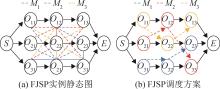
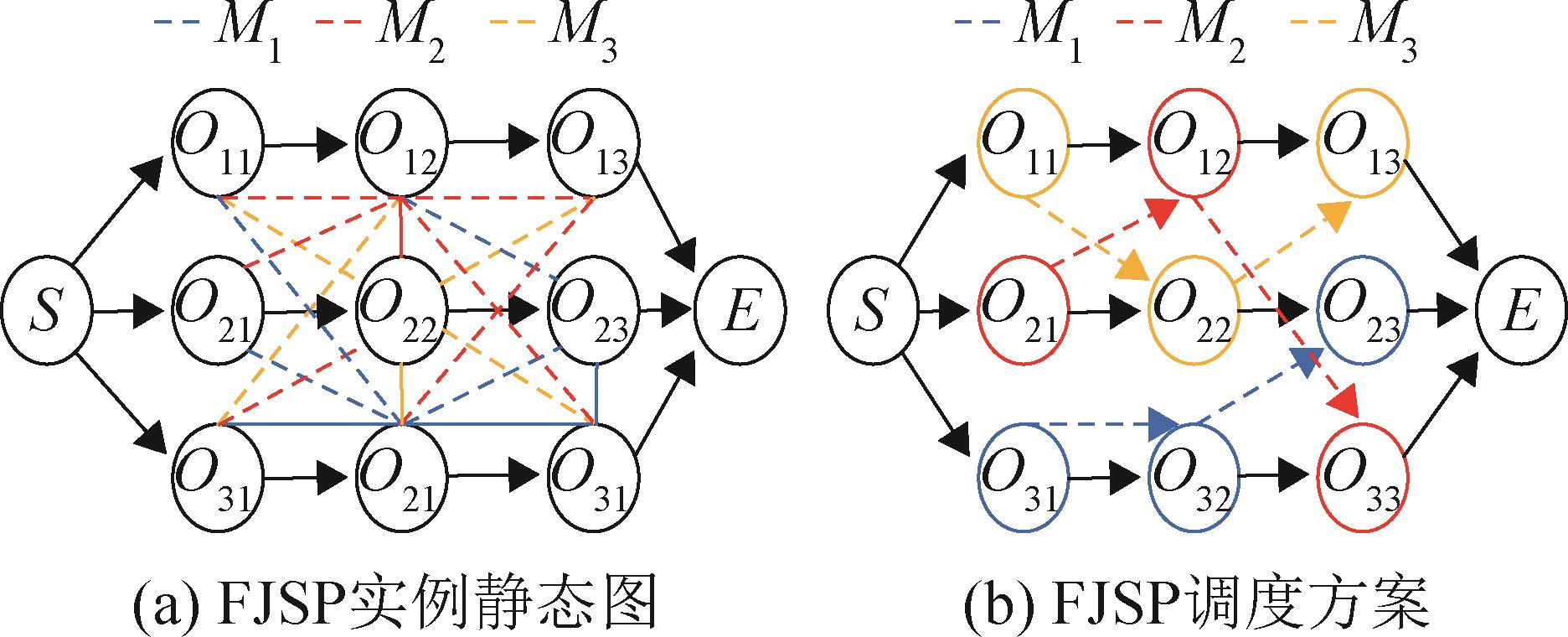
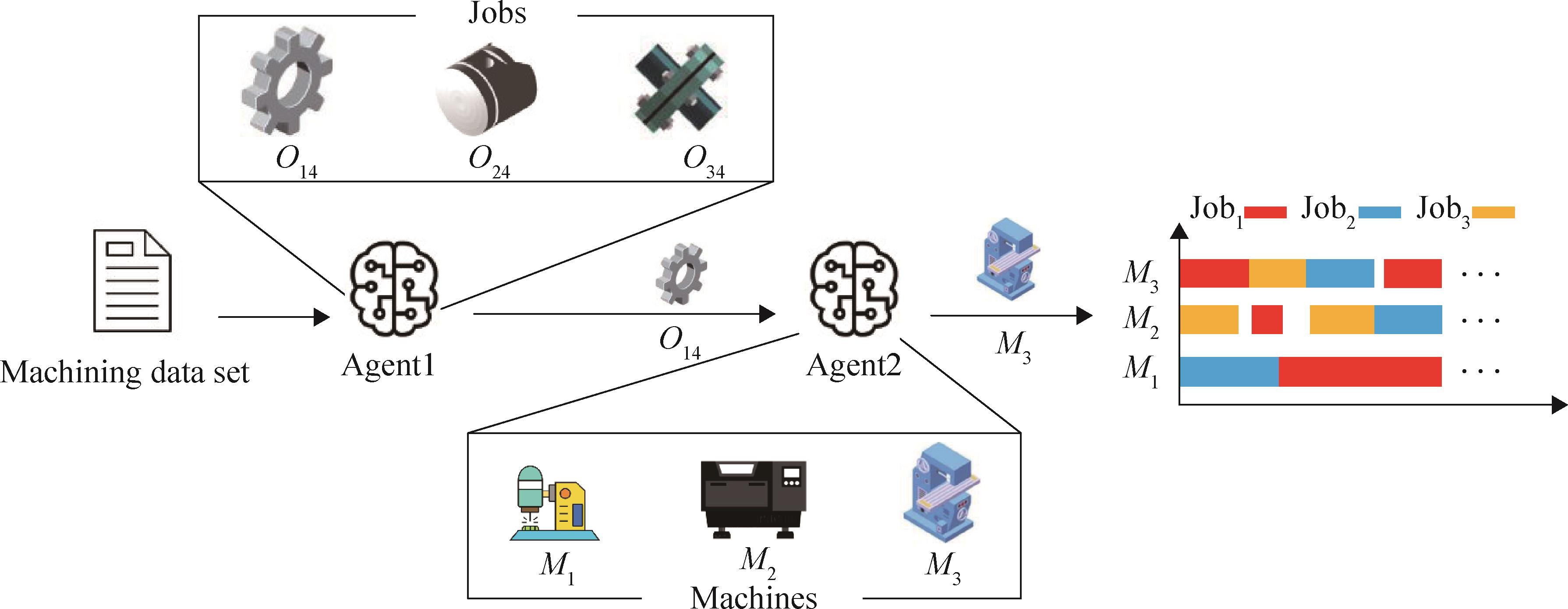
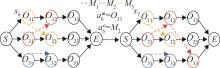
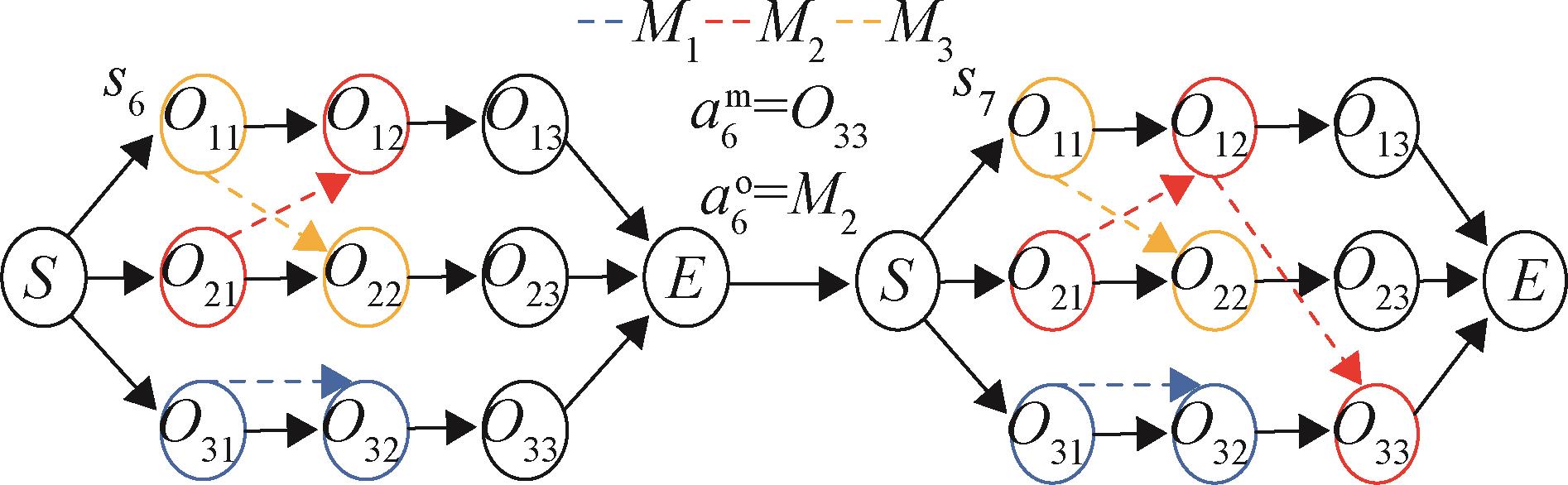
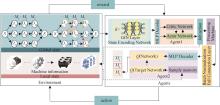
