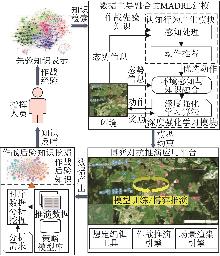
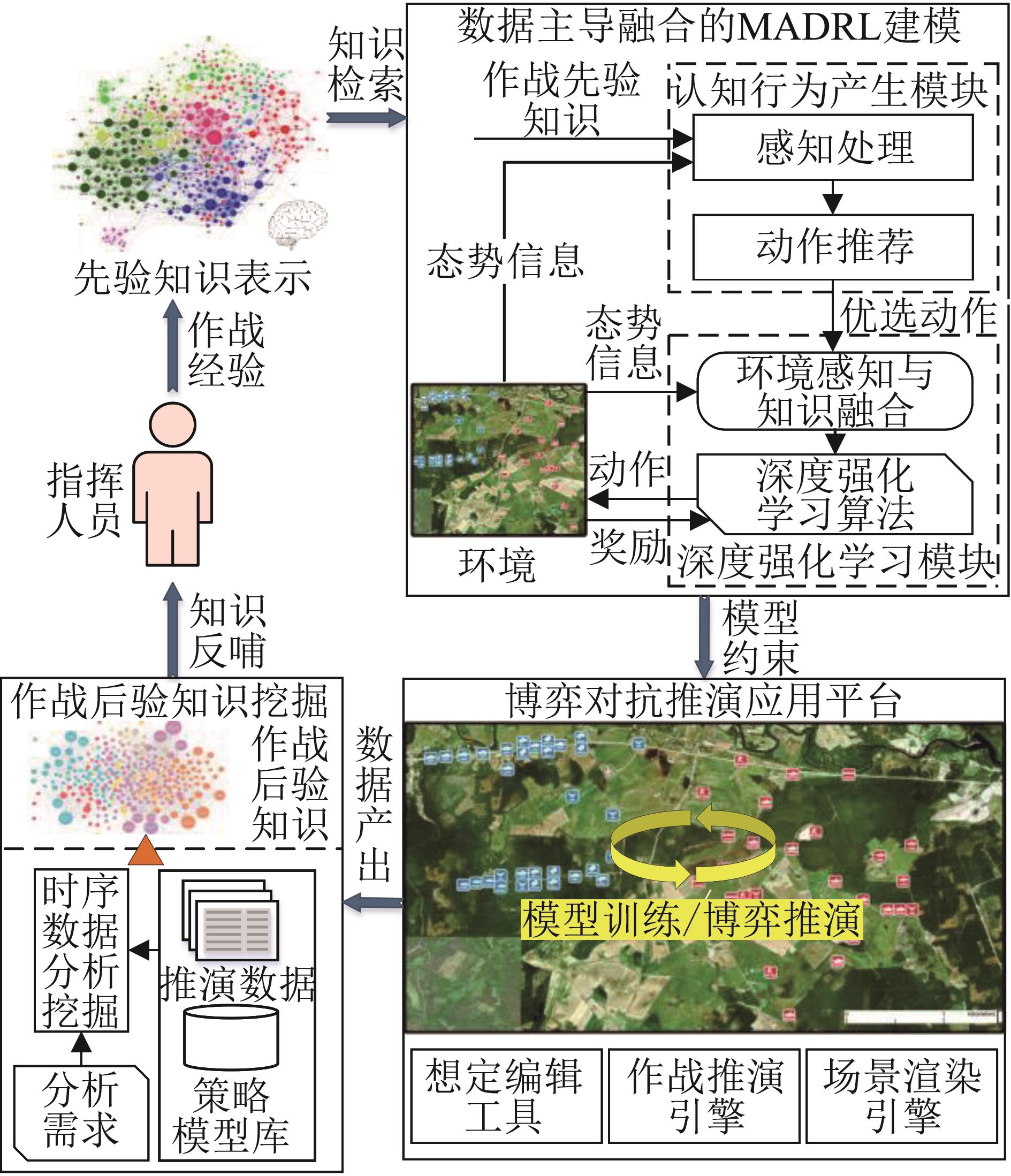
