


0 引言
随着人工智能、云原生、弹性通信等技术范式的变革,博弈强对抗的多域战场未来将朝着模块分散化、无人自主化、智能赋能化方向迈进。美军陆续提出了分布式作战、联合全域作战、马赛克战、决策中心战等新型作战概念,为其未来的智能指控系统开发提供了蓝图引领。基于“算力+算法+数据”三者的螺旋融合,面向智能博弈求解的算法博弈论、强化学习、对手建模、元学习、持续学习等方法被广泛应用于金融、经济、交通等民用领域,指挥控制与决策辅助等军事领域。
本文采用实证分析视角切入,从国外兵棋推演相关技术研究的聚焦点出发,根据智能博弈技术研究进展,结合三类基准(国际象棋、强权外交、星际争霸)对当前三类典型博弈(完美信息博弈、不完美信息博弈、马尔可夫博弈)求解方法进行了全面梳理,围绕开放式博弈问题、根据博弈策略求解范式转变,分析了智能博弈决策大模型相关支撑技术与智能体设计方式。
1 智能博弈与决策智能
1.1 从机器博弈到作战指挥
虽然机器博弈领域取得了长足进步,但想将游戏对抗的相关算法直接应用于作战指挥决策仍然存在较大差距。胡晓峰等[3]从态势理解、知识利用、智能涌现(局部优化+全局平衡+控制调度)等方面分析了决策智能研究面临的若干问题,并指出了决策智能还需要跨过的可解释性、终身学习、机器常识与可被信任四道坎。
1.2 决策智能与军事智能博弈
表1 面向兵棋推演的典型人工智能项目
Table 1
| 项目名称 | 项目概览 | 研究目的 | 研究机制 | 关键发现 |
|---|---|---|---|---|
打破游戏规则 Gamebreaker | 利用视频游戏研究如何在兵棋推演中使用AI | 为了理解如何使用AI来解决模拟游戏中的多种问题,包括评估游戏平衡、识别新战术,以及测试电子游戏中最不稳定的行动。目标是使用AI创造不平衡的兵棋 | 9个团队的任务是破解两款商业电子游戏,操纵游戏以识别游戏中的意外状态(游戏动态未按预期运行),其目的是设计一种可以扩展到兵棋推演场景的方法。Blue Waves团队试图使用自主对抗、可解释人工智能和人工神经网络来预测结果,并确定某些对抗的输赢原因;Northrop Grumman团队计划建模并攻克“指挥:现代作战”模拟环境 | 可以借鉴商业游戏行业的成功经验,而不是从零开始开发国防应用。高度量化的方法可能适用于战术游戏或带有预先确定规则手册的游戏。不清楚这是否适用于具有高度不确定性的兵棋对抗 |
头脑风暴 BrainSTORM | 研究战役级多域作战模型 | 评估人工智能是否可以增强行动分析,以及人工智能辅助的非专家玩家是否可以在兵棋推演中击败专家团队 | 头脑风暴由三种不同的工具组成:“兵棋云”旨在促进高层次的战略开发;“作战行动序列(course of action,COA)比较”有助于将这些战略转化成为详细的COA计划;“SpeedSTORM”人工智能指令推荐所依托的访问环境 | 早期的实验结果表明,用户更喜欢依靠自己来解释人工智能的建议,而不是全盘接受 |
阴影 SHADE | 利用人工智能改善外交战略决策,特别是谈判过程 | 调查人工智能在多大程度上可以模仿人类的外交行为,包括“欺骗、共谋、画像”和“复杂的多方互动”。希望提高人们对谈判中涉及复杂沟通问题的理解 | 采用开源的“外交”游戏引擎来训练和评估人工智能体,方便人类与“外交”智能体对抗。目前已有团队创建了基准智能体来帮助训练 | 研究人员正在努力了解人工智能程序如何在更具战略意义的视角处理人类的担忧,例如,欺骗性的人类行为。当前的一些探索示例是开发一个原型AI |
作战 COMBAT | 开发模拟红队行为的人工智能程序,在兵棋推演中对抗蓝队 | 为红队制定多个可行的行动方案。利用这些基于人工智能的COA来确定蓝队的最佳反应。目标是使用人工智能来帮助、激发新的蓝队行为 | DARPA选择了一些公司的方案来开发人工智能应用。这些公司的任务是根据“俄罗斯战争方式:俄罗斯地面部队的力量结构、战术和现代化”来制定初始战术 | 目前不清楚该项目是否表明人工智能红队的成功,缺乏该种人工智能方法取得成功结果的公开信息 |