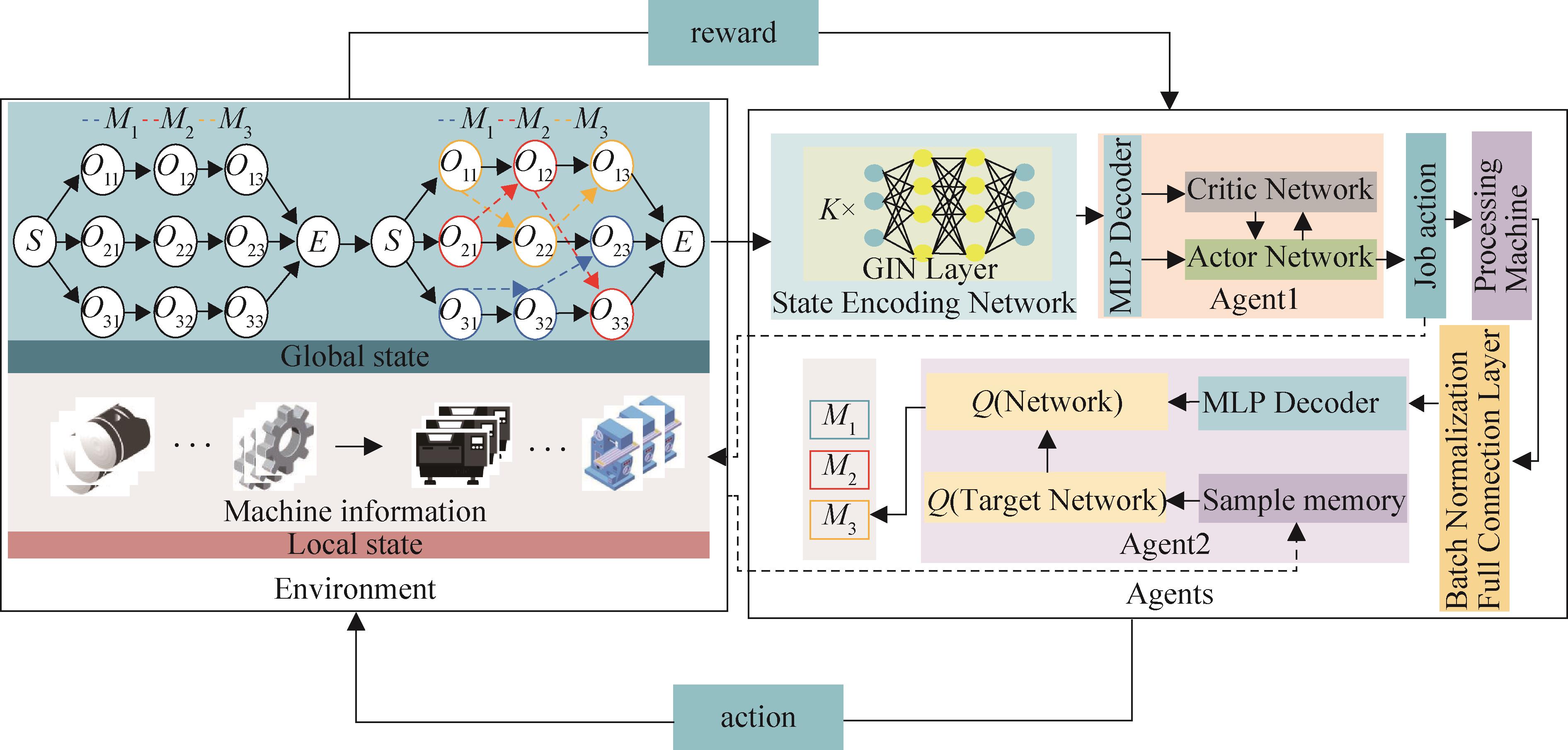
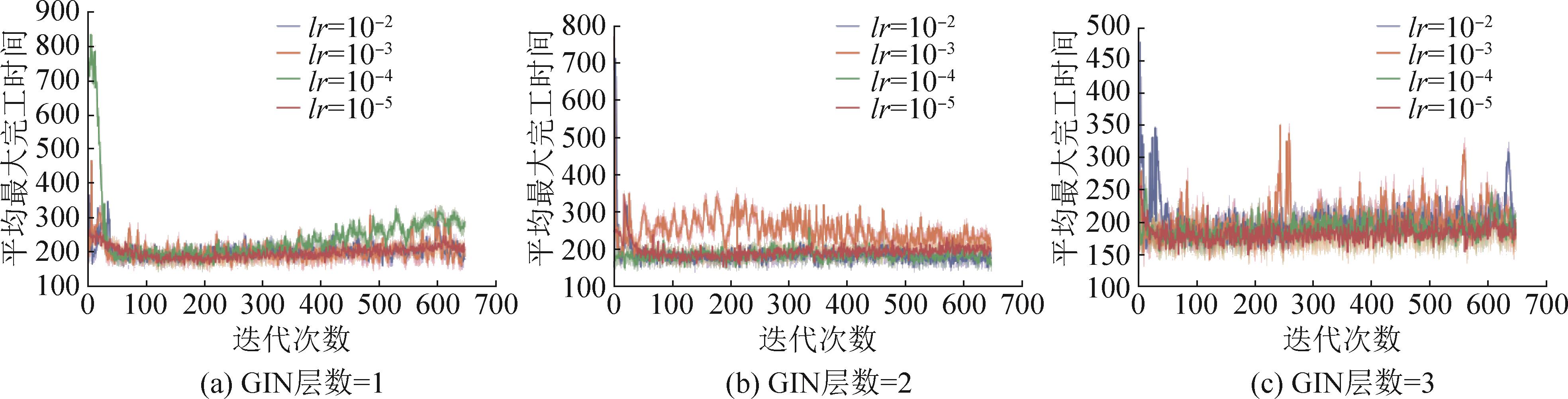
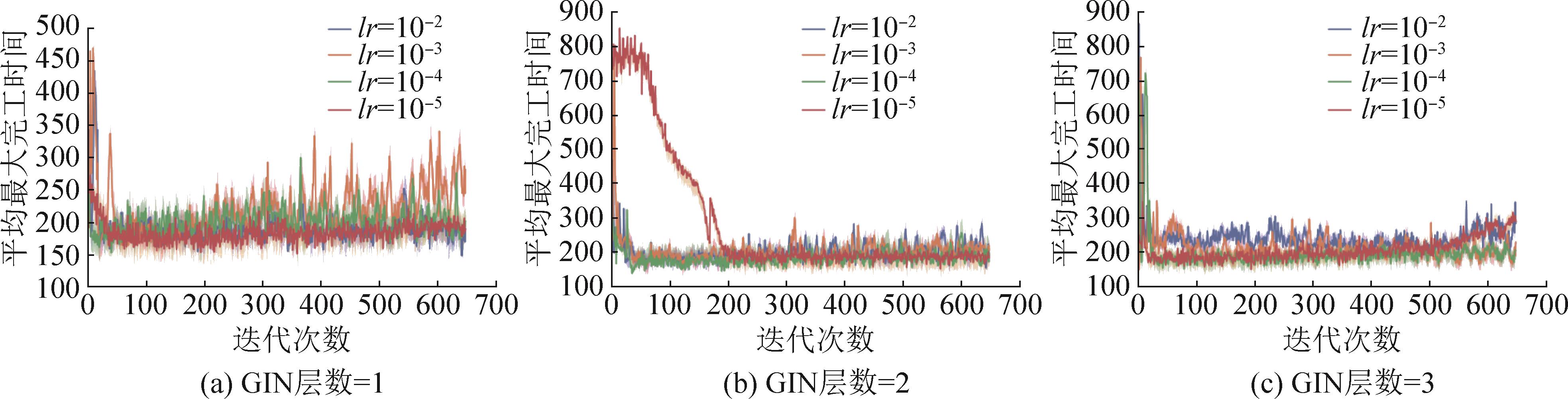
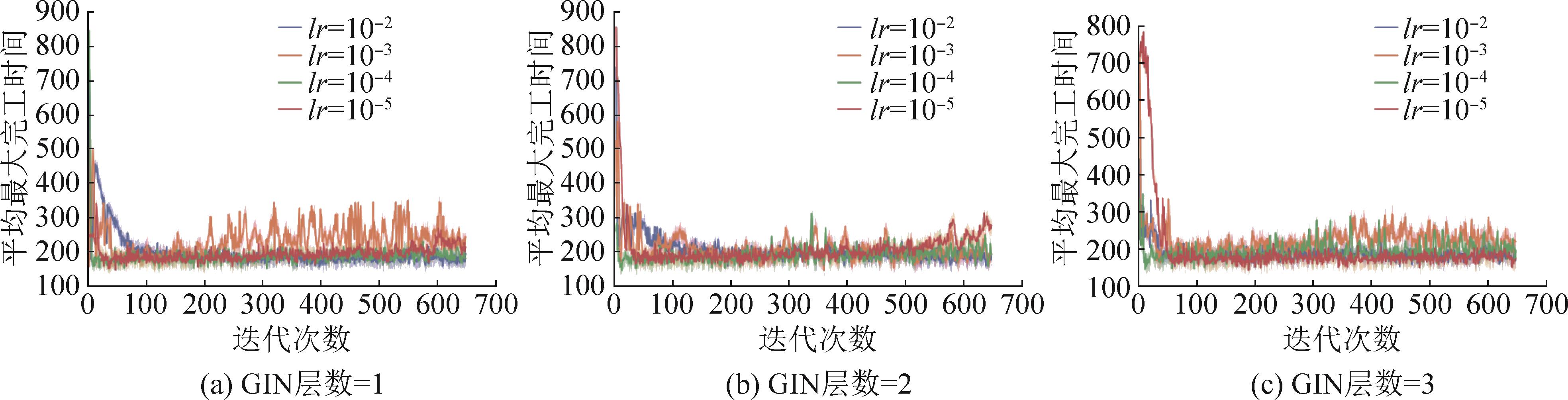
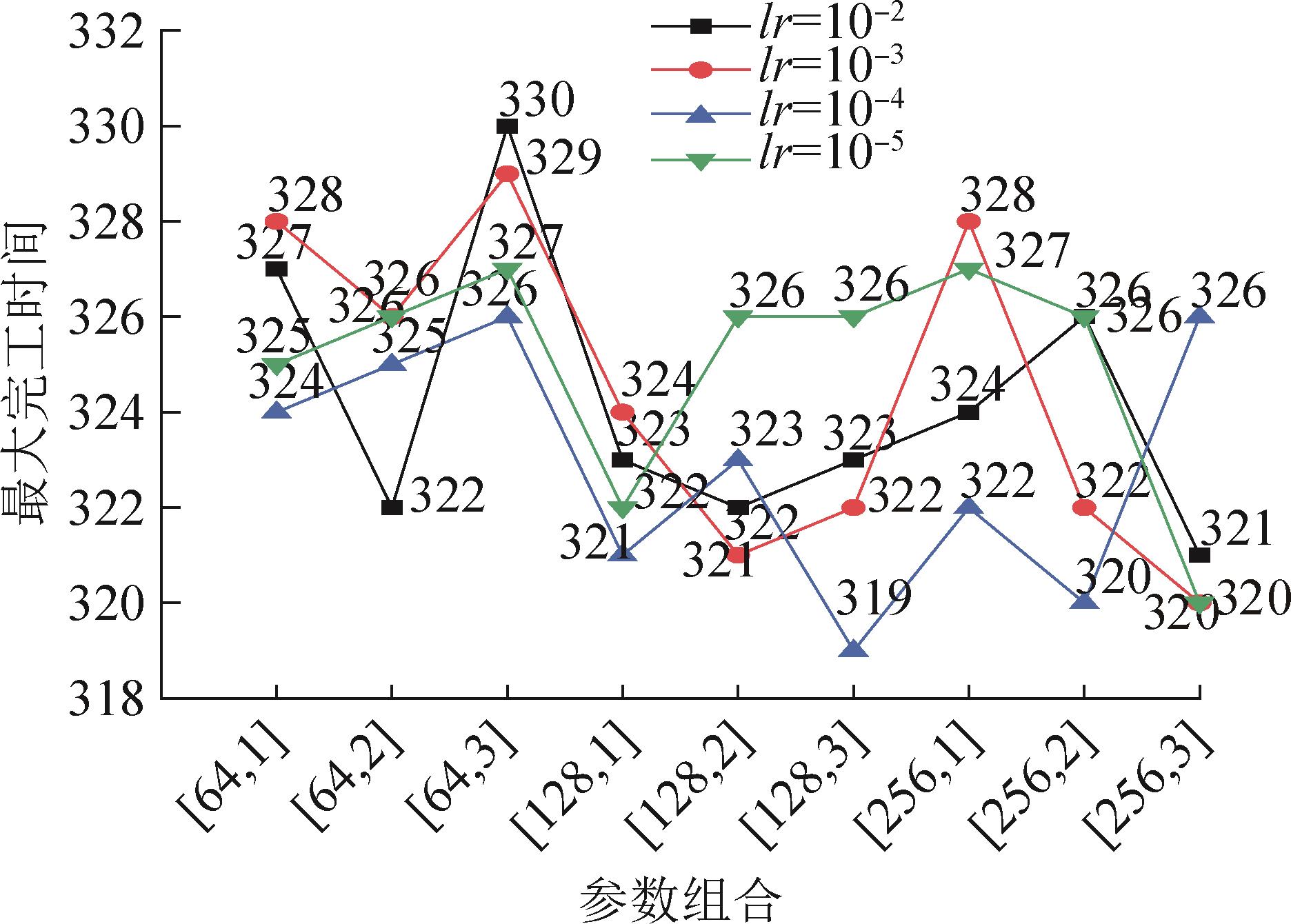
| 1 |
Brucker P, Schlie R. Job-shop Scheduling with Multi-purpose