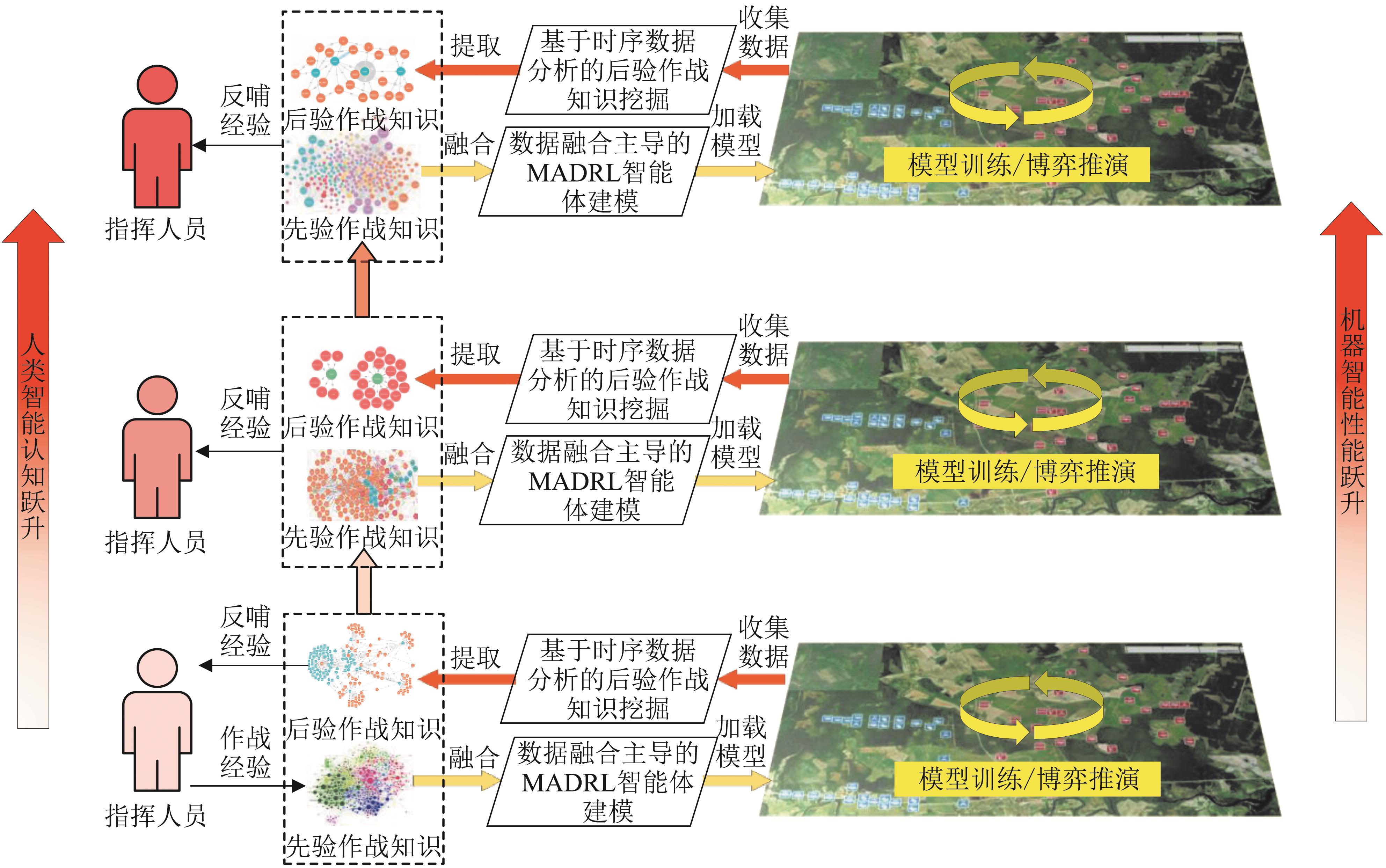
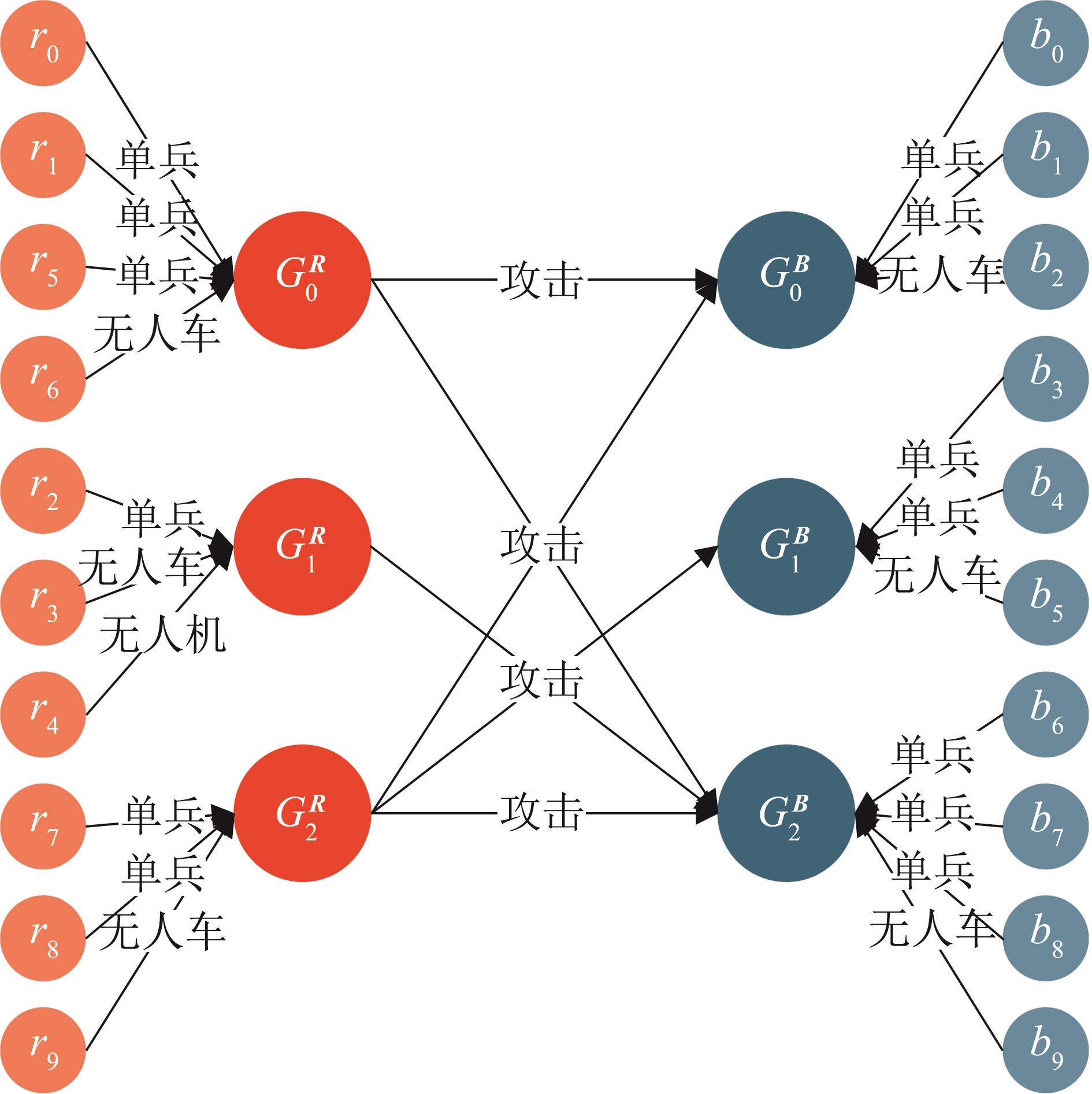