权杖 SCEPTER | 旨在使用自动化和人工智能技术来探索和开发新的COA方案 | 旨在研究是否可以通过先进的自动化来提高COA方案的生成速度,以及这些COA是否可以战胜人类的方案 | 为机器生成COA方案的策略将在可信的模拟环境中进行测试,并由人类对其进行评估 | 该项目处于早期阶段,需要进一步跟踪其发展 |
1.3 博弈视角下的智能指控
2 智能博弈决策AI实证分析
2.1 国际象棋—完美信息博弈
国际象棋可建模成“两人零和完美信息博弈”,这意味着与扑克或西洋双陆棋不同的是,所有特定于国际象棋的信息都为玩家所知,既不存在秘密也不存在机会。棋手双方都能看到棋盘上的位置,也知道对方的棋步,因为棋步不是同时下的,而是按顺序下的。因此,国际象棋是一种纯粹的智力游戏,是测试人工智能技术的完美环境。尽管国际象棋的合法位置数量惊人,但研究人员所依赖的事实是计算机可以比人类更准确、更快地处理问题,因此,在下棋时比人类“思考”得更快。国际象棋是一个受控的环境,在这个环境中,向计算机呈现一个情境和一个目标,计算机必须找到实现目标的可能性并做出决定。
在人机对抗领域,1996年由IBM开发的超级计算机深蓝(DeepBlue)[12]与国际象棋世界冠军卡斯帕罗夫在纽约进行了历史性对抗比赛,以2:4的比分输给了冠军,但1997年的复赛中,深蓝成为首个在标准赛事中战胜国际冠军的计算机程序。21世纪以来,国际象棋AI的发展取得了长足进步,2009年开始可以系统性地击败人类顶级棋手。
2.1.1 策略空间形态的非传递性
尽管人工智能技术在国际象棋方面取得了算法突破,但对国际象棋的策略空间形态了解仍然有限。Czarnecki等[13]提出了策略空间陀螺猜想,给出了策略传递性和非传递性概念,指出大多数现实世界的博弈策略都拥有一个陀螺状旋转的策略空间。其中,传递性指的是一种策略比其他策略更好,在传递博弈中,如果策略A战胜了策略B,而B又战胜了C,那么A就会战胜C。而非传递博弈是指存在一个获胜策略循环的博弈。例如,策略A打败策略B,策略B打败策略C,但策略A输给了策略C。
图1
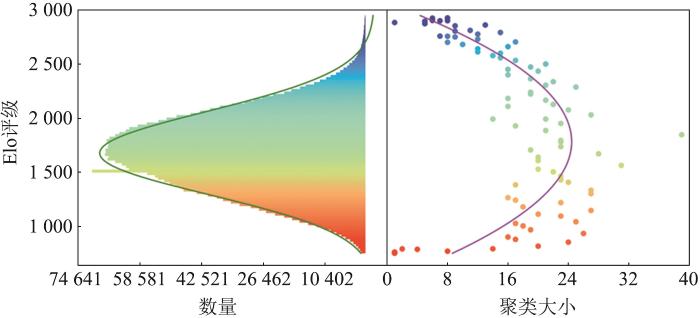
图1展示了Lichess 2020数据集中策略的Elo评级直方图与每个Elo评级的非传递维,其中,非传递性是通过纳什簇的大小和“石头-剪刀-布”循环的次数来衡量的。随着技能的Elo评级向高发展(向上)或退化(向下),这种非传递性逐渐减弱,Elo直方图的峰值出现在1 300~1 700之间,这是大多数人类玩家陷入困境的范围。非传递性曲线的峰值与Elo直方图的峰值重合,即难度与非传递性程度之间存在很强的关系。对于基于种群的训练方法,当种群规模增加时,智能体的策略性能会发生相变,因此,保持庞大而多样化的策略种群是必要的。
2.1.2 启发式引导有限深度搜索
极大极小博弈树逐渐发展成为国际象棋程序中主要的组成部分,几乎所有的象棋程序都使用各种形式的极大极小树。极大极小树是迄今为止桌游编程史上最成功、最受欢迎的AI技术之一。DeepBlue主要依托人类知识设计各种各样的局面评价函数(棋子价值、机动性、控制力、阵形等),在极大极小搜索、Alpha-Beta搜索的基础上使用了空着启发式搜索和单步扩展搜索等技术,充分利用多类开局和残局数据库辅助统计分析。
2.1.3 对称博弈自对弈强化学习
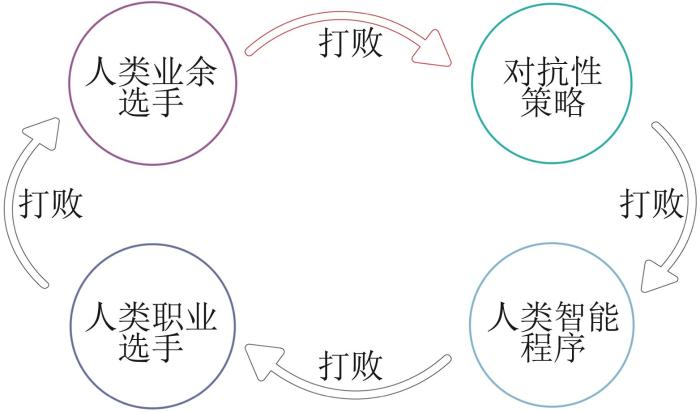
由于对抗双方策略池相同,自对弈强化学习方法为这类对称博弈问题的求解提供了方案。AlphaZero[15]的出现解决了多类完美信息棋类游戏(国际象棋、围棋、将棋)的策略学习问题。2017年DeepMind开发的AlphaZero采用自对弈的方式击败了国际象棋引擎Stockfish。类似的国际象棋引擎还有基于MCTS的Leela Chess Zero。DeepMind的McGrath联合世界冠军利用国际象棋分析了AlphaZero的能力生成过程[16]。虽然当前这类方法已然取得了成功,但一些研究表示对抗性策略依然存在[17],即对抗性策略可以被业余选手打败,但对抗性策略却能打败职业选手,如图2所示。
