72 | Li Chunyuan, Gan Zhe, Yang Zhengyuan, et al. Multimodal Foundation Models: From Specialists to General-purpose Assistants[EB/OL]. (2023-09-18) [2023-09-22]. . |
| [1] | 张云景, 杨明辉, 王昊. 基于预训练与可微模糊建模的NeRF优化方法及仿真研究[J]. 系统仿真学报, 2026, 38(3): 608-619. |
| [2] | 闫强, 张倩语, 魏娜. 基于演化博弈的生成式人工智能幻觉应对分析[J]. 系统仿真学报, 2026, 38(2): 399-415. |
| [3] | 罗俊仁, 张万鹏, 项凤涛, 蒋超远, 陈璟. 智能推演综述:博弈论视角下的战术战役兵棋与战略博弈[J]. 系统仿真学报, 2023, 35(9): 1871-1894. |
| [4] | 柴慧敏, 张勇, 李欣粤, 宋雅楠. 基于深度学习的空中目标威胁评估方法[J]. 系统仿真学报, 2022, 34(7): 1459-1467. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