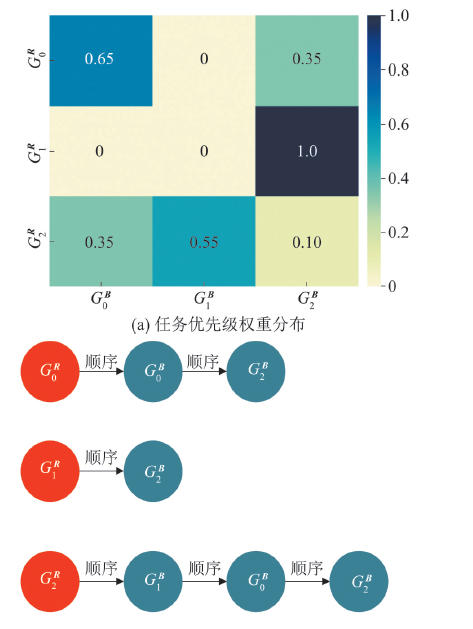
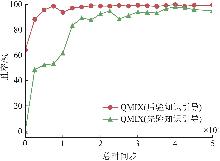
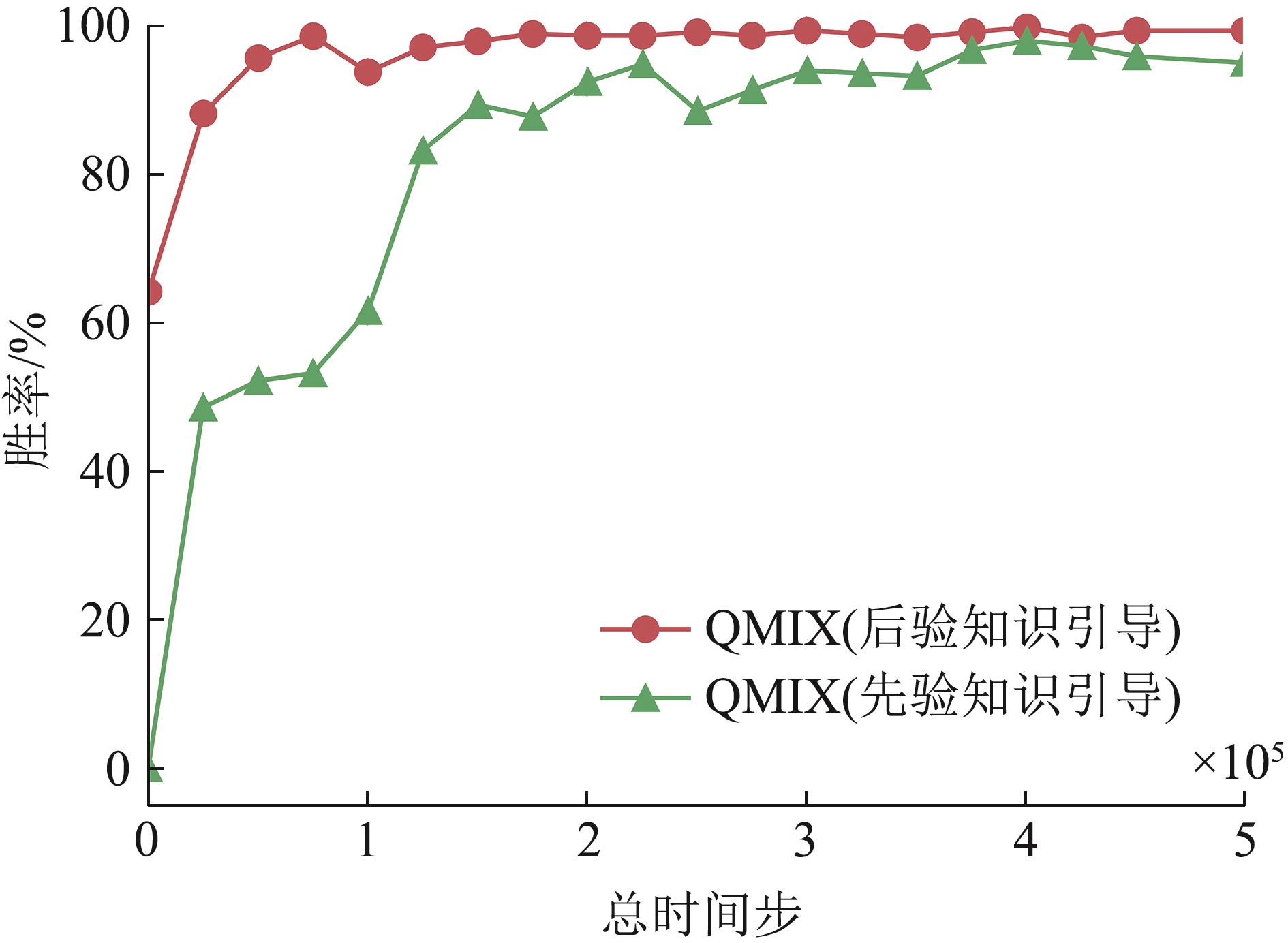