图2
2.1.4 双模态策略对齐与学习
图3
2.1.5 多源数据决策预训练模型
图4
2.2 强权外交—不完美信息博弈
强权外交(Diplomacy)是一款专门为强调竞争与合作之间的紧张关系而设计的桌游,特别适合研究混合动机环境下的学习。该游戏是在一张欧洲地图上进行的,每个玩家控制多个单位,每个回合所有玩家同时移动所有单位,一个单位可以支持另一个单位(由同一或其他玩家拥有),使其能够克服其他单位的阻力。由于单位之间的相互依赖,玩家必须协调自己单位的移动,并通过协调其他玩家的移动来获得收益。最初的游戏允许玩家在每个回合之前进行廉价谈判(cheap-talk)协商。根据玩家之间是否可以通信,区别为公众媒体(Public Press)、媒体(Press)和无媒体(No Press),其中无通信不允许玩家之间沟通,但可以通过指令传递信号(Signals by order)。
强权外交可建模成多人一般和不完美信息博弈,可以利用多智能体学习方法来求解。7名玩家在地图上争夺更多补给中心(supply centers, SCs);地图包括75块区域(provinces),包含水陆两种,其中有34个SCs;每名玩家初始化3~4个行动单位(unit)和SCs,先占领18个SCs的玩家获胜,否则游戏为平局;行动单位动作集包括移动(move)、帮助(support、convey)和防守(hold);每个行动单位力量设置为1,可行的帮助动作可以使被帮助单位的力量+1;双方发生冲突时,力量大的一方占据优势,被占领的一方可以选择撤退或解散单位,每一个SCs可以供应一个单位;玩家同步控制所有己方单位执行动作,游戏进行N轮或达到结束条件时游戏结束。
2.2.1 多人博弈离线蓝图策略求解
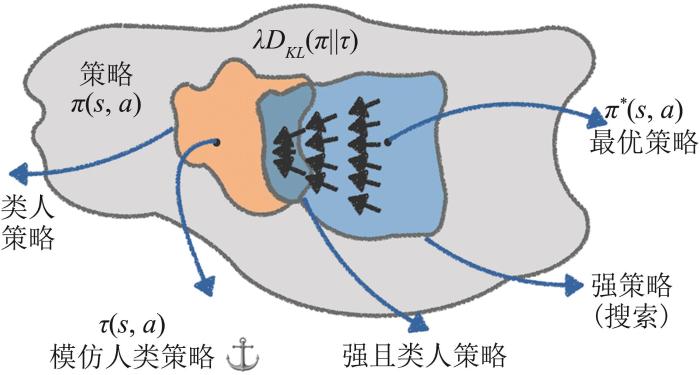
Kraus等[28]提出将“外交”引入多智能体研究,Paquette等[29]采用图神经网络与Transformer等进行了状态编码,利用监督学习与A2C强化学习设计了基线智能体DipNet。Anthony等[30]采用元博弈理论,利用自对弈强化学习设计了随机虚拟对弈的最佳响应策略迭代方法FPPI(fictitious play policy iteration)。Bakhtin等[31]采用深度纳什值迭代与双重Oracle行动发掘设计了面向行动探索的双重Oracle强化学习方法DORA(double oracle reinforcement learning for action exploration),根据学习目标,最终策略可区别为均衡蓝图策略与剥削式策略两类。考虑人类的非理性等因素,Bakhtin等[32]基于正则化策略迭代与贝叶斯博弈理论,设计了基于强化学习的分布式正则化方法RL-DiL-piKL。Meta开发出了超越人类的AI模型Cicero[33],如图5所示,提出了考虑交叉玩家相关的联合策略相关感知正则化强化学习方法(CoShar piKL)。
图5
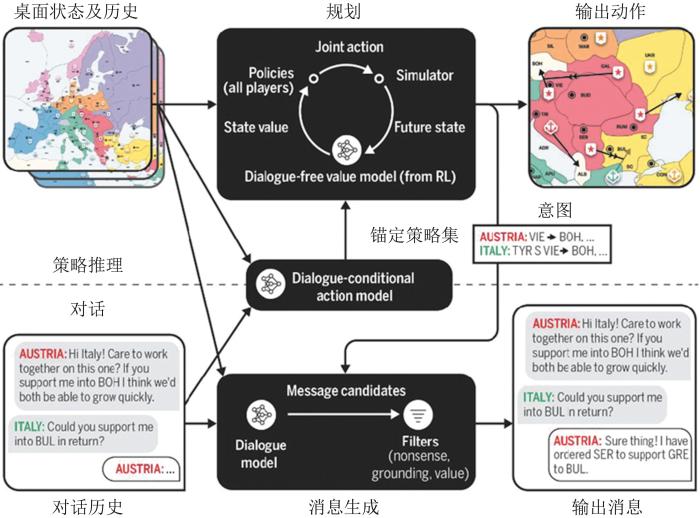
2.2.2 多人博弈在线自适应策略搜索
图6

2.2.3 多人博弈协商策略生成
图7
2.2.4 欺骗检测与社会福利
通信与交流过程中,尔虞我诈的残酷现实使多人博弈的最优策略受各类因素的干扰,信息发送方的真实意图与接受方得到的信息是否等价,网络水军制造的“迷雾”等为多人博弈中的欺骗与谎言相关研究提出了挑战。Peskov等[41]研究了外交的谎言检测问题。Shi等[42]通过自动判别性回复来自省地检测对话中的废话。Hansin等[43]提出基于图的强化学习方法来识别获胜策略,采用两层架构,首先将社会语言学行为编码为语言特征,然后使用强化学习来估计给任何玩家带来的优势。Mukobi等[44]围绕多方合作博弈中的社会福利(Social Welfare),提出围绕帕累托支配解构建具有冲突偏好的谈判问题,设计多类零样本大语言模型智能体。
