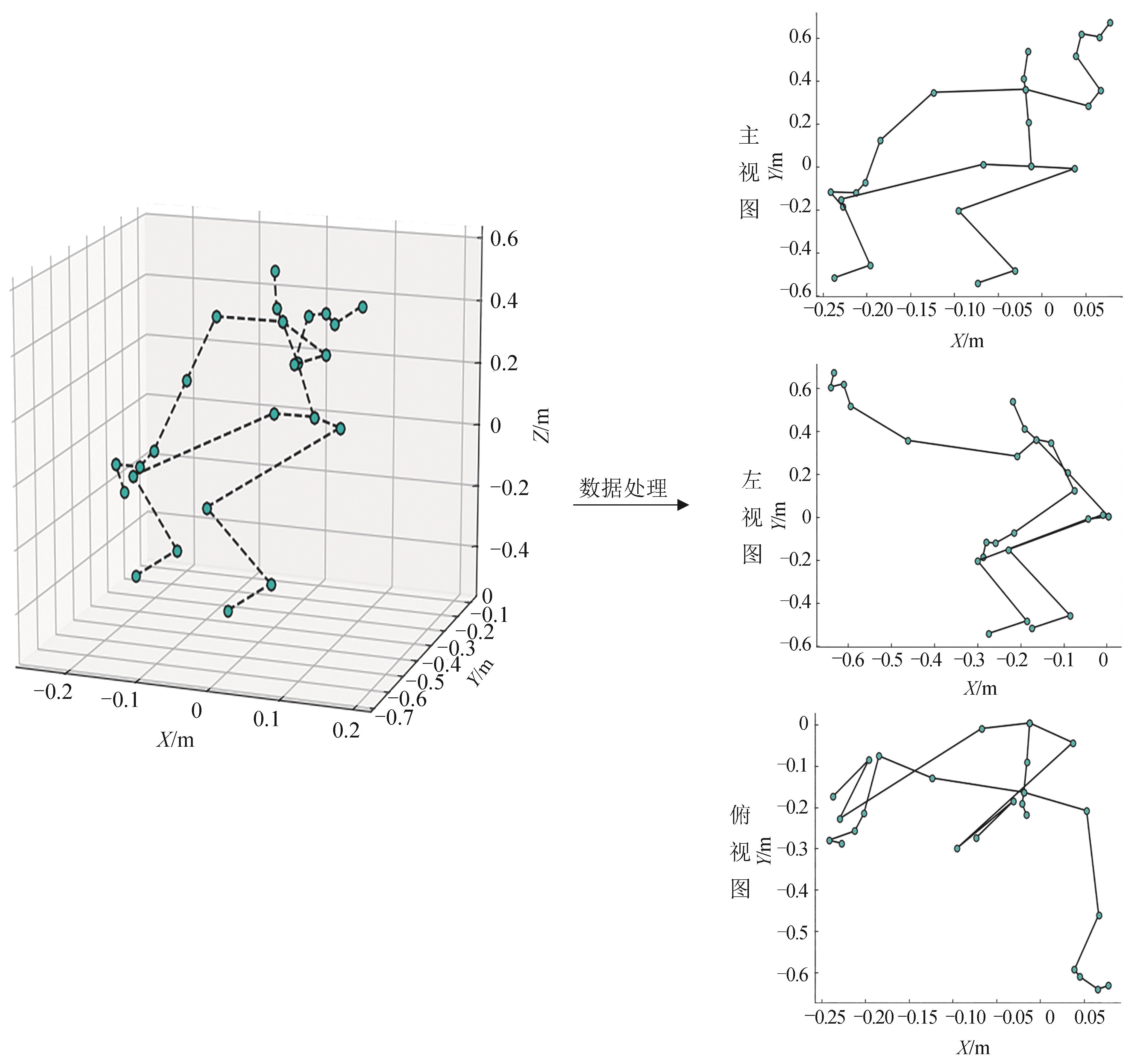
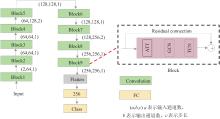
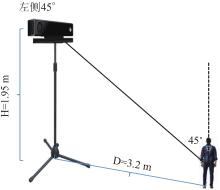
| 1 |
Martinez-Hernandez U, Dodd T J, Prescott T J. Feeling the Shape: Active Exploration Behaviors for Object Recognition with a Robotic Hand[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems (S2168-2216), 2018, 48(12): 2339-2348.