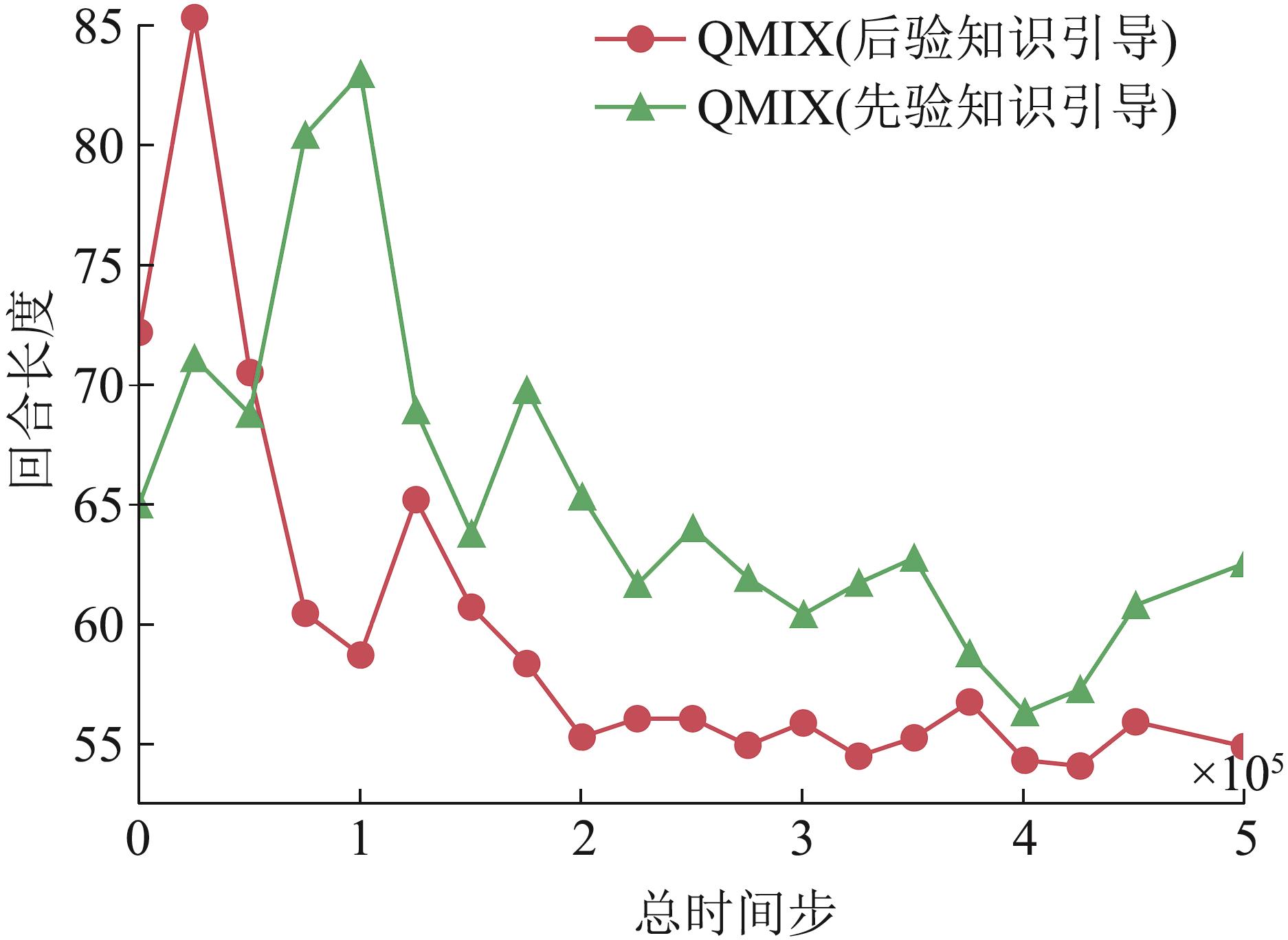
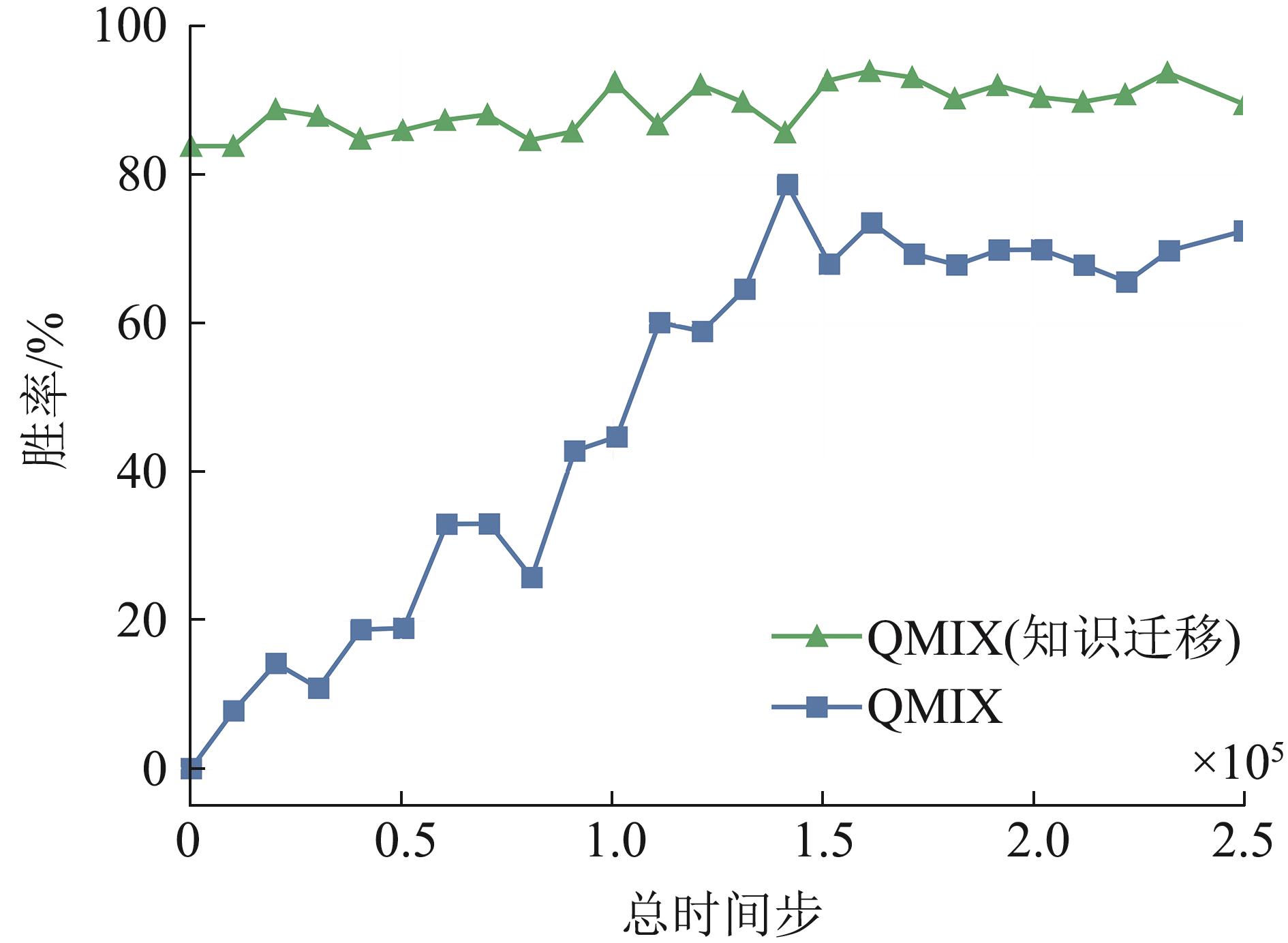