2.3 星际争霸—马尔可夫博弈
早前的一些多智能体强化学习方法将星际争霸多智能体挑战环境作为基准算法,构建了部分可观、协作多智能体环境。与注重完整星际争霸AI不同,SMAC专注于微观操作,对手为内置的规则AI,目标是希望协作的多智能体能够学会集火、放风筝等策略,在规定的时间内击败所有敌方单位为胜,最大的目标是获取最高胜率。根据地图与兵种的变化,该基准共有14个子环境,难度上分三档。
2.3.1 新的基准环境
由于MAPPO等算法的出现,在此前发布的SMAC环境的各类不同场景中胜率近乎100%。近来,一些基于SMAC的新型基准环境相继被提出。Kim等[48]设计了SMAC+环境,其中,智能体学习执行多阶段任务,没有精确奖励,涵盖了进攻和防守两种情况。在进攻场景中,智能体必须学会首先找到对手,然后消灭他们。防御场景要求智能体使用地形特征。
由于SMAC的随机性不足,难以获得闭环策略,仅以时间步长为条件的开环策略可以在许多SMAC场景中实现非平凡的胜率,Ellis等[49]设计了SMACv2环境,其中,场景是程序生成的,并要求智能体在评估期间泛化到以前未见过的设置(来自相同分布),这些更改确保基准需要使用闭环策略。
由于SMAC的计算代价比较高,并且需要特定游戏知识和使用专有工具来进行任何有意义的更改,Michalski等[50]设计了SMAClite,这个开源框架可以在没有任何专业知识的情况下创建新内容,在运行速度和内存方面优于SMAC。
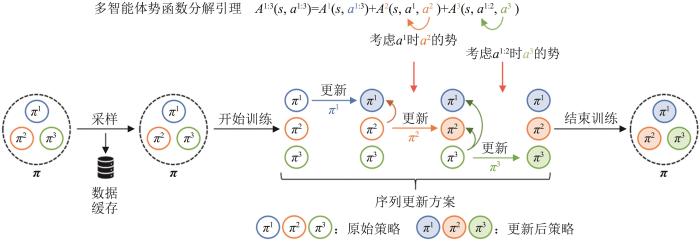
2.3.2 多智能体合作学习
图8
2.3.3 离线预训练模型与在线微调
随着大模型技术的发展,两阶段模型(预训练+微调)学习范式引领了很多领域的发展。通常认为传统在线强化学习方法获得的策略很难适应在线对抗,还可利用离线数据集学习热启动策略。DeepMind发布了利用离线大数据集、基于离线强化学习的可插拔的AI设计方法[55],包括了行为克隆、离线Actor-Critic和Muzero等多类基线AI。
图9

图9
多任务离线预训练与在线微调
Fig. 9
Multi-task offline pre-training and online fine-tuning
3 智能博弈决策策略求解新视角
随着人工智能技术的发展,“数据+算法+算力”模式的成功实践为智能博弈问题的建模与求解提供了全栈支撑。借助孪生战场生成的样本数据、可克服非传递性压制的自对弈策略学习方法、分布式策略推理学习框架,在多类模拟仿真平台上,算法涌现出可被观测的智能[59]。
3.1 开放式博弈问题建模
3.1.1 博弈模型及特点
智能博弈体现了智能化战争下的作战对抗新形态。由于军事对抗充满不确定性战争迷雾、非零和连续对抗、大规模博弈策略空间,可用“开放式不完备信息多方动态博弈”建模,如图10所示。
图10
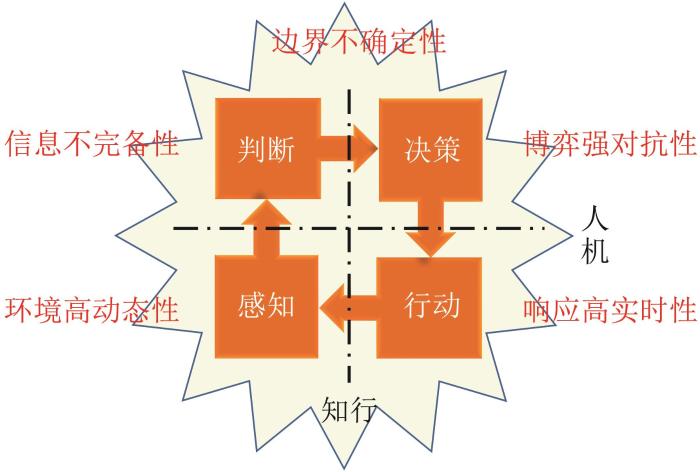
图10
开放式不完备信息多方动态博弈
Fig. 10
Open-ended multi-player dynamic game with incomplete information
开放性主要体现在环境动态演化,即决策主体所处环境可动态演化,不固定,无法预先知晓;决策(行为)无约束,即决策主体处于环境及对手的不断变化,自身决策行动不受约束;结果不固定,即环境、决策主体行为及过程的变化导致结果不固定,即胜战不复。
不完备性主要体现在信息缺失,即决策主体自身感知能力范围及客观环境限制等因素造成对特定信息的不可获取;信息欺骗(虚假),即决策主体自身感知能力误差及其他主体可以隐真示假造成特定信息的错误获取;信息不完全,即不是所有主体都对博弈损益完全了解;信息不完美,即不是所有主体都对已有行动完全把握;信息不对称,即博弈各方主体对于信息的掌握不一致。