|
| 2 |
吴培良, 杨霄, 毛秉毅, 等. 一种视角无关的时空关联深度视频行为识别方法[J]. 电子与信息学报, 2019, 41(4): 904-910.
|
|
Wu Peiliang, Yang Xiao, Mao Bingyi, et al. A Perspective-Independent Method for Behavior Recognition in Depth Video Via Temporal-Spatial Correlating[J]. Journal of Electronics & Information Technology, 2019, 41(4): 904-910.
|
| 3 |
Sudha M R, Sriraghav K, Sudar Abisheck S, et al. Approaches and Applications of Virtual Reality and Gesture Recognition: A Review[M]. Hershey, PA, USA: IGI Global, 2018: 180-199.
|
| 4 |
刘云, 薛盼盼, 李辉, 等. 基于深度学习的关节点行为识别综述[J]. 电子与信息学报, 2021, 43(6): 1789-1802.
|
|
Liu Yun, Xue Panpan, Li Hui, et al. A Review of Action Recognition Using Joints Based on Deep Learning[J]. Journal of Electronics & Information Technology, 2021, 43(6): 1789-1802.
|
| 5 |
Johansson G. Visual Perception of Biological Motion and A Model for Its Analysis[J]. Perception & Psychophysics (S1532-5962), 1973, 14(2): 201-211.
|
| 6 |
Yan Sijie, Xiong Yuanjun, Lin Dahua. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition[C]// Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence. Palo Alto, CA, USA: AAAI Press, 2018: 7444-7452.
|
| 7 |
Shi Lei, Zhang Yifan, Cheng Jian, et al. Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2019: 12018-12027.
|
| 8 |
Qin Zhenyue, Liu Yang, Ji Pan, et al. Fusing Higher-Order Features in Graph Neural Networks for Skeleton-Based Action Recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2021. arXiv: 2105.01563[cs.CV].
|
| 9 |
Sun Dengdi, Zeng Fanchen, Luo Bin, et al. Information Enhanced Graph Convolutional Networks for Skeleton-Based Action Recognition[C]// 2020 International Joint Conference on Neural Networks (IJCNN). Piscataway, NJ, USA: IEEE, 2020: 1-7.
|
| 10 |
Feng Dong, Wu Zhongcheng, Zhang Jun, et al. Multi-scale Spatial Temporal Graph Neural Network for Skeleton-Based Action Recognition[J]. IEEE Access (S2169-3536), 2021, 9: 58256-58265.
|
| 11 |
Shi Lei, Zhang Yifan, Cheng Jian, et al. Skeleton-Based Action Recognition with Directed Graph Neural Networks[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2019: 7904-7913.
|
| 12 |
Ji Xiaofei, Liu Honghai. Advances in View-Invariant Human Motion Analysis: A Review[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews) (S1094-6977), 2010, 40(1): 13-24.
|
| 13 |
Su Benyue, Wu Huang, Sheng Min, et al. Accurate Hierarchical Human Actions Recognition from Kinect Skeleton Data[J]. IEEE Access (S2169-3536), 2019, 7: 52532-52541.
|
| 14 |
Cao Congqi, Lan Cuiling, Zhang Yifan, et al. Skeleton-Based Action Recognition with Gated Convolutional Neural Networks[J]. IEEE Transactions on Circuits and Systems for Video Technology (S1051-8215), 2019, 29(11): 3247-3257.
|
| 15 |
Li Bo, Dai Yuchao, Cheng Xuelian, et al. Skeleton Based Action Recognition Using Translation-Scale Invariant Image Mapping and Multi-scale Deep CNN[C]// 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW). Piscataway, NJ, USA: IEEE, 2017: 601-604.