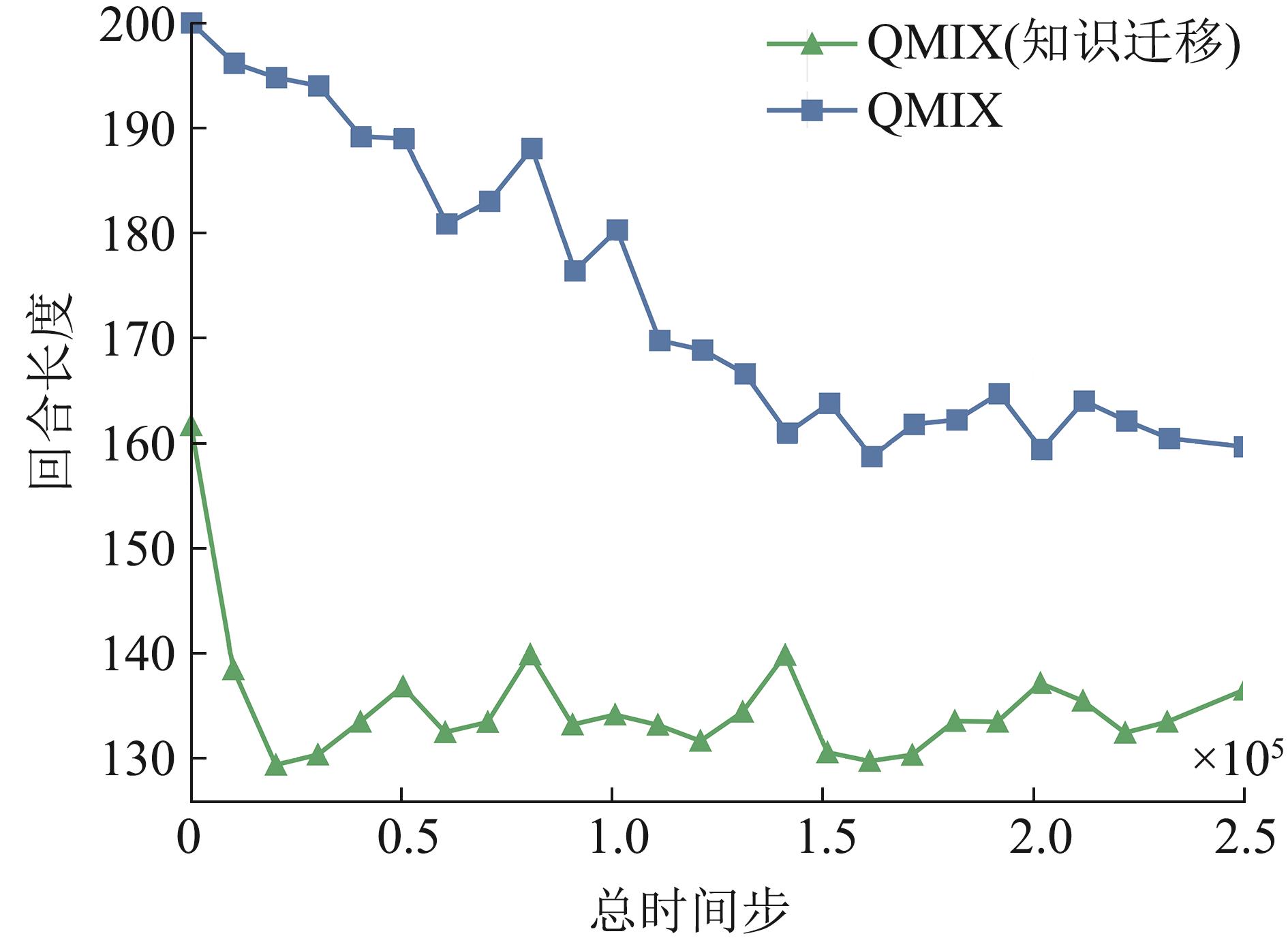
| [1] |
胡晓峰. 复杂性也可以成为一种武器[J]. 军事文摘, 2024(1): 1.
|
| [2] |
李艺春, 刘泽娇, 洪艺天, 等. 基于多智能体强化学习的博弈综述[J]. 自动化学报, 2025, 51(3): 540-558.