3.1.2 多方全域分层对抗
未来战争将呈现多方全域分层博弈对抗过程,其中,博弈方包括国际行为体、国家行为体、非政府组织、雇佣兵团、志愿军等,全域是指军事/政治/经济/外交,陆海空天网电,物理域/信息域/认知域,分层是指战略/战役/战术。
可从时域上对多域联合作战全过程进行阶段划分,依托底层博弈的元博弈模型构建多阶段博弈,探索多方博弈均衡解的存在性、合作与非合作博弈中的利益联盟,建立多方动态博弈模型,有限理性下的博弈策略搜索方法。
3.1.3 序贯决策博弈模型映射
在博弈论领域,不完备信息多方动态博弈由基类博弈组合而成,其中典型基类博弈模型包括:
不完备信息博弈,在博弈开始之前,至少有一方对博弈问题信息结构的某一方面没有完全了解,存在事前的不确定性。
多方合作博弈,多个博弈方有结盟的可能,联盟中的所有成员方通过充分协商,采取联合行动,争取整个联盟所获得收益的总和越大。
对抗团队博弈,多个博弈方组队与另一队对抗,在团队内各方合作,团队之间对抗,各自追求收益最大化。
动态博弈,参与方的行动存在先后顺序,且参与方可以获得有关博弈历史的部分或全部信息。
信号博弈,一类特殊的不完全信息动态博弈,博弈方分为信号发送者和信号接收者两类,信号发送者先行动,发送一个关于自己类型的信号,信号接收者根据所接收的信号选择自己的行动,这里的类型是指参与方的私有信息,其他参与方根据对其私有信息的推断选择自己的行动策略。
3.2 策略求解范式转变
图11
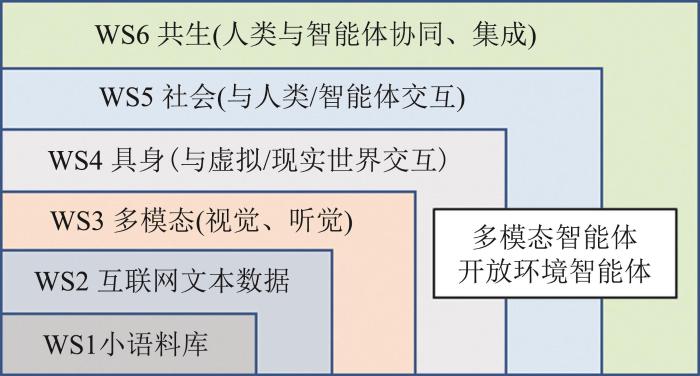
作为人工智能领域的核心概念,智能体的构建方式与问题的求解范式紧密相关,相关研究逐步从强化学习智能体、博弈学习智能体到生成式学习智能体。如何构造面向开放环境任务的多模态智能体是大(语言)模型时代面临的紧迫挑战。当前围绕智能博弈策略求解的范式主要为三大类。
3.2.1 基于决策理论的最优解
通常采用集中式或分散式部分可观马尔可夫决策过程模型来建模,采用动态优化、强化学习、蒙特卡罗搜索等方式求解最优解。面向帕累托最优解的多目标优化问题可表示为
式中:
3.2.2 基于博弈理论的均衡解
通常采用马尔可夫博弈模型来建模多方动态交互过程,采用自对弈、虚拟对弈、协同对弈、种群对弈、课程对弈等博弈强化学习方法求解均衡解。面向纳什均衡解的双线性优化问题可表示为
式中: x 和 y 为策略向量; X 和 Y 为博弈方的策略空间; U 为效用函数。
3.2.3 基于生成式学习的适变解
通常采用Transformer等注意力神经网络进行交互过程的序列建模,或直接依托多模态大模型的规划和推理能力,采用离线预训练、在线微调、提示学习、情景学习、思维链、工具学习等方法求解适变解。基于离线预训练与在线自适应的学习问题可表示为
式中:
3.3 智能博弈决策大模型初探
美国Scale公司推出了Hermes军事规划大语言模型,该模型由美国国防部资助,是一种基于深度学习的大型自然语言处理模型,具有强大的语言理解和生成能力,在面对大规模的军事情报数据和信息时表现出色。其核心技术包括自然语言处理、神经机器翻译、知识图谱构建、信息抽取和深度强化学习等,这些技术的综合应用使该模型能够在实际应用中取得卓越表现。该模型可以准确地将海量的军事情报数据转化为有意义的指令和决策,同时它还可以对复杂的战略场景进行分析和推理,并提供各种军事策略的建议和预测结果,可用于帮助军事规划者和指挥官分析复杂的军事战役场景并辅助决策,在军事指挥、军事决策、战略规划等领域有广泛应用前景。
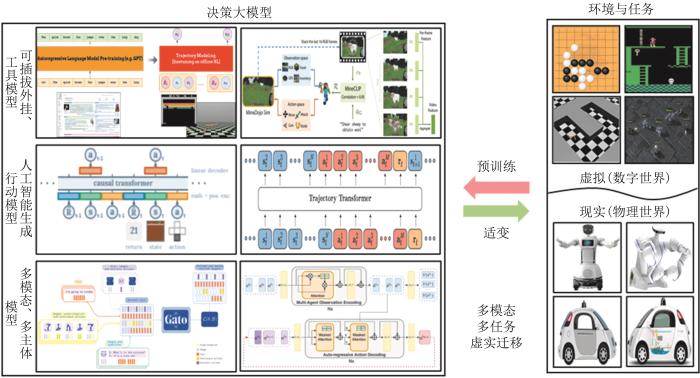
伴随着生成式人工智能技术的发展,美国Scale AI公司推出了Donovan系统[63],用于辅助国防军事决策、生成行动方案。Palantir公司推出了AIP系统,用于分析战场中对方军队的详细情报,给出作战行动计划的相关建议。类比指挥员作战筹划与任务规划过程,智能指控系统可以利用人工智能预训练生成基线预案、利用微调形成精细实案、借助演进式架构获得临机应对方案。如何构建智能博弈决策大模型,利用大模型辅助智能决策是当前智能指控领域的前沿课题。