Machines[J]. Computing, 1990, 45(4): 369-375.
|
| 2 |
Li Junqing, Pan Quanke, Liang Y C. An Effective Hybrid Tabu Search Algorithm for Multi-objective Flexible Job-shop Scheduling Problems[J]. Computers & Industrial Engineering, 2010, 59(4): 647-662.
|
| 3 |
蔡敏, 王艳, 纪志成. 基于多策略融合量子粒子群算法的MOFFJSP研究[J]. 系统仿真学报, 2021, 33(11): 2615-2626.
|
|
Cai Min, Wang Yan, Ji Zhicheng. Research on MOFFJSP Based on Multi-strategy Fusion Quantum Particle Swarm Optimization[J]. Journal of System Simulation, 2021, 33(11): 2615-2626.
|
| 4 |
张朝阳, 徐莉萍, 李健, 等. 基于改进狼群算法的柔性作业车间调度研究[J]. 系统仿真学报, 2023, 35(3): 534-543.
|
|
Zhang Chaoyang, Xu Liping, Li Jian, et al. Flexible Job-shop Scheduling Problem Based on Improved Wolf Pack Algorithm[J]. Journal of System Simulation, 2023, 35(3): 534-543.
|
| 5 |
Riedmiller Simone, Riedmiller Martin. A Neural Reinforcement Learning Approach to Learn Local Dispatching Policies in Production Scheduling[C]//Proceedings of the 16th International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann Publishers Inc., 1999: 764-769.