|
|
Li Yichun, Liu Zejiao, Hong Yitian, et al. Multi-agent Reinforcement Learning Based Game: A Survey[J]. Acta Automatica Sinica, 2025, 51(3): 540-558.
|
| [3] |
胡晓峰, 齐大伟. 智能化兵棋系统: 下一代需要改变的是什么[J]. 系统仿真学报, 2021, 33(9): 1997-2009.
|
|
Hu Xiaofeng, Qi Dawei. Intelligent Wargaming System: Change Needed by Next Generation Need to be Changed[J]. Journal of System Simulation, 2021, 33(9): 1997-2009.
|
| [4] |
胡晓峰. 兵棋推演的"魂"是什么[J]. 军事文摘, 2024(7): 1.
|
| [5] |
孙宇祥, 彭益辉, 李斌, 等. 智能博弈综述: 游戏AI对作战推演的启示[J]. 智能科学与技术学报, 2022, 4(2): 157-173.
|
|
Sun Yuxiang, Peng Yihui, Li Bin, et al. Overview of Intelligent Game: Enlightenment of Game AI to Combat Deduction[J]. Chinese Journal of Intelligent Science and Technology, 2022, 4(2): 157-173.
|
| [6] |
罗俊仁, 张万鹏, 项凤涛, 等. 智能推演综述:博弈论视角下的战术战役兵棋与战略博弈[J]. 系统仿真学报, 2023, 35(9): 1871-1894.
|
|
Luo Junren, Zhang Wanpeng, Xiang Fengtao, et al. Survey on Intelligent Wargaming: Tactical & Campaign Wargame and Strategic Game from Game-theoretic Perspective[J]. Journal of System Simulation, 2023, 35(9): 1871-1894.
|
| [7] |
施伟, 冯旸赫, 程光权, 等. 基于深度强化学习的多机协同空战方法研究[J]. 自动化学报, 2021, 47(7): 1610-1623.
|
|
Shi Wei, Feng Yanghe, Cheng Guangquan, et al. Research on Multi-aircraft Cooperative Air Combat Method Based on Deep Reinforcement Learning[J]. Acta Automatica Sinica, 2021, 47(7): 1610-1623.
|
| [8] |
陈浩, 李嘉祥, 黄健, 等. 融合认知行为模型的深度强化学习框架及算法[J]. 控制与决策, 2023, 38(11): 3209-3218.
|
|
Chen Hao, Li Jiaxiang, Huang Jian, et al. Deep Reinforcement Learning Framework and Algorithms Integrated with Cognitive Behavior Models[J]. Control and Decision, 2023, 38(11): 3209-3218.
|
| [9] |
韩润海, 陈浩, 刘权, 等. 基于对手动作预测的智能博弈对抗算法[J]. 计算机工程与应用, 2023, 59(7): 190-197.
|
|
Han Runhai, Chen Hao, Liu Quan, et al. Intelligent Game Countermeasures Algorithm Based on Opponent Action Prediction[J]. Computer Engineering and Applications, 2023, 59(7): 190-197.
|
| [10] |
Zhou Zhiming, Qi Hongmin, Liu Zhen, et al. Research on Autonomous Decision-making of multi-UAV Air Combat Based on Deep Reinforcement Learning[C]//Proceedings of 2023 7th Chinese Conference on Swarm Intelligence and Cooperative Control. Singapore: Springer Nature Singapore, 2024: 687-700.
|
| [11] |
张斌, 雷永林, 李群, 等. 基于强化学习的导弹突防决策建模研究[J]. 系统仿真学报, 2025, 37(3): 763-774.
|
|
Zhang Bin, Lei Yonglin, Li Qun, et al. Reinforcement Learning Modeling of Missile Penetration Decision Based on Combat Simulation[J]. Journal of System Simulation, 2025, 37(3): 763-774.
|
| [12] |
胡晓峰, 荣明. 作战决策辅助向何处去-"深绿"计划的启示与思考[J]. 指挥与控制学报, 2016, 2(1): 22-25.
|
|
Hu Xiaofeng, Rong Ming. Where Do Operation Decision Support Systems Go: Inspiration and Thought on Deep Green Plan[J]. Journal of Command and Control, 2016, 2(1): 22-25.
|
| [13] |
胡晓峰, 贺筱媛, 陶九阳. AlphaGo的突破与兵棋推演的挑战[J]. 科技导报, 2017, 35(21): 49-60.
|
|
Hu Xiaofeng, He Xiaoyuan, Tao Jiuyang. AlphaGo's Breakthrough and Challenges of Wargaming[J]. Science & Technology Review, 2017, 35(21): 49-60.
|
| [14] |
胡晓峰, 荣明. 智能化作战研究值得关注的几个问题[J]. 指挥与控制学报, 2018, 4(3): 195-200.