3.3.1 决策大模型范式探索
图12
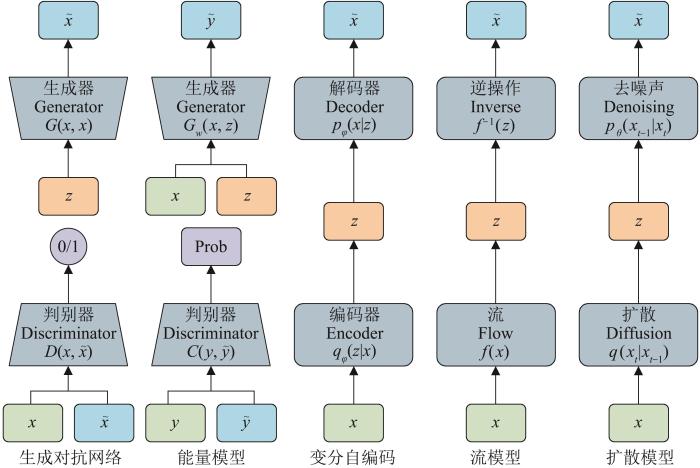
3.3.2 生成式人工智能典型模型
围绕智能决策的生成式模型主要有生成对抗网络模型、能量模型、变分自编码模型、流模型、扩散模型等[65],相关主要模块如图13所示。生成对抗网络模型是一种利用博弈的方式对模型进行训练的生成模型,由生成器和判别器两部分组成,生成器通过无数次迭代训练生成假数据,以尽量欺骗判别器,而判别器则主要负责判断真假数据,并反馈给生成器以供调整;基于能量的模型是一种通过最小化能量函数来生成数据的生成模型;变分自编码(隐变量模型)是一种基于概率图模型的生成模型技术,通过编码样本的特征向量为隐变量,再通过解码生成新数据;流模型利用可逆变换来生成数据,不需要估计极大似然或变分下限等概率分布的性质;扩散模型介于流模型和变分自编码器之间,生成数据时通过随机计算背后的分布,可以处理一些比较复杂的数据;自回归序列建模是一种基于概率的建模技术,这类模型可以处理序列数据。
图13
3.3.3 大模型智能体关键技术
随着ChatGPT来袭,在涌现(Emergence)与顿悟(Grokking)现象的加持下,幂律(Scaling Law)指引着相关机构开发出参数更多的基座模型。如何构建大语言模型智能体(LLM Agents)是生成式人工智能服务化应用的前沿研究领域,这类智能体(AI Agents)将LLM当作“超级大脑”,由“规划、记忆、工具使用”等关键组件构成。此外,当前的一些研究聚焦设计走向通用人工智能(强人工智能)的AI智能体,总体上可分为两大类:生成式智能体(Generative Agents)和自主智能体(Autonomous Agents)。生成式智能体一般通过名称、目标和与其他智能体的关系等信息来描述智能体[66],如MetaGPT[67]等预先定义了软件开发中的各种角色及其相应的职责,手动为每个智能体分配不同的配置文件以促进协作。围绕自主智能体,Liu等[68]提出利用“编排”的方法来构建大语言模型增强的自主智能体。Wang等[69]给出了设计自主智能体的方法,如图14所示,框架的总体结构由一个分析模块、一个记忆模块、一个规划模块和一个动作模块组成。分析模块的目的是确定智能体的角色。记忆和规划模块将智能体置于动态环境中,使其能够利用记忆中的行为并规划未来的行动。动作模块负责将智能体的决策转换为特定的输出。
图14
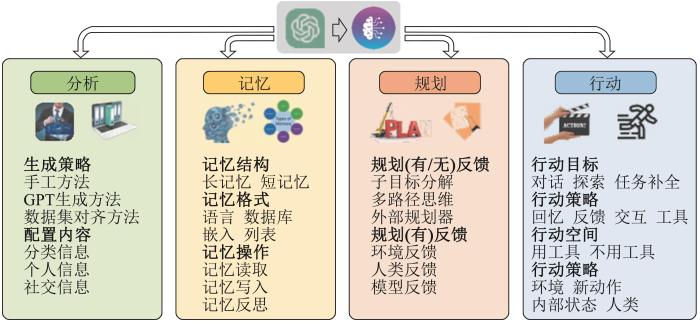
图15
4 结论
本文通过实证分析三个典型计算机博弈的智能体设计方案,为智能博弈决策领域智能体研究提供指引,为智能博弈决策领域的相关研究提供参考借鉴。力图理清多智能体学习领域从“基础”(Fundamental)方法进入“基座”(Foundation)模型研究的路径,为“大模型+大算力+大数据”技术体制下的智能决策新范式相关技术研究提供参考。
智能博弈决策理论的持续推进与方法的范式更新为新时代多模态开放式环境下的多类博弈问题求解提供了新思路、新途径、新方案。未来将聚焦多模态环境下智能博弈决策大模型智能体关键技术的研究。
参考文献
多智能体博弈学习研究进展
[J].
Research Progress of Multi-agent Learning in Games
[J].
智能决策问题探讨——从游戏博弈到作战指挥, 距离还有多远
[J].
On Problems of Intelligent Decision-making-how Far is It from Game-playing to Operational Command
[J].
Taking Back the Seas: Transforming the U.S. Surface Fleet for Decision-centric Warfare