|
| 16 |
付仔蓉, 吴胜昔, 吴潇颖, 等. 基于空间特征的BI-LSTM人体行为识别[J]. 华东理工大学学报(自然科学版), 2021, 47(2): 225-232.
|
|
Fu Zairong, Wu Shengxi, Wu Xiaoying, et al. Human Action Recognition Using BI-LSTM Network Based on Spatial Features[J]. Journal of East China University of Science and Technology, 2021, 47(2): 225-232.
|
| 17 |
Shahroudy A, Liu Jun, Ng T T, et al. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2016: 1010-1019.
|
| 18 |
Liu Jun, Shahroudy A, Perez M, et al. NTU RGB+D 120: A Large-Scale Benchmark for 3D Human Activity Understanding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence (S0162-8828), 2020, 42(10): 2684-2701.
|
| 19 |
Ke Qiuhong, Bennamoun M, An Senjian, et al. Learning Clip Representations for Skeleton-Based 3D Action Recognition[J]. IEEE Transactions on Image Processing (S1057-7149), 2018, 27(6): 2842-2855.
|
| 20 |
徐飞翔. 基于视角估计的自由视点动作理解[D]. 成都: 电子科技大学, 2021: 19-37.
|
|
Xu Feixiang. The Analysis of Action Understanding Under Arbitrary-View Based on the Viewpoint Estimation[D]. Chengdu: University of Electronic Science and Technology of China, 2021: 19-37.
|
| 21 |
孙鹏辉. 基于深度学习的多视图三维重建算法及并行化研究[D]. 银川:宁夏大学, 2020: 1-7.
|
|
Sun Penghui. Multi-view 3D Reconstruction Algorithm and Parallelization Research Based on Deep Learning[D]. Yinchuan: Ningxia University, 2020: 1-7.
|
| 22 |
胡文涛, 陈秀宏. 基于局部保持投影的鲁棒稀疏子空间学习[J]. 计算机工程与应用, 2021, 57(10): 194-199.
|
|
Hu Wentao, Chen Xiuhong. Robust Sparse Subspace Learning Based on Locality Preserving Projections[J]. Computer Engineering and Applications, 2021, 57(10): 194-199.
|
| 23 |
Kim T S, Reiter A. Interpretable 3D Human Action Analysis with Temporal Convolutional Networks[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Piscataway, NJ, USA: IEEE, 2017: 1623-1631.
|
| 24 |
Ke Qiuhong, Bennamoun M, An Senjian, et al. A New Representation of Skeleton Sequences for 3D Action Recognition[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE, 2017: 4570-4579.
|
| 25 |
Liu Jun, Shahroudy A, Xu Dong, et al. Skeleton-Based Action Recognition Using Spatio-Temporal LSTM Network with Trust Gates[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence (S1939-3539), 2018, 40(12): 3007-3021.
|
| 26 |
Li Chaolong, Cui Zhen, Zheng Wenming, et al. Spatio-Temporal Graph Convolution for Skeleton Based Action Recognition[C]// AAAI Conference on Artificial Intelligence. Palo Alto, CA, USA: AAAI Press, 2018: 3482-3489.
|
| 27 |
Liu Jun, Wang Gang, Duan Lingyu, et al. Skeleton-Based Human Action Recognition with Global Context-Aware Attention LSTM Networks[J]. IEEE Transactions on Image Processing (S1941-0042), 2018, 27(4): 1586-1599.
|
| 28 |
Yang Zhengyuan, Li Yuncheng, Yang Jianchao, et al. Action Recognition with Spatio-Temporal Visual Attention on Skeleton Image Sequences[J]. IEEE Transactions on Circuits and Systems for Video Technology (S1558-2205), 2019, 29(8): 2405-2415.
|
| 29 |
Qin Yang, Mo Lingfei, Li Chenyang, et al. Skeleton-Based Action Recognition by Part-Aware Graph Convolutional Networks[J]. The Visual Computer (S0178-2789), 2020, 36(3): 621-631.
|
 ), 孙满贞3, 马庆4, 盛敏4
), 孙满贞3, 马庆4, 盛敏4