|
|
Hu Xiaofeng, Rong Ming. Several Important Questions of Intelligent Warfare Research[J]. Journal of Command and Control, 2018, 4(3): 195-200.
|
| [15] |
胡晓峰, 齐大伟. 智能决策问题探讨—从游戏博弈到作战指挥, 距离还有多远[J]. 指挥与控制学报, 2020, 6(4): 356-363.
|
|
Hu Xiaofeng, Qi Dawei. On Problems of Intelligent Decision-making—How Far is It from Game-playing to Operational Command[J]. Journal of Command and Control, 2020, 6(4): 356-363.
|
| [16] |
贺筱媛, 郭圣明, 吴琳, 等. 面向智能化兵棋的认知行为建模方法研究[J]. 系统仿真学报, 2021, 33(9): 2037-2047.
|
|
He Xiaoyuan, Guo Shengming, Wu Lin, et al. Modeling Research of Cognition Behavior for Intelligent Wargaming[J]. Journal of System Simulation, 2021, 33(9): 2037-2047.
|
| [17] |
吴琳, 胡晓峰, 陶九阳, 等. 面向智能成长的兵棋推演生态系统[J]. 系统仿真学报, 2021, 33(9): 2048-2058.
|
|
Wu Lin, Hu Xiaofeng, Tao Jiuyang, et al. Wargaming Eco-system for Intelligence Growing[J]. Journal of System Simulation, 2021, 33(9): 2048-2058.
|
| [18] |
Davis P K, Bracken P. Artificial Intelligence for Wargaming and Modeling[J]. The Journal of Defense Modeling and Simulation: Applications, Methodology, Technology, 2025, 22(1): 25-40.
|
| [19] |
胡晓峰, 贺筱媛, 陶九阳. 认知仿真:是复杂系统建模的新途径吗?[J]. 科技导报, 2018, 36(12): 46-54.
|
|
Hu Xiaofeng, He Xiaoyuan, Tao Jiuyang. Cognitive Simulation: Is It a New Approach for Complex System Modeling?[J]. Science & Technology Review, 2018, 36(12): 46-54.
|
| [20] |
尹奇跃, 赵美静, 倪晚成, 等. 兵棋推演的智能决策技术与挑战[J]. 自动化学报, 2023, 49(5): 913-928.
|
|
Yin Qiyue, Zhao Meijing, Ni Wancheng, et al. Intelligent Decision Making Technology and Challenge of Wargame[J]. Acta Automatica Sinica, 2023, 49(5): 913-928.
|
| [21] |
刘潇, 刘书洋, 庄韫恺, 等. 强化学习可解释性基础问题探索和方法综述[J]. 软件学报, 2023, 34(5): 2300-2316.
|
|
Liu Xiao, Liu Shuyang, Zhuang Yunkai, et al. Explainable Reinforcement Learning: Basic Problems Exploration and Method Survey[J]. Journal of Software, 2023, 34(5): 2300-2316.
|
| [22] |
Liu Yuntao, Li Yuan, Xu Xinhai, et al. Heterogeneous Skill Learning for Multi-agent Tasks[C]//Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 37011-37023.
|
| [23] |
Wang Peng, Wang Haixun, Wang Wei. Finding Semantics in Time Series[C]//Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data. New York: Association for Computing Machinery, 2011: 385-396.
|
| [24] |
Zhao Zhe, Wang Pengkun, Wen Haibin, et al. STEM-LTS: Integrating Semantic-temporal Dynamics in LLM-driven Time Series Analysis[C]//Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelligence. Palo Alto: AAAI Press, 2025: 22858-22866.
|
| [25] |
Rashid T, Samvelyan M, Christian Schroeder De Witt, et al. Monotonic Value Function Factorisation for Deep Multi-agent Reinforcement Learning[J]. The Journal of Machine Learning Research, 2020, 21(1): 7234 - 7284.
|
| [26] |
刘权, 王宇, 付可, 等. 面向城市场景的多智能体协同博弈对抗决策仿真技术研究[C]//2024中国自动化大会论文集. 北京: 中国自动化学会, 2024: 647-652.
|
|
Liu Quan, Wang Yu, Fu Ke, et al. Research on Simulation Technology of Multi-agent Cooperative Game Confrontation Decision-making Simulation for Urban Scenarios[C]//Proceedings of the 2024 China Automation Congress. Beijing: Chinese Association of Automation, 2024: 647-652.
|
| [27] |
Cao Yuji, Zhao Huan, Cheng Yuheng, et al. Survey on Large Language Model-enhanced Reinforcement Learning: Concept, Taxonomy, and Methods[J]. IEEE Transactions on Neural Networks and Learning Systems, 2025, 36(6): 9737-9757.
|
| [28] |
Liang Yuxuan, Wen Haomin, Nie Yuqi, et al. Foundation Models for Time Series Analysis: A Tutorial and Survey[C]//Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. New York: Association for Computing Machinery, 2024: 6555-6565.
|