[EB/OL]. (
Final Report of the Defense Science Board (DSB) Task Force on Gaming, Exercising, Modeling, and Simulation
[EB/OL]. [
Joint All-domain Command and Control (JADC2) Opportunities on the Horizon
[EB/OL]. [
Artificial Intelligence in Wargaming: An Evidence-based Assessment of AI Applications
[EB/OL]. [
Game Theory and Prescriptive Analytics for Naval Wargaming Battle Management Aids
[EB/OL]. [
基于影响网络与序贯博弈的作战行动序列模型与求解
[J].
Modeling and Solution of Course of Action Based on Influence Net and Sequential Game
[J].
Programming a Computer for Playing Chess
[C]//
Is Chess the Drosophila of Artificial Intelligence? A Social History of an Algorithm
[J].
Deep Blue
[J].
Real World Games Look Like Spinning Tops
[C]//
Measuring the Non-transitivity in Chess
[J].
A General Reinforcement Learning Algorithm That Masters Chess, Shogi, and Go Through Self-play
[J].
Acquisition of Chess Knowledge in AlphaZero
[J].
Adversarial Policies Beat Professional-level Go AIs
[EB/OL]. (
Representation Matters: The Game of Chess Poses a Challenge to Vision Transformers
[EB/OL]. (
Watching a Language Model Learning Chess
[C]//
Chess as a Testbed for Language Model State Tracking
[C]//
The Chess Transformer: Mastering Play Using Generative Language Models
[EB/OL]. (
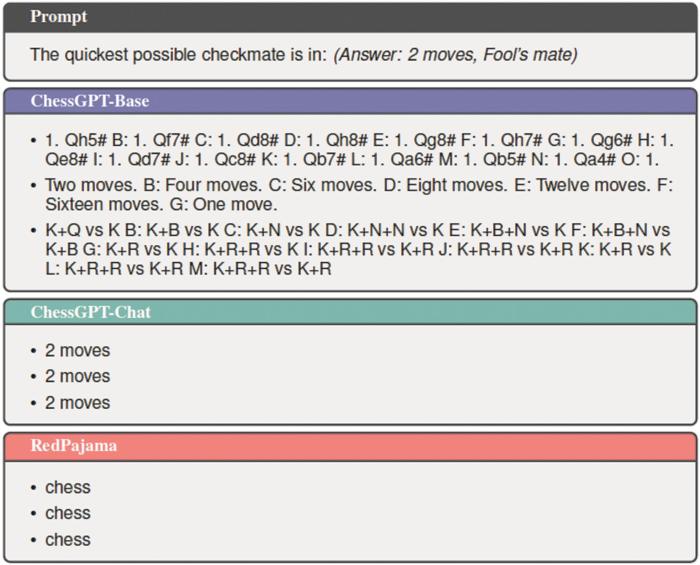
ChessGPT: Bridging Policy Learning and Language Modeling
[EB/OL]. [
Tactical Coordination in No-press Diplomacy
[C]//
A Comparison of Diplomacy Gameboard Graph Search Algorithms
[C]//
Nested Look-ahead Evolutionary Algorithm Based Planning for a Believable Diplomacy Bot
[C]//
D-brane: A Diplomacy Playing Agent for Automated Negotiations Research
[J].