|
| 6 |
Gui Yong, Tang Dunbing, Zhu Haihua, et al. Dynamic Scheduling for Flexible Job Shop Using a Deep Reinforcement Learning Approach[J]. Computers & Industrial Engineering, 2023, 180: 109255.
|
| 7 |
Luo Shu. Dynamic Scheduling for Flexible Job Shop with New Job Insertions by Deep Reinforcement Learning[J]. Applied Soft Computing, 2020, 91: 106208.
|
| 8 |
Lei Kun, Guo Peng, Zhao Wenchao, et al. A Multi-action Deep Reinforcement Learning Framework for Flexible Job-shop Scheduling Problem[J]. Expert Systems with Applications, 2022, 205: 117796.
|
| 9 |
Liu Renke, Piplani Rajesh, Toro Carlos. Deep Reinforcement Learning for Dynamic Scheduling of a Flexible Job Shop[J]. International Journal of Production Research, 2022, 60(13): 4049-4069.
|
| 10 |
Jing Xuan, Yao Xifan, Liu Min, et al. Multi-agent Reinforcement Learning Based on Graph Convolutional Network for Flexible Job Shop Scheduling[J]. Journal of Intelligent Manufacturing, 2024, 35(1): 75-93.
|
| 11 |
Du Yu, Li Junqing, Li Chengdong, et al. A Reinforcement Learning Approach for Flexible Job Shop Scheduling Problem with Crane Transportation and Setup Times[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(4): 5695-5709.
|
| 12 |
Song Wen, Chen Xinyang, Li Qiangng, et al. Flexible Job-shop Scheduling via Graph Neural Network and Deep Reinforcement Learning[J]. IEEE Transactions on Industrial Informatics, 2023, 19(2): 1600-1610.
|
| 13 |
Nazari M, Oroojlooy A, Takáč Martin, et al. Reinforcement Learning for Solving the Vehicle Routing Problem[C]//Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 9861-9871.
|
| 14 |
Brandimarte Paolo. Routing and Scheduling in a Flexible Job Shop by tabu Search[J]. Annals of Operations Research, 1993, 41(3): 157-183.
|
| 15 |
Jiang Tianhua, Zhang Chao. Application of Grey Wolf Optimization for Solving Combinatorial Problems: Job Shop and Flexible Job Shop Scheduling Cases[J]. IEEE Access, 2018, 6: 26231-26240.
|
| 16 |
Wang Yuhui, He Hao, Tan Xiaoyang. Truly Proximal Policy Optimization[C]//Truly Proximal Policy Optimization. Chia Laguna Resort: PMLR, 2020: 113-122.
|
| 17 |
Schulman J, Moritz P, Levine S, et al. High-dimensional Continuous Control Using Generalized Advantage Estimation[EB/OL]. (2010-10-20) [2023-05-16]. .
|
| 18 |
Xu Keyulu, Hu Weihua, Leskovec J, et al. How Powerful are Graph Neural Networks?[EB/OL]. (2019-02-22) [2023-05-31]. .
|
| 19 |
Han B A, Yang J J. A Deep Reinforcement Learning Based Solution for Flexible Job Shop Scheduling Problem[J]. International Journal of Simulation Modelling, 2021, 20(2): 375-386.
|
| 20 |
张凯, 毕利, 焦小刚. 集成强化学习算法的柔性作业车间调度问题研究[J]. 中国机械工程, 2023, 34(2): 201-207.
|
|
Zhang Kai, Bi Li, Jiao Xiaogang. Research on Flexible Job-shop Scheduling Problems with Integrated Reinforcement Learning Algorithm[J]. China Mechanical Engineering, 2023, 34(2): 201-207.
|
| 21 |
吴昊泽, 李艳武, 谢辉. 改进PPO算法求解柔性作业车间调度问题[J/OL]. 计算机集成制造系统. (2023-06-02) [2023-06-28]. .
|
|
Wu Haoze, Li Yanwu, Xie Hui. Improved Proximal Policy Optimization Algorithm for Solving Flexible Job Shop Scheduling Problem[J/OL]. Computer Integrated Manufacturing Systems. (2023-06-02) [2023-06-28]. .
|