A Generic Agent Architecture for Cooperative Multi-agent Games
[D].
Diplomat, an Agent in a Multi Agent Environment: An Overview
[C]//
No Press Diplomacy: Modeling Multi-agent Gameplay
[C]//
Learning to Play No-press Diplomacy with Best Response Policy Iteration
[C]//
No-press Diplomacy from Scratch
[C]//
Mastering the Game of No-press Diplomacy via Human-regularized Reinforcement Learning and Planning
[EB/OL]. (
Human-level Play in the Game of Diplomacy by Combining Language Models with Strategic Reasoning
[J].
Sample-based Approximation of Nash in Large Many-player Games via Gradient Descent
[C]//
A Unified Approach to Reinforcement Learning, Quantal Response Equilibria, and Two-player Zero-sum Games
[EB/OL]. (
Equilibrium Finding in Normal-form Games via Greedy Regret Minimization
[C]//
Human-level Performance in No-press Diplomacy via Equilibrium Search
[EB/OL]. (
Modeling Strong and Human-like Gameplay with KL-regularized Search
[C]//
Cooperative AI: Machines Must Learn to Find Common Ground
[J].
Negotiation and Honesty in Artificial Intelligence Methods for the Board Game of Diplomacy
[J].
It Takes Two to Lie: One to Lie, and One to Listen
[C]//
AutoReply: Detecting Nonsense in Dialogue Introspectively with Discriminative Replies
[EB/OL]. (
Using Graph-aware Reinforcement Learning to Identify Winning Strategies in Diplomacy Games (Student Abstract)
[C]//
Welfare Diplomacy: Benchmarking Language Model Cooperation
[EB/OL]. (
The StarCraft Multi-agent Challenge
[C]//
Grandmaster Level in StarCraft II Using Multi-agent Reinforcement Learning
[J].
SCC: An Efficient Deep Reinforcement Learning Agent Mastering the Game of StarCraft II
[C]//
The StarCraft Multi-agent Challenges+ : Learning of Multi-stage Tasks and Environmental Factors Without Precise Reward Functions
[EB/OL]. (
SMACv2: An Improved Benchmark for Cooperative Multi-agent Reinforcement Learning
[EB/OL]. (
SMAClite: A Lightweight Environment for Multi-agent Reinforcement Learning
[EB/OL]. (
Inducing Stackelberg Equilibrium Through Spatio-temporal Sequential Decision-making in Multi-Agent Reinforcement Learning
[EB/OL]. (
Asynchronous Multi-agent Reinforcement Learning for Efficient Real-time Multi-robot Cooperative Exploration
[EB/OL]. (
Sequential Cooperative Multi-agent Reinforcement Learning
[C]//
Heterogeneous-agent Reinforcement Learning
[EB/OL]. [
StarCraft II Unplugged: Large Scale Offline Reinforcement Learning
[C]//
Offline Pre-trained Multi-agent Decision Transformer: One Big Sequence Model Tackles all SMACtasks
[EB/OL]. (
Offline Pre-trained Multi-agent Decision Transformer
[J].
Modularization for Multi-task and Multi-agent Offline Pre-training
[C]//
Emergent Abilities of Large Language Models
[EB/OL]. (
Experience Grounds Language
[EB/OL]. (
Enhancing Human Capabilities Through Symbiotic Artificial Intelligence with Shared Sensory Experiences
[EB/OL]. (
Donovan-AI Powered Decision Making for Defense
[EB/OL]. (
Foundation Models for Decision Making: Problems, Methods, and Opportunities
[EB/OL]. (
Unleashing the Power of Edge-cloud Generative AI in Mobile Networks: A Survey of AIGC Services
[EB/OL]. (
Building Cooperative Embodied Agents Modularly with Large Language Models
[EB/OL]. (
MetaGPT: Meta Programming for A Multi-agent Collaborative Framework
[EB/OL]. (
BOLAA: Benchmarking and Orchestrating LLM-augmented Autonomous Agents
[EB/OL]. (
A Survey on Large Language Model Based Autonomous Agents
[EB/OL]. (
Tool Learning with Foundation Models
[EB/OL]. (
Auto-GPT for Online Decision Making: Benchmarks and Additional Opinions
[EB/OL]. (
Multimodal Foundation Models: From Specialists to General-purpose Assistants
[EB/OL]. (


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}